CrewAI tools and integration for Memanto's persistent memory

Project description
CrewAI + Memanto: Persistent Multi-Agent Memory
This package provides CrewAI tools for integrating Memanto's persistent, cross-agent memory capabilities into your CrewAI pipelines.
Installation
pip install memanto-crewai
A real-world example of CrewAI agents using Memanto as their shared, persistent memory layer. Two agents collaborate through a semantic memory database that survives across sessions, agents, and runs.
What This Demonstrates
- Cross-agent memory sharing: A Research Agent stores findings that a Writer Agent retrieves
- Cross-session persistence: Run the researcher today, run the writer tomorrow -- memories persist
- Typed semantic memory: 13 memory types (fact, observation, decision, etc.) with confidence scoring
- Contradictory memory handling: Detect and resolve conflicting facts (bonus)
Architecture
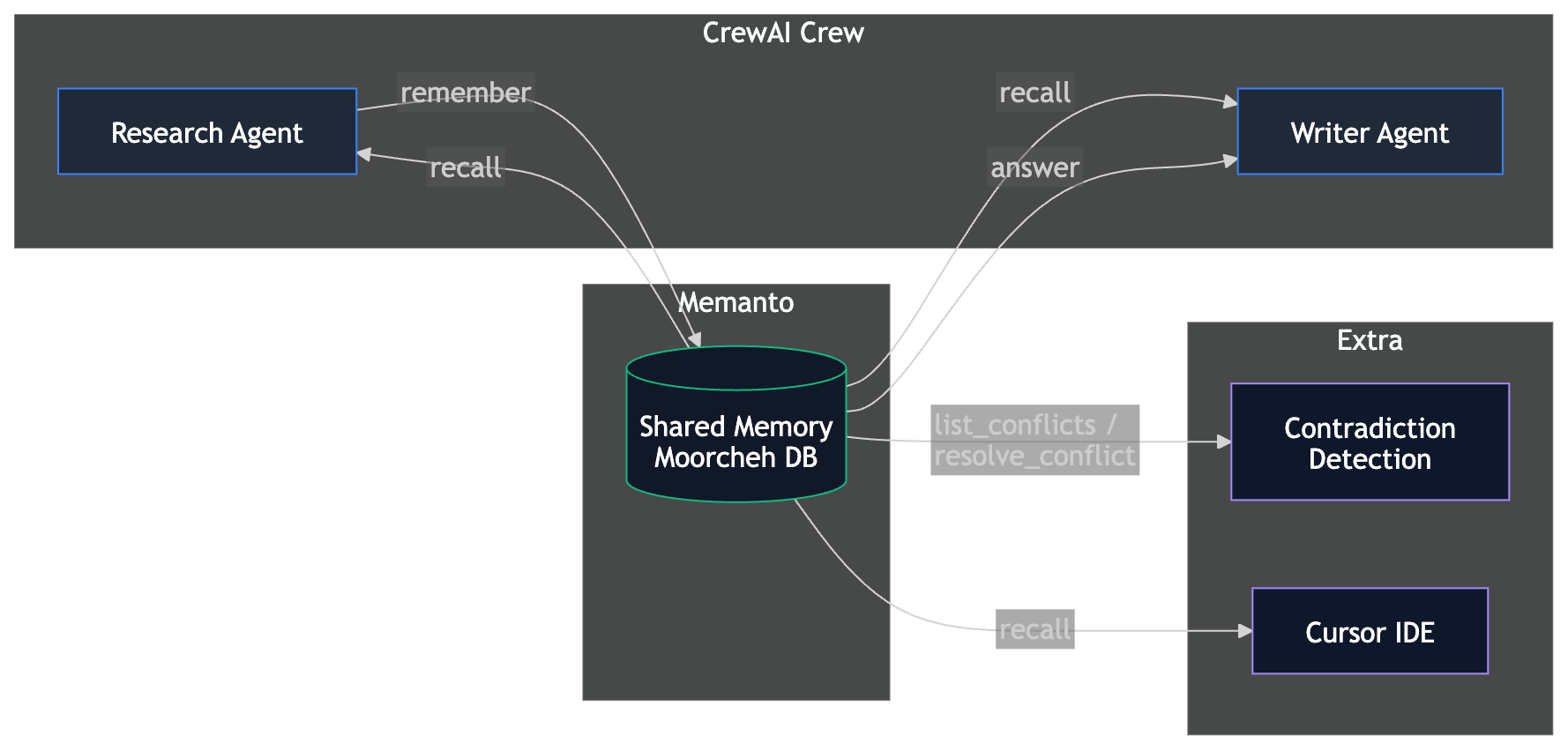
Both CrewAI agents share the same Memanto agent ID (crewai-research-team), giving them access to a shared memory namespace.
Prerequisites
- Python 3.10+
- A Moorcheh API key (free tier: 100K ops/month)
- An OpenRouter API key (for CrewAI's LLM — free tier available)
Setup
# 1. Clone the repo (if you haven't already)
git clone https://github.com/moorcheh-ai/memanto.git
cd memanto/examples/crewai-memory
# 2. Create a virtual environment
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 3. Install dependencies
pip install -r requirements.txt
# 4. Configure API keys
cp .env.example .env
# Edit .env and add your MOORCHEH_API_KEY and OPENROUTER_API_KEY
Quick Start
Run the full pipeline (Research Agent + Writer Agent) in one command:
python run_full_pipeline.py
Step-by-Step Demo (Proves Persistence)
This is the recommended flow for your terminal recording:
# Step 1: Research Agent stores findings in Memanto
python run_research.py
# Step 2: Writer Agent retrieves those memories in a NEW session
# (This proves memories persist across sessions!)
python run_writer.py
# Step 3 (Bonus): Demonstrate contradictory memory handling
python run_contradiction.py
Architecture: Why Tool-Based Integration?
CrewAI offers two ways to plug in external memory:
-
Native
StorageBackendoverride — Implement CrewAI'sStorageBackendprotocol and pass it viaMemory(storage=my_backend). CrewAI's memory pipeline (LLM analysis, consolidation, composite scoring) runs on top of your backend. -
Tool-based integration — Provide Memanto operations as CrewAI tools that agents call directly.
This example uses the tool-based approach. Here's why:
-
API mismatch: CrewAI's
StorageBackend.search()receives a pre-computed vector embedding. By the time it reaches the storage layer, the original query text is lost. Memanto's API performs semantic search from natural language text, not raw vectors. There's no clean way to bridge this gap without redundant embedding work or losing Memanto's search quality. -
Rich metadata: The tool-based approach lets the LLM choose the right memory type (out of 13 semantic types), set confidence scores, and add tags at write time. A native backend override only receives what CrewAI's encoding pipeline extracts, which doesn't map to Memanto's type system.
-
No dual memory risk: We explicitly set
memory=Falseon all Crews to prevent CrewAI from injecting its own LanceDB-backed memory tools alongside the Memanto tools. Whenmemory=True, CrewAI auto-injects "Search memory" and "Save to memory" tools into every agent — running both systems would cause duplicate storage and retrieval confusion.
Note: Native
StorageBackendintegrations (like Hindsight or Mengram) work well when the external system accepts vector embeddings directly. Memanto's information-theoretic search operates on text, making the tool-based pattern the better fit.
Namespace Design
All CrewAI agents in this example share a single Memanto agent ID (crewai-research-team), which maps to one Memanto namespace. This is intentional: the Research Agent stores findings and the Writer Agent retrieves them from the same namespace. Memanto's scope system (memanto_agent_{agent_id}) provides the isolation boundary — different crews or projects should use different agent IDs.
How to Swap CrewAI Memory for Memanto
Before: CrewAI's Built-in Memory
from crewai import Crew
# CrewAI's built-in memory uses LanceDB locally
# When memory=True, CrewAI auto-injects "Search memory" and
# "Save to memory" tools into every agent
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
memory=True, # Uses LanceDB, lost when storage is cleared
)
After: Memanto Memory (Persistent)
from memanto.cli.client.sdk_client import SdkClient
from memanto_crewai import MemantoSetup, create_memanto_tools
# 1. Set up Memanto (one-time per session)
setup = MemantoSetup(api_key="your-moorcheh-key")
client = setup.setup(agent_id="my-crew")
# 2. Create memory tools bound to your agent
tools = create_memanto_tools(client, agent_id="my-crew")
# 3. Give agents Memanto tools instead of using memory=True
researcher = Agent(
role="Researcher",
goal="Research and store findings",
backstory="...",
tools=[tools["remember"], tools["recall"]], # Persistent memory!
)
writer = Agent(
role="Writer",
goal="Retrieve findings and write",
backstory="...",
tools=[tools["recall"], tools["answer"]], # Reads persistent memory!
)
# 4. Run the crew with memory=False to prevent dual memory systems
crew = Crew(
agents=[researcher, writer],
tasks=[...],
memory=False, # Memanto handles memory via tools
)
crew.kickoff()
Key differences:
| Feature | CrewAI Memory | Memanto Memory |
|---|---|---|
| Persistence | Session only | Permanent |
| Cross-agent | Same crew only | Any agent, any session |
| Search | Embedding-based | Semantic (Moorcheh) |
| Memory types | Untyped | 13 semantic types |
| Confidence scoring | No | Yes (0.0-1.0) |
| Conflict detection | No | Yes |
| Cost at idle | N/A | Zero (serverless) |
File Structure
examples/crewai-memory/
├── README.md # This file
├── requirements.txt # Python dependencies
├── .env.example # API key template
├── memanto_tools.py # CrewAI Tool wrappers around Memanto SdkClient
├── agents.py # Research Agent + Writer Agent definitions
├── tasks.py # Task definitions
├── crew.py # Crew orchestration factories
├── run_research.py # Run 1: Research Agent stores findings
├── run_writer.py # Run 2: Writer Agent recalls (proves persistence)
├── run_full_pipeline.py # Full pipeline in one run
└── run_contradiction.py # Bonus: contradictory memory handling
Bonus: Cursor Integration
After running the CrewAI pipeline, you can access the same memories from Cursor:
# Connect Cursor to Memanto globally (all projects)
memanto connect cursor --global
# Or for a specific project directory
memanto connect cursor --project-dir /path/to/your/project
This creates .cursor/rules/memanto.mdc (memory instructions) and .cursor/skills/memanto/SKILL.md (memory type guide). Open any project in Cursor and ask it to recall your research findings -- it accesses the same Memanto memory namespace used by the CrewAI agents.
Example Cursor prompt after running the CrewAI pipeline:
"Use memanto recall to find what the research team stored about AI agent market size"
Troubleshooting
- "MOORCHEH_API_KEY not set": Copy
.env.exampleto.envand add your key - "No active session": The setup manager handles this automatically; check your API key is valid
- "Agent already exists": This is normal -- the setup reuses existing agents
- CrewAI LLM errors: Ensure
OPENROUTER_API_KEYis set, or override withCREWAI_LLMenv var
Learn More
- Memanto Documentation
- CrewAI Documentation
- Moorcheh API Keys
- OpenRouter — unified LLM gateway (free tier available)
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file memanto_crewai-0.1.0.tar.gz.
File metadata
- Download URL: memanto_crewai-0.1.0.tar.gz
- Upload date:
- Size: 7.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
229e967bb64c4bed4d6cf93d94cb733772866e8eed2696766c236bb84adf3243
|
|
| MD5 |
7cf6d794ac98fdc26f6a4350987efb9b
|
|
| BLAKE2b-256 |
fe8a6bcc157d8680e001f0e1e22429dbb992f1ed069c945445532731c31f271a
|
File details
Details for the file memanto_crewai-0.1.0-py3-none-any.whl.
File metadata
- Download URL: memanto_crewai-0.1.0-py3-none-any.whl
- Upload date:
- Size: 7.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f3073bcd1ad71c7411b341647aaa7e5492eb9b41156c0df782f238d8db9241a1
|
|
| MD5 |
cf98d3a404f744c39b6fe0f847cd7c00
|
|
| BLAKE2b-256 |
d636ee3016fff9fd33e32a497a385525e64217afcb6f41fed290d7c614caae40
|







