Largest-Triangle-Three-Buckets algorithm for downsampling time series-like data

Project description
Numpy implementation of Steinarsson’s Largest-Triangle-Three-Buckets algorithm for downsampling time series–like data while retaining the overall shape and variability in the data
LTTB is well suited to filtering time series data for visual representation, since it reduces the number of visually redundant data points, resulting in smaller file sizes and faster rendering of plots.
Note that it is not a technique for statistical aggregation, cf. regression models or non-parametric curve fitting / smoothing.
This implementation is based on the original JavaScript code at https://github.com/sveinn-steinarsson/flot-downsample and Sveinn Steinarsson’s 2013 MSc thesis Downsampling Time Series for Visual Representation.
Licence: MIT


Usage
Install the lttb package into your (virtual) environment:
$ pip install lttb
The function lttb.downsample() can then be used in your Python code:
import numpy as np
import lttb
# Generate an example data set of 100 random points:
# - column 0 represents time values (strictly increasing)
# - column 1 represents the metric of interest: CPU usage, stock price, etc.
data = np.array([range(100), np.random.random(100)]).T
# Downsample it to 20 points:
small_data = lttb.downsample(data, n_out=20)
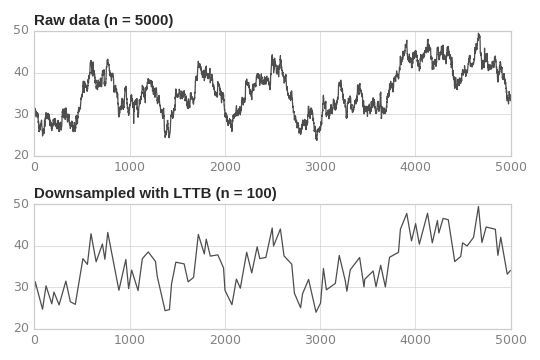
assert small_data.shape == (20, 2)A test data set is provided in the source repo in tests/timeseries.csv. It was downloaded from http://flot.base.is/ and converted from JSON to CSV.
This is what it looks like, downsampled to 100 points:
Input validation
By default, downsample() checks that the input data satisfies the following constraints:
it is a two-dimensional array of two columns;
the values in the first column are strictly increasing; and
there are no missing (NaN) values in the data.
These checks can be skipped (e.g. if you know that your data will always meet these conditions), or additional checks can be added (e.g. that the time values must be evenly spaced), by passing in a different list of validation functions, e.g.:
# No input validation:
small_data = lttb.downsample(data, n_out=20, validators=[])
# Stricter check on x values:
from lttb.validators import *
small_data = lttb.downsample(data, n_out=20, validators=[has_two_columns, x_is_regular])History
0.3.2 / 2024-09-06
[dev] The library has been successfully tested against Python 3.12 and Numpy 1.25. No changes to the code were required.
[dev] The project is now defined in pyproject.toml and packaged with Flit.
0.3.1 / 2020-10-14
All modules and functions now have docstrings.
[dev] The library is now also tested against Python 3.9. No changes to the code were required.
[dev] The project is now hosted on SourceHut; the links on the PyPI page have been updated.
[dev] CI testing has been migrated from Travis to builds.sr.ht.
0.3.0 / 2020-09-15
Validation of input data is now configurable.
New default: downsample() raises ValueError if input data contains NaN values. This can be disabled by removing contains_no_nans() from the list of validators.
[dev] Imports are now sorted with isort.
0.2.2 / 2020-01-08
setup.py was fixed so that this package can be installed in Python 2 again.
0.2.1 / 2019-11-25
[dev] Versions are now managed with setuptools_scm rather than bumpversion.
[dev] The code is formatted with Black.
0.2.0 / 2018-02-11
Performance improvements
Released on PyPI (on 2019-11-06)
0.1.0 / 2017-03-18
Initial implementation
Contributors
JA Viljoen – original Numpy implementation
Guillaume Bethouart – performance improvements
Jens Krüger – fix for py27


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lttb-0.3.2.tar.gz.
File metadata
- Download URL: lttb-0.3.2.tar.gz
- Upload date:
- Size: 106.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.32.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b7f280d3ad71a68497f75eee3d03f1bcaccac0d56c430b7afa562682bf6c69c0
|
|
| MD5 |
c785b71fa0a7a6e9e663c48fee16c0ad
|
|
| BLAKE2b-256 |
faaf422282fcfe21179a4e25a03bea607d51f426957956b18fbe97b7bda8ba13
|
File details
Details for the file lttb-0.3.2-py3-none-any.whl.
File metadata
- Download URL: lttb-0.3.2-py3-none-any.whl
- Upload date:
- Size: 5.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.32.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
10fddd96bc4b6084ce9146045aeed2016176b78057d8803424a6740af102ef50
|
|
| MD5 |
b998e1111d0c01daecec7832c38bd2fa
|
|
| BLAKE2b-256 |
f983146c427d76d647a474da827c7d896b8114fb17db93b1393939cecde45af3
|







