Moises-Light: Resource-efficient Band-split U-Net for Music Source Separation
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Moises-Light





This is an unofficial PyTorch implementation of the Moises-Light architecture from "Moises-Light: Resource-efficient Band-split U-Net for Music Source Separation" (Hung et al., WASPAA 2025). The paper does not release code; this is an independent implementation based on the paper's description and the open-source implementations of DTTNet, BS-RoFormer, and SCNet.
Installation
Install from PyPI
pip install moises-light
Install from GitHub
pip install git+https://github.com/crlandsc/moises-light.git
Or, you can clone the repository and install it in editable mode for development:
git clone https://github.com/crlandsc/moises-light.git
cd moises-light
pip install -e .
Dependencies
- PyTorch (>=2.0)
- einops
- rotary-embedding-torch
Quick Start
import torch
from moises_light import MoisesLight, configs
# Use a preset
model = MoisesLight(**configs['paper_large'])
# Forward pass
x = torch.randn(1, 2, 264600) # [batch, channels, samples] 6s @ 44.1kHz
y = model(x) # [1, 4, 2, 264600] = [batch, stems, channels, samples]
# With auxiliary outputs interface (for training framework compatibility)
y, aux = model(x, return_auxiliary_outputs=True)
Preset Configurations
All presets use n_fft=6144, hop_size=1024, stereo input, and 4-stem output (vocals, drums, bass, other).
The paper truncates the STFT at 2048 bins (~14.7 kHz), zeroing everything above. While the original DTTNet paper noted that this truncation has little to no effect on SI-SDR scores, in practice these high frequencies are critical for perceptual audio quality — vocal air, cymbal shimmer, synth brightness, etc. all live above 15 kHz. This package includes fullband presets that extend processing to the full 0-22 kHz spectrum.
Extending to fullband requires increasing n_bands from 4 to 6 (to maintain 512 bins per band), and G must be divisible by n_bands for group convolutions. Since 56 is not divisible by 6, G must change. Two strategies are provided:
- Fullband matched-param — Pick the nearest valid G that keeps total params similar to the paper (G=60 or 36). This trades per-band capacity for full spectrum coverage within the same parameter budget. SI-SDR may decrease slightly since the same capacity is spread across 2 additional high-frequency bands.
- Fullband wide — Pick G so that
G/n_bandsmatches the paper's per-group channel count (84/6=14, matching 56/4=14). Each band retains the same representation power as the paper model, but total params increase ~1.8x. This may preserve metric performance while gaining full spectrum coverage.
Paper-Faithful (truncated spectrum, 0-14.7 kHz)
Faithful to the paper's architecture. Frequencies above ~14.7 kHz are zeroed.
| Preset | G | Bands | Per-group ch | Freq coverage | Params |
|---|---|---|---|---|---|
paper_large |
56 | 4 | 14 | 0-14.7 kHz | 4,660,592 |
paper_small |
32 | 4 | 8 | 0-14.7 kHz | 2,520,592 |
Fullband Matched-Param (full spectrum, 0-22 kHz, similar param budget)
Full spectrum via 6 bands of 512 bins (freq_dim=3072). G adjusted to keep param count close to paper variants.
| Preset | G | Bands | Per-group ch | Freq coverage | Params |
|---|---|---|---|---|---|
fullband_large |
60 | 6 | 10 | 0-22 kHz | 4,948,612 |
fullband_small |
36 | 6 | 6 | 0-22 kHz | 2,824,244 |
Fullband Wide (full spectrum, 0-22 kHz, matched per-group capacity)
Full spectrum with the same per-group channel capacity as the paper models.
| Preset | G | Bands | Per-group ch | Freq coverage | Params |
|---|---|---|---|---|---|
fullband_large_wide |
84 | 6 | 14 | 0-22 kHz | 8,354,908 |
fullband_small_wide |
48 | 6 | 8 | 0-22 kHz | 4,102,712 |
Architecture
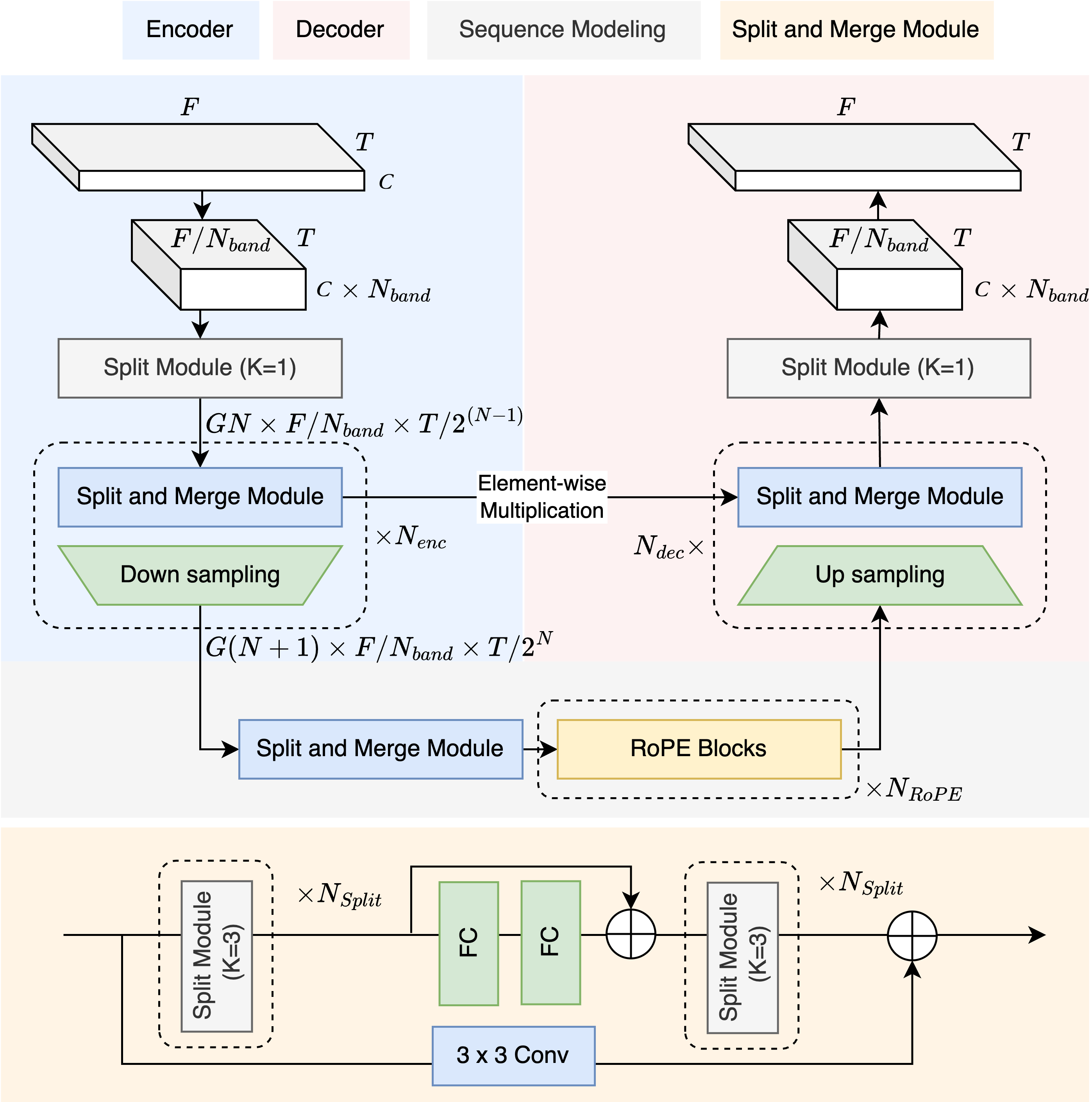
Moises-Light builds on the DTTNet foundation (a symmetric U-Net with TFC-TDF encoder/decoder blocks and dual-path RNN bottleneck) and integrates improvements from BS-RoFormer and SCNet:
- Band splitting via group convolutions (inspired by BSRNN/BS-RoFormer): Instead of DTTNet's full-spectrum convolutions, the STFT is divided into
n_bandsequal-width subbands and processed with group convolutions (Split Module). This replaces DTTNet's first/last 1x1 convolutions and dramatically reduces parameters compared to the original band-split MLPs in BSRNN. - Split and Merge Module (replaces DTTNet's TFC-TDF V3 blocks): Group conv blocks with
n_bandsgroups replace the original TFC layers, so each band is processed independently. The TDF (Time-Distributed Frequency FC) bottleneck is retained but now operates on per-band frequency dimensions (freq_dim / n_bands), which isn_bandstimes cheaper. - RoPE transformer bottleneck (from BS-RoFormer): DTTNet's dual-path RNN is replaced with dual-path RoPE transformers for sequence modeling along both frequency and time axes. This improves performance without significantly increasing parameters.
- Asymmetric encoder/decoder (from SCNet): The encoder has
n_encheavy stages (each with a full Split and Merge block), while the decoder uses onlyn_decheavy stages plusn_enc - n_declight stages (upsample + skip connection only, no Split and Merge). This saves significant compute in the decoder. - Frequency truncation (from DTTNet): Only
freq_dimof then_fft/2+1STFT bins are processed; the rest are zero-padded for iSTFT reconstruction. Paper presets truncate at ~14.7 kHz; fullband presets extend to ~22 kHz. - Multiplicative skip connections (from DTTNet): Decoder stages combine upsampled features with encoder skip connections via element-wise multiplication rather than concatenation or addition.
Implementation Notes
This is an independent implementation — the paper does not release code. The following decisions were made where the paper was ambiguous or where I diverged:
-
Asymmetric decoder interpretation: The paper specifies
N_enc=3, N_dec=1(Table 1) but doesn't explicitly state what happens with the remaining 2 decoder stages. I interpretN_dec=1as 1 heavy stage (with Split and Merge processing) and 2 light stages (upsample + skip connection only), matching the SCNet asymmetric pattern. -
Time-only downsampling: DTTNet downsamples both time and frequency dimensions (
T/2^NandF/2^N). Our implementation only downsamples time. The paper states that band-splitting "allows us to remove frequency pooling or upsampling across all DTTNet layers" (Sec 3.1), but doesn't explicitly confirm this removal in the final architecture. -
Transformer hyperparameters: The paper does not specify the RoPE transformer's internal dimensions. I use
heads=4, dim_head=32, ff_mult=2— chosen to keep the bottleneck lightweight and consistent with the model's parameter budget. -
Multiplicative masking: The paper states the model "directly generating the separated target spectrogram." By default (
use_mask=True), our implementation applies multiplicative masking on the original STFT (i.e., the network predicts a mask rather than the spectrogram directly). This is a common and effective approach in other SOTA models like BS-RoFormer and often leads to better perceptual quality, particularly for silent segments. Settinguse_mask=Falseswitches to the paper's direct spectrogram generation mode, where the network output produces spectrograms directly. -
Z-score normalization: The paper does not mention input normalization. I apply Z-score normalization (zero mean, unit variance) to the STFT features before the U-Net, inspired by HTDemucs-style preprocessing. This is standard practice in similar architectures and stabilizes training.
-
Multi-stem output: The paper trains separate per-stem models (4x ~5M params for VDBO). This implementation outputs all stems simultaneously via a shared encoder and source head, as this paradigm has proven effective in other U-Net models like HTDemucs and SCNet. To reproduce the paper's approach, train 4 separate single-stem models (e.g.,
MoisesLight(sources=['vocals'])).
Key Parameters
| Parameter | Description | Constraint |
|---|---|---|
G |
Base channel width. Channels at encoder stage i = G*(i+1) | Must be divisible by n_bands |
n_bands |
Number of equal-width frequency bands for group conv | freq_dim must be divisible by n_bands |
freq_dim |
Number of STFT bins to process (rest zero-padded) | Paper: 2048 (~~14.7 kHz). Fullband: 3072 (~~22 kHz) |
n_rope |
Number of dual-path RoPE transformer blocks in bottleneck | Paper large: 5, paper small: 6 |
n_enc / n_dec |
Encoder stages / heavy decoder stages | Asymmetric: n_dec < n_enc saves params |
n_split_enc / n_split_dec |
Number of group conv layers per SplitAndMerge block | Controls depth within each stage |
bn_factor |
TDF bottleneck factor (freq_dim -> freq_dim/bn_factor -> freq_dim) | Higher = more compression |
Integration
Custom Training Loop
model = MoisesLight(**configs['paper_large'])
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4)
for batch in dataloader:
mix = batch['mix'] # [B, 2, L]
targets = batch['targets'] # [B, 4, 2, L]
pred = model(mix) # [B, 4, 2, L]
loss = criterion(pred, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
Known Limitations
- MPS (Apple Silicon):
torch.istftdoes not support MPS. The model automatically falls back to CPU for iSTFT, which adds overhead. This is a PyTorch limitation, not a model issue. - Frequency truncation: Paper presets zero frequencies above ~14.7 kHz. Use fullband presets if high-frequency content matters.
Citation
@inproceedings{hung2025moises,
title={Moises-Light: Resource-efficient Band-split U-Net for Music Source Separation},
author={Hung, Yun-Ning and Pereira, Igor and Korzeniowski, Filip},
booktitle={2025 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
pages={1--5},
year={2025},
doi={10.1109/WASPAA66052.2025.11230925}
}
Contributing
Contributions are welcome! Please open an issue or submit a pull request if you have any bug fixes, improvements, or new features to suggest.
License
This project is licensed under the MIT License - see the LICENSE file for details.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file moises_light-0.1.1.tar.gz.
File metadata
- Download URL: moises_light-0.1.1.tar.gz
- Upload date:
- Size: 20.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9ce6151648219f28162c8e8304db9318a921a064069d9cfd8fafeba1ceec2a86
|
|
| MD5 |
394b1db89b0595b5f4c3bf9ba9d8f83d
|
|
| BLAKE2b-256 |
2f0209f8f7a9edd152e24e7705664f6482d7015258d9240e210d21c21e08e71d
|
Provenance
The following attestation bundles were made for moises_light-0.1.1.tar.gz:
Publisher:
pypi.yml on crlandsc/moises-light
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
moises_light-0.1.1.tar.gz -
Subject digest:
9ce6151648219f28162c8e8304db9318a921a064069d9cfd8fafeba1ceec2a86 - Sigstore transparency entry: 1135162946
- Sigstore integration time:
-
Permalink:
crlandsc/moises-light@661dadf63a5fb992aa997f40e3bcb115c6db5f7f -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/crlandsc
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi.yml@661dadf63a5fb992aa997f40e3bcb115c6db5f7f -
Trigger Event:
push
-
Statement type:
File details
Details for the file moises_light-0.1.1-py3-none-any.whl.
File metadata
- Download URL: moises_light-0.1.1-py3-none-any.whl
- Upload date:
- Size: 16.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7e7c3f8f07a4c64c1162936c09b778ae4869d96877cc3e3d87b9aefe93fe6bb3
|
|
| MD5 |
08a6c948908622fb679fef52a51dcbdd
|
|
| BLAKE2b-256 |
6f64ad4de170a9422797fc32738b31db2e321f5f395ff45665957008678ca8f8
|
Provenance
The following attestation bundles were made for moises_light-0.1.1-py3-none-any.whl:
Publisher:
pypi.yml on crlandsc/moises-light
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
moises_light-0.1.1-py3-none-any.whl -
Subject digest:
7e7c3f8f07a4c64c1162936c09b778ae4869d96877cc3e3d87b9aefe93fe6bb3 - Sigstore transparency entry: 1135163018
- Sigstore integration time:
-
Permalink:
crlandsc/moises-light@661dadf63a5fb992aa997f40e3bcb115c6db5f7f -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/crlandsc
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi.yml@661dadf63a5fb992aa997f40e3bcb115c6db5f7f -
Trigger Event:
push
-
Statement type:







