MAC: Multi-Agent Constitution Learning — a general-purpose rule learning engine

Project description


The explainable, auditable prompt optimizer
Rules you can read. Gains you can trust. No fine-tuning.




Healthcare PII +123% · Legal PII +17% · HoVer +63% · GSM8K → 100%
Overview
Constitutional AI steers LLM behavior through natural-language rules, but writing those rules by hand is hard, and getting them right is harder. Existing prompt optimizers try to automate this but fall short: they need many labeled examples, produce opaque prompt edits, and hit diminishing returns as prompts grow.
MAC fixes this. It optimizes over structured sets of rules using a network of specialized agents that propose, edit, and validate rule updates against a held-out set. The result is a human-readable constitution with no fine-tuning and no gradient updates.
Here are real rules MAC learned for PII tagging across three regulated domains:
Legal: "Mark as private specific dates when they appear in the context of personal events or actions, such as births, deaths, or significant life events. Do not mark general references or narrative text." Examples: mark "1975", "22 August 2003"; do not mark "on a day in June".
Healthcare: "Mark terms such as heart failure subtypes (e.g., diastolic heart failure, systolic heart failure) when explicitly mentioned in a patient's medical history as private. Do not mark generic medical conditions without an explicit subtype."
Finance: "Mark as private any phrase indicating a specific financial timeframe (e.g., FY2022, YTD FY2021) when it appears in direct association with identifiable information. Do not mark standalone labels without specific identifiers."
Why MAC over other prompt optimizers?
- Explainable: every rule is natural language you can read, audit, and hand-edit. No black-box token shuffling.
- Structured: optimizes over a set of rules, not a monolithic prompt blob. Rules are added, edited, or removed independently, so the constitution stays clean as it grows.
- Auditable: each proposed rule is validated against a held-out batch before acceptance. You see exactly what changed and why.
- Transferable: a constitution learned on one model works on another without retraining.
- Sample-efficient: converges with far fewer labeled examples than GEPA or MIPRO.
Full documentation, prompting modes, and model configuration are at mac-prompt.com.
How It Works
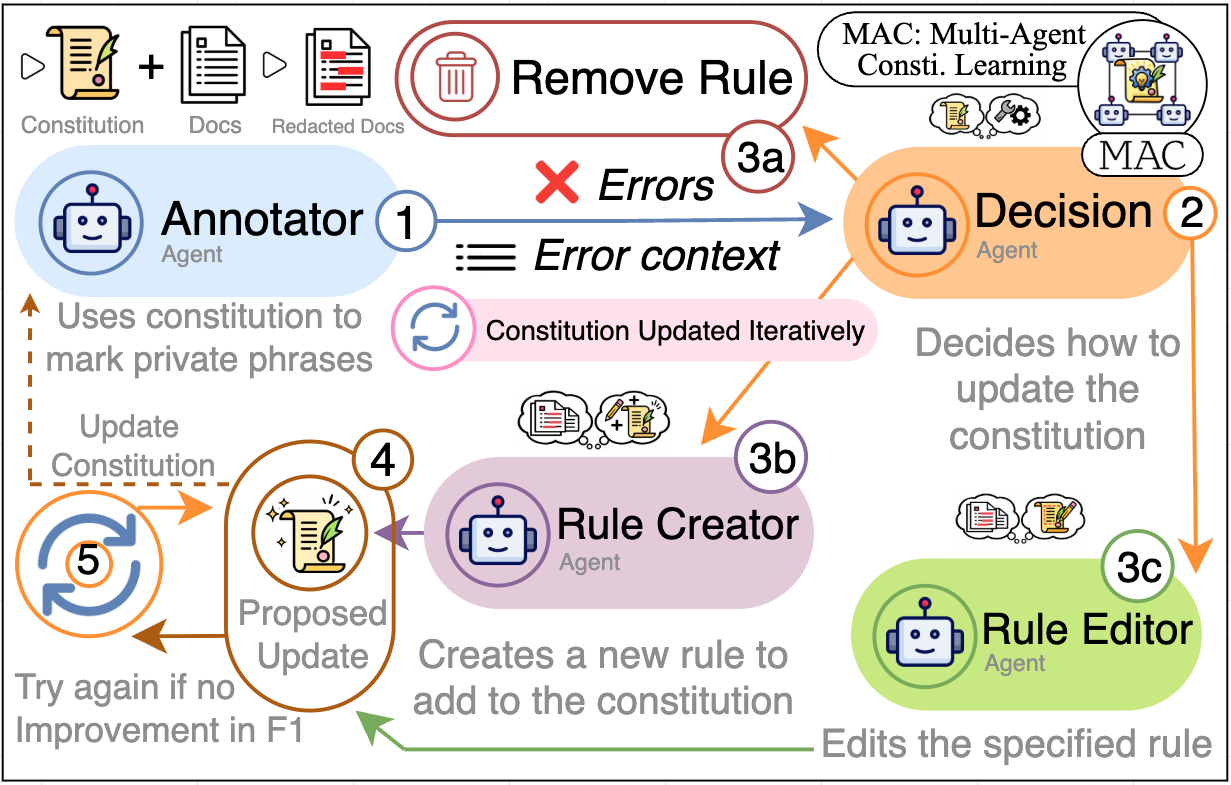
Four agents coordinate in a closed loop each epoch:
- Annotator runs the current constitution on a training batch and scores each example
- Decision Agent looks at the errors and decides whether to add a new rule or edit an existing one
- Rule Proposer drafts a candidate rule targeting the observed error pattern
- Rule Editor refines existing rules to remove contradictions or sharpen specificity
Every proposed change is tested on a held-out validation batch. If the score goes up, the rule is accepted and the constitution advances to the next version. If not, the change is discarded. This means the constitution only ever improves, with no regression.
The meta-model and task adaptation
MAC works on any task because of a fifth component: a meta-model that runs once before training starts. It reads your task description, inspects real data samples, and rewrites the four agent prompts to be domain-specific, replacing generic placeholders with actual instructions about your task format, output schema, and evaluation criteria. This is a structural rewrite, not a word swap. After adaptation, all four agents speak the language of your task.
Any Task, Any Model
MAC is not tied to a single domain or model family. Give it a task_description, a few labeled examples, and a scoring function, and it learns a constitution for any task you can evaluate: classification, extraction, math, QA, tool calling, and more.
Under the hood, MAC uses a three-tier model setup:
- Tier 1 (Worker): annotates examples using the current constitution. Can be a cheap local model (Qwen3-8B on vLLM) or a cloud API model (gpt-4o-mini). Runs on every example in every batch, so cost matters here.
- Tier 2 (MAC agents): the four-agent network that proposes, edits, and validates rules. Should be a strong model (gpt-4o or equivalent). Runs far less frequently than the worker.
- Tier 3 (Adapt model): rewrites agent prompts before training starts. Defaults to the same model as Tier 2 if not set separately.
compiler = MAC(
model="Qwen/Qwen3-8B", # Tier 1: worker (cheap / local)
base_url="http://localhost:8000/v1", # vLLM server at any port
mac_model="gpt-4o", # Tier 2: MAC agents (strong)
# adapt_model="gpt-4o", # Tier 3: defaults to mac_model
task_description="Solve AIME competition math problems.",
rule_type="math reasoning rules",
)
See Model Configuration for the full fallback cascade, vLLM port configuration, and provider examples.
Try it now
Step 1. Install and set your API key
pip install mac-prompt
export OPENAI_API_KEY=sk-...
Step 2. Import MAC
Example wraps a single labeled input/output pair. MAC is the optimizer. CompiledMAC is what you get back — a callable model you can save and reload.
from mac import Example, MAC, CompiledMAC
Step 3. Define your task
Tell MAC what you're solving and what kind of rules to learn.
optimizer = MAC(
model="gpt-4o-mini",
task_description="Solve AIME math problems. Return only the integer answer.",
rule_type="math reasoning rules",
)
Step 4. Provide your data
A small labeled set is enough. MAC uses trainset to learn rules and holdout to validate each candidate rule before accepting it.
train = [
Example(input="Find all integer bases b>9 where 17_b divides 97_b.", output="70"),
Example(input="How many ordered pairs (x,y) in [-100,100] satisfy 12x²-xy-6y²=0?", output="117"),
]
holdout = [
Example(input="Sum of positive integers n where n+2 divides 3(n+3)(n²+9)?", output="49"),
]
Step 5. Define a metric
Any function that returns a score between 0 and 1 works.
def metric(pred, gold):
try: return 1.0 if float(str(pred).strip()) == float(str(gold).strip()) else 0.0
except ValueError: return 0.0
Step 6. Run and inspect
compile() runs the rule-learning loop and returns a ready-to-call model.
optimized = optimizer.compile(trainset=train, holdout=holdout, metric=metric)
answer = optimized("Find all integer bases b>9 where 17_b divides 97_b.")
optimized.overview() # shows the learned rules and baseline vs final score
optimized.save("rules.json") # save and reload with CompiledMAC.load("rules.json")
MAC vs Prompt Optimizers
Domain-specific PII tagging across Legal, Finance, and Healthcare documents using Qwen2.5-Instruct models at 3B, 7B, and 14B scales.
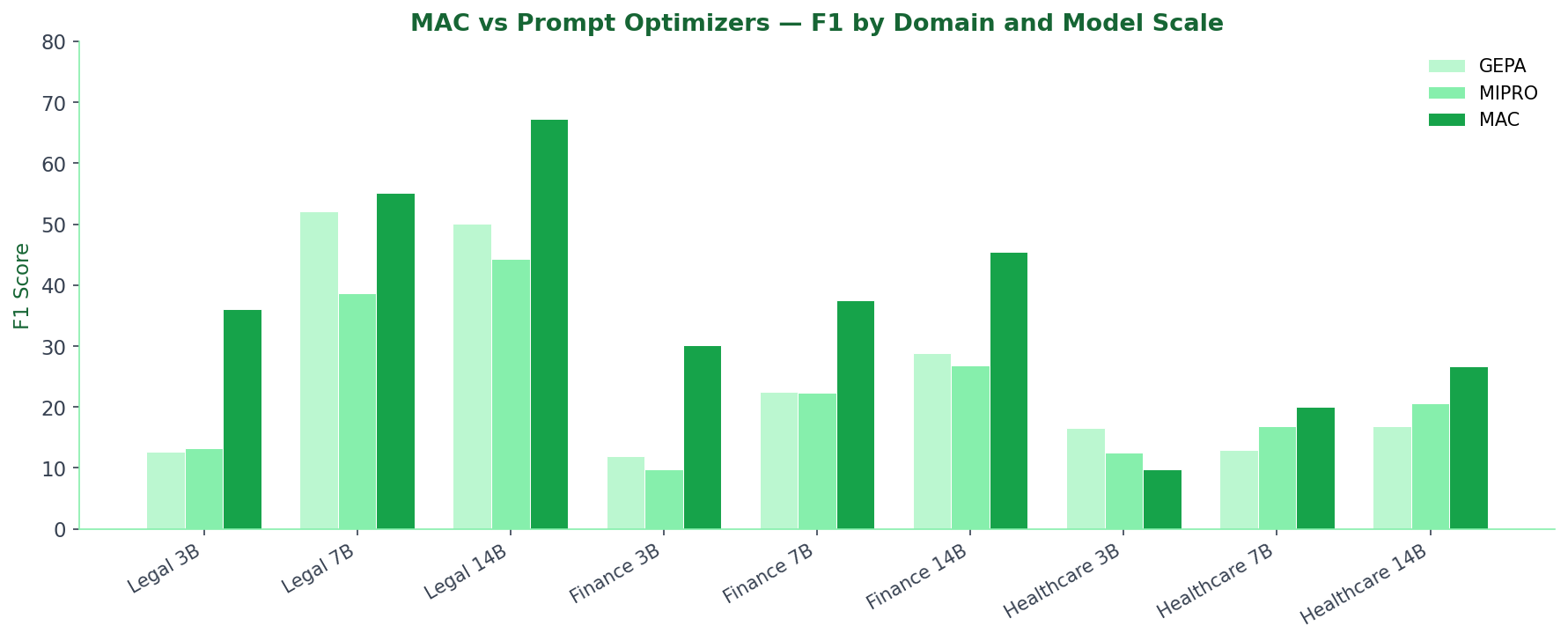
| Dataset | Method | 3B | 7B | 14B |
|---|---|---|---|---|
| Legal | GEPA | 12.7 | 52.1 | 50.1 |
| Legal | MIPRO | 13.2 | 38.6 | 44.3 |
| Legal | MAC | 36.0 | 55.1 | 67.3 |
| Finance | GEPA | 11.9 | 22.5 | 28.8 |
| Finance | MIPRO | 9.8 | 22.3 | 26.8 |
| Finance | MAC | 30.1 | 37.5 | 45.5 |
| Healthcare | GEPA | 16.5 | 12.9 | 16.8 |
| Healthcare | MIPRO | 12.5 | 16.8 | 20.6 |
| Healthcare | MAC | 9.7 | 20.1 | 26.7 |
8 of 9 configurations MAC wins. Largest gain: Legal 3B +174% over next best.
MAC vs Pretrained Taggers (14B)
| Domain | MAC | Best Baseline | Gain |
|---|---|---|---|
| Legal | 67.3 | 57.3 (Presidio) | +17% |
| Finance | 45.5 | 44.7 (Presidio) | +2% |
| Healthcare | 26.7 | 12.0 (GLiNER) | +123% |
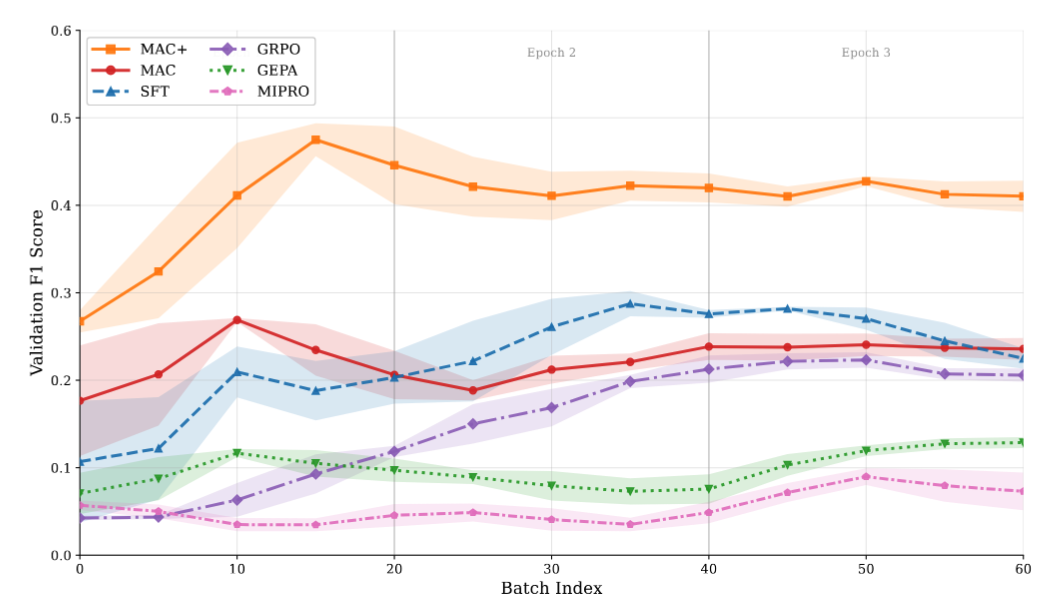
Training Dynamics
Validation F1 over training batches on 3B models (ECHR dataset). MAC steadily improves while baselines plateau or fluctuate.
Results: General-Purpose Benchmarks
MAC is task-agnostic. Below are results across three standard benchmarks ordered by largest gain: fact verification (HoVer), multi-hop QA (HotpotQA), and grade-school math (GSM8K).
Reading the tables
Each row is one (worker, MAC agents, style) configuration:
- Worker: the model being optimised; annotates every example in every batch
- MAC Agents: the decision, rule-proposer, and rule-editor agents that learn the constitution
- Meta-Model: adapts all four agent prompts to your task before training starts; identical to MAC Agents in all runs below
- Style: adapt means MAC builds the initial prompt from scratch via the meta-model; custom means the user supplies a prompt with
{{CONSTITUTION_BLOCK}}
HoVer: Fact Verification
HoVer asks the model to verify multi-hop factual claims against Wikipedia evidence (a binary yes/no task). The biggest gain (+63%) comes from gpt-4o-mini worker with gpt-5.2 MAC agents in Auto-Adapt mode. Even with a fully local Qwen3-8B worker paired with gpt-5.2 MAC agents, MAC adds +26% in Custom Prompt mode.
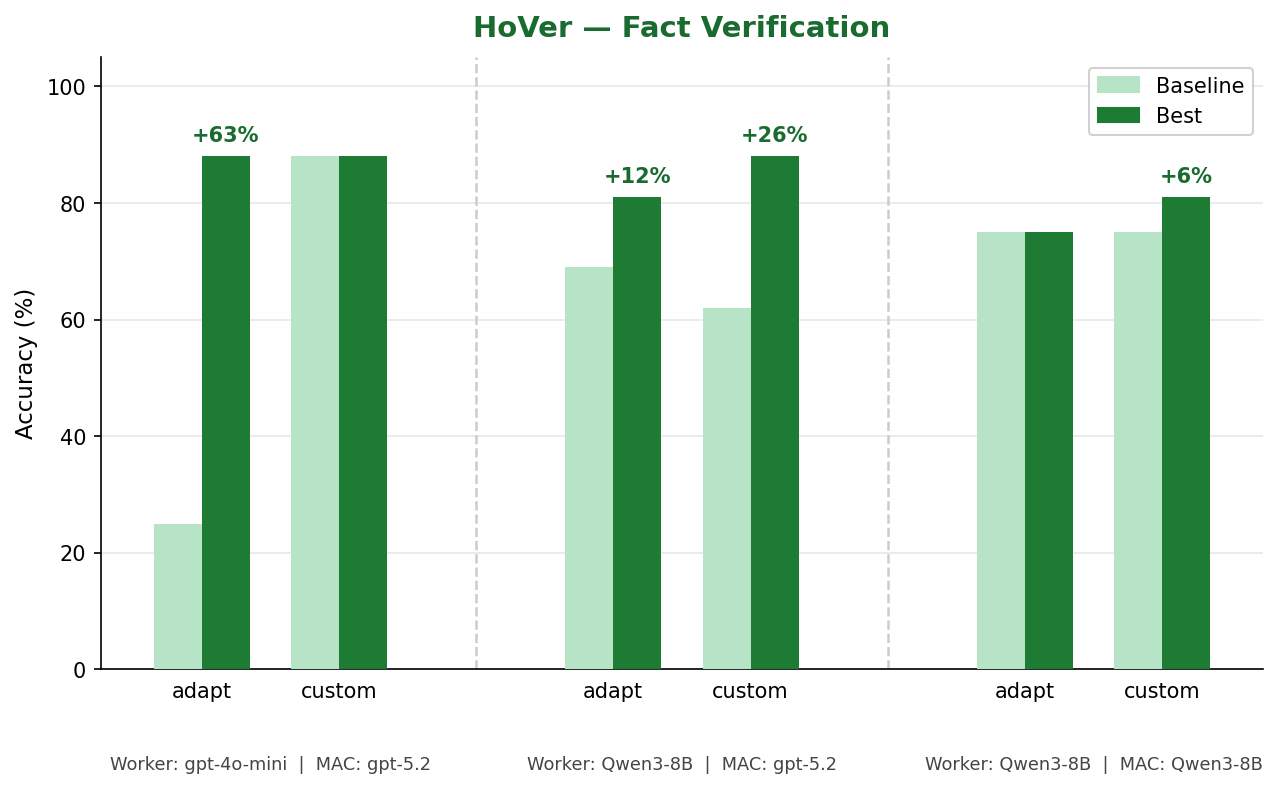
| Worker | MAC Agents | Meta-Model | Style | Baseline | Best | Delta |
|---|---|---|---|---|---|---|
| gpt-4o-mini | gpt-5.2 | gpt-5.2 | adapt | 25% | 88% | +63% |
| gpt-4o-mini | gpt-5.2 | gpt-5.2 | custom | 88% | 88% | 0% |
| Qwen3-8B | gpt-5.2 | gpt-5.2 | adapt | 69% | 81% | +12% |
| Qwen3-8B | gpt-5.2 | gpt-5.2 | custom | 62% | 88% | +26% |
| Qwen3-8B | Qwen3-8B | Qwen3-8B | adapt | 75% | 75% | 0% |
| Qwen3-8B | Qwen3-8B | Qwen3-8B | custom | 75% | 81% | +6% |
HotpotQA: Multi-Hop QA
HotpotQA requires chaining facts across two Wikipedia documents to answer a question. Baselines sit between 22% and 29%. MAC improves across every configuration except one, with the best gain of +14% when Qwen3-8B handles all three roles. The fully-local setup achieves the largest gain here because the local model has a lower baseline and more structured error patterns for the rule-proposer to target.
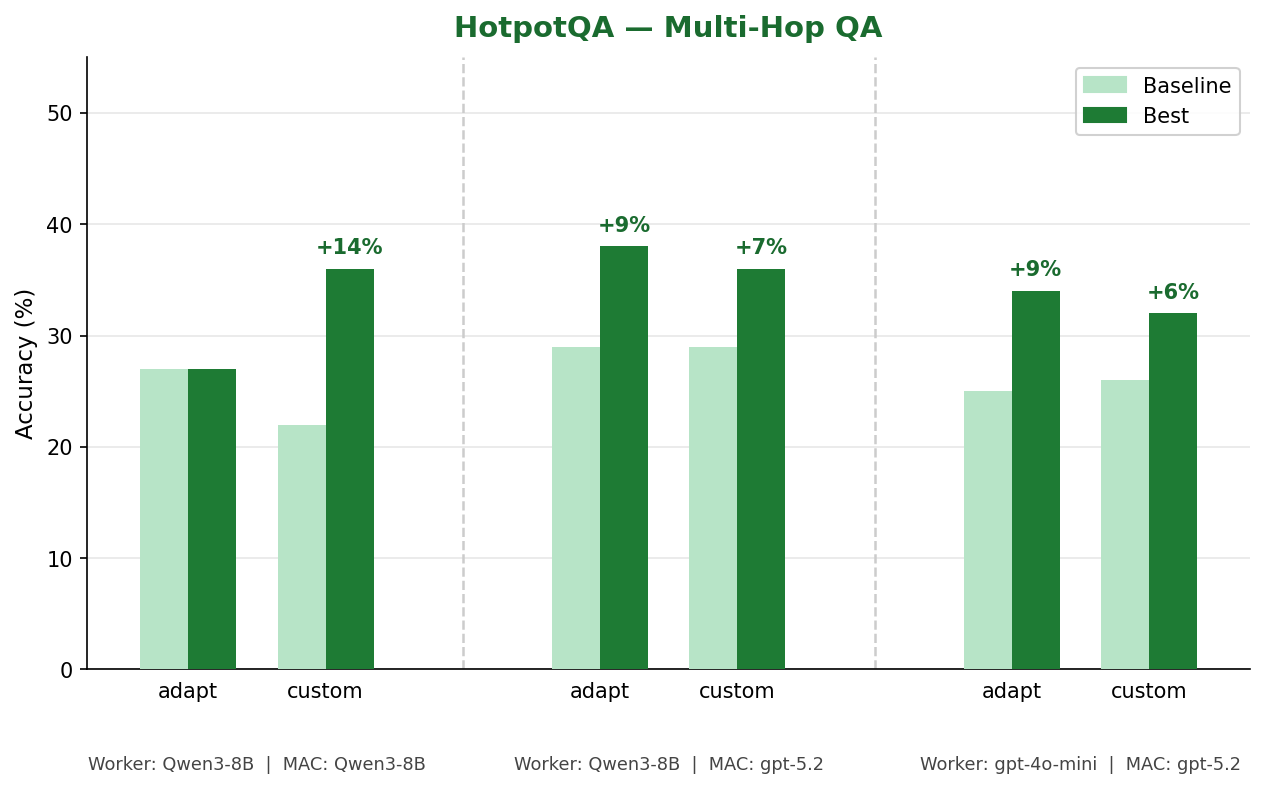
| Worker | MAC Agents | Meta-Model | Style | Baseline | Best | Delta |
|---|---|---|---|---|---|---|
| Qwen3-8B | Qwen3-8B | Qwen3-8B | adapt | 27% | 27% | 0% |
| Qwen3-8B | Qwen3-8B | Qwen3-8B | custom | 22% | 36% | +14% |
| Qwen3-8B | gpt-5.2 | gpt-5.2 | adapt | 29% | 38% | +9% |
| Qwen3-8B | gpt-5.2 | gpt-5.2 | custom | 29% | 36% | +7% |
| gpt-4o-mini | gpt-5.2 | gpt-5.2 | adapt | 25% | 34% | +9% |
| gpt-4o-mini | gpt-5.2 | gpt-5.2 | custom | 26% | 32% | +6% |
GSM8K: Math Reasoning
GSM8K tests multi-step arithmetic word problems. The Qwen3-8B baseline already scores 94% zero-shot, a high ceiling. Despite this, MAC pushes it to 100% in both modes when paired with gpt-5.2 MAC agents. The fully-local Qwen3-8B setup also reaches 100% in Custom Prompt mode.
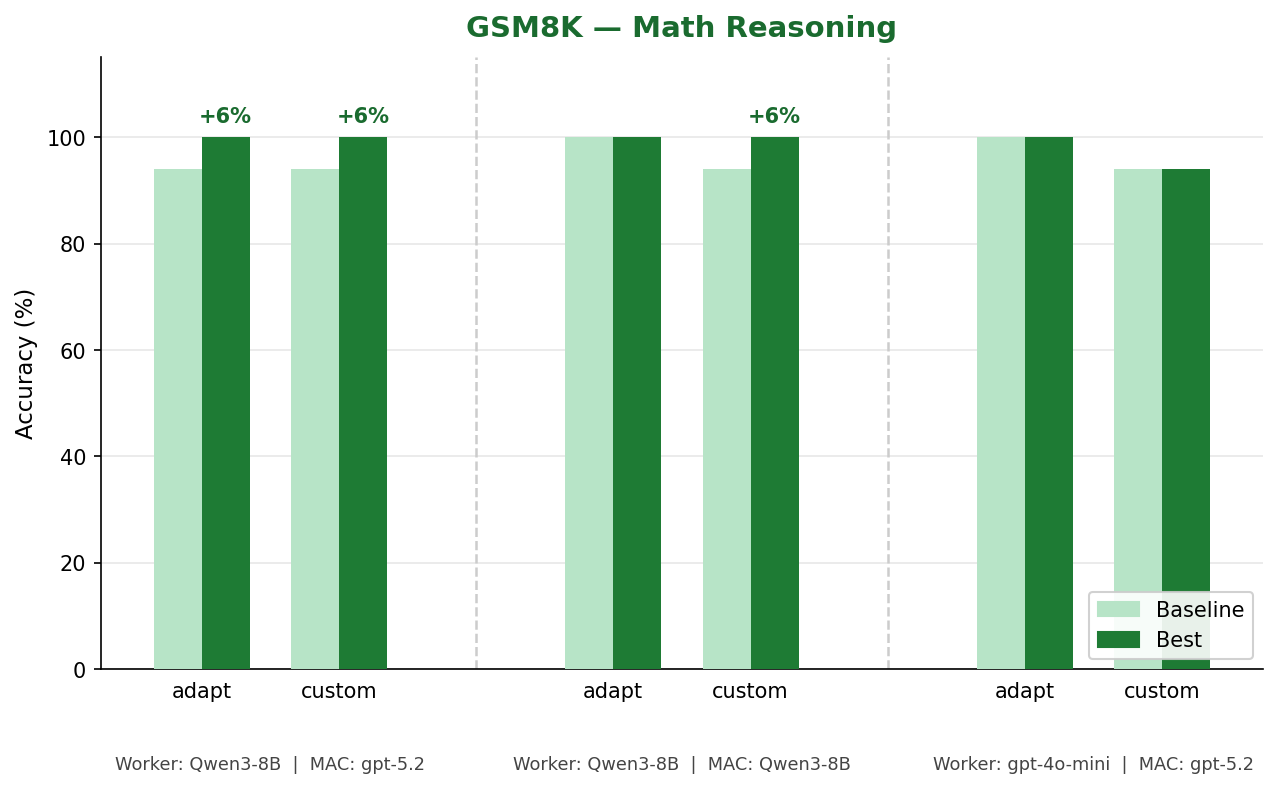
| Worker | MAC Agents | Meta-Model | Style | Baseline | Best | Delta |
|---|---|---|---|---|---|---|
| Qwen3-8B | gpt-5.2 | gpt-5.2 | adapt | 94% | 100% | +6% |
| Qwen3-8B | gpt-5.2 | gpt-5.2 | custom | 94% | 100% | +6% |
| Qwen3-8B | Qwen3-8B | Qwen3-8B | adapt | 100% | 100% | 0% |
| Qwen3-8B | Qwen3-8B | Qwen3-8B | custom | 94% | 100% | +6% |
| gpt-4o-mini | gpt-5.2 | gpt-5.2 | adapt | 100% | 100% | 0% |
| gpt-4o-mini | gpt-5.2 | gpt-5.2 | custom | 94% | 94% | 0% |
Documentation
| Guide | Description |
|---|---|
| Usage Modes | Custom prompt (Mode 1) vs auto-adapt (Mode 2) |
| Model Configuration | Three-tier setup, fallback cascade, provider support |
| API Reference | Constructor kwargs, compile(), CompiledMAC |
| MAC Variants | reMAC, MAC+, Tool-MAC: advanced paper results |
| Examples | Self-contained benchmark scripts (GSM8K, HotpotQA, HoVer) |
Citation
@article{thareja2025mac,
title={MAC: Multi-Agent Constitution Learning for Generalizable Text Annotation},
author={Thareja, Rushil},
year={2025}
}
License
MAC is released under a dual license:
- Non-commercial use (academic research, education, personal projects): free
- Commercial use: requires a separate license. Contact
rushil.thareja@mbzuai.ac.ae
See LICENSE for full terms.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mac_prompt-1.0.2.tar.gz.
File metadata
- Download URL: mac_prompt-1.0.2.tar.gz
- Upload date:
- Size: 1.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
541f4423d85abfe0c97cce0dd566c83dc711b969558ed8efbe171984e91d6ceb
|
|
| MD5 |
b4122ee318b9763d8a6c406908f1be15
|
|
| BLAKE2b-256 |
09e292bdcdbb084afd35cab50862605f6c043ed8e21fc355dce005b874f14fbd
|
File details
Details for the file mac_prompt-1.0.2-py3-none-any.whl.
File metadata
- Download URL: mac_prompt-1.0.2-py3-none-any.whl
- Upload date:
- Size: 110.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3669e6af840ae18a989fcb6f642365a80cb164ee4890ff83c3e8bf4d29c74673
|
|
| MD5 |
47631d4f154f2689b0bdc3fd7724d352
|
|
| BLAKE2b-256 |
7b091222e0a04b46b703af9d58634cba6cd3712859df832476dad2379736997c
|







