An extensible, parser-agnostic 'include' directive for Markdown.

Project description
Markdata: Keep your data out of your markup!




Markdata is a Python library and command-line tool for managing data (e.g., code, diagrams, tables, etc.) in Markdown files. Its goal is to promote one simple rule: prose and non-prose supplements (collectively referred to as "data") should be managed separately whenever possible. The benefits of this philosophy include:
-
Adherence to the DRY principle: multiple files can include data from the same source.
-
Higher-quality data: code examples can be tested, tables can be generated directly from serialization formats, diagrams can be built from source, etc.
-
Human-friendly markup: less non-prose content means shorter files, which are easier to update and maintain.
See Fixing Markdown’s shortcomings with Python for more information.
Installation
:exclamation: Markdata requires Python >= 3.6.0. :exclamation:
$ pip install markdata
Usage
As a library
import markdata
def my_directive():
pass
markdown = markdata.markdata(
# A string or file-like object.
file_or_str,
# A dictionary of custom directives (optional).
#
# Format: {'name': my_directive}.
directives={},
# The type of front matter to parse (optional).
fm_format=None, # 'JSON', 'YAML', or 'TOML'
# The directory that paths will be resolved relative to (optional).
root=None
)
From the command line
$ markdata --help
Usage: markdata [OPTIONS] SOURCE [DESTINATION]
A flavor-agnostic extension framework for Markdown.
Reads from <SOURCE> and writes to <DESTINATION>.
If <SOURCE> is a single file, it will be converted to Markdown and written
to <DESTINATION> (default: stdout).
If <SOURCE> is a directory, all child Markdata files will be converted to
Markdown and written to <DESTINATION> (default: overwrite <SOURCE>).
Options:
--fm-type [JSON|YAML|TOML] The type of front matter to parse.
--root PATH The directory that paths will be resolved
relative to.
--directives PATH The directory containing your custom directives.
--version Show the version and exit.
--help Show this message and exit.
Directives
Markdata's functionality is driven by directives, which are Markdown snippets that invoke Python functions. Directives can be defined in two ways:
# Example directives
<!-- This is a "block" directive -->
```callout{'title': 'NOTE', 'classes': ['warning']}
This is a callout message.
```
<!-- This is an "inline" directive -->
`table{'path': '../data/table.yml', 'classes': ['table'], 'caption': 'My data'}`
The table directive creates an HTML table from a YAML, JSON, or CSV file (with an optional caption and classes). After calling markdata on this file, the output would be something along the lines of:
<table class="table">
<caption>My data</caption>
<thead>
<!-- headers -->
</thead>
<tbody>
<!-- rows -->
</tbody>
</table>
Built-in directives
Markdata has a few built-in, general-purpose directives:
def table(path: str, classes: List[str] = [], caption: str = "") -> str:
"""Return an HTML table built from structured data (CSV, JSON, or YAML).
`path` [required]: A path (relative to the directive-containing file) to a
CSV, JSON, or YAML file.
`classes` [optional]: A list of HTML classes to apply to the table.
`caption` [optional]: A caption for the table.
Example:
`table{'path': 'table.yml', 'classes': ['table'], 'caption': '...'}`
"""
The table directive (discussed above) creates an HTML table from an external data source (CSV, JSON, or YAML). This allows you to avoid having to write and maintain tables in raw Markdown or HTML.
def document(path: str, span: Tuple[int, int] = []) -> str:
"""Return the contents of a document (or part of it).
`path` [required]: A path (relative to the directive-containing file) to a
local file.
`span` [optional]: A tuple ([begin, end]) indicating the beginning and
ending line of the snippet (defaults to the entire file).
Example:
`document{'path': 'my_file.py', 'span': (10, 13)}`
"""
The document directive includes the content of an external text file (of any type—Markdown, Python, etc.).
def code(front_matter, path, span=[], lang=None):
"""Return the contents of a document (or part of it) as a code block.
`path` [required]: A path (relative to the directive-containing file) to a
local file.
`span` [optional]: A tuple ([begin, end]) indicating the beginning and
ending line of the snippet (defaults to the entire file).
`lang` [optional]: The code block's info string. If not defined, it will be
inferred from the given file extension.
Example:
`code{'path': 'my_file.py', 'span': [10, 13], 'lang': 'python'}`
"""
The code directive includes the content of an external source code formatted as a fenced code block. This allows you to, for example, write your code examples in their own files (which can be properly tested and linted).
Writing your own
NOTE: The first argument passed to custom directives will be a dictionary created from the file's front matter (
{}by default).
While table and document attempt to solve the most common needs, the true power of Markdata comes from leveraging Python in your own directives.
There are three steps to creating a directive:
-
Design your directive definition: Choose either an inline or block directive and decide what arguments it'll accept.
-
Write a Python function: This function needs to accept the arguments defined in step (1). So, if you were re-implementing the built-in
tabledirective, you'd have a directive definition oftable{'path': '../data/table.yml', 'classes': ['table'], 'caption': 'My data'}and a function definition oftable(fm: Dict, path: str, classes: List[str] = [], caption: str = "") -> str:. When using block directives, the first argument passed to the backend function is its content (see our admonition example). -
Associate your directive with your function:
- Using the library:
# When using Markdata as a library, you simply pass your function to `markdata`: import markdata def implementation(path): pass markdown = markdata.markdata(file_or_str, directives={'directive': implementation})
- Using the command-line tool: Markdata will associate all Python modules with their
mainfunction found in the directory passed to--directives='my_dir'.
Check out our test cases for some examples.
Converters
Converters are utilities that you can import and use in your own directives.
# from markdata.converters import to_html_table
def to_html_table(
rows: List[List[str]], caption: str = "", classes: List[str] = []
) -> str:
"""Convert the given rows into an HTML table.
The first entry in `rows` will be used as the table headers.
"""
FAQ
Why only Markdown? What about AsciiDoc and reStructuredText?
AsciiDoc and reStructuredText have more feature-rich syntaxes than Markdown. Many of Markdata's features are available out-of-the-box (in some form) in AsciiDoc and reStructuredText.
That said, Markdown has a much larger ecosystem of parsers (practically every language has a native Markdown library), editors (and editor plugins), linters, and static site generators than both AsciiDoc and reStructuredText.
Markdata's goal is to enrich Markdown's syntax without hurting its portability (see the next question).
What "flavors" of Markdown does Markdata support?
All of them.
One of the common complaints about Markdown is that many of its best features are tied to a particular "flavor" (see Babelmark) that may not be compatible with other Markdown-related tooling.
Markdata avoids this problem by acting as more of a "preprocessor" (i.e., Markdata + Markdown <=> Sass + CSS) than another Markdown implementation. Its users have full control over what it outputs—meaning that they can choose to output raw HTML (effectively bypassing the problem of flavors altogether) or make use of features limited to their favorite flavor:
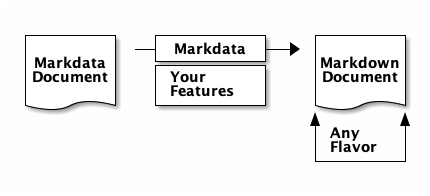
What if I'm already using a static site generator (SSG)?
While many SSGs have built-in support for external data sources (e.g., Jekyll, Hugo, and Gatsby), there are still benefits to using Markdata:
-
As dicussed in the previous question, Markdata doesn't introduce new Markdown syntax—meaning Markdata directives can be used with any SSG that supports Markdown. This means that you can change SSGs without having to update the syntax (i.e., template language) for accessing your data.
-
Markdata's ability to manage data is far more powerful than what most SSGs offer: instead of merely iterating over static resource files, you have full access to Python and its library ecosystem. So, for example, you can
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file markdata-0.5.2.tar.gz.
File metadata
- Download URL: markdata-0.5.2.tar.gz
- Upload date:
- Size: 12.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.7.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
295d9b4786ce321a9ff1b993021619484e2a156a7d00fc842016d6061df0777c
|
|
| MD5 |
3802d8fae42ee02166772a934ee73aad
|
|
| BLAKE2b-256 |
eee489bab1d448a5886f5e97b086f693d8a4d52b2d79b0105625959ac91c4f74
|
File details
Details for the file markdata-0.5.2-py2.py3-none-any.whl.
File metadata
- Download URL: markdata-0.5.2-py2.py3-none-any.whl
- Upload date:
- Size: 13.0 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.7.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9bc51eb08441c45ac7498a746ac7bb0258f89ea61a971201265341aac0cad55a
|
|
| MD5 |
1cbb8b631cd2de29c9e6f804ffef240c
|
|
| BLAKE2b-256 |
bf10c8bc29b8de61bc4dcf096a030ad495115f23108af1d170f2c87801a566d8
|







