mmore: Scalable multimodal document extraction pipeline for custom RAG integration.

Project description




Massive Multimodal Open RAG & Extraction
MMORE is an open-source, end-to-end pipeline to ingest, process, index, and retrieve knowledge from heterogeneous files: PDFs, Office docs, spreadsheets, emails, images, audio, video, and web pages. It standardizes content into a unified multimodal format, supports distributed CPU/GPU processing, and provides hybrid dense+sparse retrieval with an integrated RAG service (CLI, APIs).
👉 Read the paper for more details (OpenReview): MMORE: Massive Multimodal Open RAG & Extraction
:bulb: Quickstart
Installation
(Step 0 – Install system dependencies)
Our package requires system dependencies. This snippet will take care of installing them!
sudo apt update
sudo apt install -y ffmpeg libsm6 libxext6 chromium-browser libnss3 \
libgconf-2-4 libxi6 libxrandr2 libxcomposite1 libxcursor1 libxdamage1 \
libxext6 libxfixes3 libxrender1 libasound2 libatk1.0-0 libgtk-3-0 libreoffice \
libpango-1.0-0 libpangoft2-1.0-0 weasyprint
:warning: On Ubuntu 24.04, replace libasound2 with libasound2t64. You may also need to add the repository for Ubuntu 20.04 focal to have access to a few of the sources (e.g. create /etc/apt/sources.list.d/mmore.list with the contents deb http://cz.archive.ubuntu.com/ubuntu focal main universe).
Step 1 – Install MMORE
To install the package simply run:
pip install mmore
:warning: This is a big package with a lot of dependencies, so we recommend to use
uvto handlepipinstallations. Check our tutorial on uv.
Minimal Example
You can use our predefined CLI commands to execute parts of the pipeline. Note that you might need to prepend python -m to the command if the package does not properly create bash aliases.
# Run processing
python -m mmore process --config-file examples/process/config.yaml
python -m mmore postprocess --config-file examples/postprocessor/config.yaml --input-data examples/process/outputs/merged/merged_results.jsonl
# Run indexer
python -m mmore index --config-file examples/index/config.yaml --documents-path examples/process/outputs/merged/final_pp.jsonl
# Run RAG
python -m mmore rag --config-file examples/rag/config.yaml
You can also use our package in python code as shown here:
from mmore.process.processors.pdf_processor import PDFProcessor
from mmore.process.processors.base import ProcessorConfig
from mmore.type import MultimodalSample
pdf_file_paths = ["/path/to/examples/sample_data/pdf/calendar.pdf"] #write here the full path, not a relative path
out_file = "/path/to/examples/process/outputs/example.jsonl"
pdf_processor_config = ProcessorConfig(custom_config={"output_path": "examples/process/outputs"})
pdf_processor = PDFProcessor(config=pdf_processor_config)
result_pdf = pdf_processor.process_batch(pdf_file_paths, False, 1) # args: file_paths, fast mode (True/False), num_workers
MultimodalSample.to_jsonl(out_file, result_pdf)
Usage
To launch the MMORE pipeline, follow the specialised instructions in the docs.
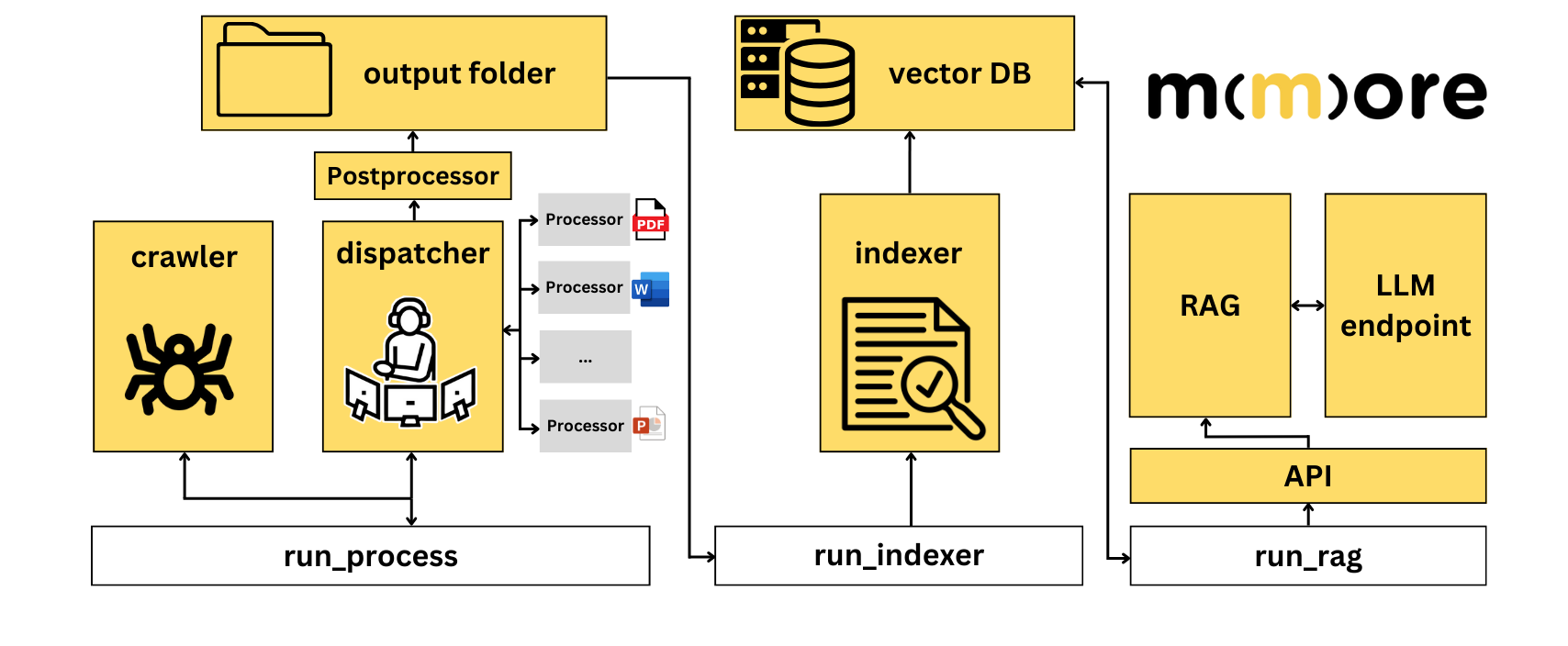
-
:page_facing_up: Input Documents Upload your multimodal documents (PDFs, videos, spreadsheets, and m(m)ore) into the pipeline.
-
:mag: Process Extracts and standardizes text, metadata, and multimedia content from diverse file formats. Easily extensible! You can add your own processors to handle new file types. Supports fast processing for specific types.
-
:file_folder: Index Organizes extracted data into a hybrid retrieval-ready Vector Store DB, combining dense and sparse indexing through Milvus. Your vector DB can also be remotely hosted and then you only have to provide a standard API. There is also an HTTP Index API for adding new files on the fly with HTTP requests.
-
:robot: RAG Use the indexed documents inside a Retrieval-Augmented Generation (RAG) system that provides a LangChain interface. Plug in any LLM with a compatible interface or add new ones through an easy-to-use interface. Supports API hosting or local inference.
-
:tada: Evaluation Coming soon An easy way to evaluate the performance of your RAG system using Ragas.
See the /docs directory for additional details on each modules and hands-on tutorials on parts of the pipeline.
:construction: Supported File Types
| Category | File Types | Supported Device | Fast Mode |
|---|---|---|---|
| Text Documents | DOCX, MD, PPTX, XLSX, TXT, EML | CPU | :x: |
| PDFs | GPU/CPU | :white_check_mark: | |
| Media Files | MP4, MOV, AVI, MKV, MP3, WAV, AAC | GPU/CPU | :white_check_mark: |
| Web Content | HTML | CPU | :x: |
Contributing
We welcome contributions to improve the current state of the pipeline, feel free to:
- Open an issue to report a bug or ask for a new feature
- Open a pull request to fix a bug or add a new feature
- You can find ongoing new features and bugs in the [Issues]
Don't hesitate to star the project :star: if you find it interesting! (you would be our star).
To make sure your code is pretty, this repo has a pre-commit configuration file that runs linters (isort, black)
- Install pre-commit if you haven't already
pip install pre-commit
- Set up the git hook scripts
pre-commit install
- Run the checks manually (optional but good before first commit)
pre-commit run --all-files
We also use pyright to type-check the code base, please make sure your Pull Requests are type-checked.
License
This project is licensed under the Apache 2.0 License, see the LICENSE :mortar_board: file for details.
Cite MMORE
If you use MMORE in your research, please cite the paper:
@inproceedings{sallinenm,
title={M (M) ORE: Massive Multimodal Open RAG \& Extraction},
author={Sallinen, Alexandre and Krsteski, Stefan and Teiletche, Paul and Marc-Antoine, Allard and Lecoeur, Baptiste and Zhang, Michael and Nemo, Fabrice and Kalajdzic, David and Meyer, Matthias and Hartley, Mary-Anne},
booktitle={Championing Open-source DEvelopment in ML Workshop@ ICML25}
}



Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mmore-1.1.1.tar.gz.
File metadata
- Download URL: mmore-1.1.1.tar.gz
- Upload date:
- Size: 64.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7c492d93a0c1cc7cb49bb0fd4e750d776b4e10c3f7666103d1cb1fbbb3d66209
|
|
| MD5 |
913b6294e08b507913b6029c3e9a2165
|
|
| BLAKE2b-256 |
4596576cbc74c898c9e472d75ecc75d6bf602e9f819622b7bd89bb0b6268e28a
|
Provenance
The following attestation bundles were made for mmore-1.1.1.tar.gz:
Publisher:
publish.yml on swiss-ai/mmore
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mmore-1.1.1.tar.gz -
Subject digest:
7c492d93a0c1cc7cb49bb0fd4e750d776b4e10c3f7666103d1cb1fbbb3d66209 - Sigstore transparency entry: 567837554
- Sigstore integration time:
-
Permalink:
swiss-ai/mmore@817ce5e7b4790a477b107313711755007e1deed9 -
Branch / Tag:
refs/tags/v1.1.1 - Owner: https://github.com/swiss-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@817ce5e7b4790a477b107313711755007e1deed9 -
Trigger Event:
release
-
Statement type:
File details
Details for the file mmore-1.1.1-py3-none-any.whl.
File metadata
- Download URL: mmore-1.1.1-py3-none-any.whl
- Upload date:
- Size: 205.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c180916d264ce1224d3bc8e51306895893ec2e0ecb909719faf79c0d0af46e6d
|
|
| MD5 |
e1b8889e9637c55e62bab8eea12ef588
|
|
| BLAKE2b-256 |
52f814ad7df60d04dfec00ce267bcaffb9ea60c356aa40776d9f035bd67c61cd
|
Provenance
The following attestation bundles were made for mmore-1.1.1-py3-none-any.whl:
Publisher:
publish.yml on swiss-ai/mmore
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mmore-1.1.1-py3-none-any.whl -
Subject digest:
c180916d264ce1224d3bc8e51306895893ec2e0ecb909719faf79c0d0af46e6d - Sigstore transparency entry: 567837566
- Sigstore integration time:
-
Permalink:
swiss-ai/mmore@817ce5e7b4790a477b107313711755007e1deed9 -
Branch / Tag:
refs/tags/v1.1.1 - Owner: https://github.com/swiss-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@817ce5e7b4790a477b107313711755007e1deed9 -
Trigger Event:
release
-
Statement type:







