Minimal OpenAI-compatible edge gateway with multi-backend routing

Project description
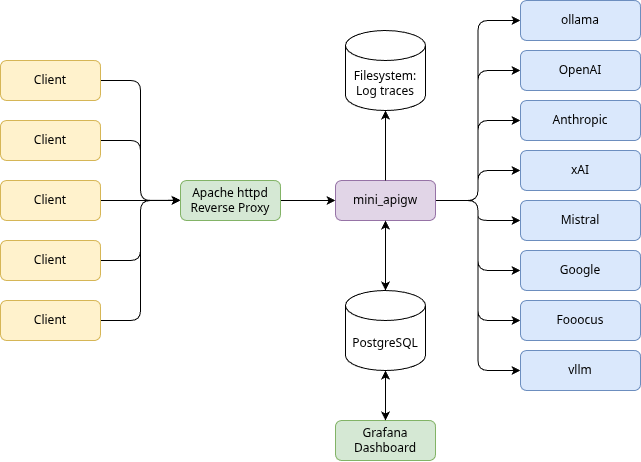
mini-apigw — Minimal OpenAI‑compatible API Gateway
_WORK IN PROGRESS
mini-apigw is a small edge gateway that presents an OpenAI‑compatible API surface and routes requests to multiple LLM and image generation backends. It is designed for simplicity and ease of control: you configure backends and apps in JSON, set policies and cost limits per app, and the gateway handles routing, scheduling, usage accounting, optional persistence, trace logging, and admin endpoints.
The main reason I developed this gateway was to handle multiple access to shared resources - I personally utilize machines that run LLMs (ollama, vllm) as well as SDXL based image generation and other software. They compete for GPU resources and since those tools are usually not developed to work together nicely and arbitrate GPU usage the gateway offers serialization of requests inside sequence groups. All backends in the same sequence group execute requests of all backends in the same group strictly in sequence so the local backends can handle loading and unloading of competing backends.
Backends included out of the box:
- OpenAI
- Ollama
- Anthropic
- Mistral
- xAI
In development:
- Fooocus
- vLLM
The gateway exposes the familiar /v1 endpoints (/chat/completions, /completions,
/embeddings, /images/generations, and /models) and normalizes responses where
needed. This allows one to use the openai client library for any backend. Note that the gateway
does not implement the full OpenAI API - it just passes through the above mentioned
endpoints. In addition it uses local API keys. Those API keys are used to select the application
from apps.json configuration file.
For more details about the rational and application there is a blog post
Installation
From PyPI (recommended):
pip install mini-apigw
From source (editable):
pip install -e .
Configuration
The gateway reads three JSON files from a configuration directory. By default this
is ./config (at the moment, this will be fixed soon, this will be a breaking change!),
or override with the environment variable MINIAPIGW_CONFIG_DIR or the CLI flag --config-dir.
Required files:
daemon.json: service, logging, admin, timeouts, and optional Postgres settingsbackends.json: model providers, aliases, costs, and capabilitiesapps.json: application definitions, API keys, allow/deny policies, cost limits, and tracing
Example daemon.json (minimal, no persistent accounting log):
{
"listen": { "host_v4": "0.0.0.0", "port": 8080 },
"admin": { "bind": ["127.0.0.1:8081", "[::1]:8081"], "stats_networks": ["127.0.0.1/32", "::1/128"] },
"logging": {
"level": "INFO",
"redact_prompts": true,
"access_log": true,
"file": "/var/log/mini-apigw.log"
},
"reload": { "enable_sighup": true },
"timeouts": { "default_connect_s": 60, "default_read_s": 600 },
"database": null
}
Example backends.json (mixed OpenAI + Ollama):
{
"aliases": { "llama3.2": "llama3.2:latest" },
"sequence_groups": { "local_gpu_01": { "description": "Serialized work for local GPU tasks" } },
"backends": [
{
"type": "openai",
"name": "openai-primary",
"base_url": "https://api.openai.com/v1",
"api_key": "<openai_key>",
"concurrency": 4,
"supports": { "chat": ["gpt-4o-mini"], "embeddings": ["text-embedding-3-small"], "images": ["gpt-image-1", "dall-e-3"] },
"cost": { "currency": "usd", "unit": "1k_tokens", "models": { "gpt-4o-mini": {"prompt": 0.002, "completion": 0.004} } }
},
{
"type" : "anthropic",
"name" : "anthropic-primary",
"base_url" : "https://api.anthropic.com",
"api_key" : "<anthropic_key>",
"concurrency" : 4,
"supports" : { "chat": [ "claude-opus-4.1", "claude-haiku-4-5", "claude-sonnet-4-5" ] },
"cost" : { "currency": "usd", "unit": "1k_tokens", "models": { "claude-opus-4-1" : { "prompt" : 0.075, "completion" : 0.075 }, "claude-sonnet-4-5" : { "prompt" : 0.0003, "completion" : 0.0003 }, "claude-haiku-4-5" : { "prompt" : 0.001, "completion" : 0.001 } } }
},
{
"type" : "mistral",
"name" : "mistral-primary",
"base_url" : "https://api.mistral.ai/v1",
"api_key" : "<mistral_key>",
"concurrency" : 1,
"supports" : { "chat" : [ "mistral-medium-latest" ], "embeddings" : [ "mistral-embed" ] },
"cost" : { "currency" : "usd", "unit" : "1k_tokens", "models" : { "mistral-medium-latest" : { "prompt" : 0.002, "completion" : 0.002 }, "mistral-embed" : { "prompt" : 0.0001, "completion" : 0.0001 } } }
},
{
"type" : "xai",
"name" : "xai-primary",
"base_url" : "api.x.ai/v1",
"api_key" : "<xai_api_key>",
"concurrency" : 4,
"supports" : {
"chat" : [ "grok-3", "grok-3-mini", "grok-4-0709", "grok-4-fast-non-reasoning", "grok-4-fast-reasoning", "grok-code-fast-1" ]
},
"cost": {
"currency": "usd",
"unit": "1k_tokens",
"models": {
"grok-3": {"prompt": 0.015, "completion": 0.015},
"grok-3-mini" : { "prompt" : 0.0005, "completion" : 0.0005 },
"grok-4-0709" : { "prompt" : 0.015, "completion" : 0.015 },
"grok-4-fast-non-reasoning" : { "prompt" : 0.0005, "completion" : 0.0005 },
"grok-4-fast-reasoning" : { "prompt" : 0.0005, "completion" : 0.0005 },
"grok-code-fast-1" : { "prompt" : 0.0015, "completion" : 0.0015 }
}
}
},
{
"type" : "google",
"name" : "google-primary",
"base_url" : "https://generativelanguage.googleapis.com/v1beta/openai/",
"api_key" : "<google_api_key>",
"supports" : {
"chat" : [
"gemini-2.5-pro",
"gemini-2.5-flash",
"gemini-2.5-flash-lite"
]
},
"cost" : {
"currency" : "usd",
"unit" : "1k_tokens",
"models" : {
"gemini-2.5-pro" : { "prompt" : 0.0, "completion" : 0.0 },
"gemini-2.5-flash" : { "prompt" : 0.0, "completion" : 0.0 },
"gemini-2.5-flash-lite" : { "prompt" : 0.0, "completion" : 0.0 }
}
}
},
{
"type": "ollama",
"name": "ollama-local",
"base_url": "http://127.0.0.1:11434",
"sequence_group": "local_gpu_01",
"concurrency": 1,
"supports": { "chat": ["llama3.2:latest", "gpt-oss:120b"], "completions": ["llama3.2:latest"], "embeddings": ["nomic-embed-text"] },
"cost": {
"models": {
"llama3.2:latest": {"prompt": 0.0, "completion": 0.0},
"gpt-oss:120b": {"prompt": 0.001, "completion": 0.001 }
}
}
}
]
}
Example apps.json (one app, you just declare them one after each other), the API keys are threatened
transparent, you can use any string as Bearer token, it just has to be unique; the app ID is used in filemanes
so you might not want to use special characters:
{
"apps": [
{
"app_id": "demo",
"name": "Demo application",
"api_keys": [
"sk-example-key"
],
"policy": {
"allow": [ "gpt-4o-mini", "llama3.2" ],
"deny": []
},
"cost_limit": {
"period": "day",
"limit": 10.0
},
"trace": {
"file": "/var/log/llmgw/demo.jsonl",
"image_dir": "/var/log/llmgw/images/demo",
"include_prompts": true,
"include_response": true,
"include_keys": true
}
}
]
}
Notes:
- Backends declare capabilities via
supports(globs allowed) and optionalaliases. Useconcurrencyandsequence_groupto tune throughput/serialization. Costs undercostare used to estimate per‑app spend. This may of course deviate from real platform billing. It's just there to provide an estimate (and may be reworked later on). Also billing is currently not tracked for images. - Apps bind one or more API keys to an
app_id, usepolicy.allow/policy.denyto restrict models, andcost_limitto enforce soft limits. Per‑app traces can be persisted as JSONL with optional image capture. - The admin interface binds on the same port (due to limitations in FastAPI code and simplicity).
It is restricted to localhost by default; when running local jails use CIDRs in
admin.stats_networks. If you expose the service through a Unix domain socket the gateway assumes a local reverse proxy enforces access control, so configure that proxy accordingly.
Running
The package installs a console entry point mini-apigw.
Foreground server_
mini-apigw start --config-dir ./config --foreground --reload
Daemonize with defaults from daemon.json (port/host or Unix socket):
mini-apigw start --config-dir ./config
This detached mode uses daemonize and writes a PID file to
<config-dir>/mini-apigw.pid so service managers can track the running process.
Set logging.file in daemon.json to mirror daemon stdout/stderr and the configured logging stream to a
specific file (paths relative to config-dir are resolved automatically).
Override listener explicitly:
mini-apigw start --config-dir ./config --host 0.0.0.0 --port 8080
# or use a Unix domain socket
mini-apigw start --config-dir ./config --unix-socket /var/llmgw/llmgw.sock
Admin helpers (call built‑in admin endpoints):
mini-apigw reload --config-dir ./config
mini-apigw stop --config-dir ./config
# explicitly talk to a Unix domain socket if you override the listener at runtime
mini-apigw stop --config-dir ./config --unix-socket /var/llmgw/llmgw.sock
mini-apigw token --bytes 32 # generate a random API key
FreeBSD rc(8)
A sample rc script lives in dist/freebsd/rc.d/mini_apigw. Install it as
/usr/local/etc/rc.d/mini_apigw, make it executable and enable it in rc.conf:
sysrc mini_apigw_enable=YES
sysrc mini_apigw_config_dir=/usr/local/etc/mini-apigw
sysrc mini_apigw_user=www # or another dedicated account
The script delegates to the CLI (mini-apigw start|stop|reload|status) and uses the PID file in the
configuration directory by default. Set mini_apigw_unix_socket if you expose the public listener via
UDS.
OpenAI‑Compatible API
All endpoints live under /v1 and require Authorization: Bearer <api_key>.
List models (combines declared and auto‑discovered where available):
curl -s -H "Authorization: Bearer sk-demo-key" http://127.0.0.1:8080/v1/models | jq .
Chat completions (JSON response; set stream: true for SSE):
curl -s \
-H "Authorization: Bearer sk-demo-key" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "You are helpful."},
{"role": "user", "content": "Say hi"}
],
"stream": false
}' \
http://127.0.0.1:8080/v1/chat/completions | jq .
Embeddings:
curl -s \
-H "Authorization: Bearer sk-demo-key" \
-H "Content-Type: application/json" \
-d '{"model": "text-embedding-3-small", "input": "hello"}' \
http://127.0.0.1:8080/v1/embeddings | jq .
Image generation (if supported by a configured backend):
curl -s \
-H "Authorization: Bearer sk-demo-key" \
-H "Content-Type: application/json" \
-d '{"model": "gpt-image-1", "prompt": "a lighthouse at dusk"}' \
http://127.0.0.1:8080/v1/images/generations | jq .
Accounting and Persistence
mini-apigw estimates request cost using backend‑specific cost rates and tracked token
usage (this is work in progress), and aggregates totals per app. By default, accounting
is in‑memory. To persist usage to Postgres for reporting or bootstrapping daily totals,
set the database section in daemon.json and apply the schema in sql/schema.sql.
Notes:
- Postgres is optional. If configured, the gateway uses
psycopg/psycopg2to insert request rows asynchronously and reconstructs the current‑day state on startup. - Cost limits (
apps[].cost_limit) are enforced against the running totals; requests beyond the limit are rejected with403.
Tracing
Per‑app tracing can write JSONL events and capture images from generation responses.
Enable under apps[].trace with file and/or image_dir. You can include prompts,
responses (non‑streaming), and masked API keys with include_prompts, include_response,
and include_keys.
Trace files are append‑only JSONL; image files are written under imagedir with content‑based
extensions for base64 payloads, or a .txt containing the URL for URL‑based images.
Admin and Stats
Admin endpoints are local‑only by default (IPv4/IPv6 loopback) and can be extended
with admin.stats_networks CIDR allow‑lists.
POST /admin/reload— reload configuration files atomicallyPOST /admin/shutdown— request a graceful stopGET /stats/live— in‑flight/queue stats per backend and sequence groupGET /stats/usage?app_id=<id>— current usage snapshot (optionally filtered)
The mini-apigw reload and stop CLI commands call these endpoints using the admin
bind defined in daemon.json.
When the gateway listens on a Unix domain socket (via listen.unix_socket or the
--unix-socket CLI flag) every request that reaches the socket is treated as trusted.
Place a local reverse proxy in front of the socket to enforce network access rules
for the public API as well as the admin/statistics endpoints.
For Apache HTTPD the following configuration proxies all API traffic through the socket:
<VirtualHost *:80>
ServerName host.example.com
ServerAdmin complains@example.com
DocumentRoot /usr/www/host.example.com/www/
ProxyTimeout 600
ProxyPass / "unix:/var/run/miniapigw.sock|http://localhost/" connectiontimeout=10 timeout=600
ProxyPassReverse / "unix:/var/run/miniapigw.sock|http://localhost/"
</VirtualHost>
If you also need HTTP authentication for administrators, Apache combines multiple Require directives with a logical AND by default. Wrap them in <RequireAll> to make that explicit:
<LocationMatch "^/(admin|stats)">
AuthType Basic
AuthName "mini-apigw admin"
AuthUserFile "/usr/local/etc/httpd/miniapigw-admin.htpasswd"
<RequireAll>
Require valid-user
Require ip 127.0.0.1 ::1 192.0.2.0/24
</RequireAll>
</LocationMatch>
Adjust the Require ip list or wrap several blocks in <RequireAny> when you want to allow either a subnet or authenticated users.
Make sure the proxy only exposes the endpoints you intend to make reachable:
/v1/… for OpenAI-compatible APIs and /admin//stats only to trusted administrators.
Note that at this moment this means any local user can control shutdown and reload! This is work in progress
Deployment Notes
The CLI embeds Uvicorn and supports IPv4/IPv6 hosts or a Unix domain socket. For production, consider:
- running behind a reverse proxy (TLS termination, headers)
- setting
logging.redact_promptstotrueunless needed - using
sequence_groupandconcurrencyto match GPU/CPU constraints
License
See LICENSE.md for the full text.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mini_apigw-0.0.26.tar.gz.
File metadata
- Download URL: mini_apigw-0.0.26.tar.gz
- Upload date:
- Size: 66.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1400a37a2fb37d8af9d397aa5a0bb195d67a488b07e854bc5eb55757e009b4f7
|
|
| MD5 |
6365399e37b678ccc6fe69722e832097
|
|
| BLAKE2b-256 |
692e2a3b2787d37ce8ecf2c8e8c9bfcc136fb04f430e0fc6f6215664a63c2b51
|
File details
Details for the file mini_apigw-0.0.26-py3-none-any.whl.
File metadata
- Download URL: mini_apigw-0.0.26-py3-none-any.whl
- Upload date:
- Size: 64.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2ad6095b5497c5f32f610eacd880645aa620bf79f2ad660f1c7fc393b73a4d55
|
|
| MD5 |
c24687a14497ebd2e806931df7856fa2
|
|
| BLAKE2b-256 |
1ee8e8aaeb4eaf557d4c315a2f1bb809f0981b16c375a723cd5147eace0b1ad0
|







