Mixed-precision quantization optimizer for LLMs on Apple Silicon (MLX)

Project description
mlx-optiq
Quantize, fine-tune and serve LLMs entirely on Apple Silicon.
Website: https://mlx-optiq.com | Docs: https://mlx-optiq.com/docs/ | Models: https://mlx-optiq.com/models | PyPI: https://pypi.org/project/mlx-optiq/ | HF org: https://huggingface.co/mlx-community
mlx-optiq is an optimizing compiler and runtime for MLX. It takes a full-precision model and turns it into the best version for a given memory/latency budget on your Mac, using per-layer sensitivity measurements instead of "uniform 4-bit everywhere". The same sensitivity signal drives every layer of the stack: weights, KV cache, LoRA fine-tuning, runtime adapter swapping.
pip install mlx-optiq
What's in v0.1.0
- Twelve pre-built OptIQ quants on Hugging Face. Qwen3.5, Qwen3.6, Gemma-4 families. Every one beats stock uniform 4-bit on the six-metric Capability Score.
- Six-benchmark Capability Score on every model card: MMLU + GSM8K + IFEval + BFCL + HumanEval + HashHop (long-context retrieval). Methodology.
- Speculative decoding everywhere. Qwen3.5 / Qwen3.6 quants ship a bundled MTP head (
mtp.safetensors) for ~1.4× decode viaoptiq serve --mtp. Gemma-4 quants pair with a small-assistant-bf16drafter viaoptiq serve --drafter. - DPO fine-tuning via
optiq lora train --method dpo. Same LoRA infrastructure, with a reference forward pass through the adapter at scale=0 (no second model load). - OptIQ Lab (
pip install "mlx-optiq[lab]"→optiq lab). Local web UI for chat, quantize, fine-tune, dataset construction, and live model swap. See screenshots below.
Why mlx-optiq
Stock mlx-lm treats every layer of a quantized model the same. mlx-optiq doesn't:
- Some layers are 50× more sensitive to quantization than others. mlx-optiq measures this once per model and assigns bits per-layer at the same average bits-per-weight. Every shipped quant beats stock uniform 4-bit on the six-metric Capability Score; the gains range from +0.17 (Qwen3.5-27B) to +13.57 (gemma-4-e4b-it).
- The same is true of the KV cache. Some attention layers' KV are catastrophic to quantize (layer 0 KV is ~56× more sensitive than the median), others are essentially lossless at 4-bit.
optiq serveruns a per-layer KV quant pipeline that keeps quality while cutting decode memory: up to +62 % decode tok/s at 64 k context vs fp16 KV on M3 Max. - LoRA fine-tuning should reuse that sensitivity signal too.
optiq lora trainassigns higher adapter rank to sensitive layers and lower rank to robust ones, so adapter capacity goes where it helps most. Supports both SFT and DPO. - One server, two protocols.
optiq serveexposes both the OpenAI/v1/chat/completionsand Anthropic/v1/messagesendpoints from the same process. Point Claude Code, the OpenAI SDK, the Anthropic SDK, or plaincurlat the same local URL. - Multi-adapter serving shouldn't reload the base model every time.
optiq serveimplements reversible mounted LoRA: keep N adapters resident on one base, switch per request via a ContextVar-isolated activation gate.
Plus a roofline latency model calibrated to Apple Silicon bandwidth for hardware-aware optimization.
The full stack at a glance
| Feature | CLI | Docs |
|---|---|---|
| Weight quantization | optiq convert |
How sensitivity works · CLI |
| KV cache quantization | optiq kv-cache |
KV-quant serving · CLI |
| OpenAI + Anthropic server | optiq serve |
KV-quant serving · Anthropic API |
| MTP / drafter spec decoding | optiq serve --mtp · --drafter |
MTP guide |
| Sensitivity-aware LoRA (SFT + DPO) | optiq lora train |
LoRA fine-tuning · Blog |
| Mounted hot-swap adapters | optiq.adapters.mount |
Adapters |
| Eval suite (6 benchmarks + score) | optiq eval --task all --score |
Eval framework |
| Local web UI | optiq lab |
OptIQ Lab |
| Latency prediction | optiq latency |
CLI |
Per-family getting-started guides: Qwen3.5 · Qwen3.6 · Gemma-4
Quickstart
Running a pre-built mlx-optiq model
Every mlx-optiq quant on Hugging Face works out of the box with stock mlx-lm:
from mlx_lm import load, generate
model, tok = load("mlx-community/Qwen3.5-9B-OptiQ-4bit")
print(generate(model, tok, prompt="Hello", max_tokens=50))
Installing mlx-optiq unlocks the rest: mixed-precision KV serving, LoRA fine-tuning (SFT + DPO), runtime hot-swap adapters, the dual-protocol server, MTP / drafter speculative decoding, and the local web UI. Bit-identical inference quality either way.
Serving with speculative decoding
# Qwen: the bundled MTP head gives ~1.4× decode via OptiqEngine
optiq serve --model mlx-community/Qwen3.5-9B-OptiQ-4bit --mtp
# Gemma-4: pair with the matching -assistant-bf16 drafter
optiq serve --model mlx-community/gemma-4-31B-it-OptiQ-4bit \
--drafter mlx-community/gemma-4-31B-it-assistant-bf16
--mtp and --drafter are mutually exclusive. Both expose the same OpenAI + Anthropic endpoints.
Serving with mixed-precision KV (and Claude Code)
# One-time per-layer KV sensitivity analysis
optiq kv-cache mlx-community/Qwen3.5-9B-OptiQ-4bit \
--target-bits 4.5 -o ./kv/qwen35_9b
# Server on :8080. Speaks BOTH OpenAI and Anthropic APIs.
optiq serve --model mlx-community/Qwen3.5-9B-OptiQ-4bit \
--kv-config ./kv/qwen35_9b/kv_config.json \
--max-tokens 32768 --temp 0.6 --top-p 0.95
Drive it from Claude Code by setting two env vars:
export ANTHROPIC_BASE_URL="http://localhost:8080"
export ANTHROPIC_API_KEY="not-used"
claude # now driven by your local quant
Or any OpenAI-compatible client:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8080/v1", api_key="not-used")
Fine-tuning with sensitivity-aware LoRA
Supervised fine-tuning (SFT) — the default:
# --rank-scaling by_bits assigns rank proportional to mlx-optiq's per-layer
# bit assignments: 8-bit layers get 2× the rank of 4-bit layers at the
# same average parameter budget.
optiq lora train mlx-community/Qwen3.5-9B-OptiQ-4bit \
--data ./my_training_data \
--rank 8 --rank-scaling by_bits \
--iters 1000 -o ./my_adapter
optiq lora info ./my_adapter # per-layer rank distribution
DPO from preference pairs:
# Data shape: one {"prompt": ..., "chosen": ..., "rejected": ...} per line.
# Reference forward pass runs through the same adapter with scale=0 — no
# second model load, no extra memory.
optiq lora train mlx-community/Qwen3.5-0.8B-OptiQ-4bit \
--data ./dpo_pairs --method dpo --dpo-beta 0.1 \
--preset small --iters 200 -o ./my_dpo_adapter
Adapter output is PEFT-compatible (adapter_config.json + adapters.safetensors) plus an mlx-optiq sidecar (optiq_lora_config.json) recording the per-layer rank distribution. Loads with any PEFT tool.
Serving with hot-swap adapters
# Preload an adapter at startup (HF repo id or local path)
optiq serve --model mlx-community/Qwen3.5-9B-OptiQ-4bit \
--adapter ./my_adapter
Converting a fresh model
pip install "mlx-optiq[convert]"
optiq convert Qwen/Qwen3.5-9B --target-bpw 5.0 --candidate-bits 4,8
optiq eval ./optiq_output/Qwen3.5-9B/optiq_mixed --task all --score
For models too large to fit in RAM as bf16, the default --reference auto builds a uniform-4-bit baseline first, then streams bf16 weights off disk one layer at a time to compute the calibration-driven sensitivity. This lets 27 B+ models still get a meaningful per-layer signal on a 36 GB Mac.
OptIQ Lab — local web UI
pip install "mlx-optiq[lab]" then optiq lab. Four workflow surfaces, one Flask process, password-gated, localhost-only.
Chat — streaming playground with web search, Python and bash tools in a three-tier sandbox.
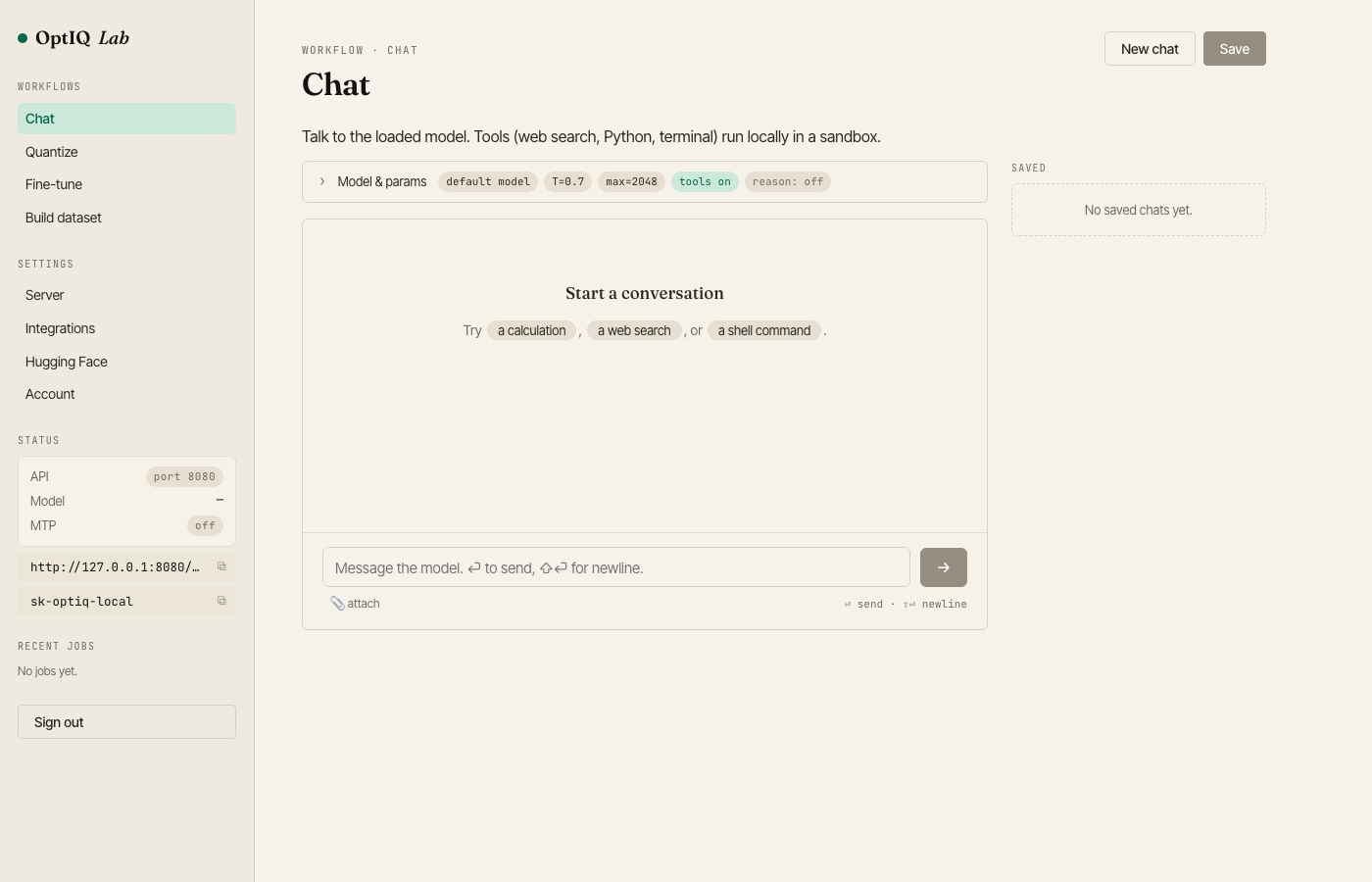
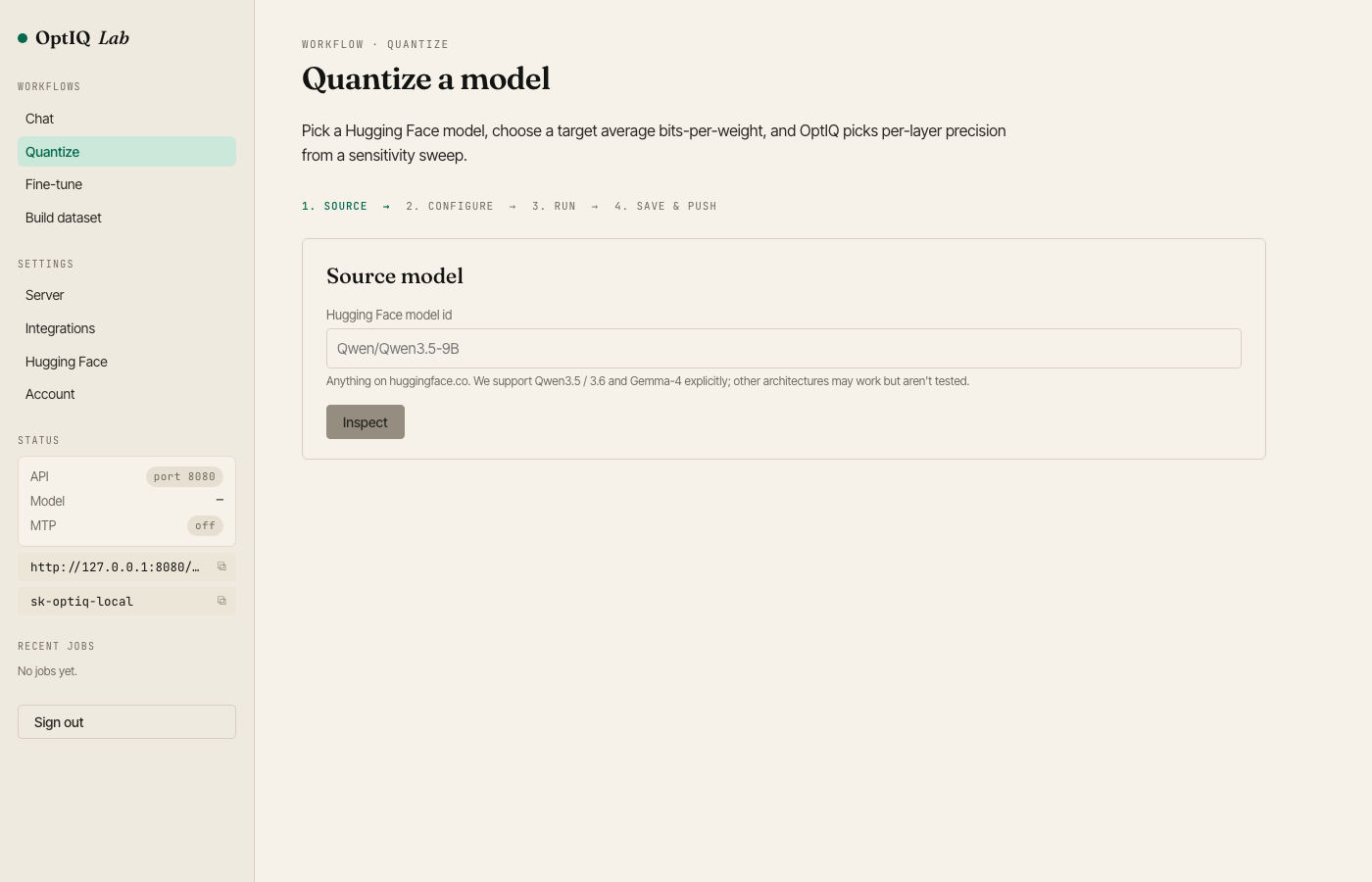
Quantize — paste an HF model id, slide a target-BPW dial, watch live sensitivity + knapsack progress, one-click push to your HF account.
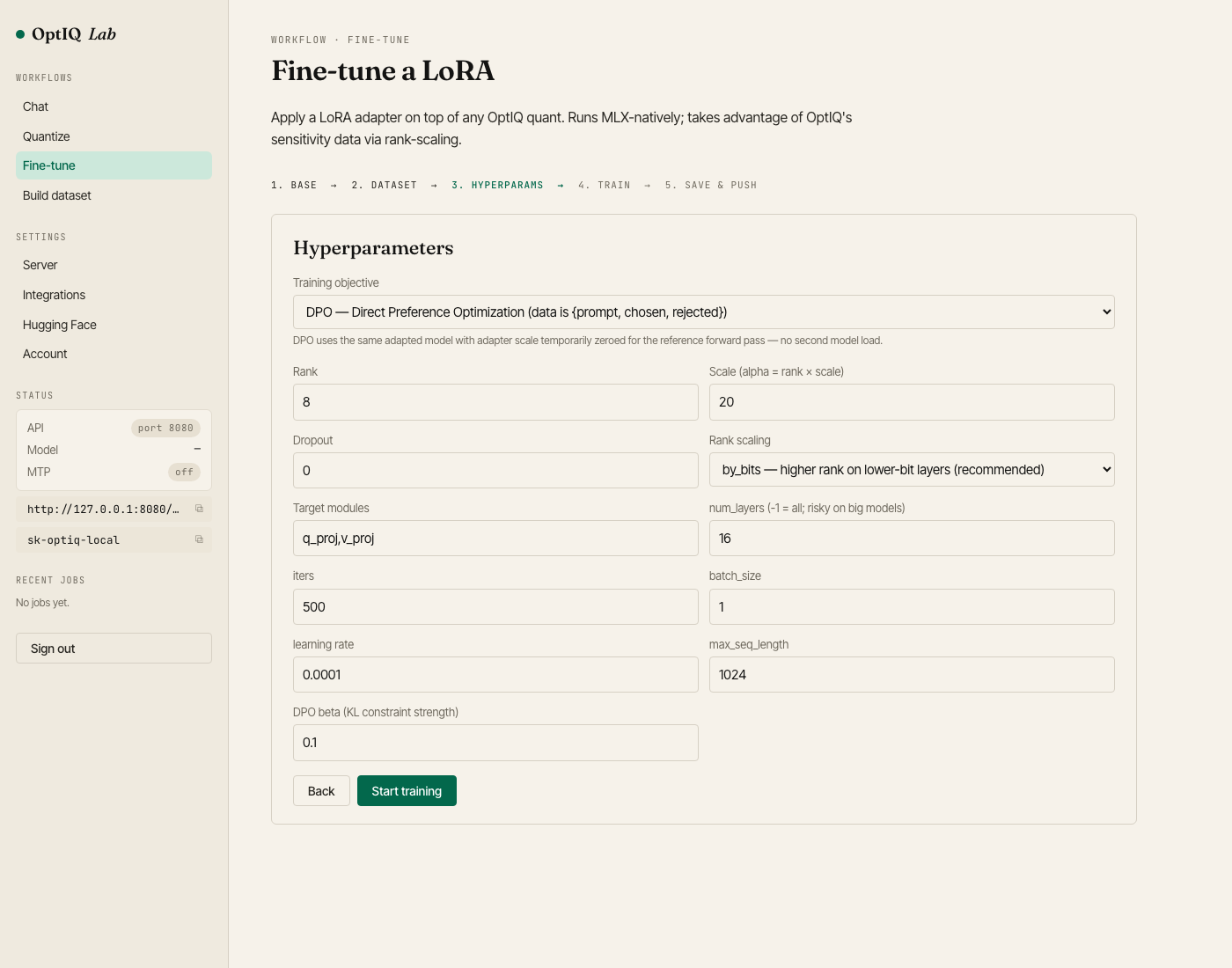
Fine-tune — SFT or DPO on any OptIQ quant, live train-loss sparkline, save + push to HF. DPO beta and method selection in the hyperparams step.
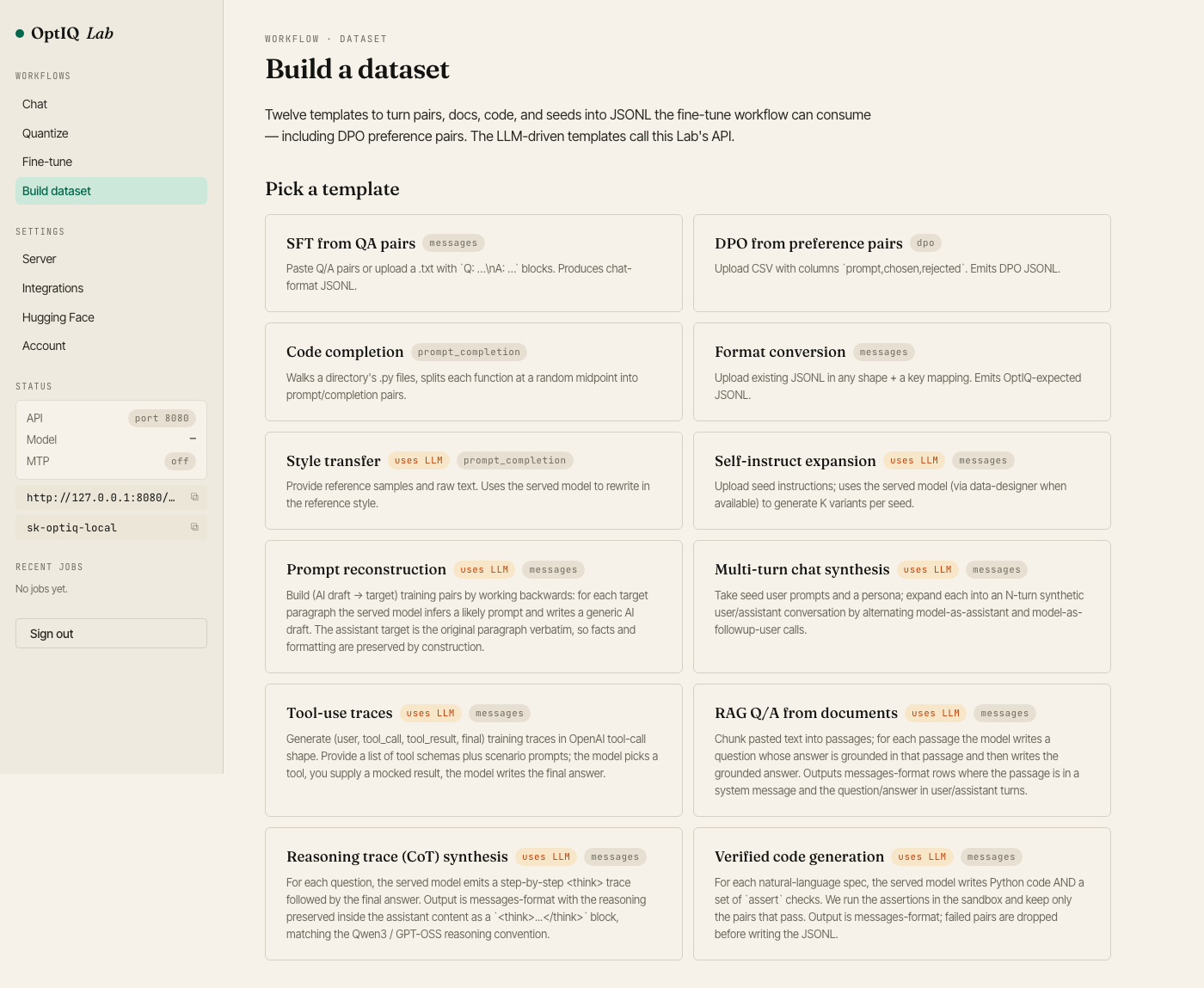
Build dataset — twelve templates: SFT from QA pairs, DPO preference pairs, style transfer, code completion, self-instruct expansion, RAG QA, multi-turn chat, and more. Outputs JSONL the fine-tune wizard reads directly.
Model server — load any local or HF OptIQ quant, toggle MTP, auto-suggest the matching Gemma-4 -assistant drafter, edit sampling overrides.
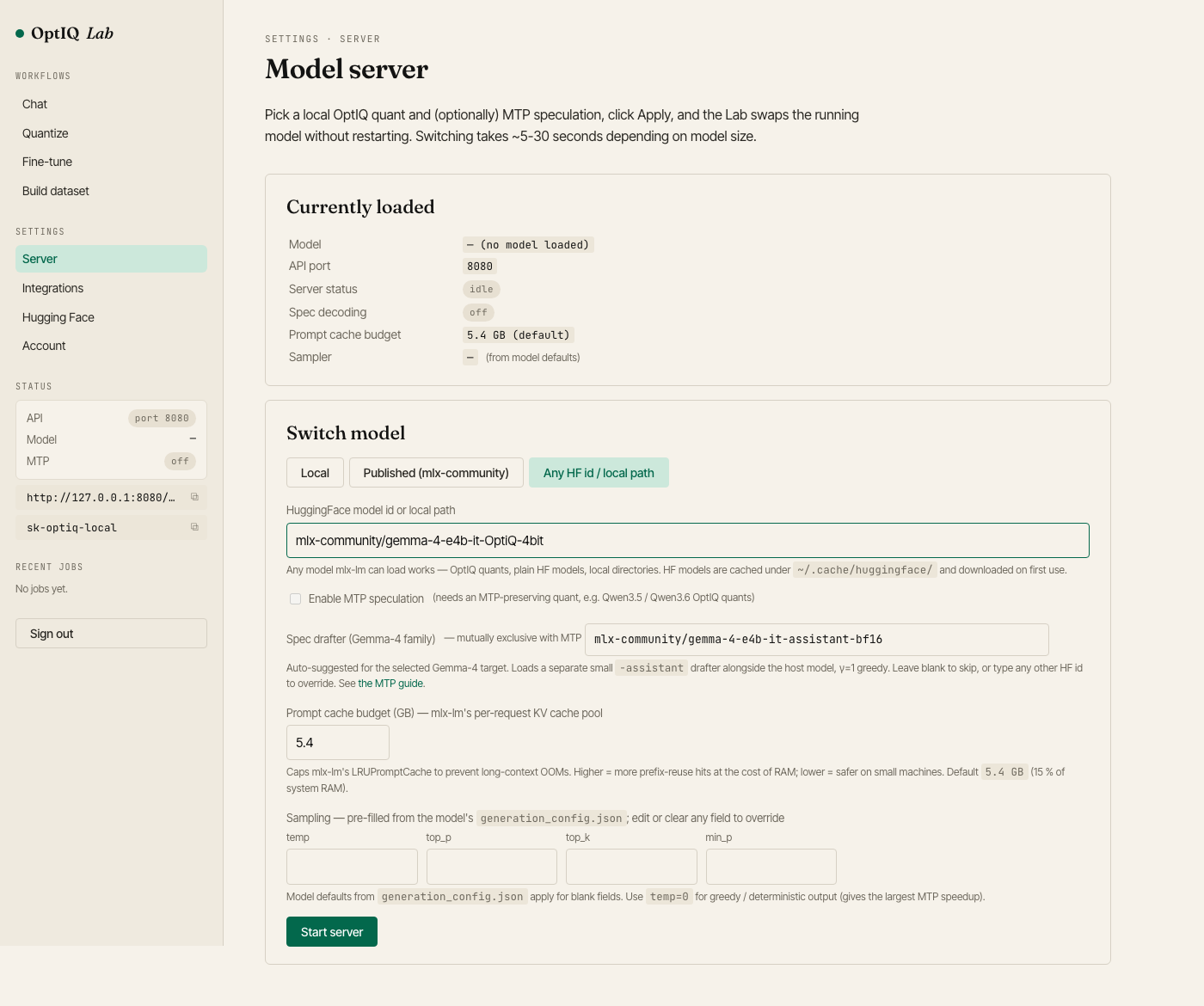
Full guide: OptIQ Lab docs.
Headline numbers
Capability Score (6-benchmark mean of MMLU + GSM8K + IFEval + BFCL + HumanEval + HashHop), mlx-optiq vs uniform 4-bit:
| Model | Uniform-4 | mlx-optiq | Δ |
|---|---|---|---|
| Qwen3.5-0.8B | 31.73 | 36.00 | +4.27 |
| Qwen3.5-2B | 45.54 | 47.66 | +2.12 |
| Qwen3.5-4B | 63.86 | 65.76 | +1.90 |
| Qwen3.5-9B | 66.58 | 66.77 | +0.19 |
| Qwen3.5-27B | 78.88 | 79.05 | +0.17 |
| Qwen3.5-35B-A3B | 73.75 | 74.17 | +0.42 |
| Qwen3.6-27B | 82.50 | 82.96 | +0.46 |
| Qwen3.6-35B-A3B | 75.67 | 76.78 | +1.12 |
| gemma-4-e2b-it | 51.09 | 53.21 | +2.12 |
| gemma-4-e4b-it | 52.28 | 65.84 | +13.57 |
| gemma-4-26B-A4B-it | 69.62 | 72.68 | +3.06 |
| gemma-4-31B-it | 76.23 | 79.69 | +3.47 |
12 of 12 quants beat uniform 4-bit on the 6-metric Capability Score. Full per-benchmark breakdowns: each model card on mlx-community. Methodology: eval-framework write-up.
Decode throughput at 64 k context, optiq serve mixed-precision KV vs fp16 on M3 Max 36 GB:
| Model | fp16 tok/s | mlx-optiq tok/s | Δ |
|---|---|---|---|
| Qwen3.5-2B | 27.9 | 41.8 | +50 % |
| Qwen3.5-4B | 8.1 | 13.1 | +62 % |
| Qwen3.5-9B | 20.7 | 27.1 | +31 % |
How it works
Weight quantization pipeline (optiq convert):
- Resolve the base model (Hugging Face snapshot, or a local path).
- Build the running model. Use bf16 if it fits in RAM, else a uniform-4-bit MLX baseline with bf16 weights streamed from disk per probe.
- For each linear layer × each candidate bit-width, simulate quantization and measure KL divergence between reference and quantized logits on the bundled
optiq.jsonlcalibration mix (40 samples across prose, reasoning, code, agent, tool-call, and constraint-bearing instruction domains; chat-template auto-applied). - Greedy knapsack: start every layer at the minimum bits, upgrade the layer with the best "KL-reduction-per-bit" ratio each step until the target BPW budget is spent. Protected layers (
lm_head,embed_tokens, first/last transformer blocks) always get the max bit-width. - MLX conversion via
mlx_lm.convert()with the per-layerquant_predicatefrom step 4.
KV cache pipeline (optiq kv-cache + optiq serve):
- Same sensitivity measurement applied to the KV cache: for each full-attention layer, replace that layer's KV with a quantized copy and measure KL on held-out prompts.
optiq servepatchesmlx_lm.serverto usemlx_lm.models.cache.QuantizedKVCacheat per-layer bit-widths.- At attention time,
mx.quantized_matmulreads packed KV directly. No fp16 materialization. On Apple Silicon, the 8-bit kernel is faster than the 4-bit kernel, so protecting one sensitive layer at 8-bit gives both quality AND a throughput bump.
Sensitivity-aware LoRA (optiq lora train):
- Read
optiq_metadata.json.per_layer, mlx-optiq's per-layer bit assignment. - Per target linear, derive rank:
rank_scaling=by_bitsgivesr = base_rank × (bits / 4), so 8-bit layers get 2× the rank of 4-bit at the same base. - SFT path: train via
mlx_lm.tuner.trainer.trainwith rank scaled per layer. - DPO path: standalone loop with reference logprobs from the same model at adapter scale=0. Standard DPO loss with
dpo_betacontrolling the KL penalty. - Save in PEFT-compatible format + mlx-optiq sidecar recording the per-layer rank distribution.
Speculative decoding (optiq serve --mtp / --drafter):
- MTP (Qwen3.5 / 3.6):
optiq convertpreserves DeepSeek-V3-style MTP head tensors as amtp.safetensorssidecar registered inconfig.json.--mtpenables ~1.4× decode via the bundled head; depth 1 is optimal on Apple Silicon. - Drafter (Gemma-4):
--drafter mlx-community/<name>-assistant-bf16loads a small companion model. γ=1 greedy speculation throughoptiq.runtime.spec; tokens are bit-identical to non-spec decode.
Mounted LoRA hot-swap (optiq.adapters.mount):
prepare_model_for_mounted_lorawalks every transformer block and wraps each target linear (q_proj,v_projby default) in aMountedLoRALinearthat holds a dict of{adapter_id: (A, B, scale)}plus the frozen base linear.mount_adapter_on_model(model, adapter_id, adapter_dir)loads adapter weights off disk and registers them on every MountedLoRALinear.- At inference, a
ContextVardecides which adapter is active.None→ base only.with AdapterActivation("A"):→ forward pass adds adapter A's residual. - ContextVar semantics mean concurrent asyncio tasks / threads with different active adapters don't step on each other.
When you need mlx-optiq vs bare mlx-lm
| Scenario | Bare mlx-lm |
mlx-optiq |
|---|---|---|
| Load + generate from an mlx-optiq HF model | ✅ | ✅ |
| Mixed-precision KV cache at serve time | ✅ | |
Anthropic-API endpoint (/v1/messages) for Claude Code |
✅ | |
| MTP / drafter speculative decoding | ✅ | |
| LoRA fine-tuning that uses the per-layer sensitivity data | ✅ | |
| DPO fine-tuning (preference learning) | ✅ | |
| Hot-swappable adapters in one serving process | ✅ | |
| Local web UI for chat / quantize / fine-tune / dataset | ✅ | |
| Six-benchmark eval suite + Capability Score | ✅ | |
| Fresh conversion of a new base model | ✅ |
For pure inference on published mlx-optiq models, bare mlx-lm is enough and gets bit-identical output. For everything else, install mlx-optiq.
Hybrid-attention note
Qwen3.5 interleaves linear-attention (GatedDeltaNet) and full-attention layers on a 4:1 ratio. Only 1 in 4 layers has a KV cache. optiq kv-cache skips the linear layers automatically. On Qwen3.5-4B/9B, you end up with 8 of 32 layers getting per-layer KV bit assignments, typically 7 @ 4-bit + 1 @ 8-bit protecting layer 3 (the first full-attention layer).
Resources
Site: mlx-optiq.com: overview, models, docs, blog.
Documentation:
- Installation · Using mlx-optiq quants · OptIQ Lab
- How sensitivity works · LoRA fine-tuning · KV-quant serving · MTP speculation
- Family guides: Qwen3.5 · Qwen3.6 · Gemma-4
- CLI reference · Models index · FAQ
For agents and IDEs: llms.txt. The entire library reference in one Markdown file you can drop into Claude Code, Cursor, or any agent context.
Blog:
- The eval framework that drives every quant we ship
- The calibration mix and what it caught
- MTP speculative decoding on Apple Silicon
- Gemma-4 speculative decoding with the assistant drafter
- Why u4 KV cache OOMs harder than fp16
- Sensitivity-aware LoRA: fine-tuning that respects the bit budget
- Lab chat tools: sandboxed Python, bash, web search
- Gemma-4 lands on mlx-optiq
- Not All Layers Are Equal: the research foundation
Requirements
- Python ≥ 3.11
- Apple Silicon Mac (for MLX)
mlx-lm ≥ 0.30
License
MIT
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mlx_optiq-0.1.1.tar.gz.
File metadata
- Download URL: mlx_optiq-0.1.1.tar.gz
- Upload date:
- Size: 1.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4e5c710e24c08d765569be88e23b168063f449895a7d2a41d6696c957f7489b6
|
|
| MD5 |
177f31edc844019cc638256c53f00eaa
|
|
| BLAKE2b-256 |
59df54ff289ef5cabd1a0f7107a50d64712eb0b8e00befa12fbfb2b4486ca472
|
File details
Details for the file mlx_optiq-0.1.1-py3-none-any.whl.
File metadata
- Download URL: mlx_optiq-0.1.1-py3-none-any.whl
- Upload date:
- Size: 1.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
62c44d3620ac1f491a003f8855b6902f943ba1d3217775102579c00adb5fc3f0
|
|
| MD5 |
4e54345614301df97ee6c5507df9430c
|
|
| BLAKE2b-256 |
fbf096349c9bd05cf71966be31d9bd0023c4be445fa1424ac572c6c25a598b9c
|







