Generative image and video model runtimes for MLX.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
MLX-Gen



MLX-Gen is a local image and video generation runtime for Apple Silicon and MLX. It exposes
mlxgen for text-to-image, image-to-image, text-to-video, image-to-video, model download, model
preparation, SeedVR2 image/video restoration and upscaling, optimized quantized model variants, and application progress
callbacks.
[!IMPORTANT] MLX-Gen started as a fork of mflux. Most credit for the current codebase goes to Filip Strand and the original mflux contributors. MLX-Gen keeps that foundation and focuses on making local generation predictable for real applications: users download or prepare models before running a job, then use one
mlxgencommand to generate, inspect supported modes, and compare generated examples and measured results. MLX-Gen contributes by adding tested T2I/I2I routes, Qwen Image Edit 2509/2511 routing and parity fixes, Bonsai Image support, Wan2.2 text-to-video, image-to-video, and video-to-video support, model-specific mixed quantization policies, published quantized Hugging Face repos optimized for MLX-Gen, and progress callbacks for apps. The fork exists so AbstractVision and related AbstractFramework projects can move quickly without losing the option to merge useful changes back upstream if that becomes valuable for the wider mflux community.
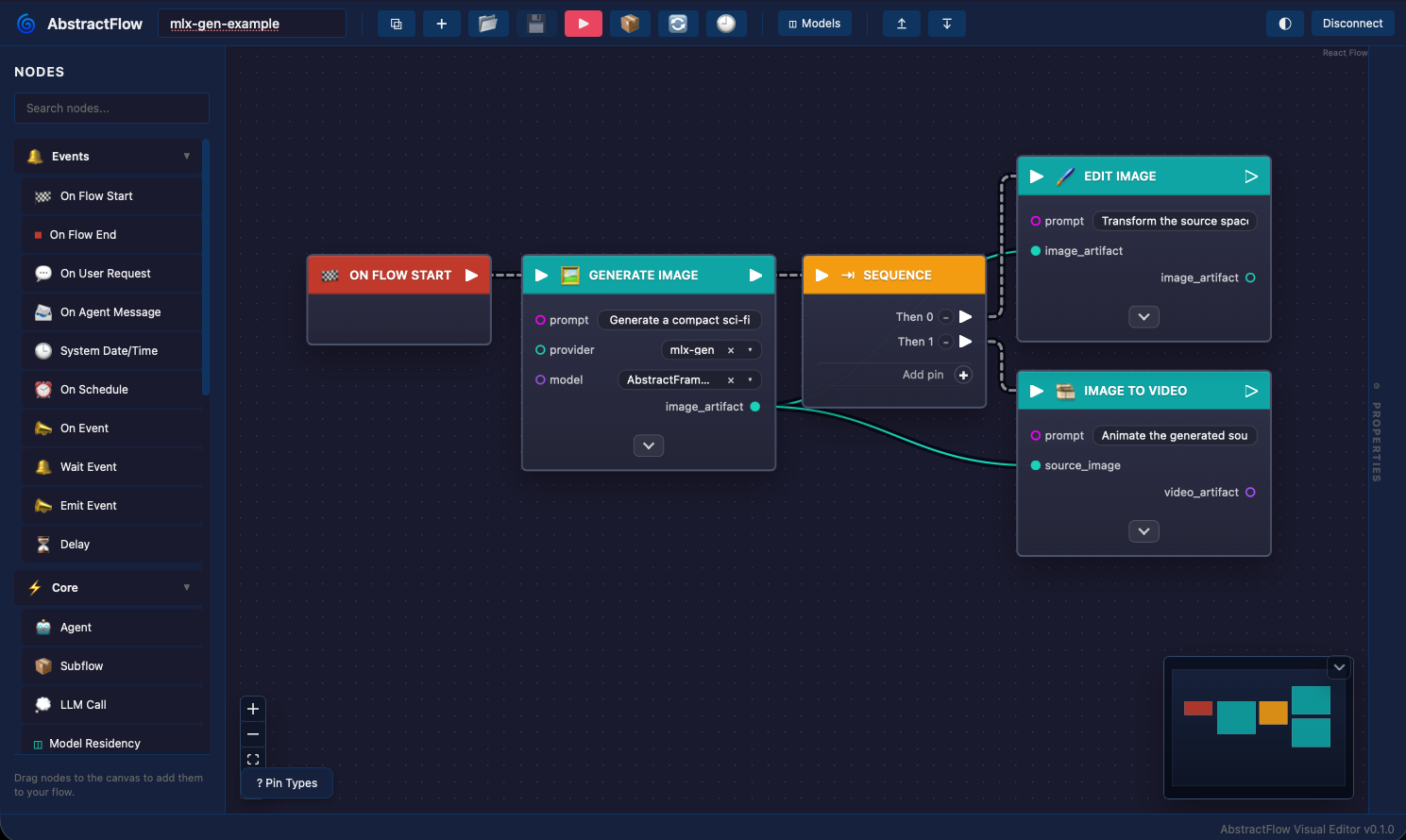
This screenshot shows AbstractFlow, a visual workflow authoring tool in the AbstractFramework ecosystem. AbstractFlow can orchestrate generative image/video capabilities exposed through AbstractVision and AbstractCore; the same MLX-Gen steps can also be run directly with the command-line examples below.
What It Does
MLX-Gen runs supported Hugging Face source models after you download them locally. It also runs quantized model variants that are published on Hugging Face for MLX-Gen. Some of those variants keep precision-sensitive layers at 8-bit or BF16 instead of blindly quantizing every layer, which is why they are published as MLX-Gen-specific repos. You explicitly download or prepare models first, then generation uses only files already on disk, which suits desktop apps, workflow engines, and long-running local jobs.
The main capabilities are:
- text-to-image generation with Qwen Image, FLUX.2 Klein, Z-Image, ERNIE Image Turbo, Bonsai Image, FIBO, and their optimized quantized variants where available;
- image-to-image modes, including latent img2img, instruction/reference edits, multi-reference
edits, masked edit/inpaint where the selected model supports
--mask-path, base-Qwen control-inpaint on the exact validatedAbstractFramework/qwen-image-8bitrow, Qwen structured control where the selected model supports--controlnet-image-path, Z-Image Turbo native inpaint on the exact validatedAbstractFramework/z-image-turbo-8bitrow, and route-specific reframe/outpaint workflows where the selected model supports them; - Wan2.2 text-to-video, image-to-video, and prompt-guided video-to-video (plain or masked via
--video-mask-path, which locks everything outside the mask to the source video), including TI2V-5B BF16/q8 packages plus A14B T2V/I2V BF16 and mixed q8/BF16 packages; video-to-video resamples the source onto the requested fps timeline (output keeps real-time speed) and copies source audio onto the output best-effort; the current public video-to-video route is limited toWan2.2-T2V-A14B, uses one source video plus one prompt, requires--solver unipc, and does not include reference images or VACE-style learned conditioning; Wan I2V resolves output size from the source image aspect ratio so inputs are not stretched into a mismatched canvas; - SeedVR2 image and video restoration through
mlxgen upscale, with official 3B/7B source support including the dedicatedseedvr2-7b-sharproute, published q8/q4 packages, shortest-edge target sizing, explicit scale factors such as2xand3x, streamed restore for longer clips, preserved source FPS, a conservative host-safe default video profile, and published five-second1xand2xvalidation bundles for the 3B/7B video path; - explicit
downloadandprepareworkflows for local MLX-Gen model packages; - JSON model capability inspection before starting a heavy run;
- strict route-specific LoRA routing and adapter application checks, with model-card compatibility
preflight when cached adapter metadata is available and exact public proof rows for Qwen Image
Edit original/2509/2511, base Qwen Image text and latent, Qwen Image 2512 text, the base Qwen
Image q8 structured-control and control-inpaint rows, the exact
AbstractFramework/z-image-turbo-8bittext and latent img2img rows, FLUX.2 Klein 9B edit and multi-reference, FLUX.2 Klein base 4B outpaint, ERNIE Image Turbo text and latent img2img, and all supported Wan q8 video routes including Lightning fast video-to-video; the LoRA guide documents the exact validated adapters per route, strict scale matching, copy-pasteowner/repo:subdir/fileadapter forms, and the validation evidence behind each proof row (same-seed A/B sheets for the image and T2V/I2V rows, a bounded multi-seed matrix for the video-to-video row). Those Lightning examples are documented against MLX-Gen q8 packages, not arbitrary external FP8 checkpoints. Bonsai LoRA stays fail-closed; - shared progress events for applications embedding MLX-Gen.
Use mlxgen capabilities --model ... before long image-edit runs. Capability output describes the
available route; validation reports and contact sheets describe whether an exact source handle or
MLX-Gen optimized package passed a visual release gate. Release evidence should use true handles such as
briaai/Fibo-Edit or AbstractFramework/flux.2-klein-9b-8bit, not short aliases.
Install
Install with uv:
uv tool install --upgrade mlx-gen
Or install into an environment:
python -m pip install -U mlx-gen
Check the command surface:
mlxgen --help
For application integration and shell-outs, use the mlxgen commands shown in
mlxgen --help. The package still installs some mflux-generate-* compatibility entry points
from the upstream codebase, but those are not the recommended integration surface for new tools.
First Commands
Download model files explicitly:
mlxgen download --model AbstractFramework/flux.2-klein-9b-8bit
Generate an image:
mlxgen generate \
--model AbstractFramework/flux.2-klein-9b-8bit \
--prompt "A cinematic wide shot of a compact sci-fi spaceship resting in deep snow on a frozen alien planet" \
--width 768 \
--height 432 \
--steps 24 \
--guidance 1.0 \
--seed 6107 \
--output spaceship.png
Generate several output images or videos in one run by passing more than one seed:
mlxgen generate \
--model qwen-image \
--prompt "A clean studio product photo" \
--seed 101 202 303 \
--output product.png
MLX-Gen saves one artifact per seed and appends the seed to the output stem automatically, for
example product_seed_101.png, product_seed_202.png, and product_seed_303.png.
mlxgen generate and mlxgen upscale also support --auto-seeds N when you want several random
variations from one command. Duplicate explicit seeds are rejected, --auto-seeds must be greater
than zero, --output supports {seed}, and SeedVR2 multi-source runs also support {input_name}
with legacy {image_name} accepted as a compatibility alias.
Upscale an image with SeedVR2:
mlxgen download --model AbstractFramework/seedvr2-3b-8bit
mlxgen upscale \
--model AbstractFramework/seedvr2-3b-8bit \
--image-path input.png \
--resolution 2x \
--softness 0.25 \
--metadata \
--output input_2x.png
For SeedVR2, an integer --resolution is the target shorter edge while values such as 2x and
3x are scale factors. Both modes preserve the source aspect ratio. Use --softness 0.25 to
0.5 when the source has visible grain in smooth areas. Small image outputs use the untiled VAE
path; large image outputs automatically use tiled VAE decode, and --vae-tiling forces tiled VAE
encode/decode for image runs only. See docs/upscaling.md for a reproducible
5x SeedVR2 image comparison plus the accepted five-second Eiffel 1x and 2x 3B / 7B
restore proof bundles.
Restore a real five-second validation clip with SeedVR2:
mlxgen upscale \
--model ByteDance-Seed/SeedVR2-3B \
--video-path input.mp4 \
--start-seconds 70 \
--max-frames 149 \
--resolution 1x \
--softness 0.0 \
--color-correction wavelet \
--temporal-chunk-size 29 \
--temporal-chunk-overlap 8 \
--low-ram \
--mlx-cache-limit-gb 8 \
--metadata \
--output restored.mp4
For video inputs, SeedVR2 preserves the source FPS by default and preserves the matching source
audio segment by default as well. If MLX-Gen cannot prove that copied audio is still aligned
safely, the run fails instead of publishing a silent output unexpectedly. Use --drop-audio only
when you intentionally want a silent restored MP4. (This is deliberately stricter than Wan
video-to-video's best-effort audio copy: restoration is a fidelity contract, while a failed mux
on a generative run must not discard the finished video.) The safe public video profile defaults to 1x,
enables --low-ram automatically, and rejects enlarged video output unless you explicitly pass
--force-unsafe-video-memory. See
docs/upscaling.md for the accepted five-second Eiffel quality proof bundle and
the published Air France audio-copy proof bundle.
mlxgen upscale accepts one or more explicit seeds and --auto-seeds N on both image and video
restore runs. When you process several seeds, MLX-Gen appends _seed_<seed> automatically. When
one SeedVR2 invocation processes several source files, MLX-Gen also appends the source-file stem so
each saved artifact gets its own path. If two source files share the same basename, keep
--replace false or rename the inputs; overwrite-prone SeedVR2 batches are rejected when
--replace true.
Inspect model capabilities before a run:
mlxgen capabilities --model AbstractFramework/flux.2-klein-9b-8bit
Capabilities are route contracts: they show which tasks, I2I modes, image counts, and options the selected model can dispatch. For release QA evidence on exact packages, use:
mlxgen validation --model AbstractFramework/qwen-image-edit-2509-8bit
LoRA support is route-specific. For LoRA work, inspect supports_lora, lora_status, and
lora_validation_profile in mlxgen capabilities, download the adapter explicitly with
mlxgen download, and use an adapter trained for the selected model family and route. Current
exact proof rows cover original Qwen Image Edit, Qwen Image Edit 2509/2511, base Qwen Image text
and latent, Qwen Image 2512 text, the exact AbstractFramework/z-image-turbo-8bit text and latent rows, FLUX.2 Klein 9B edit and
multi-reference, FLUX.2 Klein base 4B outpaint, ERNIE Image Turbo text and latent, plus the
current Wan q8 public video routes. The LoRA guide also includes the current LightX2V 4-step
A14B timing comparison against the practical original Wan profiles, same-seed
no-LoRA-versus-Lightning A/B sheets, recommended 4-step Qwen 2512 and Qwen Edit 2511 Lightning
examples, a 240p-versus-480p T2V sweep, and copy-paste download and T2V/I2V commands for
lightx2v/Wan2.2-Lightning, including the stable repo:subdir/file.safetensors form and
equivalent absolute local-file usage after download.
For example, a FLUX.2-dev LoRA is not accepted for FLUX.2 Klein. See docs/lora.md
for the A/B validation method.
Create a local MLX-Gen model package, for example an 8-bit Qwen Image package:
mlxgen prepare \
--model Qwen/Qwen-Image \
--path ./models/qwen-image-8bit \
--quantize 8
mlxgen generate does not download missing files. If something is not cached, MLX-Gen raises a
clear DownloadRequiredError with the command to run. A complete local MLX-Gen package at
./models/<repo-name> can also satisfy a matching Hugging Face handle such as
AbstractFramework/qwen-image-edit-2511-8bit.
Reproducible Example
The docs include a complete model-backed spaceship workflow:
- T2I: generate a spaceship in the snow.
- I2I edit: turn it into a pencil sketch.
- I2I edit: crash the same spaceship in the snow.
- I2I multi-reference: combine the crash layout and pencil-sketch style.
- T2V A14B: generate a spaceship taking off from a snow planet.
- I2V A14B: animate the generated spaceship taking off from the source image.
See docs/examples/spaceship-snow.md for the exact commands and included assets.

For image-edit contact sheets, command logs, and model/package status across Qwen Image
Edit, Qwen Image Edit 2509/2511, FLUX.2 Klein, and latent I2I models, see
docs/edit-capabilities.md.
That guide also includes the exact base Qwen q8 structured-control proof route, the exact
base Qwen q8 control-inpaint proof route, and the exact Z-Image Turbo q8 native-inpaint proof
route.
For the full Qwen route map, including how mlxgen capability ids line up with upstream Diffusers
Qwen pipelines and where the published proof surfaces live, see
docs/qwen-route-matrix.md.
For a plain-language guide to latent img2img, instruction edit, masked edit/inpaint, multi-reference composition,
Qwen structured control, generative reframe, and outpaint, see
docs/image-edit-modes.md.
Published Models
Quantized and BF16 model variants optimized for MLX-Gen are published under the AbstractFramework organization on Hugging Face. Current published packages include:
FLUX.2 Klein:
AbstractFramework/flux.2-klein-4b-4bitAbstractFramework/flux.2-klein-4b-8bitAbstractFramework/flux.2-klein-9b-4bitAbstractFramework/flux.2-klein-9b-8bitAbstractFramework/flux.2-klein-base-4b-4bitAbstractFramework/flux.2-klein-base-4b-8bitAbstractFramework/flux.2-klein-base-9b-4bitAbstractFramework/flux.2-klein-base-9b-8bit
Qwen Image and Qwen Image Edit:
AbstractFramework/qwen-image-4bitAbstractFramework/qwen-image-8bitAbstractFramework/qwen-image-2512-4bitAbstractFramework/qwen-image-2512-8bitAbstractFramework/qwen-image-edit-4bitAbstractFramework/qwen-image-edit-8bitAbstractFramework/qwen-image-edit-2509-4bitAbstractFramework/qwen-image-edit-2509-8bitAbstractFramework/qwen-image-edit-2511-4bitAbstractFramework/qwen-image-edit-2511-8bit
Z-Image, ERNIE, and FIBO:
AbstractFramework/z-image-4bitAbstractFramework/z-image-8bitAbstractFramework/z-image-turbo-4bitAbstractFramework/z-image-turbo-8bitAbstractFramework/ernie-image-turbo-4bitAbstractFramework/ernie-image-turbo-8bitAbstractFramework/fibo-4bitAbstractFramework/fibo-8bit
SeedVR2 upscaling:
AbstractFramework/seedvr2-3b-4bitAbstractFramework/seedvr2-3b-8bitAbstractFramework/seedvr2-7b-4bitAbstractFramework/seedvr2-7b-8bit
SeedVR2 7B can also run from the official ByteDance-Seed/SeedVR2-7B source model, including the
seedvr2-7b-sharp checkpoint alias, or from the published q8/q4 package handles above. See
docs/upscaling.md and docs/quantization.md for the
validated 7B source/q8/q4 profile.
Wan2.2 video:
AbstractFramework/wan2.2-ti2v-5b-diffusers-bf16AbstractFramework/wan2.2-ti2v-5b-diffusers-8bitAbstractFramework/wan2.2-t2v-a14b-diffusers-bf16AbstractFramework/wan2.2-t2v-a14b-diffusers-8bitAbstractFramework/wan2.2-i2v-a14b-diffusers-bf16AbstractFramework/wan2.2-i2v-a14b-diffusers-8bit
Use mlxgen download --model <repo-id> to cache a published model, then pass the repository id to
the relevant command: mlxgen generate for image/video generation or mlxgen upscale for SeedVR2
upscaling. See
docs/quantization.md for the complete current package matrix with source
sizes, optimized package sizes, task coverage, and quantization notes.
For Wan2.2 TI2V-5B, the published BF16 MLX-Gen package is 21.2 GiB versus 31.9 GiB for the upstream source snapshot. It is mainly a smaller reusable source-equivalent package because MLX-Gen already loads Wan transformer/VAE weights at BF16 runtime precision. The published q8 package is 16.9 GiB. Since the 2026-06-12 runtime-precision fix, Wan q8 packages dequantize all transformer-block linears to BF16 at load, so q8 is a storage/download saving only and runtime memory matches the BF16 package. Wan TI2V-5B q4 or mixed q4/q8 is not published as a supported package. See the exact benchmark profile and the dated correction in docs/quantization.md.
Wan A14B Measurements
Wan A14B was measured on an Apple M5 Max with 128 GB unified memory. The published-card benchmark uses small, repeatable low-RAM runs and records full-process Darwin physical footprint, RSS, MLX allocator peak, and generation time. Use these values for the listed profiles; memory and runtime scale with resolution, frame count, step count, cache settings, and image-to-video conditioning.
Correction (2026-07-05): the q8 rows below predate the 2026-06-12 runtime-precision fix. Since that fix, Wan q8 packages dequantize all transformer-block linears to BF16 at load, so runtime memory matches the BF16 rows (re-measured: 27.8 GiB MLX peak at the same T2V profile). Plan memory as if running the BF16 package; q8 saves disk and download only.
| Model | Package | Disk | Physical Peak | Max RSS | MLX Peak | Time | Profile |
|---|---|---|---|---|---|---|---|
| Wan2.2 T2V-A14B | BF16 | 64.1 GiB | 33.0 GiB | 31.8 GiB | 27.7 GiB | 152.7 s | 384x224, 33 frames, 12 steps, 8 fps |
| Wan2.2 T2V-A14B | mixed q8/BF16 | 39.5 GiB | 20.7 GiB | 19.5 GiB | 15.5 GiB | 154.8 s | 384x224, 33 frames, 12 steps, 8 fps |
| Wan2.2 I2V-A14B | BF16 | 64.1 GiB | 33.7 GiB | 31.8 GiB | 28.2 GiB | 228.2 s | 384x384, 33 frames, 12 steps, 8 fps |
| Wan2.2 I2V-A14B | mixed q8/BF16 | 39.5 GiB | 21.5 GiB | 19.6 GiB | 15.9 GiB | 242.2 s | 384x384, 33 frames, 12 steps, 8 fps |
In these runs, mixed q8/BF16 reduces disk usage by about 38% versus BF16 MLX-Gen packages; since 2026-06-12 it is not a runtime-memory or speed improvement. See docs/quantization.md for model-family quantization details and metrics JSON. The 0.18.11 release also validates the published A14B q8 T2V/I2V handles on a 41-frame, 15-step, 480x240-target profile with saved MP4/contact-sheet evidence in the quantization docs.
Ecosystem
MLX-Gen is used as the local Apple Silicon generation backend for:
- AbstractVision, the direct integration layer for abstracting generative image and video capabilities across local and hosted providers;
- AbstractCore, which can expose OpenAI-compatible endpoints backed by AbstractVision providers, including image and video capabilities;
- AbstractFlow, a visual workflow authoring layer that can compose generative image/video nodes alongside other media, text, and agent workflows.
MLX-Gen remains useful as a standalone CLI package, and it is also designed for applications: jobs run from model files already on disk, apps can inspect supported modes before loading weights, and progress callbacks make long runs observable.
Documentation
- Getting started: installation, first runs, SeedVR2 upscaling, and Wan video.
- API and CLI: command surface, router behavior, image-to-image modes, generative reframe, backend-specific outpaint, SeedVR2 sizing, Wan video sizes, capabilities, and Python entry points.
- Image edit modes: what latent img2img, edit-reference, multi-reference, generative reframe, and outpaint mean in practice, with examples.
- Wan video: practical Wan2.2 T2V/I2V sizing, plain and masked prompt-guided A14B video-to-video with included proof artifacts, a measured motion-fidelity ladder (strength vs gesture preservation), broader A14B target size families, and 5-second M5 Max comparison clips.
- Example workflow: reproducible image and video commands.
- Image upscaling: SeedVR2 sizing, published 3B/7B q8/q4 package usage, the host-safe video restore profile, published five-second Eiffel
1xand2x3B/7B validation bundles, readable tone-correction labels, and 5x source/output comparisons. - Image edit capabilities: image-edit contact sheets, exact model/package status, and command logs.
- Reframe and outpaint:
--reframe-paddingand--outpaint-paddingroutes with the mixed June 8 profile, FLUX.2 Klein base source-model validation, and links to the exact Qwen and FLUX route proofs. - Model management: download, prepare, and run from local model files.
- Quantization: q8/q4/BF16 policies and measurements.
- Python integration: route-resolved runtime loading, serial multi-output reuse for unified
mlxgen generatefamilies, SeedVR2's direct-model boundary, progress callbacks, and AbstractVision/AbstractCore notes. - FAQ: recurring questions, image-to-image mode selection, SeedVR2 sizing, Qwen edit variants, negative prompts, reframe/outpaint, Wan resolutions, and usage limits.
- Troubleshooting: common setup and runtime failures.
- Acknowledgements: upstream mflux and model-community credits.
License
MLX-Gen is MIT licensed. Model weights remain governed by their original licenses and access terms.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mlx_gen-0.19.0.tar.gz.
File metadata
- Download URL: mlx_gen-0.19.0.tar.gz
- Upload date:
- Size: 992.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ce192aacc33871ce6f603c4617418ef322e5670db3702e7c7c1d321b39aceb29
|
|
| MD5 |
d54fe663afa3ee7cfa77fb7bafaa5525
|
|
| BLAKE2b-256 |
3728f6a47feba21bbd709cfd5eb0e39b234ea50e00ae5f05dcbc09704d973e91
|
Provenance
The following attestation bundles were made for mlx_gen-0.19.0.tar.gz:
Publisher:
release.yml on lpalbou/mlx-gen
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mlx_gen-0.19.0.tar.gz -
Subject digest:
ce192aacc33871ce6f603c4617418ef322e5670db3702e7c7c1d321b39aceb29 - Sigstore transparency entry: 2083244720
- Sigstore integration time:
-
Permalink:
lpalbou/mlx-gen@6dbe72e9367fba88b654949feaabe1ad5f6dbe15 -
Branch / Tag:
refs/tags/v0.19.0 - Owner: https://github.com/lpalbou
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@6dbe72e9367fba88b654949feaabe1ad5f6dbe15 -
Trigger Event:
push
-
Statement type:
File details
Details for the file mlx_gen-0.19.0-py3-none-any.whl.
File metadata
- Download URL: mlx_gen-0.19.0-py3-none-any.whl
- Upload date:
- Size: 1.3 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
655ded73a7e22866392321b1c5752486ab401f40a17ae26770673f89a508293a
|
|
| MD5 |
4842bc92f20e7ed6c6490ca8a4e2bbf9
|
|
| BLAKE2b-256 |
3ef5d18e461b44182322e5b7726e21f2c31db4ab037f8e128dca361a424389de
|
Provenance
The following attestation bundles were made for mlx_gen-0.19.0-py3-none-any.whl:
Publisher:
release.yml on lpalbou/mlx-gen
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mlx_gen-0.19.0-py3-none-any.whl -
Subject digest:
655ded73a7e22866392321b1c5752486ab401f40a17ae26770673f89a508293a - Sigstore transparency entry: 2083244727
- Sigstore integration time:
-
Permalink:
lpalbou/mlx-gen@6dbe72e9367fba88b654949feaabe1ad5f6dbe15 -
Branch / Tag:
refs/tags/v0.19.0 - Owner: https://github.com/lpalbou
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@6dbe72e9367fba88b654949feaabe1ad5f6dbe15 -
Trigger Event:
push
-
Statement type:







