High-speed, high-accuracy, local OCR for Japanese video games.

Project description
meikiocr




high-speed, high-accuracy, local ocr for japanese video games.
meikiocr is a python-based ocr pipeline that combines state-of-the-art detection and recognition models to provide an unparalleled open-source solution for extracting japanese text from video games and similar rendered content.
| original image | ocr result |
|---|---|
 |
 |
ナルホド
こ、こんなにドキドキするの、
小学校の学級裁判のとき以来です。
live demo
the easiest way to see meikiocr in action is to try the live demo hosted on hugging face spaces. no installation required!
try the meikiocr live demo here
core features
- high accuracy: purpose-built and trained on japanese video game text,
meikiocrsignificantly outperforms general-purpose ocr tools like paddleocr or easyocr on this specific domain. - high speed: the architecture is pareto-optimal, delivering exceptional performance on both cpu and gpu.
- fully local & private: unlike cloud-based services,
meikiocrruns entirely on your machine, ensuring privacy and eliminating api costs or rate limits. - cross-platform: it works wherever onnx runtime runs, providing a much-needed local ocr solution for linux users.
- open & free: both the code and the underlying models are freely available under permissive licenses.
performance & benchmarks
meikiocr is built from two highly efficient models that establish a new pareto front for japanese text recognition. this means they offer a better accuracy/latency tradeoff than any other known open-weight model.
| detection (cpu) | detection (gpu) |
|---|---|
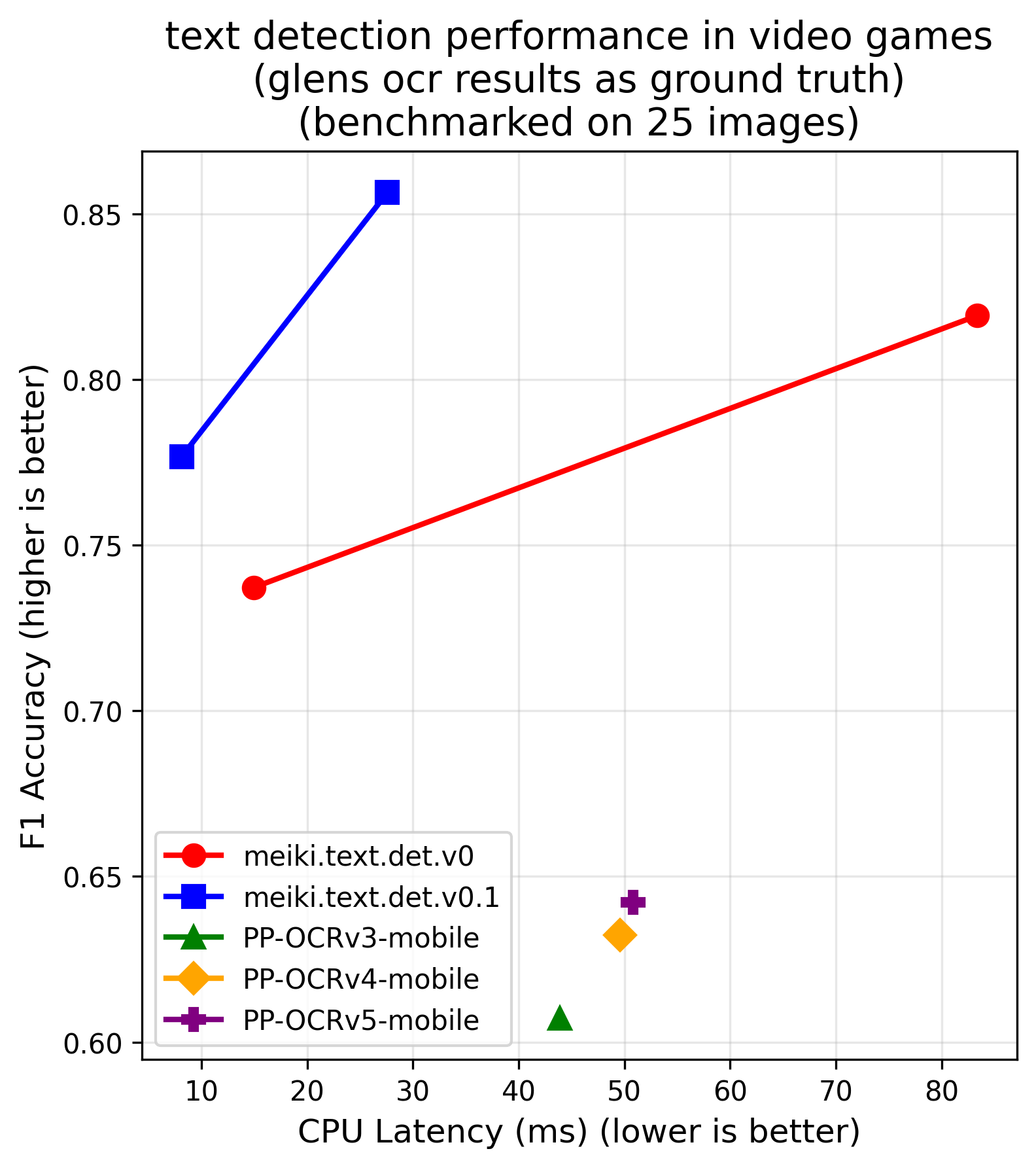 |
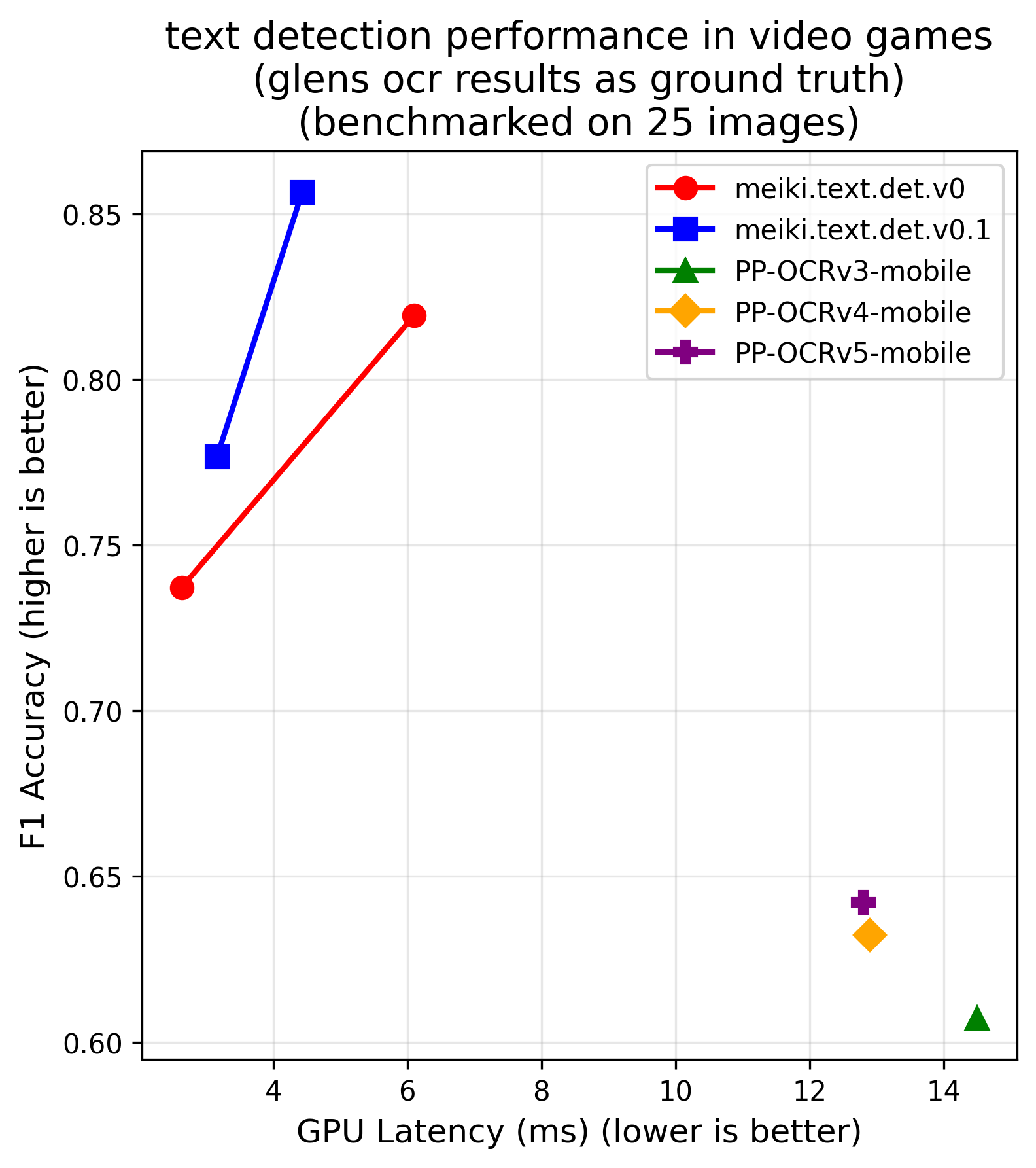 |
| recognition (cpu) | recognition (gpu) |
|---|---|
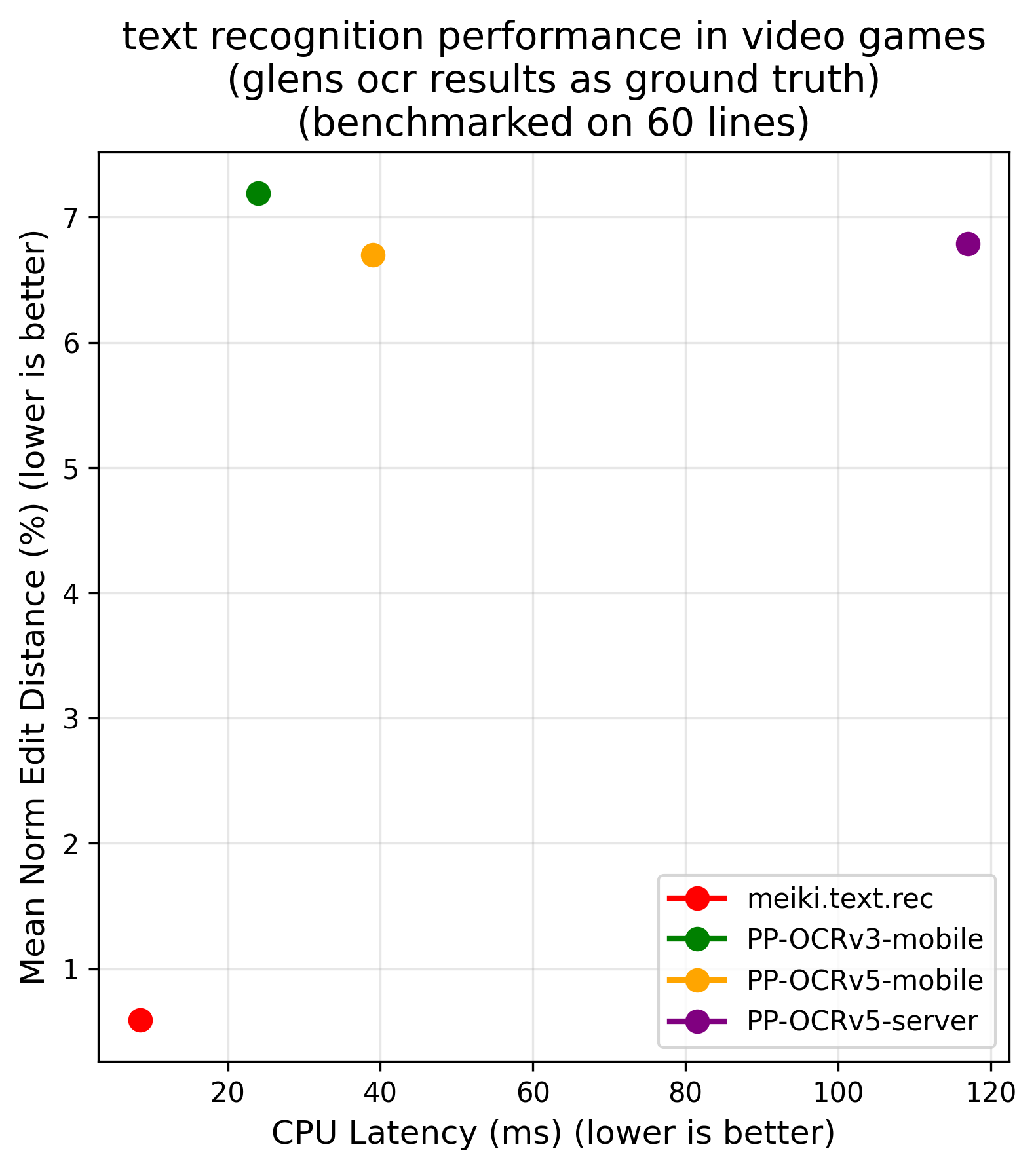 |
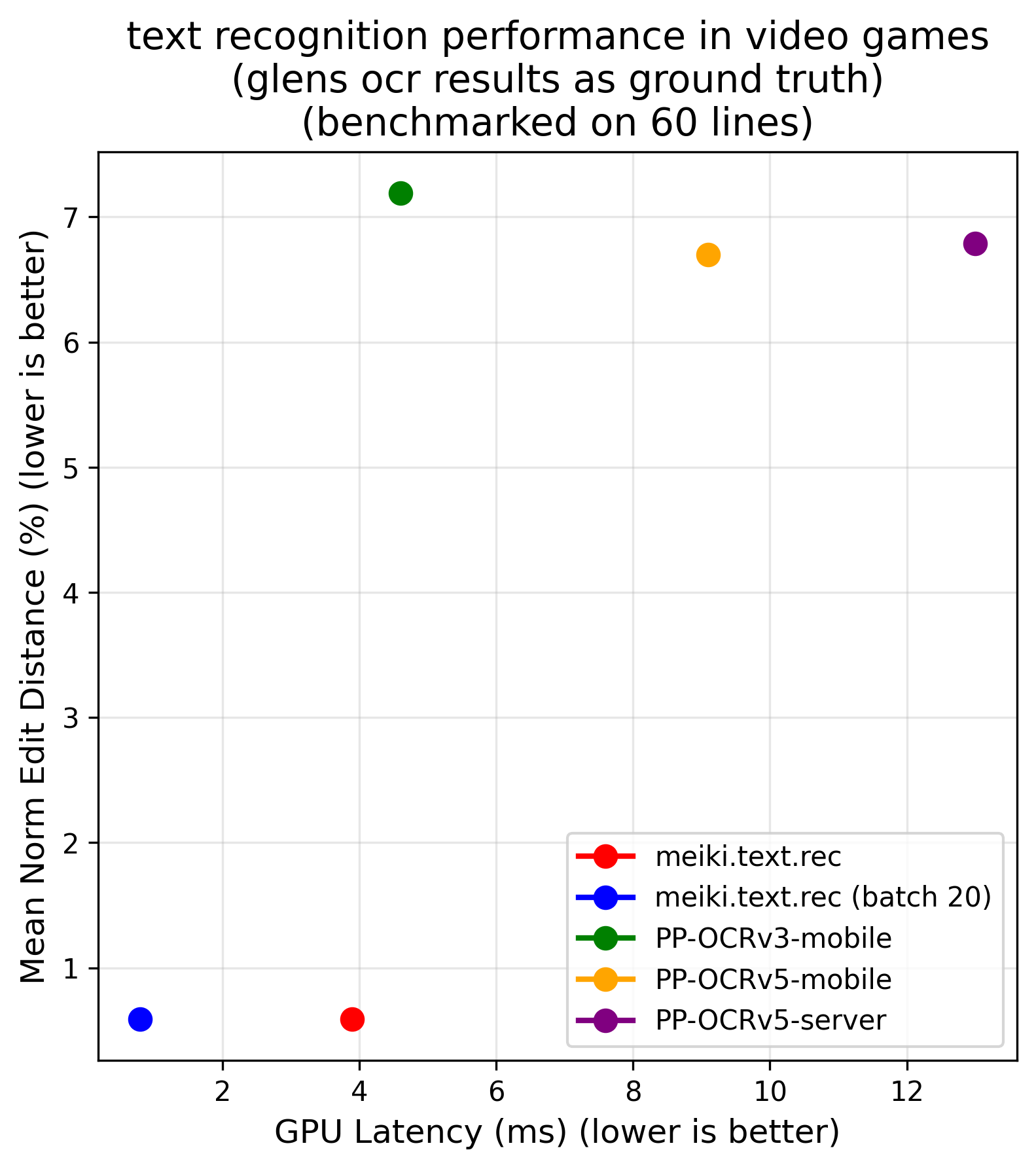 |
installation
the script is designed to be easy to run. first, clone the repository and install the required packages.
git clone https://github.com/your-github-username/meikiocr.git
cd meikiocr
pip install -r requirements.txt
for nvidia gpu users (recommended)
for a massive performance boost, you can install the gpu-enabled version of onnx runtime. this will be detected automatically by the script.
# first, uninstall the cpu version if it's already installed
pip uninstall onnxruntime
# then, install the gpu version
pip install onnxruntime-gpu
usage
run the pipeline by providing the path to an image.
python meiki_ocr.py examples/input.jpg
this will generate three output files in the same directory:
input_ocrresult.jpg: a copy of the input image with character bounding boxes drawn on it.input_ocrresult.json: a structured file containing the recognized text and detailed information for each character, including its bounding box and confidence score.input_ocrresult.txt: a plain text file with just the recognized lines.
adjusting thresholds
you can adjust the confidence thresholds for both the text line detection and the character recognition models. lowering the thresholds results in more detected text lines and characters, while higher values prevent false positives.
# example with lower thresholds
python meiki_ocr.py examples/input.jpg --det_threshold 0.3 --rec_threshold 0.05
how it works
meikiocr is a two-stage pipeline:
- text detection: the meiki.text.detect.v0 model first identifies the bounding boxes of all horizontal text lines in the image.
- text recognition: each detected text line is then cropped and processed in a batch by the meiki.text.recognition.v0 model, which recognizes the individual characters within it.
limitations
while meikiocr is state-of-the-art for its niche, it's important to understand its design constraints:
- domain specific: it is highly optimized for rendered text from video games and may not perform well on handwritten or complex real-world scene text.
- horizontal text only: it does not currently support vertical text.
- architectural limits: the detection model is capped at finding 64 text boxes, and the recognition model can process up to 48 characters per line. these limits are sufficient for over 99% of video game scenarios but may be a constraint for other use cases.
advanced usage & potential
the meiki_ocr.py script provides a straightforward implementation of a post-processing pipeline that selects the most confident prediction for each character. however, the raw output from the recognition model is richer and can be used for more advanced applications. for example, one could build a language-aware post-processing step using n-grams to correct ocr mistakes by considering alternative character predictions.
this opens the door for meikiocr to be integrated into a variety of projects.
license
this project is licensed under the apache 2.0 license. see the license file for details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file meikiocr-0.1.0.tar.gz.
File metadata
- Download URL: meikiocr-0.1.0.tar.gz
- Upload date:
- Size: 11.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9e0095f61a63dc6a451b62f9cfb9acca8c6cf92fbde8275a0e14514159ea0b9f
|
|
| MD5 |
2e0e11f60a94a39228a45e8009bd38fb
|
|
| BLAKE2b-256 |
11a55ea1e3d5a7983bb4711de610770c43e9b156cc0e384b427d4e1cdda3e3e3
|
File details
Details for the file meikiocr-0.1.0-py3-none-any.whl.
File metadata
- Download URL: meikiocr-0.1.0-py3-none-any.whl
- Upload date:
- Size: 11.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
19910b161a6392c7fa878308acf0209e63b1e9aa108897f037e2825576c0026c
|
|
| MD5 |
4bdbbf9e22b4b7b98ea4081c2184e10e
|
|
| BLAKE2b-256 |
69e668ae748be56a56726a1658cf104a6efb4127dc7306121c68490850aa16de
|







