A Model Compression Toolkit for neural networks

Project description






Getting Started
Quick Installation
Pip install the model compression toolkit package in a Python>=3.9 environment with PyTorch>=2.3 or Tensorflow>=2.14.
pip install model-compression-toolkit
For installing the nightly version or installing from source, refer to the installation guide.
Important note: In order to use MCT, you’ll need to provide a pre-trained floating point model (PyTorch/Keras) as an input.
Tutorials and Examples
Our tutorials section will walk you through the basics of the MCT tool, covering various compression techniques for both Keras and PyTorch models. Access interactive notebooks for hands-on learning with popular models/tasks or move on to Resources section.
Supported Quantization Methods
MCT supports various quantization methods as appears below.
| Quantization Method | Complexity | Computational Cost | API | Tutorial |
|---|---|---|---|---|
| PTQ (Post Training Quantization) | Low | Low (~1-10 CPU minutes) | PyTorch API / Keras API |   |
| GPTQ (parameters fine-tuning using gradients) | Moderate | Moderate (~1-3 GPU hours) | PyTorch API / Keras API |  |
| QAT (Quantization Aware Training) | High | High (~12-36 GPU hours) | QAT API | |
For each flow, Quantization core utilizes various algorithms and hyper-parameters for optimal hardware-aware quantization results. For further details, please see Supported features and algorithms.
Required input: Pre-trained floating point model (PyTorch/Keras)
Optional input: Representative dataset - can be either provided by the user, or generated utilizing the Data Generation capability

High level features and techniques
MCT offers a range of powerful features to optimize models for efficient edge deployment. These supported features include:
Quantization Core Features
🏆 Mixed-precision search 
📈 Graph optimizations. Transforming the model to be best fitted for quantization process.
🔎 Quantization parameter search
🧮 Advanced quantization algorithms
Hardware-aware optimization
🎯 TPC (Target Platform Capabilities). Describes the target hardware’s constrains, for which the model optimization is targeted. See TPC Readme for more information.
Data-free quantization (Data Generation)
Generates synthetic images based on the statistics stored in the model's batch normalization layers, according to your specific needs, for when image data isn’t available. See Data Generation Library for more. The specifications of the method are detailed in the paper: "Data Generation for Hardware-Friendly Post-Training Quantization" [5].
Structured Pruning
Reduces model size/complexity and ensures better channels utilization by removing redundant input channels from layers and reconstruction of layer weights. Read more (Pytorch API / Keras API).
Debugging and Visualization
🎛️ Network Editor (Modify Quantization Configurations)
🖥️ Visualization. Observe useful information for troubleshooting the quantized model's performance using TensorBoard. Read more.
🔑 XQuant (Explainable Quantization)
🔑 XQuant Extension Tool. Calculates the error for each layer by comparing the float model and quantized model, using both models along with the quantization log. The results are presented in reports. It identifies the causes of the detected errors and recommends appropriate improvement measures for each cause. Read more Troubleshoot Manual
Enhanced Post-Training Quantization (EPTQ)
As part of the GPTQ capability, we provide an advanced optimization algorithm called EPTQ. The specifications of the algorithm are detailed in the paper: "EPTQ: Enhanced Post-Training Quantization via Hessian-guided Network-wise Optimization" [4]. More details on how to use EPTQ via MCT can be found in the GPTQ guidelines.
Resources
-
User Guide contains detailed information about MCT and guides you from installation through optimizing models for your edge AI applications.
-
MCT's API Docs is separated per quantization methods:
- Post-training quantization | PTQ API docs
- Gradient-based post-training quantization | GPTQ API docs
- Quantization-aware training | QAT API docs
-
Debug – modify optimization process or generate an explainable report
Supported Versions
Currently, MCT is being tested on various Python, Pytorch and TensorFlow versions:
Supported Versions Table
| PyTorch 2.3 | PyTorch 2.4 | PyTorch 2.5 | PyTorch 2.6 | |
|---|---|---|---|---|
| Python 3.9 |  |
 |
 |
 |
| Python 3.10 |  |
 |
 |
 |
| Python 3.11 |  |
 |
 |
 |
| Python 3.12 |  |
 |
 |
 |
| TensorFlow 2.14 | TensorFlow 2.15 | |
|---|---|---|
| Python 3.9 |  |
 |
| Python 3.10 |  |
 |
| Python 3.11 |  |
 |
Results

MCT can quantize an existing 32-bit floating-point model to an 8-bit fixed-point (or less) model without compromising accuracy. Below is a graph of MobileNetV2 accuracy on ImageNet vs average bit-width of weights (X-axis), using single-precision quantization, mixed-precision quantization, and mixed-precision quantization with GPTQ.
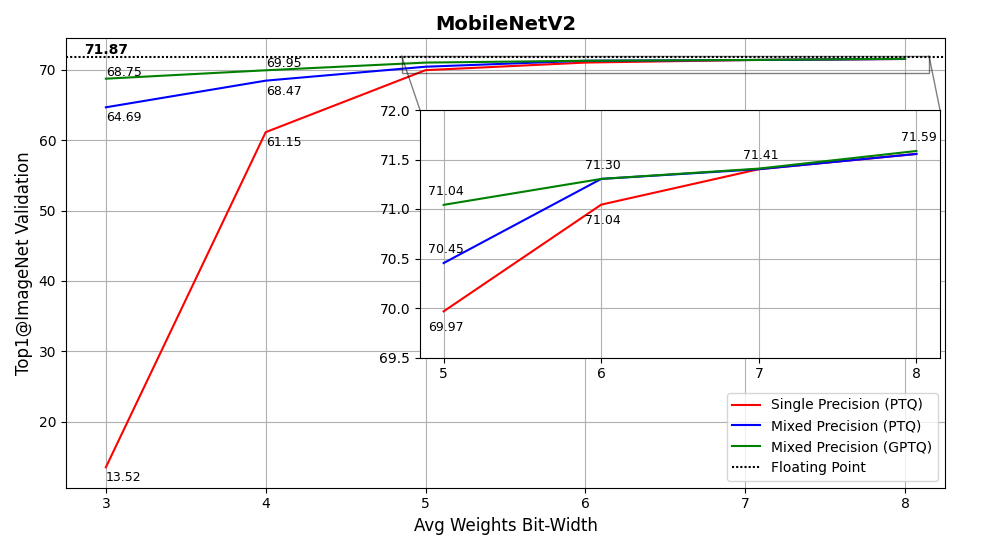
For more results, please see [1]
Pruning Results
Results for applying pruning to reduce the parameters of the following models by 50%:
| Model | Dense Model Accuracy | Pruned Model Accuracy |
|---|---|---|
| ResNet50 [2] | 75.1 | 72.4 |
| DenseNet121 [3] | 74.44 | 71.71 |
Troubleshooting and Community
If you encountered a large accuracy degradation with MCT, check out the Quantization Troubleshooting for common pitfalls and some tools to improve the quantized model's accuracy.
Check out the FAQ for common issues.
You are welcome to ask questions and get support on our issues section and manage community discussions under the discussions section.
Contributions
We'd love your input! MCT would not be possible without help from our community, and welcomes contributions from anyone!
*Checkout our Contribution guide for more details.
Thank you 🙏 to all our contributors!
License
MCT is licensed under Apache License Version 2.0. By contributing to the project, you agree to the license and copyright terms therein and release your contribution under these terms.
References
[1] Habi, H.V., Peretz, R., Cohen, E., Dikstein, L., Dror, O., Diamant, I., Jennings, R.H. and Netzer, A., 2021. HPTQ: Hardware-Friendly Post Training Quantization. arXiv preprint.
[4] Gordon, O., Cohen, E., Habi, H.V., Netzer, A. (2025). EPTQ: Enhanced Post-Training Quantization via Hessian-guided Network-wise Optimization – ECCV 2024 Workshops
[5] Dikstein, L., Lapid, A., Netzer, A., & Habi, H. V., 2024. Data Generation for Hardware-Friendly Post-Training Quantization, Accepted to IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2025
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mct_nightly-2.4.2.20251002.523.tar.gz.
File metadata
- Download URL: mct_nightly-2.4.2.20251002.523.tar.gz
- Upload date:
- Size: 550.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c21f046a8e49b0199f391496fb53bf8af6877593ebeb99c6f7bb3ffd27d8641c
|
|
| MD5 |
54e12877495a00ec799ebf6e73a9c828
|
|
| BLAKE2b-256 |
2dea483c969206279bce30e477a7357acc93a78d46c0de65f1a4863cb648373f
|
File details
Details for the file mct_nightly-2.4.2.20251002.523-py3-none-any.whl.
File metadata
- Download URL: mct_nightly-2.4.2.20251002.523-py3-none-any.whl
- Upload date:
- Size: 1.0 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
39d9c26839046b50d9dd2404d982fc3cda16546fcd896a06d9d9bdc12de1c8a4
|
|
| MD5 |
5855707ca2f8f7bc4bb630f9eddc393b
|
|
| BLAKE2b-256 |
51556c587fd53453ad64fed6246a230da84ee72004d2cc6f356208223991bafb
|







