3-rd party plugin for markitdown library. It is to be used for converting a pdf to markdown purely based on llm's capability

Project description
markitdown-advanced-pdf-llm-plugin
Overview
markitdown-advanced-pdf-llm-plugin is a plugin for the MarkItDown library, specifically engineered for extracting the knowledge out of complex multi-modal PDF documents which is non-text heavy. This plugin addresses the challenges of reduced LLM output quality on large multi-modal documents by leveraging higher intelligence Large Language Models (LLMs) to interpret/extract knowledge out of these documents.
Why MarkItDown
MarkItDown is a lightweight Python utility for converting various files to Markdown for use with LLMs and related text analysis pipelines. Markdown is extremely close to plain text, with minimal markup or formatting, but still provides a way to represent important document structure. Mainstream LLMs, such as OpenAI's GPT-4o, natively "speak" Markdown, and often incorporate Markdown into their responses unprompted. This suggests that they have been trained on vast amounts of Markdown-formatted text, and understand it well. As a side benefit, Markdown conventions are also highly token-efficient.
Why markitdown-advanced-pdf-llm-plugin
- Token efficiency: When involving Multi-Modal document in RAG, text only capabilities consume less token than multi-modal capabilities
- RAG output quality: The quality of LLMs output degrades as input token increases. Passing several pages of multi-modal document at once can lead to poor LLM summarization than several pages of text documents
- Latency: Text only input has lesser latency than multi-modal input
What it does?
SimpleLLMKnowledgeExtractor
- Converts each PDF page to both a standalone PDF and an image
- prompts LLM (presently only OpenAI Client) to extract all text, tables, and picture information
- Processes pages concurrently for improved performance
- Generates a complete markdown document with both extracted content and adds page image
Future Extractor (In Progress)
Current approach of sending full pages to LLMs sometimes results in incomplete extraction or information loss. Future extractor's goal is to
- Make the extraction more deterministic by extracting each element (text, table and picture) using libraries like PyMuPDF4LLM
- Validate the deterministic extraction performed well using LLM
- Apply LLM extraction if needed
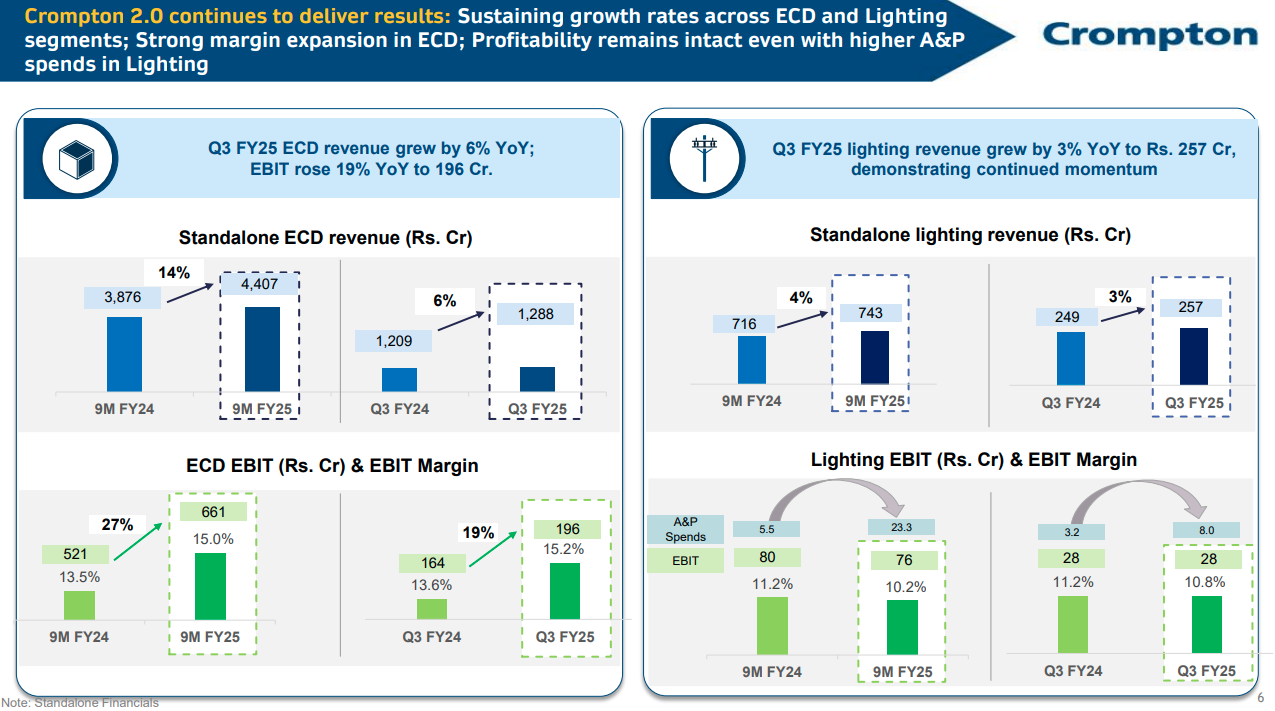
Example page from a document where this plugin is beneficial
Installation
The plugin is available for installation through pip
pip install markitdown-advanced-pdf-llm-plugin
Usage
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI(api_key="openai-key")
md = MarkItDown(enable_plugins=True, llm_client=openai_client, llm_model="prefered-model") # Incase custom prompt, use arg 'llm_prompt'
result = md.convert("doc.pdf")
markdown_content = result.markdown
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file markitdown_advanced_pdf_llm_plugin-0.1.1.tar.gz.
File metadata
- Download URL: markitdown_advanced_pdf_llm_plugin-0.1.1.tar.gz
- Upload date:
- Size: 7.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
19efbc8c94d440c8617f3ffe8f46b57f4fbfa8e93603bc252941d100bf09bfc8
|
|
| MD5 |
adaa6a4b4de511a816dbf32c2c28c5d8
|
|
| BLAKE2b-256 |
d87aee13f40c3adfb20bd81673b75c13a705425fe024a3c1ba0b1c6178dde373
|
File details
Details for the file markitdown_advanced_pdf_llm_plugin-0.1.1-py3-none-any.whl.
File metadata
- Download URL: markitdown_advanced_pdf_llm_plugin-0.1.1-py3-none-any.whl
- Upload date:
- Size: 7.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1cc4a33be2c21e485277c6e7566e97c2bfd741b45722429c44084820aeb9dc23
|
|
| MD5 |
e87cca9de01d6ef13dbea4e6bc591648
|
|
| BLAKE2b-256 |
5342dc0615c8cb2189b7b54bbe5b3c2104a704dbddf8ff444ace8efb447ce1a1
|







