A Fast, Flexible Trainer with Callbacks and Extensions for PyTorch

Project description

lpd
A Fast, Flexible Trainer with Callbacks and Extensions for PyTorch
lpd derives from the Hebrew word lapid (לפיד) which means "torch".
For latest PyPI stable release



pip install lpd
v0.2.7-beta Release - contains the following:
- Added
trainervalidation formetric_name_to_func ModelCheckpointargs changed to acceptCallbackMonitorEarlyStoppingargs changed to acceptCallbackMonitor- Adjusted examples and tests
- Added more unittests
Usage
lpd intended to properly structure your PyTorch model training. The main usages are given below.
Training your model
from lpd.trainer import Trainer
from lpd.enums import Phase, State, MonitorType, MonitorMode, StatsType
from lpd.callbacks import LossOptimizerHandler, StatsPrint, ModelCheckPoint, Tensorboard, EarlyStopping, SchedulerStep, CallbackMonitor
from lpd.extensions.custom_schedulers import KerasDecay
from lpd.metrics import BinaryAccuracyWithLogits
from lpd.utils.torch_utils import get_gpu_device_if_available
from lpd.utils.general_utils import seed_all
seed_all(seed=42) # because its the answer to life and the universe
device = get_gpu_device_if_available() # with fallback to CPU if GPU not avilable
model = MyModel(config, num_embeddings).to(device) # this is your model class, and its being sent to the relevant device
optimizer = torch.optim.SGD(params=model.parameters())
scheduler = KerasDecay(optimizer, decay=0.01, last_step=-1) # decay scheduler using keras formula
loss_func = torch.nn.BCEWithLogitsLoss().to(device) # this is your loss class, already sent to the relevant device
metric_name_to_func = {'acc':BinaryAccuracyWithLogits()} # define your metrics in a dictionary
# you can use some of the defined callbacks, or you can create your own
callbacks = [
LossOptimizerHandler(),
SchedulerStep(apply_on_phase=Phase.BATCH_END, apply_on_states=State.TRAIN),
ModelCheckPoint(checkpoint_dir,
checkpoint_file_name,
CallbackMonitor(patience=-1,
monitor_type=MonitorType.LOSS,
stats_type=StatsType.VAL,
monitor_mode=MonitorMode.MIN),
save_best_only=True),
Tensorboard(summary_writer_dir=summary_writer_dir),
EarlyStopping(CallbackMonitor(patience=10,
monitor_type=MonitorType.METRIC,
stats_type=StatsType.VAL,
monitor_mode=MonitorMode.MAX,
metric_name='acc')),
StatsPrint(train_metrics_monitors=CallbackMonitor(patience=-1,
monitor_type=MonitorType.METRIC,
stats_type=StatsType.TRAIN,
monitor_mode=MonitorMode.MAX,
metric_name='acc'))
]
trainer = Trainer(model,
device,
loss_func,
optimizer,
scheduler,
metric_name_to_func,
train_data_loader, # DataLoader, Iterable or Generator
val_data_loader, # DataLoader, Iterable or Generator
train_steps,
val_steps,
callbacks,
name='Readme-Example')
trainer.train(num_epochs)
Evaluating your model
trainer.evaluate(test_data_loader, test_steps)
Making predictions
# On single sample:
prediction = trainer.predict_sample(sample)
# On batch:
predictions = trainer.predict_batch(batch)
# On Dataloader/Iterable/Generator:
predictions = trainer.predict_data_loader(data_loader, steps)
TrainerStats
Trainer tracks stats for train/validate/test and you can access them in your custom callbacks
or any other place that has access to your trainer.
Here are some examples
train_loss = trainer.train_stats.get_loss() # the mean of the last epoch's train losses
val_loss = trainer.val_stats.get_loss() # the mean of the last epoch's validation losses
test_loss = trainer.test_stats.get_loss() # the mean of the test losses (available only after calling evaluate)
train_metrics = trainer.train_stats.get_metrics() # dict(metric_name, mean(values)) of the current epoch in train state
val_metrics = trainer.val_stats.get_metrics() # dict(metric_name, mean(values)) of the current epoch in validation state
test_metrics = trainer.test_stats.get_metrics() # dict(metric_name, mean(values)) of the test (available only after calling evaluate)
Callbacks
Some common callbacks are available under lpd.callbacks.
Notice that apply_on_phase (lpd.enums.Phase) will determine the execution phase,
and apply_on_states (lpd.enums.State or list(lpd.enums.State)) will determine the execution states
These are the current available phases and states, more might be added in future releases
State.EXTERNAL
Phase.TRAIN_BEGIN
# train loop:
Phase.EPOCH_BEGIN
State.TRAIN
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.VAL
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.EXTERNAL
Phase.EPOCH_END
Phase.TRAIN_END
Evaluation phases and states will behave as follow
State.EXTERNAL
Phase.TEST_BEGIN
State.TEST
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.EXTERNAL
Phase.TEST_END
Predict phases and states will behave as follow
State.EXTERNAL
Phase.PREDICT_BEGIN
State.PREDICT
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.EXTERNAL
Phase.PREDICT_END
With phases and states, you have full control over the timing of your callbacks,
LossOptimizerHandler Callback
Derives from LossOptimizerHandlerBase, probably the most important callback 😎
Use LossOptimizerHandler to determine when to call:
loss.backward(...)
optimizer.step(...)
optimizer.zero_grad(...)
Or, you may choose to create your own AwesomeLossOptimizerHandler class by deriving from LossOptimizerHandlerBase.
Trainer.train(num_epochs) will validate that at least one LossOptimizerHandlerBase callback was provided.
For example, say your machine can handle up to batch_size = 8, but you want to accumulate gradients until you reach 32 samples before you backprop, then you can define your optimizer handler function, to pass it later to LossOptimizerHandler:
def my_optimizer_handler_closure(action):
last_invocation_sample_count = 0 # closure state
def handler(callback_context): # CallbackContext class will be passed here by LossOptimizerHandler
nonlocal last_invocation_sample_count # for closure state
trainer = callback_context.trainer
optimizer = callback_context.optimizer
if callback_context.sample_count - last_invocation_sample_count >= 32:
last_invocation_sample_count = callback_context.sample_count
if action == 'step':
optimizer.step()
elif action == 'zero_grad':
optimizer.zero_grad()
return handler
And now, use it in LossOptimizerHandler callback :
LossOptimizerHandler(apply_on_phase=Phase.BATCH_END,
apply_on_states=State.TRAIN,
loss_handler=None, # default loss handler will be used (calls loss.backward() every invocation)
optimizer_step_handler=my_optimizer_handler_closure(action='step'),
optimizer_zero_grad_handler=my_optimizer_handler_closure(action='zero_grad')),
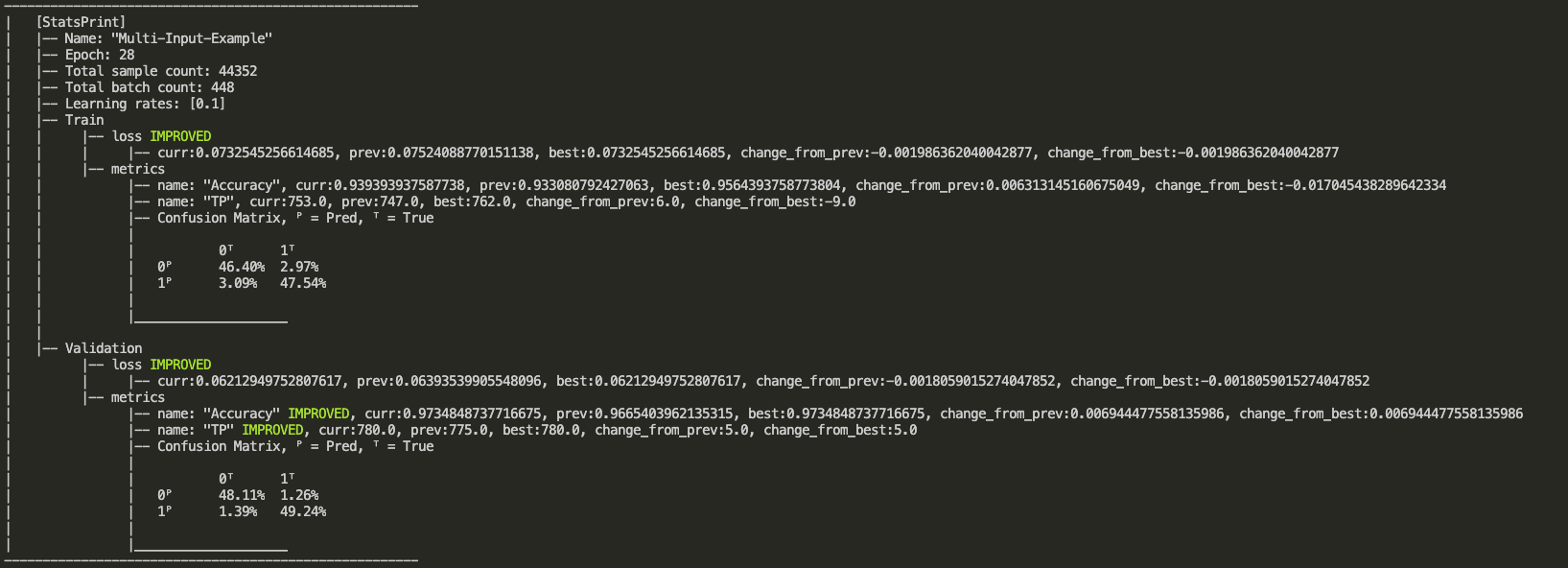
StatsPrint Callback
StatsPrint callback prints informative summary of the trainer stats including loss and metrics.
StatsPrint(apply_on_phase=Phase.EPOCH_END,
apply_on_states=State.EXTERNAL,
train_metrics_monitors=CallbackMonitor(patience=None,
monitor_type=MonitorType.METRIC,
stats_type=StatsType.TRAIN,
monitor_mode=MonitorMode.MAX,
metric_name='Accuracy'))
Output example:
ModelCheckPoint Callback
Saving a checkpoint when a monitored loss/metric has improved. The callback will save the model, optimizer, scheduler, and epoch number. You can also configure it to save Full Trainer.
For example, ModelCheckPoint that will save a new full trainer checkpoint every time the validation metric_name my_metric
is getting higher than the highest value so far.
ModelCheckPoint(checkpoint_dir,
checkpoint_file_name,
callback_monitor=CallbackMonitor(patience=None,
monitor_type=MonitorType.METRIC,
stats_type=StatsType.VAL,
monitor_mode=MonitorMode.MAX,
metric_name='my_metric'),
save_best_only=False,
save_full_trainer=True))
EarlyStopping Callback
Stops the trainer when a monitored loss/metric has stopped improving. For example, EarlyStopping that will monitor at the end of every epoch, and stop the trainer if the validation loss didn't improve (decrease) for the last 10 epochs.
EarlyStopping(apply_on_phase=Phase.EPOCH_END,
apply_on_states=State.EXTERNAL,
callback_monitor=CallbackMonitor(patience=10,
monitor_type=MonitorType.LOSS,
stats_type=StatsType.VAL,
monitor_mode=MonitorMode.MIN))
SchedulerStep Callback
Will invoke step() on your scheduler in the desired phase and state.
For example, SchedulerStep callback to invoke scheduler.step() at the end of every batch, in train state (as opposed to validation and test):
from lpd.callbacks import SchedulerStep
from lpd.enums import Phase, State
SchedulerStep(apply_on_phase=Phase.BATCH_END, apply_on_states=State.TRAIN)
In case you need it on validation state as well, pass a list for apply_on_states like so:
SchedulerStep(apply_on_phase=Phase.BATCH_END, apply_on_states=[State.TRAIN, State.VAL])
Tensorboard Callback
Will export the loss and the metrics at a given phase and state, in a format that can be viewed on Tensorboard
Tensorboard(apply_on_phase=Phase.EPOCH_END,
apply_on_states=State.EXTERNAL,
summary_writer_dir=dir_path)
CollectOutputs Callback
Use it in case you want to collect the outputs of any given state during training.
CollectOutputs is automatically used by Trainer to collect the predictions when calling one of the predict methods.
CollectOutputs(apply_on_phase=Phase.BATCH_END, apply_on_states=State.VAL)
Create your custom callbacks
from lpd.enums import Phase, State
from lpd.callbacks import CallbackBase
class MyAwesomeCallback(CallbackBase):
def __init__(self, apply_on_phase=Phase.BATCH_END, apply_on_states=[State.TRAIN, State.VAL]):
# make sure to call init parent class
super(MyAwesomeCallback, self).__init__(apply_on_phase, apply_on_states)
def __call__(self, callback_context): # <=== implement this method!
# your implementation here
# using callback_context, you can access anything in your trainer
# below are some examples to get the hang of it
val_loss = callback_context.val_stats.get_loss()
train_loss = callback_context.train_stats.get_loss()
train_metrics = callback_context.train_stats.get_metrics()
val_metrics = callback_context.val_stats.get_metrics()
optimizer = callback_context.optimizer
scheduler = callback_context.scheduler
trainer = callback_context.trainer
if val_loss < 0.0001:
# you can also mark the trainer to STOP training by calling stop()
trainer.stop()
Lets expand MyAwesomeCallback with CallbackMonitor to track if our validation loss is getting better
from lpd.callbacks import CallbackBase, CallbackMonitor # <== CallbackMonitor added
from lpd.enums import Phase, State, MonitorType, StatsType, MonitorMode # <== added few needed enums to configure CallbackMonitor
class MyAwesomeCallback(CallbackBase):
def __init__(self, apply_on_phase=Phase.BATCH_END, apply_on_states=[State.TRAIN, State.VAL]):
super(MyAwesomeCallback, self).__init__(apply_on_phase, apply_on_states)
# adding CallbackMonitor to track VAL LOSS with regards to MIN (lower is better) and patience or 20 epochs
self.val_loss_monitor = CallbackMonitor(patience=20, MonitorType.LOSS, StatsType.VAL, MonitorMode.MIN)
def __call__(self, callback_context: CallbackContext): # <=== implement this method!
# same as before, using callback_context, you can access anything in your trainer
train_metrics = callback_context.train_stats.get_metrics()
val_metrics = callback_context.val_stats.get_metrics()
# invoke track() method on your monitor and pass callback_context as parameter
# since you configured your val_loss_monitor, it will get the relevant parameters from callback_context
monitor_result = self.val_loss_monitor.track(callback_context)
# monitor_result (lpd.callbacks.CallbackMonitorResult) contains lots of informative properties
# for example lets check the status of the patience countdown
if monitor_result.has_patience():
print(f'[MyAwesomeCallback] - patience left: {monitor_result.patience_left}')
# Or, let's stop the trainer, by calling the trainer.stop()
# if our monitored value did not improve
if not monitor_result.has_improved():
print(f'[MyAwesomeCallback] - {monitor_result.description} has stopped improving')
callback_context.trainer.stop()
Metrics
lpd.metrics provides metrics to check the accuracy of your model, let's create a custom metric using MetricBase and also show the use of BinaryAccuracyWithLogits in this example
from lpd.metrics import BinaryAccuracyWithLogits, MetricBase
# our custom metric
class InaccuracyWithLogits(MetricBase):
def __init__(self):
self.bawl = BinaryAccuracyWithLogits() # we exploit BinaryAccuracyWithLogits for the computation
def __call__(self, y_pred, y_true): # <=== implement this method!
# your implementation here
acc = self.bawl(y_pred, y_true)
return 1 - acc # return the inaccuracy
# we can now define our metrics and pass them to the trainer
metric_name_to_func = {'accuracy':BinaryAccuracyWithLogits(), 'inaccuracy':InaccuracyWithLogits()}
Save and Load full Trainer
Sometimes you just want to save everything so you can continue training where you left off.
To do so, you may use ModelCheckPoint for saving full trainer by setting parameter
save_full_trainer=True
Or, you can invoke it directly from your trainer
your_trainer.save_trainer(dir_path, file_name)
Loading a trainer from checkpoint is as simple as:
loaded_trainer = Trainer.load_trainer(dir_path, # the folder where the saved trainer file exists
trainer_file_name, # the saved trainer file name
model, # state_dict will be loaded
device,
loss_func, # state_dict will be loaded
optimizer, # state_dict will be loaded
scheduler, # state_dict will be loaded
train_data_loader, # provide new/previous data_loader
val_data_loader, # provide new/previous data_loader
train_steps,
val_steps)
Utils
lpd.utils provides torch_utils, file_utils and general_utils
For example, a good practice is to use seed_all as early as possible in your code, to make sure that results are reproducible:
import lpd.utils.general_utils as gu
gu.seed_all(seed=42) # because its the answer to life and the universe
Extensions
lpd.extensions provides some custom PyTorch layers, and schedulers, these are just some stuff we like using when we create our models, to gain better flexibility.
So you can use them at your own will, more extensions are added from time to time.
TODOS (more added frequently)
- Add Logger
- Add support for multiple schedulers
- Add support for multiple losses
- Add colab examples
Something is missing?! please share with us
You can open an issue, but also feel free to email us at torch.lpd@gmail.com
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







