LLM Context Compression and Retrieval Engine -- zero dependencies, sub-100ms queries, document + code ingestion
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

Mnemosyne
Intelligent code retrieval engine -- index, search, and compress any codebase with zero dependencies.




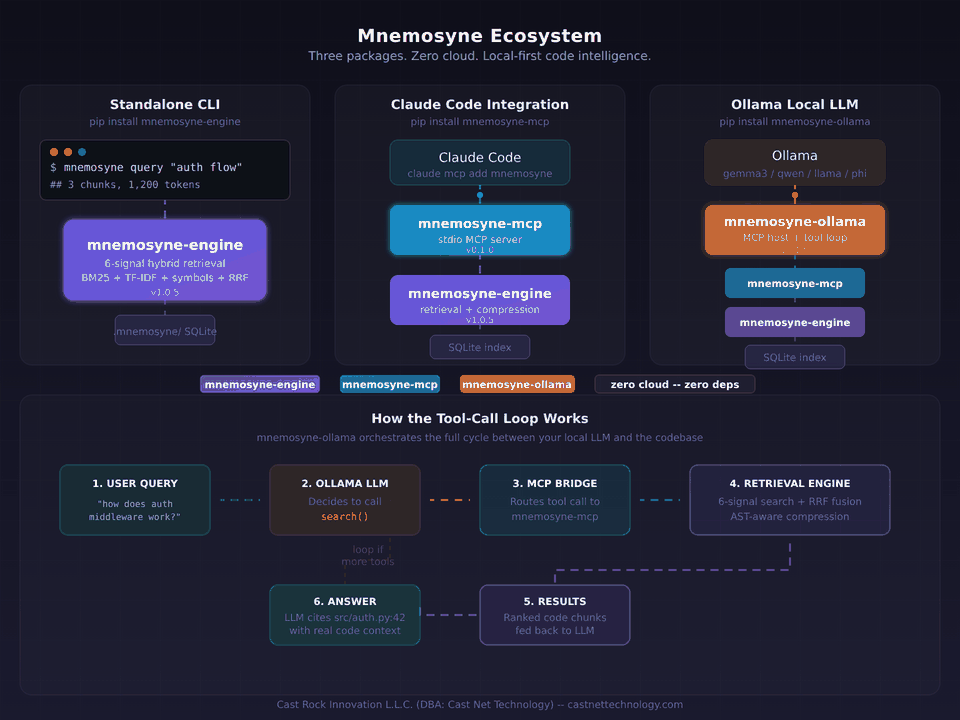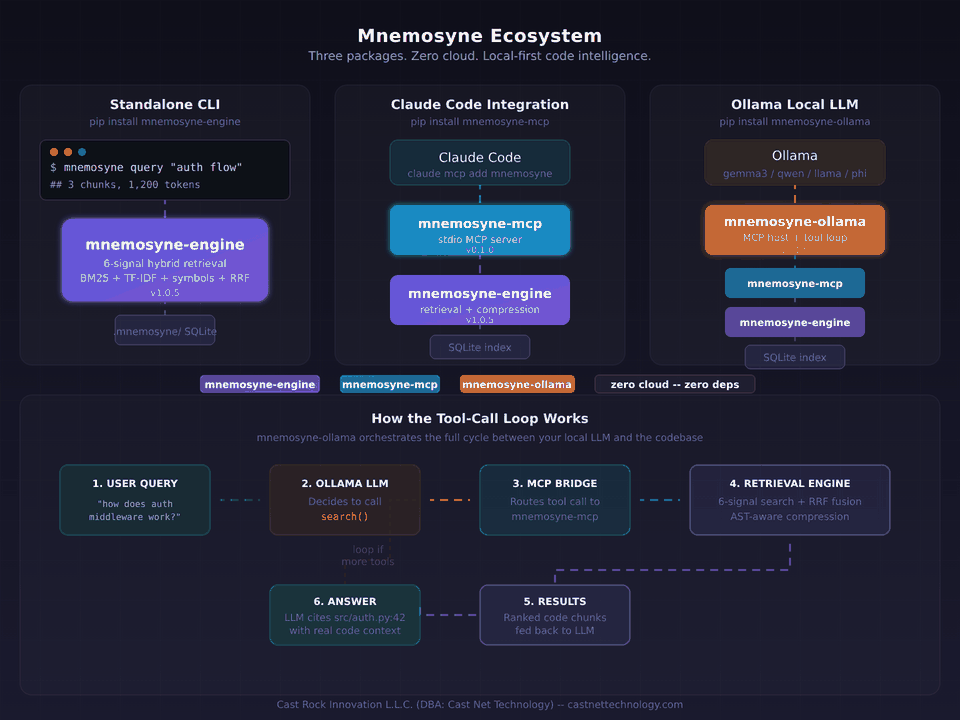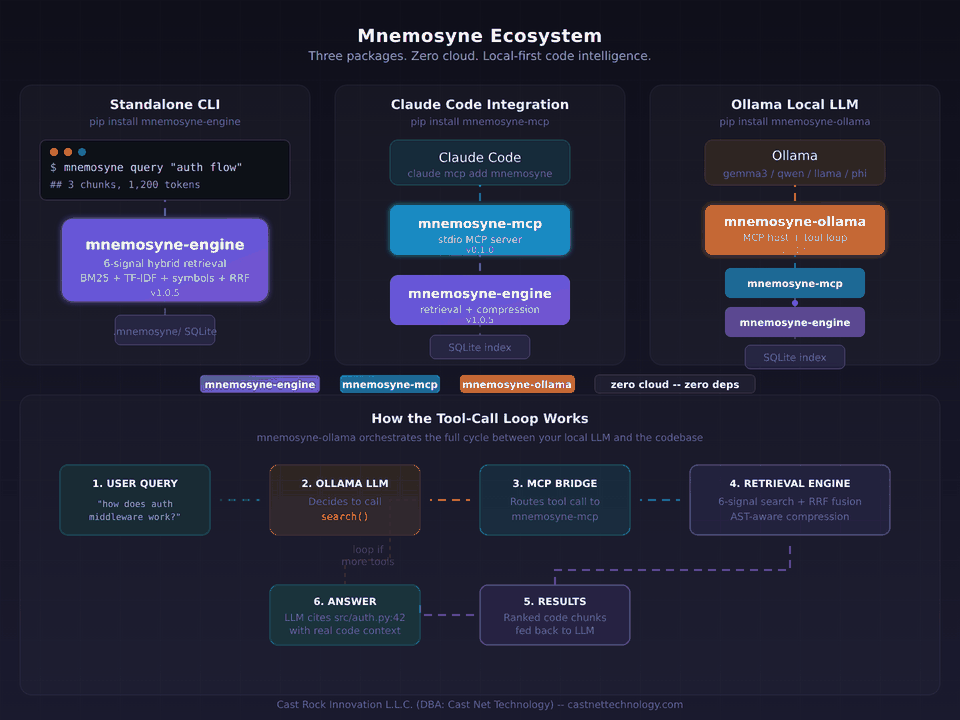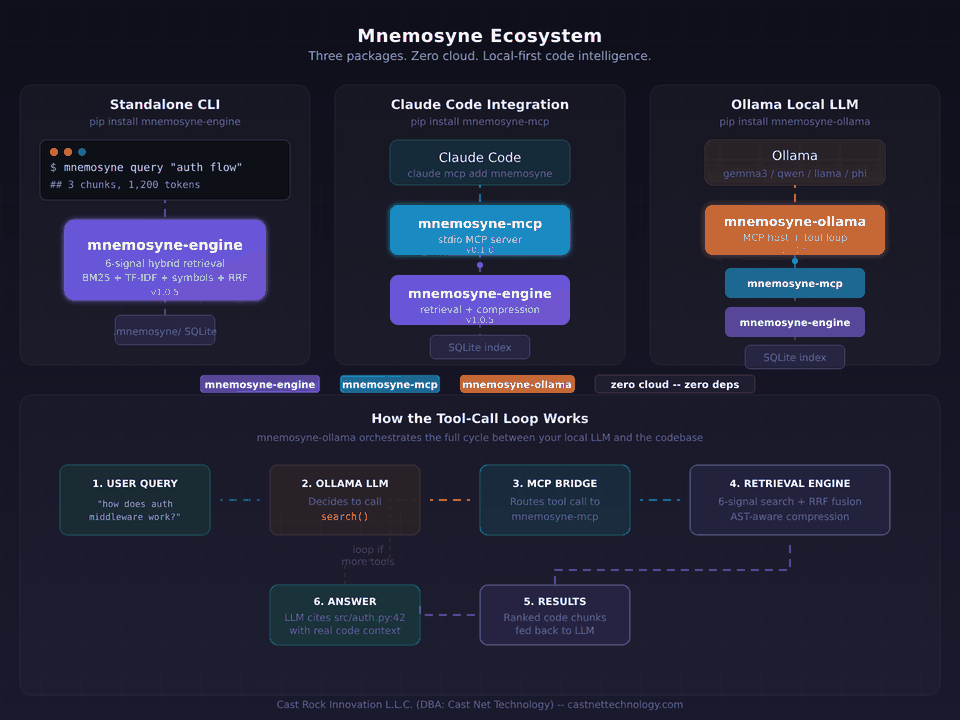
Mnemosyne indexes your codebase and documents into a local SQLite store, scores every chunk with a 6-signal hybrid retriever, compresses results with AST awareness, and returns exactly what you need within a token or result budget. Supports source code (Python, JS/TS, Go, Rust, C#, Java, Kotlin), documents (PDF, DOCX, CSV, plaintext), and database schemas (SQL DDL, JSON snapshots, SQLite introspection). It runs entirely locally -- no API keys, no cloud, no runtime dependencies beyond Python 3.11+.
Install
pip install mnemosyne-engine
Quick Start
mnemosyne init # create .mnemosyne/ workspace
mnemosyne ingest # index your codebase
mnemosyne query "How does authentication work?" # search
Performance
| Metric | Result |
|---|---|
| Query latency | <20ms warm, <500ms cold |
| Token reduction | 73% on 829-file production repo |
| File retrieval accuracy | 100% across all test sets |
| Ingestion speed | 167 files/sec (~0.5s for 87 files) |
| Compression | 40-70% per chunk, AST-aware |
| Memory footprint | 10-30 MB total |
| Storage overhead | ~4.2 bytes per indexed token |
Features
- Hybrid 6-signal search -- BM25, TF-IDF, symbol matching, usage frequency, predictive prefetch, and optional dense embeddings fused via Reciprocal Rank Fusion
- Cost-model ranking -- results ranked by value-per-token, not just relevance. Like a query optimizer for code retrieval
- AST-aware compression -- four-stage pipeline preserves signatures, docstrings, and control flow while collapsing boilerplate (20-60% reduction)
- Self-tuning ARC cache -- adapts between recency and frequency patterns automatically, persisted across sessions
- Delta-aware tracking -- detects file and chunk-level changes, delivers diffs instead of full content (80-95% savings on incremental queries)
- Content deduplication -- SHA-256 addressed storage eliminates duplicate chunks across files
- 7-language structural chunking -- Python (AST), JavaScript/TypeScript, Go, C#, Rust, Java, Kotlin
- Document ingestion -- PDF, DOCX, CSV, and plaintext extraction into an isolated document partition with independent BM25 + TF-IDF retrieval. Optional
mnemosyne-engine[pdf]extra for PDF support - Schema ingestion -- DDL files, JSON/YAML snapshots, and live SQLite introspection indexed alongside code for cross-domain queries
- Daemon mode -- JSON-RPC over Unix socket keeps indexes warm for sub-20ms queries
- Full audit trail -- append-only JSON-lines log of every operation
- Zero runtime dependencies -- pure Python 3.11+ stdlib. One
pip install, no conflicts
Use Cases
Code search and navigation -- Natural language queries return ranked, deduplicated results with function-level precision. Symbol-aware search finds implementations directly, not just string matches.
LLM context optimization -- Feed Claude, GPT, Cursor, or any LLM agent the right tokens from a 100K+ codebase. Drop-in integration via instruction files cuts API spend 70%+ on context-heavy workflows.
Developer onboarding -- New team members query "how does X work?" and get ranked results spanning models, middleware, and routes -- complete function signatures with context, not random line hits.
PR review and CI/CD -- Delta tracking identifies which functions changed and pulls their callers and tests into a review bundle. Pipe query output into automated review pipelines.
Legacy codebase archaeology -- Before a rewrite or migration, index a large monolith to answer "what calls this table?" or "which modules depend on this API?" Hybrid search beats grep for cross-cutting queries.
Security audit surface mapping -- Query for patterns like exec(, eval(, subprocess.call with usage-frequency ranking to prioritize the most-called dangerous patterns. Audit log provides evidence trail for compliance.
Incident response -- On-call engineer searches "payment timeout retry" at 3am. Gets ranked, compressed results across the codebase instead of grepping blindly.
Migration impact analysis -- Planning a framework upgrade or library swap? Query every usage of the old API, ranked by call frequency, to estimate effort and prioritize high-traffic paths.
MCP Server (Claude Code Integration)
For native Claude Code integration, install the MCP server addon:
pip install mnemosyne-mcp
claude mcp add mnemosyne -- mnemosyne-mcp
Claude Code will automatically call mnemosyne.search for code understanding, mnemosyne.index to build the index, and mnemosyne.stats for index info -- no manual CLI steps required. Everything runs locally over stdio. No API calls, no data egress.
See the full MCP Server Reference for configuration, tools, and integration details.
Ollama Integration (Local LLMs)
For local LLM code search via Ollama, install the Ollama bridge:
pip install mnemosyne-ollama
cd /your/project
mnemosyne-ollama "how does authentication work"
Auto-detects your Ollama model (Qwen, Llama, Phi, etc.), indexes if needed, searches with hybrid retrieval, and returns answers with file citations. Zero config, zero cloud.
See the Ollama bridge README for details.
LLM Agent Integration (CLI)
For agents that run shell commands (Cursor, Aider, Copilot, etc.), add to your CLAUDE.md, .cursorrules, or equivalent instruction file:
Before answering questions about this codebase, run:
! mnemosyne query "<question>" --budget 8000
Use the returned chunks as primary context. Only read additional files if needed.
Works with any agent that can execute shell commands.
CLI
| Command | Purpose |
|---|---|
init |
Create workspace and config |
ingest |
Index files (incremental, --full to rebuild) |
query |
Search with token budget (--docs, --all for document partition) |
stats |
Index and cache statistics |
schema-ingest |
Import database schema (DDL, JSON, SQLite) |
schema-stats |
Schema index statistics |
compress |
Preview compression for a file |
delta |
Show changes since last index |
cache |
Manage ARC cache (show, clear, warm) |
daemon |
Persistent server for warm-start queries |
analytics |
Precision metrics and usage patterns |
audit |
Operation log |
health |
Index integrity checks |
gc |
Garbage collect stale data |
benchmark |
Run precision benchmarks |
Documentation
| Document | Contents |
|---|---|
| MCP.md | MCP server reference -- installation, tools, configuration, architecture |
| ollama/README.md | Ollama bridge -- local LLM code search via tool-calling models |
| REFERENCE.md | Full CLI reference, configuration, architecture, integration guides |
| ALGORITHMS.md | Algorithm details with academic paper references |
| TUNING.md | Precision tuning guide |
| CHANGELOG.md | Version history |
Trademarks
All third-party product names (Claude Code, Ollama, Qwen, Llama, Gemma, Phi, Mistral, Command-R, Cursor, Aider, Copilot) are trademarks of their respective owners. Mnemosyne is an independent project and is not endorsed by or affiliated with any of these companies. Product names are used solely to describe compatibility.
License
Dual-licensed: AGPL-3.0 for open-source use | Commercial license for proprietary embedding.
Copyright 2026 Cast Rock Innovation L.L.C. (DBA: Cast Net Technology)
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mnemosyne_engine-1.1.0.tar.gz.
File metadata
- Download URL: mnemosyne_engine-1.1.0.tar.gz
- Upload date:
- Size: 221.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5aae3917e69ba9dc7425d132d47891b4706aae903463dda1aa00d714a4c3d2cc
|
|
| MD5 |
daaaa222d683210a1de1474f12f23b57
|
|
| BLAKE2b-256 |
a459d47f81b74235f6e0b85326fef91817cbe9f451f5c77e2c1a7545d1cb6969
|
Provenance
The following attestation bundles were made for mnemosyne_engine-1.1.0.tar.gz:
Publisher:
publish.yml on castnettech/mnemosyne
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mnemosyne_engine-1.1.0.tar.gz -
Subject digest:
5aae3917e69ba9dc7425d132d47891b4706aae903463dda1aa00d714a4c3d2cc - Sigstore transparency entry: 1247557269
- Sigstore integration time:
-
Permalink:
castnettech/mnemosyne@ef872bd5a9ab526ec5da6353e56acdce8dd210c9 -
Branch / Tag:
refs/tags/v1.1.0 - Owner: https://github.com/castnettech
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@ef872bd5a9ab526ec5da6353e56acdce8dd210c9 -
Trigger Event:
release
-
Statement type:
File details
Details for the file mnemosyne_engine-1.1.0-py3-none-any.whl.
File metadata
- Download URL: mnemosyne_engine-1.1.0-py3-none-any.whl
- Upload date:
- Size: 265.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
91de271246b2ca641d3b565db2177c1a203049acfc5c54788372d1cf17e5a581
|
|
| MD5 |
bb4b2cc9bf75332bd5ea25a087c772fe
|
|
| BLAKE2b-256 |
b4be074efab881771b700b52a7780e761ed6d077ab571fee6302d67b5b3e2e69
|
Provenance
The following attestation bundles were made for mnemosyne_engine-1.1.0-py3-none-any.whl:
Publisher:
publish.yml on castnettech/mnemosyne
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mnemosyne_engine-1.1.0-py3-none-any.whl -
Subject digest:
91de271246b2ca641d3b565db2177c1a203049acfc5c54788372d1cf17e5a581 - Sigstore transparency entry: 1247557279
- Sigstore integration time:
-
Permalink:
castnettech/mnemosyne@ef872bd5a9ab526ec5da6353e56acdce8dd210c9 -
Branch / Tag:
refs/tags/v1.1.0 - Owner: https://github.com/castnettech
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@ef872bd5a9ab526ec5da6353e56acdce8dd210c9 -
Trigger Event:
release
-
Statement type:







