A Self-Supervised Learning Library


Project description

MK_SSL: A Modular Self-Supervised Learning Library for Audio, Vision, Graph, and Cross-Modal Data
A research-driven library with high-level APIs, tightly integrated with HuggingFace, PyTorch Lightning, and state-of-the-art tools for self-supervised learning.



📚 Table of Contents
- 📍 Overview
- 🧠 What is Self-Supervised Learning?
- 🚀 Supported Methods
- 📦 Installation
- 🛠️ Usage Tutorial
- 📊 Benchmarks
- 🔧 Extra Superpowers
- 🧬 HuggingFace Example
- 🤝 Collaborators and Advisors
- 📜 License
📍 Overview
Say hello to MK_SSL — a library born from late-night debugging sessions, too much coffee, and the realization that self-supervised learning didn’t need to feel like solving a Rubik’s cube in the dark. In our research, we bounced between half-finished repos, clashing APIs, and “it worked on my machine” moments. Out of that chaos, we decided to build something cleaner: one place where SSL across audio, vision, graph, and cross-modal data actually makes sense.
At its core, MK_SSL is a unified playground for SSL. Imagine a command center where you can test state-of-the-art methods, swap modalities with a single line change, and still keep your sanity intact. Everything is modular, transparent, and reproducible — because science should be fun, not frustrating.
We also wanted MK_SSL to be welcoming. Whether you’re a student curious about representation learning, a researcher hunting for benchmarks, or a practitioner putting SSL into production, this library has your back. With HuggingFace and PyTorch Lightning baked in, plus support for distributed training, hyperparameter tuning, and lightweight fine-tuning, you’ll spend less time wrestling with setup and more time exploring ideas.
In short: MK_SSL is where rigor meets playfulness. Built from academic struggles but polished for the community, it lowers the barriers to SSL while giving you the tools to push the boundaries further. It also represents an improved version of an earlier research project, AK_SSL, developed by two previous students. That library contained the implementation of some other ssl methods, and the good news is: everything from AK_SSL is now accessible directly from MK_SSL with the same syntax. If you’d like to read more about AK_SSL or see the original methods, check the link above — but for practical use, everything has been consolidated here into one unified framework.
🧠 What is Self-Supervised Learning?
Self-Supervised Learning (SSL) is basically the art of teaching machines to make up their own homework and then solve it. Instead of us spoon-feeding models with expensive, hand-labeled data, SSL lets them invent clever tasks using only the raw input. Mask part of an audio signal and predict it? Shuffle an image and put it back together? Align speech with text? All of these are ways for models to get smarter without needing humans to sit down and annotate millions of examples.
From an academic angle, SSL has become a game-changer. It powers breakthroughs in speech recognition for low-resource languages, revolutionizes medical imaging where labels are scarce, and even helps scientists model molecules and proteins. At the same time, it’s the secret sauce behind today’s most powerful foundation models — making it both theoretically fascinating and practically indispensable.
But SSL isn’t just serious science — it’s also a bit of fun. There’s something delightful about watching a model reconstruct missing audio or fill in the gaps of an image, almost like it’s playing puzzles at scale. That blend of rigor and playfulness is exactly why we built MK_SSL: to give you a sandbox where curiosity, research, and real-world applications all come together.
🚀 Supported Methods
🎧 Audio-based Methods
Self-supervised audio modeling has transformed speech processing by enabling models to generalize from unlabeled sound. MK_SSL includes all the major paradigms, each capturing a different angle of how machines can learn to understand sound.
Wav2Vec2
Wav2Vec2 masks segments of raw audio and predicts them using latent features. The clever trick is that it forces the model to capture contextual information in speech without needing phonetic labels. This method has shown that even with minimal annotated data, models can reach near state-of-the-art performance in automatic speech recognition. It is especially impactful for languages and domains where labeled datasets are scarce.
HuBERT
HuBERT (Hidden-Unit BERT) takes the Wav2Vec2 philosophy further. It introduces pseudo-labeling through k-means clustering of hidden representations and uses those as targets for a BERT-like masked prediction. This iterative process of clustering and prediction refines the model over time, resulting in more robust and generalizable embeddings that can transfer effectively to multiple downstream tasks.
SpeechSimCLR
SpeechSimCLR adapts the contrastive learning approach SimCLR from vision to the audio domain. By applying augmentations such as time warping, noise injection, and speed perturbation, it teaches models to bring augmented versions of the same audio close together in representation space. This results in representations that are robust to noise and variations, and useful for speaker verification, classification, and general audio understanding.
COLA
COLA (Contrastive Learning with Alignment) emphasizes the temporal aspect of speech. Instead of treating audio as independent segments, it enforces alignment such that temporally close segments are nearby in the embedding space, while distant segments are pushed apart. This design makes embeddings more faithful to the sequential nature of speech, aiding tasks like dialogue modeling and speech segmentation.
EAT
The Embedding Audio Transformer (EAT) introduces the concept of masked autoencoders into the audio domain. It converts audio into spectrogram patches, masks random sections, and trains the model to reconstruct them. This pushes the model to learn high-level acoustic structures and relationships, similar to how vision transformers learn about images. EAT is especially promising for music understanding and large-scale pretraining where context-rich embeddings matter.
🖼️ Vision-based Method
MAE (Masked AutoEncoder)
MAE is a vision SSL method that masks random patches of an image and reconstructs them. The beauty of MAE is that it does not require labels yet learns powerful visual representations by solving this reconstruction puzzle. It has proven highly effective as a pretraining approach, enabling models to perform well with fewer labels in transfer tasks like object classification, segmentation, and fine-grained recognition.
🧬 Graph-based Method
GraphCL
GraphCL applies contrastive learning to graph-structured data. It creates multiple augmented versions of the same graph through techniques such as edge perturbation, node dropping, and attribute masking, and then aligns their embeddings. By doing so, it captures structural invariances that are central to understanding graphs. This makes it valuable for applications such as molecular property prediction, biological network analysis, and social network embeddings.
🔀 Cross-Modal Methods
Cross-modal SSL allows models to bridge domains like text, audio, and images, which is crucial for multimodal AI systems.
CLAP
CLAP learns joint embeddings for paired audio and text data. It aligns sound with natural language, enabling models to perform cross-modal retrieval and semantic classification. This makes it possible to, for instance, search for sound effects by typing text queries, or build systems that understand both speech and textual descriptions.
AudioCLIP
AudioCLIP extends the CLIP architecture into the audio domain, aligning text, audio, and image together. This tri-modal alignment creates a rich shared embedding space that can be applied to multimedia search, generative AI, and multimodal classification tasks. It essentially gives models the ability to understand and connect three different modalities at once.
Wav2CLIP
Wav2CLIP simplifies the cross-modal problem by directly mapping raw audio into the pretrained CLIP embedding space. With frozen CLIP encoders guiding the training, it leverages the vast visual-text knowledge already baked into CLIP and transfers it to audio. This opens doors to creative tasks like audio-to-image retrieval and multimodal creative applications.
📦 Installation
pip install mk-ssl
Requirements:
- Python ≥ 3.8
- PyTorch ≥ 1.12
- CUDA-enabled GPU recommended for large-scale training
🛠️ Usage Tutorial
With MK_SSL, you can go from raw data to results in minutes. The design philosophy is plug-and-play, letting you switch methods or modalities seamlessly.
🧩 Trainer Initialization (Audio Example)
from MK_SSL.audio.Trainer import Trainer
trainer = Trainer(
method = 'wav2vec2',
backbone = None,
save_dir = './',
wandb_project = 'wav2vec2-pretext',
wandb_mode = "online",
use_data_parallel = True,
checkpoint_interval = 5,
verbose = True,
reload_checkpoint=False,
mixed_precision_training=False
)
🎯 Train the Model
trainer.train(
train_dataset=train_dataset,
val_dataset=val_dataset,
batch_size=16,
epochs=100,
lr=1e-4,
weight_decay=1e-2,
optimizer="adamw",
use_hpo=True,
n_trials=20,
tuning_epochs=5,
use_embedding_logger=True,
logger_loader=logger_loader
)
🧪 Evaluate on Downstream Task
trainer.evaluate(
train_dataset=train_dataset,
test_dataset=test_dataset,
num_classes=39,
batch_size=64,
lr=1e-3,
epochs=10,
freeze_backbone=True
)
📊 Benchmarks
MK_SSL is designed for reproducible benchmarking across domains.
🎧 Audio (Wav2Vec2 - TESS Emotion Dataset)
Wav2Vec2 pretrained with MK_SSL.
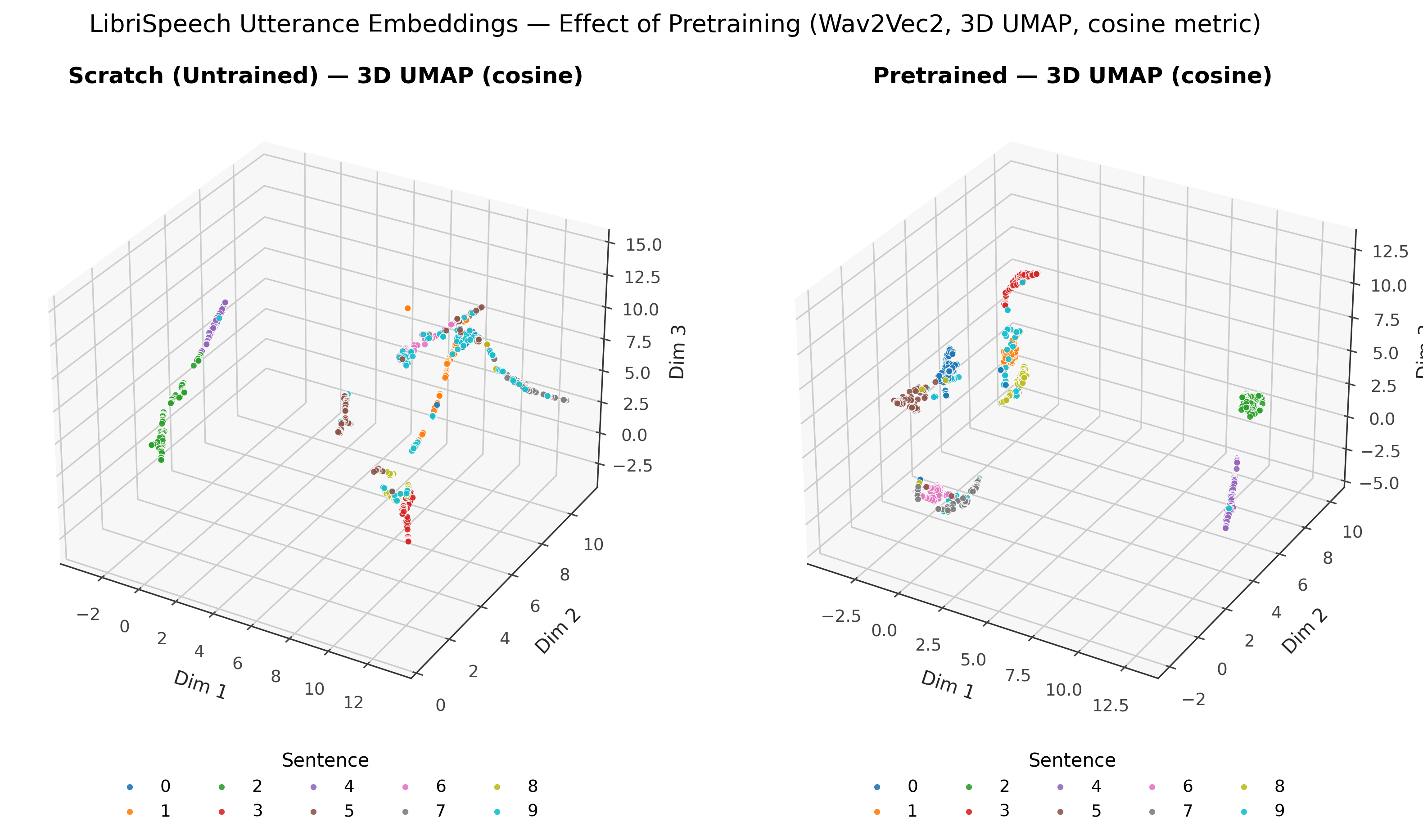
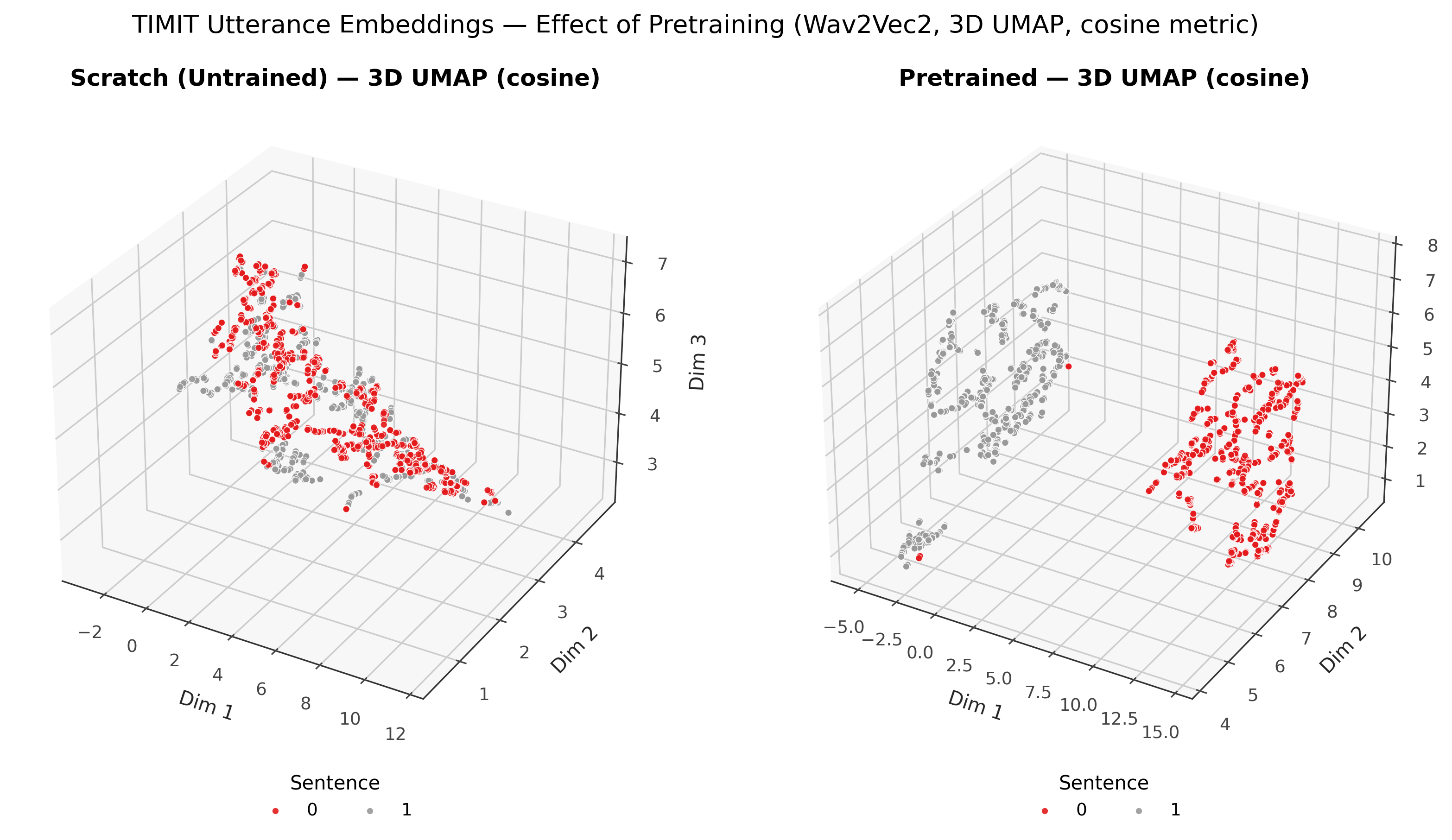
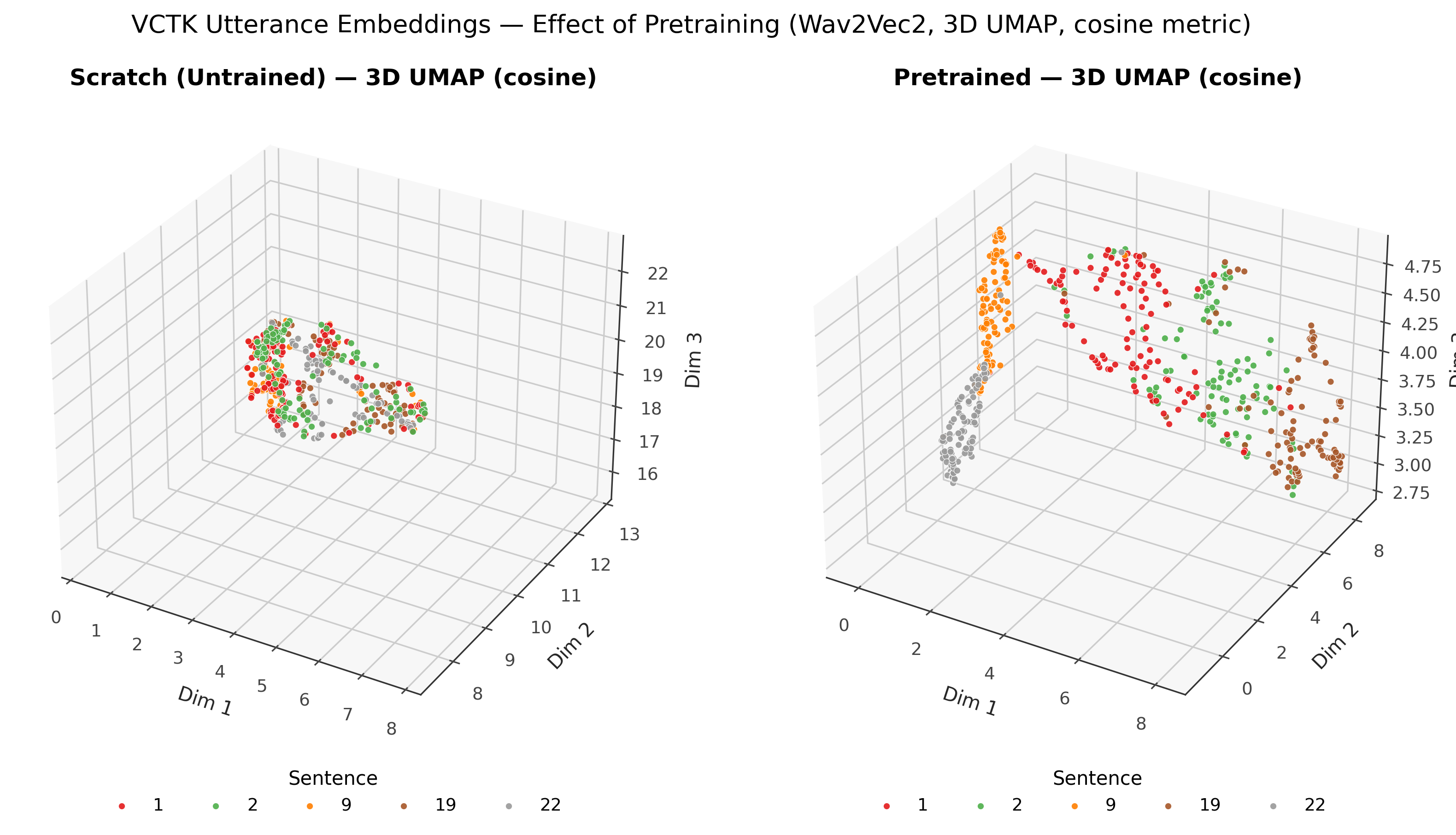
| Task | Dataset | Model | Accuracy |
|---|---|---|---|
| Emotion Clf | Speaker Recognition (2 speakers) | Speech SimCLR | 72.5% |
| Emotion Clf | TESS | COLA | 88.39% |
| Speaker Clf | TESS | EAT | 93.21% |
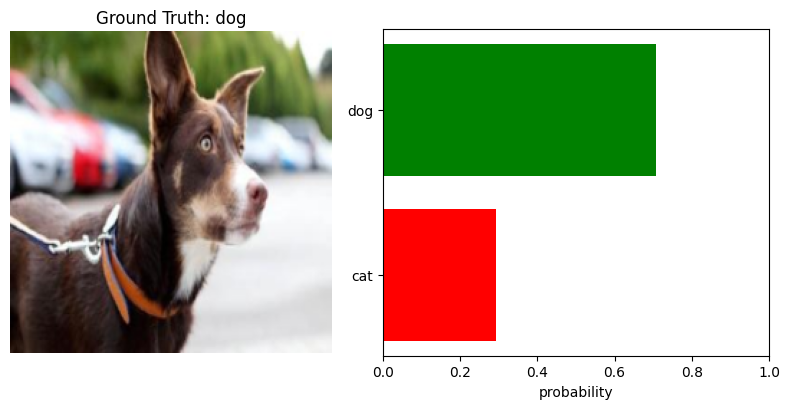
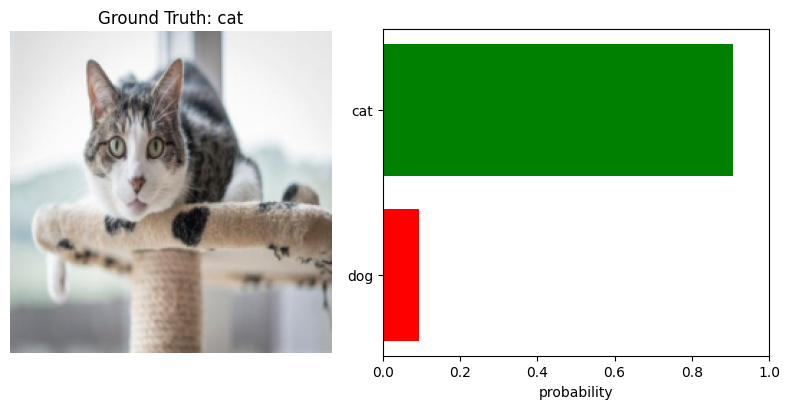
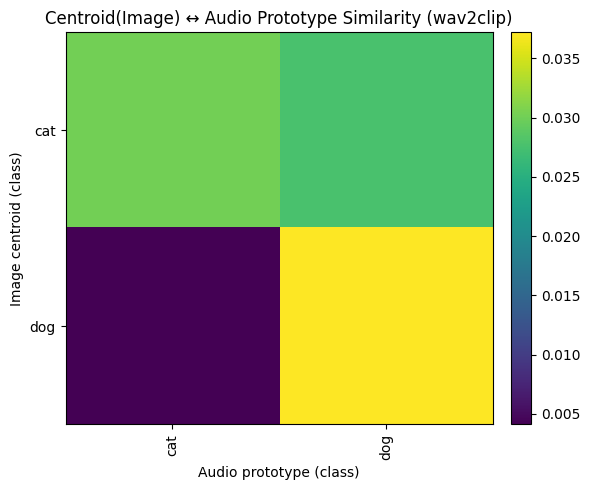
🔀 Cross-Modal (Wav2CLIP)
Wav2CLIP learns powerful joint embeddings, enabling intuitive cross-modal retrieval.
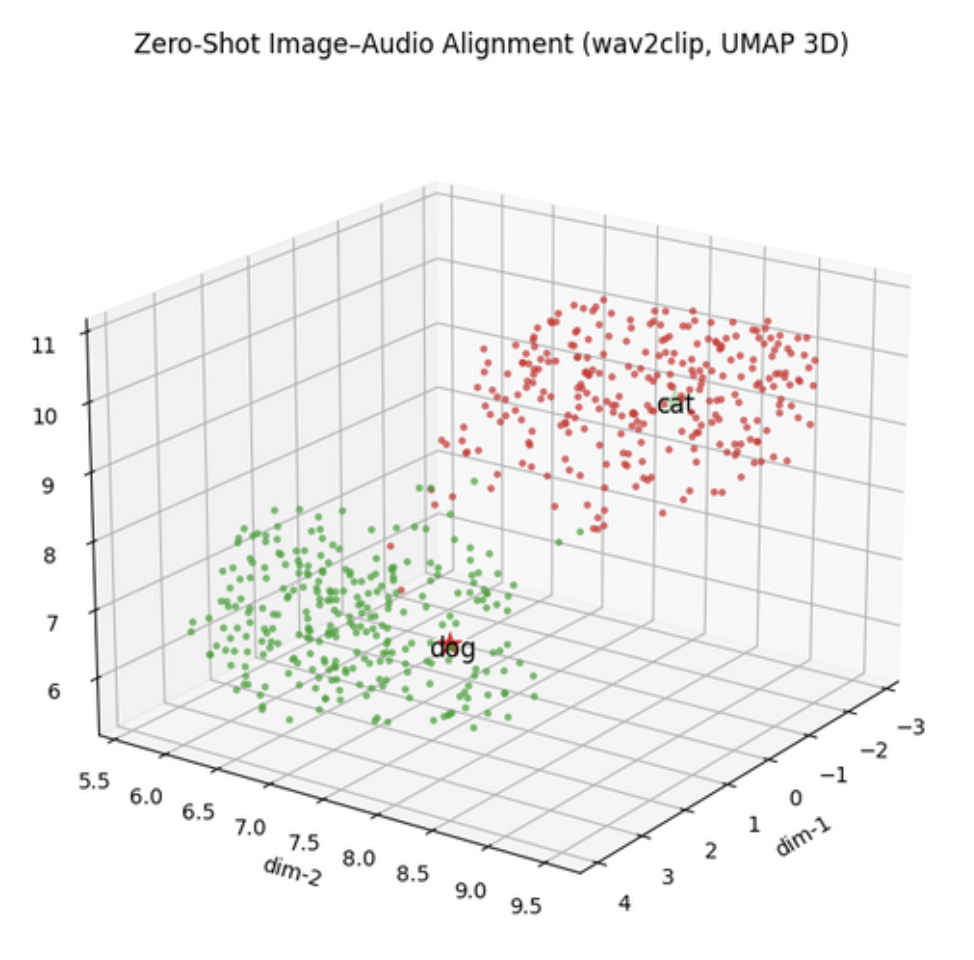
🖼️ Vision (MAE on CIFAR-10)
MAE pretrained with MK_SSL yields competitive performance with limited fine-tuning.
| Setting | Accuracy |
|---|---|
| Linear Probing | 61.84% |
| Fine-tuned | 87.98% |

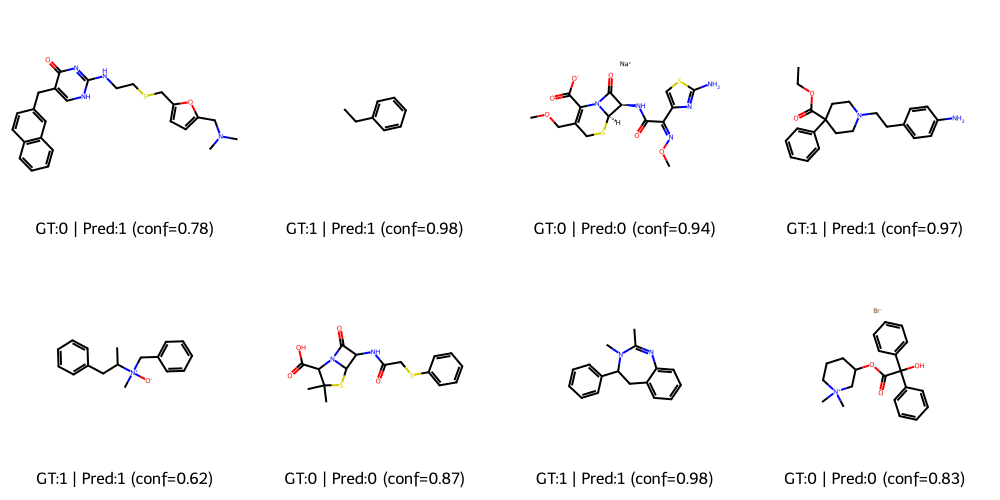
🧬 Graph (GraphCL)
GraphCL learns molecular-level embeddings competitive with supervised baselines.
| Dataset | Accuracy | AUC |
|---|---|---|
| BBBP | 89.76% | 92.62% |
| Tox21 | task0: 96.61% | – |
| Tox21 | task1: 97.25% | – |
| Tox21 | task2: 87.28% | – |
| Tox21 | task3: 91.39% | – |
| Tox21 | task4: 86.73% | – |
| Tox21 | task5: 96.30% | – |
| Tox21 | task6: 96.11% | – |
| Tox21 | task7: 76.65% | – |
| Tox21 | task8: 94.61% | – |
| Tox21 | task9: 91.71% | – |
| Tox21 | task10: 83.11% | – |
| Tox21 | task11: 88.78% | – |
| Tox21 | 12-task avg: 90.54% | – |
🔧 Extra Superpowers
MK_SSL isn’t just a collection of SSL methods — it’s armed with extra superpowers that make your research life smoother, faster, and a lot more fun. Think of these as the cheat codes we always wished existed when we were wrestling with messy experiments:
- 🖥️ Distributed Deep Learning (DDL) — Scale your experiments across multiple GPUs or nodes without needing to summon a cluster-wrangling wizard. Big models? Big data? Bring it on.
- 🎯 Hyperparameter Optimization (HPO) — Stop playing guessing games. Automated tuning with Optuna helps you find the sweet spots without losing weeks of your life.
- 🧠 LoRA Finetuning — Efficiently adapt giant models with lightweight parameter updates. It’s like upgrading your model’s brain without burning your GPU.
- 📊 WandB Integration — Track, visualize, and share every training run like a pro. Who doesn’t love pretty dashboards?
- 🧾 Logging System — Clean, colorful, and customizable logs that won’t make your terminal cry.
- 🤗 HuggingFace Compatibility — Plug and play with transformers and pretrained backbones. Because reinventing the wheel is overrated.
- 🎥 Dynamic Visualizations — Watch your embeddings evolve over time with animated plots. It’s science, but make it art.
In other words: MK_SSL doesn’t just help you run experiments — it helps you run better experiments, with less pain and more insight.
🧬 HuggingFace Example
from transformers import BertForPreTraining, AutoTokenizer
model = BertForPreTraining.from_pretrained("bert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
trainer = GenericSSLTrainer(
model=model,
loss_fn=bert_loss_fn,
dataloader=dataloader,
optimizer_ctor=optimizer,
epochs=10
)
trainer.fit()
🤝 Collaborators and Advisors
This project was made possible through our collaborative research and academic mentorship. The main contributors are:
Our combined efforts shaped the design, implementation, and structure of MK_SSL. The project was further enriched by the guidance of Dr. Peyman Adibi and Dr. Hossein Karshenas, whose academic mentorship ensured rigor and practical impact.
📜 License
We’re keeping things chill with the MIT License. In plain English: do whatever you want with this code — use it, remix it, build something wild on top of it. Just don’t sue us if your GPU explodes or your cat walks across your keyboard mid-training and somehow invents AGI. Fair game? Cool. 🚀


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mk_ssl-0.1.3.tar.gz.
File metadata
- Download URL: mk_ssl-0.1.3.tar.gz
- Upload date:
- Size: 156.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
046b417210f07bc52aabfa46cd5adfc7c6674a93d42ccb04ea3a2980e9376a20
|
|
| MD5 |
a6ff4de52b36b92c8f1077aac18c7267
|
|
| BLAKE2b-256 |
67de690379aeedd25e69bbcf361f799c208f73d23df713077c6b95aeac2f6df9
|
File details
Details for the file mk_ssl-0.1.3-py3-none-any.whl.
File metadata
- Download URL: mk_ssl-0.1.3-py3-none-any.whl
- Upload date:
- Size: 199.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c73d414b04af8f0ddb06c25fd5c5d943996088b49c101bb6fb5e9d9317ba3dbd
|
|
| MD5 |
013a34edf32dfcfb55ae190837a22ebc
|
|
| BLAKE2b-256 |
48bd8bad3cefb15c35c73a5524fdb20015257e2443c762be8ce794b7b8bd162f
|







