Client library for the MariTalk API



Project description
MariTalk API
Conteúdo
- Introdução
- Compatibilidade com API da Open AI
- Instalação
- Exemplo de uso
- Exemplo de uso via requisições HTTP - JavaScript
- Exemplo de uso via requisições HTTP - C#
- Exemplo MariTalk + RAG com LangChain
- Exemplo Maritalk no LlamaIndex
- Documentação da API
Introdução
Este repositório contém o código e a documentação explicando como usar a API da MariTalk e a versão local para deploy on-premises. A MariTalk é uma assistente baseada nos modelos da família Sabiá, especialmente treinados para entender bem o português e o contexto brasileiro.
A cobrança pelo uso dos modelos é baseada no volume de tokens, considerando tanto os dados de entrada quanto os de saída.
Para tanto, acesse plataforma.maritaca.ai/recarga
Novos usuários recebem R$20 em créditos da API ao cadastrarem um cartão de crédito ou fazerem a primeira recarga (cujo valor mínimo é R$5).
A API da MariTalk é compatível com a API da Open AI
Isso significa que os modelos Sabiá podem ser utilizados em qualquer programa que use as bibliotecas da Open AI.
Para tanto, basta apontar o endpoint para https://chat.maritaca.ai/api e usar um dos modelos Sabiá.
Veja o exemplo em Python a seguir:
# Primeiro instale a biblioteca da openai, digitando este comando no terminal:
pip install openai
import openai
client = openai.OpenAI(
api_key="insira sua chave aqui. Ex: '100088...'",
base_url="https://chat.maritaca.ai/api", # ** Esta linha de código que foi trocada **
)
response = client.responses.create(
model="sabia-4", # ** Esta linha de código que foi trocada **
input="Quanto é 25 + 27?",
)
answer = response.output[0].content[0].text
print(answer) # Deve imprimir algo como "25 + 27 é 52"
Biblioteca Python da Maritaca
Instalação
Instale a biblioteca da OpenAI usando pip:
pip install openai
Opcionalmente, instale a biblioteca da Maritaca para utilitários como contagem de tokens:
pip install maritalk
Exemplo de Uso
Mostramos abaixo um exemplo simples de uso em Python. Na pasta exemplos existem mais códigos mostrando como chamar a API.
Primeiramente, você precisa de uma chave da API, que pode ser obtida em plataforma.maritaca.ai -> "Criar nova chave".
import openai
client = openai.OpenAI(
api_key="insira sua chave aqui. Ex: '100088...'",
base_url="https://chat.maritaca.ai/api",
)
response = client.responses.create(
model="sabia-4", # No momento, os modelos recomendados são sabia-4 e sabiazinho-4
input="Quanto é 25 + 27?",
)
answer = response.output[0].content[0].text
print(f"Resposta: {answer}") # Deve imprimir algo como "25 + 27 é igual a 52."
Streaming
Para tarefas de geração de texto longo, como a criação de um artigo extenso ou a tradução de um documento grande, pode ser vantajoso receber a resposta em partes, à medida que o texto é gerado, em vez de esperar pelo texto completo. Isso torna a aplicação mais responsiva e eficiente, especialmente quando o texto gerado é extenso. Oferecemos duas abordagens para atender a essa necessidade: o uso de um generator e de um async_generator.
Generator
- Ao usar
stream=True, o código irá retornar um stream de eventos. Cada evento de texto pode ser processado à medida que os tokens são produzidos.
stream = client.responses.create(
model="sabia-4",
input=messages,
max_output_tokens=200,
temperature=0.7,
stream=True,
)
for event in stream:
if event.type == "response.output_text.delta":
print(event.delta, end="", flush=True)
AsyncGenerator
Ao utilizar stream=True em conjunto com o cliente assíncrono, o código irá retornar um AsyncStream. Este tipo de stream é projetado para ser consumido de forma assíncrona, o que significa que você pode executar o código que consome o stream de maneira concorrente com outras tarefas, melhorando a eficiência do seu processamento.
import asyncio
import openai
async def consume_stream():
client = openai.AsyncOpenAI(
api_key="insira sua chave aqui. Ex: '100088...'",
base_url="https://chat.maritaca.ai/api",
)
stream = await client.responses.create(
model="sabia-4",
input=messages,
max_output_tokens=200,
temperature=0.7,
stream=True,
)
async for event in stream:
if event.type == "response.output_text.delta":
print(event.delta, end="", flush=True)
# Seu código aqui...
asyncio.run(consume_stream())
Modo chat
Você pode definir uma conversa especificando uma lista de dicionários como entrada, sendo que cada dicionário precisa ter duas chaves: content e role.
Atualmente, a API da MariTalk suporta três valores para role: "system" para mensagem de instrução do chatbot, "user" para mensagens do usuário, e "assistant" para mensagens do assistente.
Mostramos um exemplo de conversa abaixo:
messages = [
{"role": "user", "content": "sugira três nomes para a minha cachorra"},
{"role": "assistant", "content": "nina, bela e luna."},
{"role": "user", "content": "e para o meu peixe?"},
]
response = client.responses.create(
model="sabia-4",
input=messages,
max_output_tokens=200,
temperature=0.7,
)
answer = response.output[0].content[0].text
print(f"Resposta: {answer}") # Deve imprimir algo como "nemo, dory e neptuno."
Exemplos few-shot
Embora a MariTalk seja capaz de responder a instruções sem nenhum exemplo de demonstração, fornecer alguns exemplos da tarefa pode melhorar significativamente a qualidade de suas respostas.
Abaixo mostramos como isso é feito para uma tarefa simples de análise de sentimento, i.e., classificar se uma resenha de filme é positiva ou negativa. Neste caso, passaremos dois exemplos few-shot, um positivo e outro negativo, e um terceiro exemplo, para o qual a MariTalk efetivamente fará a predição.
prompt = """Classifique a resenha de filme como "positiva" ou "negativa".
Resenha: Gostei muito do filme, é o melhor do ano!
Classe: positiva
Resenha: O filme deixa muito a desejar.
Classe: negativa
Resenha: Apesar de longo, valeu o ingresso..
Classe:"""
response = client.responses.create(
model="sabia-4",
input=prompt,
max_output_tokens=20,
temperature=0.0,
)
answer = response.output[0].content[0].text
print(f"Resposta: {answer.strip()}") # Deve imprimir "positiva"
Para tarefas com apenas uma resposta correta, como no exemplo acima, é recomendado usar temperature=0.0. Isso garante que a mesma resposta seja gerada dado um prompt específico.
Para tarefas de geração de textos diversos ou longos, é recomendado usar temperature=0.7. Quanto maior a temperatura, mais diversos serão os textos gerados, mas há maior chance de o modelo "alucinar" e gerar textos sem sentido. Quanto menor a temperatura, a resposta é mais conservadora, mas corre o risco de gerar textos repetidos.
Como saber o número de tokens que serão cobrados?
Para saber de antemão o quanto suas requisições irão custar, use a função count_tokens para saber o número de tokens em um dado prompt.
Exemplo de uso:
from maritalk import count_tokens
prompt = "Com quantos paus se faz uma canoa?"
total_tokens = count_tokens(prompt, model="sabia-4")
print(f'O prompt "{prompt}" contém {total_tokens} tokens.')
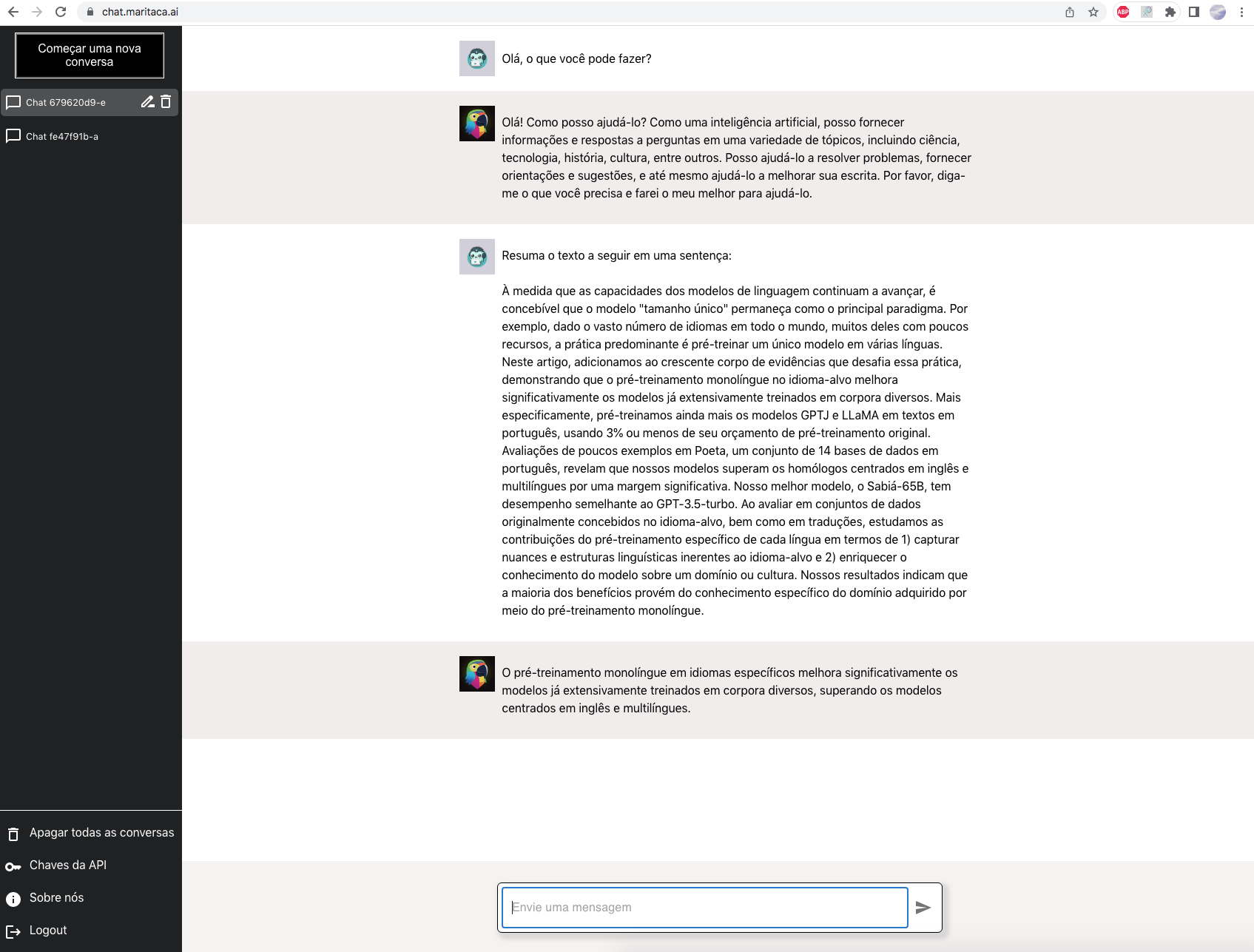
Web Chat
Teste a MariTalk via interface web em: chat.maritaca.ai
Citação
Para referenciar os modelos da família Sabiá-2, por favor, cite nosso relatório técnico.
@article{maritaca2024sabia2,
title={Sabi{\'a}-2: A New Generation of Portuguese Large Language Models},
author={Sales Almeida, Thales and Abonizio, Hugo and Nogueira, Rodrigo and Pires, Ramon},
year={2024}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file maritalk-0.3.2.tar.gz.
File metadata
- Download URL: maritalk-0.3.2.tar.gz
- Upload date:
- Size: 3.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
879c1959ad439e64f86e0eed60a72339d811c0961a9a24ee6e093d7a81ff1ea0
|
|
| MD5 |
eda6161754f0ba558c99f73b24076e84
|
|
| BLAKE2b-256 |
25775a557086e5c96cbd86dfed44f25a1adca293997cf3a27ddc19fd4538af1c
|
File details
Details for the file maritalk-0.3.2-py3-none-any.whl.
File metadata
- Download URL: maritalk-0.3.2-py3-none-any.whl
- Upload date:
- Size: 3.1 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
52cae9ebeee5a74f3fff6329207db1b803acf24691b9f9a3df63575b8fd5ac2c
|
|
| MD5 |
b82afaaac266deda7f7cc3ae2f89e06d
|
|
| BLAKE2b-256 |
cdfc1e8a98df90fc96967a75915a89361292d1fe21c9c534c2c48ff7cb514144
|







