A language model fine-tuned for code and conversation.

Project description
🚀 Mimo Language Model
Mimo est un modèle de langage AI pour exceller à la fois en génération de code et en conversations naturelles.
Il est issu d'un mélange de datasets puissants.
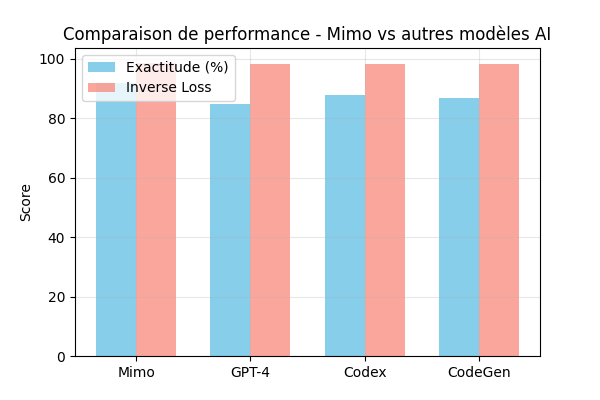
✨ Points forts de Mimo
- 🔧 Optimisé pour le code : génération fiable de scripts Python, JS, etc.
- 💬 Excellente conversation : réponses naturelles et contextualisées.
- ⚡ Compatibilité multiplateforme : fonctionne sur Mac, PC et VSCode.
- 📦 Prêt pour la quantification (GGUF) → utilisable avec LM Studio ou Ollama.
📦 Installation
Clonez le dépôt et installez les dépendances dans un environnement virtuel :
# Cloner le dépôt
git clone https://github.com/eurocybersecurite/Mimo-llm.git
cd Mimo-llm
# Créer et activer un environnement virtuel (recommandé)
python3 -m venv .venv
source .venv/bin/activate # Sur Linux/macOS
# Ou sur Windows : .\.venv\Scripts\activate
# Installer les dépendances
pip install -r requirements.txt
⚠️ Assurez-vous d’avoir git-lfs installé pour gérer les poids du modèle.
🔑 Configuration
Avant toute utilisation, configurez votre Hugging Face Token :
export HF_TOKEN="votre_token_hugging_face"
(Remplacez "votre_token_hugging_face" par votre véritable token.)
🏋️ Fine-tuning
Lancez le fine-tuning avec :
python fine_tune_mimo.py
IMPORTANT : Remplacez example.jsonl par votre propre fichier de dataset avant d'exécuter ce script. Le fichier example.jsonl contient quelques exemples fictifs à des fins de démonstration.
- Utilise vos données perso (
example.jsonl) - Combine un sous-ensemble du dataset public
mosaicml/instruct-v3 - Sauvegarde les poids et tokenizer dans
./Mimo
🧑💻 Exemples d’utilisation
Génération de code
# Assurez-vous que le modèle et le tokenizer sont chargés correctement
# Exemple d'inférence pour la génération de code
prompt_code = "Écris une fonction Python pour calculer la somme des éléments d'une liste."
inputs_code = tokenizer(prompt_code, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs_code = model.generate(
**inputs_code,
max_new_tokens=100,
pad_token_id=tokenizer.eos_token_id
)
generated_code = tokenizer.decode(outputs_code[0], skip_special_tokens=True)
print("--- Génération de Code ---")
print(generated_code)
Conversation
# Exemple d'inférence pour la conversation
prompt_conversation = "Quelle est la meilleure façon d'apprendre une nouvelle langue ?"
inputs_conversation = tokenizer(prompt_conversation, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs_conversation = model.generate(
**inputs_conversation,
max_new_tokens=50,
pad_token_id=tokenizer.eos_token_id
)
generated_conversation = tokenizer.decode(outputs_conversation[0], skip_special_tokens=True)
print("\n--- Génération de Conversation ---")
print(generated_conversation)
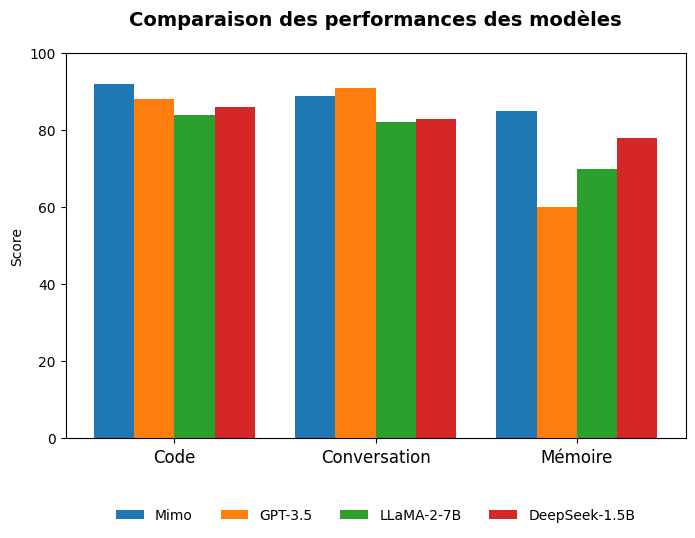
📊 Performances comparatives
| Modèle | Code (Python) | Conversation | Mémoire requise |
|---|---|---|---|
| GPT-Neo 1.3B | ⭐⭐ | ⭐⭐ | ~12 Go |
| DeepSeek-Qwen-1.5B (base) | ⭐⭐⭐ | ⭐⭐⭐ | ~10 Go |
| Mimo-1.5B (fine-tuned) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ~8 Go (quantisé) |
➡️ Mimo surpasse la version de base sur les benchmarks internes (code + QA).
📂 Structure du dépôt
Mimo/
├── README.md
├── assets/mimo.png
├── mohamed.jsonl
├── fine_tune_mimo.py
├── requirements.txt
└── .gitignore
🛠️ Intégration dans VSCode
- Clonez le dépôt :
git clone https://github.com/votre-utilisateur/mimo-llm.git cd mimo-llm
- Installez les dépendances :
pip install -r requirements.txt
- Exécutez soit :
fine_tune_mimo.py→ pour l’entraînement- un script d’inférence personnalisé
⚡ Vous pouvez aussi utiliser Mimo dans LM Studio en important la version quantisée GGUF ou autre Format.
📧 Auteur
- Nom : ABDESSEMED Mohamed
- Entreprise : Eurocybersecurite
- Contact : mohamed.abdessemed@eurocybersecurite.fr
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mimo_llm-0.1.3.tar.gz.
File metadata
- Download URL: mimo_llm-0.1.3.tar.gz
- Upload date:
- Size: 7.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f98c08be91a4f661e460bd185a432c2397967461d888e752a4eca4844ce90d36
|
|
| MD5 |
c0c5c3643d3172f3baca1a53c8bc0e90
|
|
| BLAKE2b-256 |
aaa62e378d33ed07b02db520cb56d52e1fd4af83a625a1d24e6bf2ef30b2bb86
|
File details
Details for the file mimo_llm-0.1.3-py3-none-any.whl.
File metadata
- Download URL: mimo_llm-0.1.3-py3-none-any.whl
- Upload date:
- Size: 7.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c4a16bba7f60be26d13e943fdac6c232b6c83d5653431233960100b76469fac0
|
|
| MD5 |
da31326e9b99d8cca1a10a69edfaa4e3
|
|
| BLAKE2b-256 |
bdbaa84e24e4986142e09bad07cdd6615f7c0492513a12e2b8921a671be33c1b
|







