Distribution transparent Machine Learning experiments on Apache Spark



Project description







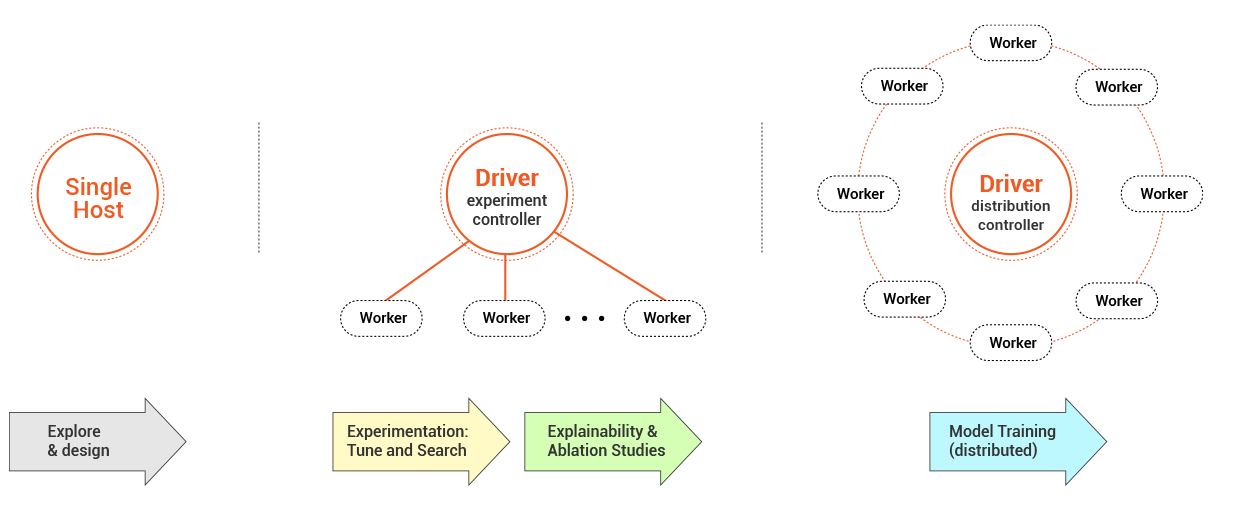
Maggy is a framework for distribution transparent machine learning experiments on Apache Spark. In this post, we introduce a new unified framework for writing core ML training logic as oblivious training functions. Maggy enables you to reuse the same training code whether training small models on your laptop or reusing the same code to scale out hyperparameter tuning or distributed deep learning on a cluster. Maggy enables the replacement of the current waterfall development process for distributed ML applications, where code is rewritten at every stage to account for the different distribution context.
Quick Start
Maggy uses PySpark as an engine to distribute the training processes. To get started, install Maggy in the Python environment used by your Spark Cluster, or install Maggy in your local Python environment with the 'spark' extra, to run on Spark in local mode:
pip install maggy
The programming model consists of wrapping the code containing the model training inside a function. Inside that wrapper function provide all imports and parts that make up your experiment.
Single run experiment:
def train_fn():
# This is your training iteration loop
for i in range(number_iterations):
...
# add the maggy reporter to report the metric to be optimized
reporter.broadcast(metric=accuracy)
...
# Return metric to be optimized or any metric to be logged
return accuracy
from maggy import experiment
result = experiment.lagom(train_fn=train_fn, name='MNIST')
lagom is a Swedish word meaning "just the right amount". This is how MAggy uses your resources.
Documentation
Full documentation is available at maggy.ai
Contributing
There are various ways to contribute, and any contribution is welcome, please follow the CONTRIBUTING guide to get started.
Issues
Issues can be reported on the official GitHub repo of Maggy.
Citation
Please see our publications on maggy.ai to find out how to cite our work.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file maggy-1.1.2.tar.gz.
File metadata
- Download URL: maggy-1.1.2.tar.gz
- Upload date:
- Size: 97.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.9.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
272f90eaa074fa57a17432ae3df7aa6b9e9e949f3ccd82962d4130d2c05a4ea2
|
|
| MD5 |
32f98397307dc4388c661f79f9a49b98
|
|
| BLAKE2b-256 |
29a4ae4d69d064ee9beaaf05c491deff814959b73dd7d8d42bfa56ac791b2acd
|







