A lightweight toolkit for de novo molecular generation (SMILES/SELFIES; CharRNN, MolGPT, VAE)
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description






A lightweight, modern toolkit for de novo molecular generation with deep sequence models. It provides atom-level SMILES and SELFIES tokenizers, several generator architectures, a mixed-precision training loop, configurable sampling, and a MOSES-style evaluation suite — small enough to train on a single GPU in minutes, but reflecting current practice.

Features
- Representations — atom-aware regex SMILES tokenizer and a SELFIES tokenizer (every sequence decodes to a valid molecule).
- Models — a Transformer β-TC-VAE, a GRU/LSTM
CharRNN, and a decoder-onlyMolGPT. - Training — teacher-forced loop with AdamW, gradient clipping, and automatic mixed precision (AMP) on CUDA.
- Sampling — autoregressive generation with temperature, top-k, and top-p (nucleus) filtering.
- Metrics — validity, uniqueness, novelty, internal diversity, unique scaffolds, SNN, and QED / logP / MW / SA-score property summaries.
- Tooling —
molgenCLI, a bundled sample dataset, tests, CI, and ruff.
Installation
git clone https://github.com/DaoyuanLi2816/molgen.git
cd molgen
pip install -e . # add ".[selfies]" for SELFIES, ".[dev]" for tests
Quickstart (Python)
from molgen.data import build_dataloaders, load_sample_smiles
from molgen.tokenizers import SmilesTokenizer
from molgen.molgpt import MolGPT
from molgen.trainer import TrainConfig, train_language_model
from molgen.sampling import sample
from molgen.metrics import evaluate_generation
smiles = load_sample_smiles() # bundled sample, or your own list
tokenizer = SmilesTokenizer.from_smiles(smiles)
train_loader, val_loader = build_dataloaders(smiles, tokenizer, augment=True)
model = MolGPT(tokenizer.vocab_size, pad_idx=tokenizer.pad_id)
train_language_model(model, train_loader, val_loader, TrainConfig(epochs=20), pad_idx=tokenizer.pad_id)
generated = sample(model, tokenizer, num_samples=1000, top_p=0.95)
print(evaluate_generation(generated, reference=smiles))
Quickstart (CLI)
molgen train --data molecules.smi --model molgpt --epochs 20 --out model.pt
molgen sample --checkpoint model.pt --num 1000 --top-p 0.95 --out generated.smi
molgen eval --generated generated.smi --reference molecules.smi
Example output
Training MolGPT on the bundled (synthetic) sample and sampling 300 molecules
produces a report like:
n_generated: 300
validity: 0.30
uniqueness: 0.96
novelty: 0.90
internal_diversity: 0.90
unique_scaffolds: 0.32
snn: 0.47
properties: {'qed': 0.52, 'logp': 1.71, 'mol_weight': 133.2, 'sa_score': 2.70}
These numbers reflect the tiny bundled sample — train on MOSES/QM9/ZINC for stronger models. (SELFIES mode guarantees 100% validity.)
Visualizations
Both figures come from real model output and are reproducible with
python scripts/make_figures.py (trains a SELFIES MolGPT on the bundled sample).
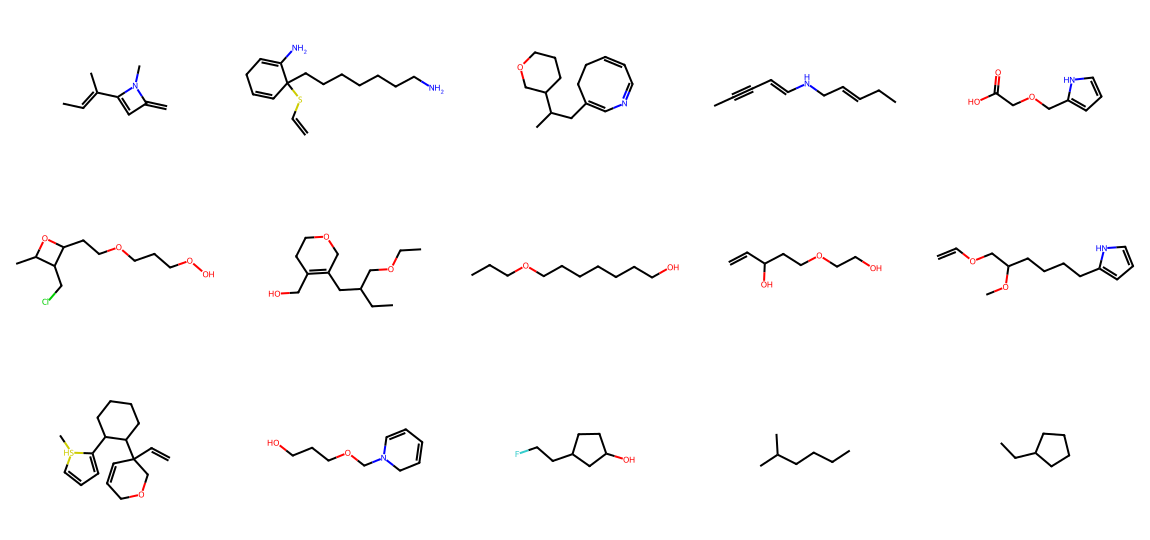
Generated molecules — structures sampled directly from the trained model:
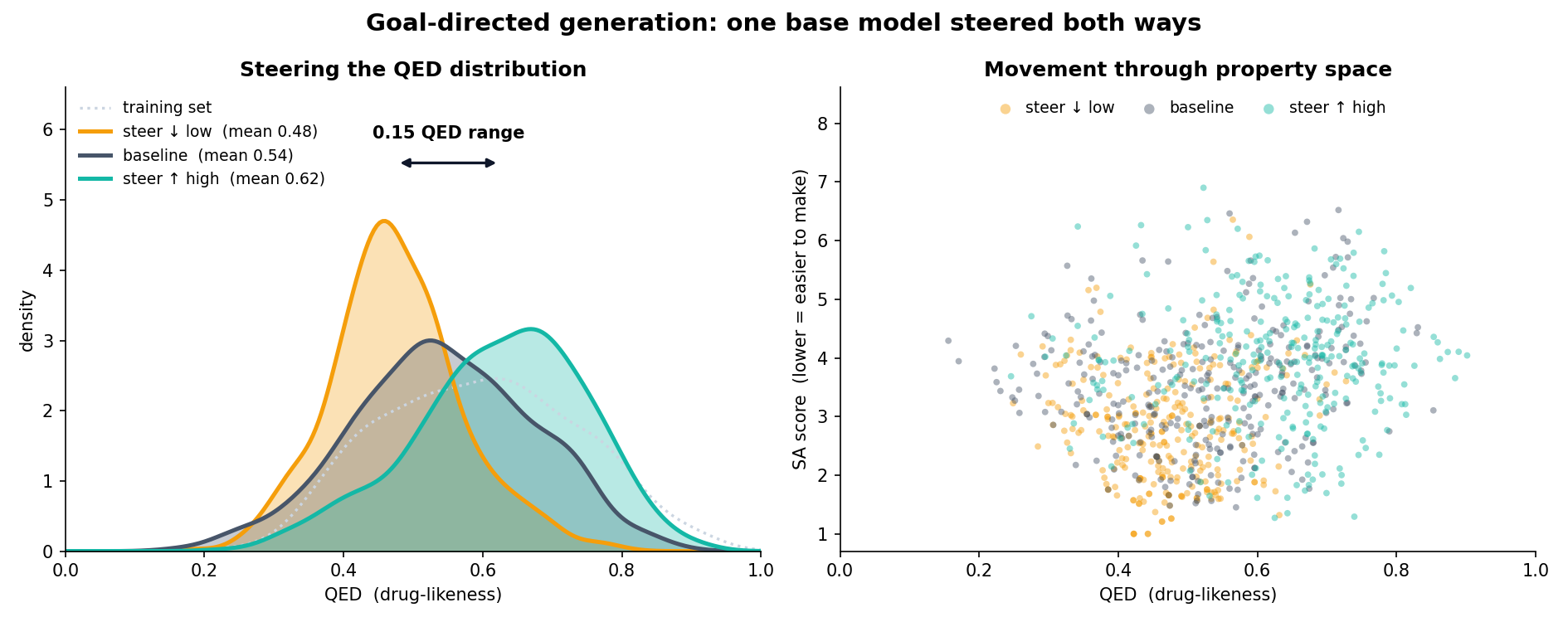
Goal-directed generation — from a single base model, fine-tuning toward the most (or least) drug-like molecules steers the generated QED distribution in both directions (a ~0.15 QED span) and moves the samples through QED-vs-SA property space. Generation can be steered toward a target, not just imitated:
Models
| Model | Module | Description |
|---|---|---|
CharRNN |
molgen.char_rnn |
GRU/LSTM next-token language model (classic strong baseline) |
MolGPT |
molgen.molgpt |
Decoder-only Transformer with causal attention |
BetaTCVAE |
molgen.vae |
Transformer VAE for reconstruction and latent interpolation |
Both CharRNN and MolGPT train and sample through the same trainer/sampler.
Latent-space exploration (VAE)
The original VAE workflow is still available for generating molecules near a seed or interpolating between two molecules in latent space:
python -m molgen.synthetic # build a synthetic dataset (molecules.csv)
python -m molgen.vae # train the VAE
python -m molgen.generate # perturb the latent space
python -m molgen.interpolate # interpolate between two molecules
Project structure
molgen/
├── chem.py # validity / canonicalization / randomization (RDKit)
├── tokenizers.py # atom-level regex SMILES tokenizer
├── selfies_tokenizer.py # SELFIES tokenizer (always-valid decoding)
├── data.py # SmilesDataset, padding collate, augmentation, sample loader
├── synthetic.py # synthetic dataset generators
├── vae.py # Transformer β-TC-VAE
├── char_rnn.py # GRU/LSTM language model
├── molgpt.py # decoder-only Transformer
├── trainer.py # AMP training loop
├── sampling.py # temperature / top-k / top-p decoding
├── metrics.py # validity, novelty, diversity, scaffolds, SNN, report
├── properties.py # QED / logP / MW / SA score
├── checkpoint.py # save & load model + tokenizer
├── cli.py # `molgen` command-line interface
└── datasets/ # bundled sample SMILES
Notes
The bundled load_sample_smiles() set is synthetic (assembled from
fragments) and intended for examples and tests; for real results, train on a
dataset such as MOSES, QM9, or ZINC. SELFIES mode guarantees 100% validity;
SMILES mode tends to learn the data distribution more faithfully.
Contributing
Contributions are welcome — see CONTRIBUTING.md. Please run
ruff check ., ruff format ., and pytest before opening a pull request.
Citation
If you use this toolkit in your work, please cite it via the Cite this
repository button on GitHub (metadata in CITATION.cff).
License
This project is licensed under the MIT License. See LICENSE.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file molgen-0.1.1.tar.gz.
File metadata
- Download URL: molgen-0.1.1.tar.gz
- Upload date:
- Size: 37.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
785ea42aeea7bf8c4f42e1154162565327ea83305758035f6b96cce5e51ece46
|
|
| MD5 |
0095ba2b3136738e0c529e45c93054e2
|
|
| BLAKE2b-256 |
089bf48d6e5dc1aebdf8e377f8240857315cda83eb567e59dd5ee8fc4e60db41
|
Provenance
The following attestation bundles were made for molgen-0.1.1.tar.gz:
Publisher:
release.yml on DaoyuanLi2816/molgen
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
molgen-0.1.1.tar.gz -
Subject digest:
785ea42aeea7bf8c4f42e1154162565327ea83305758035f6b96cce5e51ece46 - Sigstore transparency entry: 1787633654
- Sigstore integration time:
-
Permalink:
DaoyuanLi2816/molgen@194cb76bf691ee4dbab591ef32fc077b75790b02 -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/DaoyuanLi2816
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@194cb76bf691ee4dbab591ef32fc077b75790b02 -
Trigger Event:
release
-
Statement type:
File details
Details for the file molgen-0.1.1-py3-none-any.whl.
File metadata
- Download URL: molgen-0.1.1-py3-none-any.whl
- Upload date:
- Size: 33.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
626ac634351ef970b2e0993c47d1096731790f60c09f6b1fb0ca02c53386437f
|
|
| MD5 |
44e54bf624f45ec43f9d1bda897d6196
|
|
| BLAKE2b-256 |
6955d0c1326ad86d9cb70697b4e5ae3bb1a1f0b02ca6f634d9c2a3929cfd1e9f
|
Provenance
The following attestation bundles were made for molgen-0.1.1-py3-none-any.whl:
Publisher:
release.yml on DaoyuanLi2816/molgen
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
molgen-0.1.1-py3-none-any.whl -
Subject digest:
626ac634351ef970b2e0993c47d1096731790f60c09f6b1fb0ca02c53386437f - Sigstore transparency entry: 1787633727
- Sigstore integration time:
-
Permalink:
DaoyuanLi2816/molgen@194cb76bf691ee4dbab591ef32fc077b75790b02 -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/DaoyuanLi2816
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@194cb76bf691ee4dbab591ef32fc077b75790b02 -
Trigger Event:
release
-
Statement type:







