Mage is a tool for building and deploying data pipelines.


Project description
Mage OSS
Build modern data pipelines locally — fast, visual, and production-ready.
Mage OSS is a self-hosted development environment designed to help teams create production-grade data pipelines with confidence.
Ideal for automating ETL tasks, architecting data flow, or orchestrating transformations — all in a fast, notebook-style interface powered by modular code.
When it’s time to scale, Mage Pro — our core platform — unlocks enterprise orchestration, collaboration, and AI-powered workflows.




What you can do with Mage OSS
-
Build pipelines locally with Python, SQL, or R in a modular notebook-style UI
-
Run jobs manually or on a schedule (cron supported)
-
Connect to databases, APIs, and cloud storage with prebuilt connectors
-
Debug visually with logs, live previews, and step-by-step execution
-
Set up quickly with Docker, pip, or conda — no cloud account required
-
Your go-to workspace for local pipeline development — fully in your control.
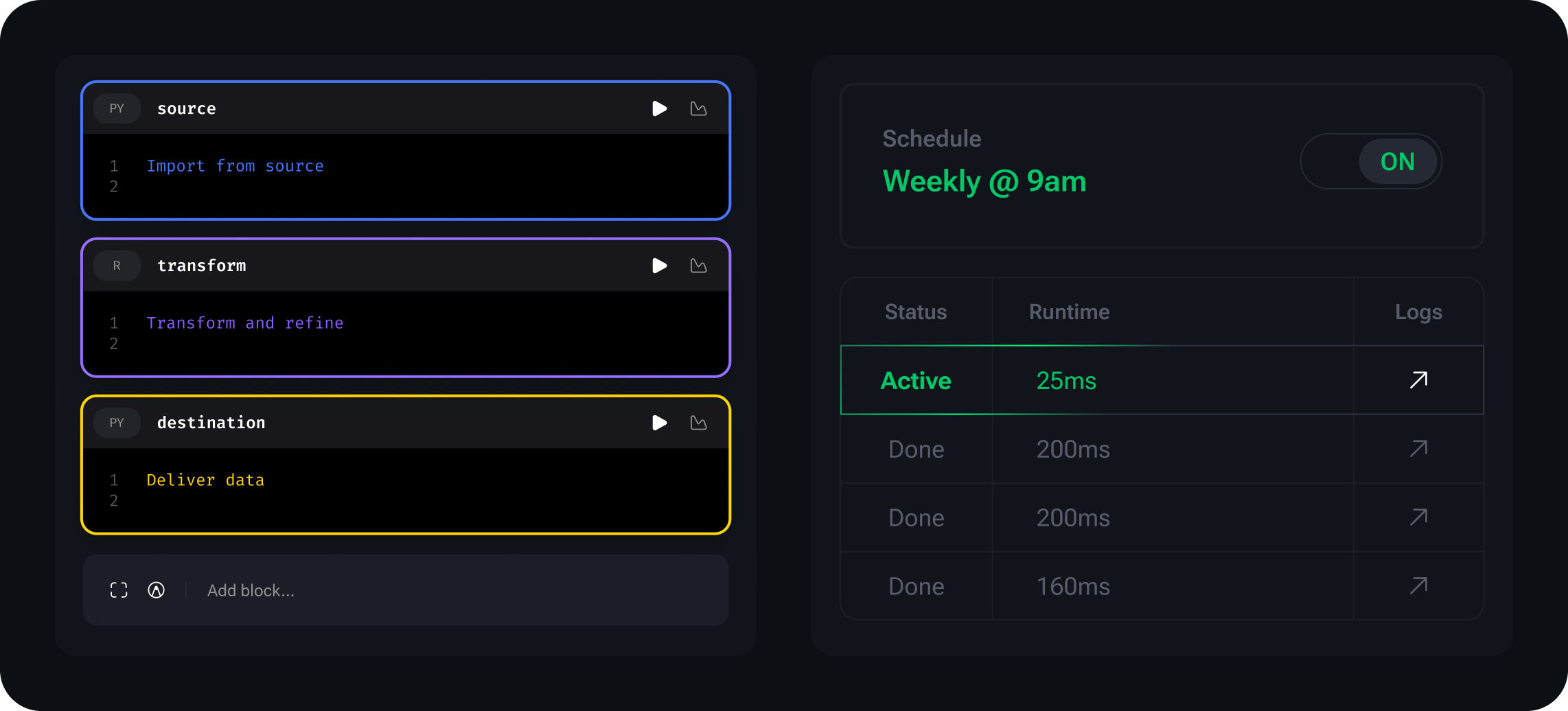
Start local. Scale when you're ready.
Use Mage OSS to build and run pipelines on your machine. When you're ready for advanced tooling, performance, and AI-assisted productivity, Mage Pro is just one click away.
Quickstart
Install using Docker (recommended):
docker pull mageai/mageai:latest
Or with pip:
pip install mage-ai
Or with conda:
conda install -c conda-forge mage-ai
Full setup guide and docs: docs.mage.ai
Core Features
| Feature | Description |
|---|---|
| Modular pipelines | Build pipelines block-by-block using Python, SQL, or R |
| Notebook UI | Interactive editor for writing and documenting logic |
| Data integrations | Prebuilt connectors to databases, APIs, and cloud storage |
| Scheduling | Trigger pipelines manually or on a schedule |
| Visual debugging | Step-by-step logs, data previews, and error handling |
| dbt support | Build and run dbt models directly inside Mage |
Example Use Cases
- Move data from Google Sheets to Snowflake with a Python transform
- Schedule a daily SQL pipeline to clean and aggregate product data
- Develop dbt models in a visual notebook-style interface
- Run simple ETL/ELT jobs locally with full transparency
Documentation
Looking for how-to guides, examples, or advanced configuration?
Explore our full documentation at docs.mage.ai.
Contributing
We welcome contributions of all kinds — bug fixes, docs, new features, or community examples.
Start with our contributing guide, check out open issues, or suggest improvements.
Ready to scale? Mage Pro has you covered.
Mage Pro is a powered-up platform built for teams. It adds everything you need for production pipelines, at scale.
- Magical AI-assisted development and debugging
- Multi-environment orchestration
- Role-based access control
- Real-time monitoring & alerts
- Powerful CI/CD & version control
- Powerful enterprise features
- Available fully managed, hybrid, or on-premises
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mage_ai-0.9.79.tar.gz.
File metadata
- Download URL: mage_ai-0.9.79.tar.gz
- Upload date:
- Size: 38.1 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b54c5fc75504c59602001e7fdfad202a3d08fb9f79f30a2282b4ac8bf6d63ce2
|
|
| MD5 |
f9aa580bcf784e7d9afa0db0e91d7edf
|
|
| BLAKE2b-256 |
5e8fd6c69df63c2369da60550f9e2e3341933450ea42f8d807c2b90a7dafca57
|
File details
Details for the file mage_ai-0.9.79-py3-none-any.whl.
File metadata
- Download URL: mage_ai-0.9.79-py3-none-any.whl
- Upload date:
- Size: 40.0 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8fc91bfa49d2fae64462c04857af8754cb9eab2a3fc302f3a287c1418934880d
|
|
| MD5 |
9d50d44c03390ed39752bac3cc0dfc85
|
|
| BLAKE2b-256 |
ea1fa45acb3fa560c66b90c53dff8d2b250bcbb8b57bdb64e1bafb6d8ad88b7a
|







