Zero-config semantic search for any MongoDB database.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
mongosemantic
Zero-config semantic search for any MongoDB database.
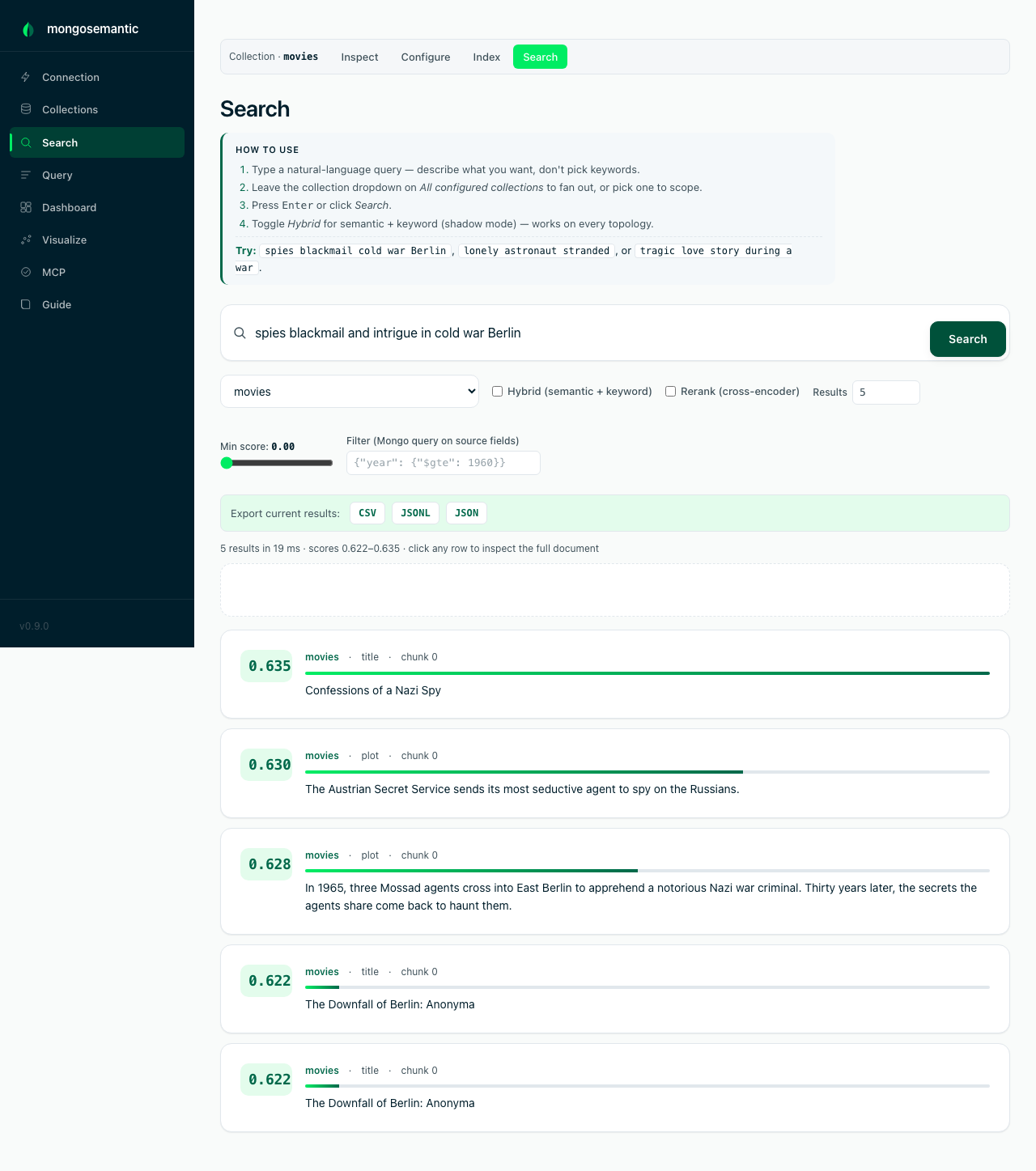
A meaning-only query — none of these results contain the words "spies" or "blackmail" as keywords. 17 ms over 45k embedded chunks via the embedded HNSW index, on a plain self-hosted replica set.
What is it
mongosemantic is a Python toolkit — CLI, web dashboard, and MCP server — that adds search-by-meaning to the MongoDB you already run. Point it at a database, pick a text field, and it embeds your documents with a local model, keeps the embeddings in sync as your data changes, and answers natural-language queries ("a washed-up boxer gets one last shot at redemption") from the CLI, a browser, or directly to AI agents over MCP.
No separate vector database. No ETL. No embedding API bill. Works on Atlas, self-hosted replica sets, and standalone MongoDB 7.0+.
Why it exists
Adding semantic search to an existing MongoDB app today usually means one of three things:
- Bolt on a vector database (Pinecone, Weaviate, Qdrant, …) — new infrastructure, an ETL pipeline to keep two systems consistent, and a second source of truth to operate forever.
- Use Atlas Vector Search directly — solid when you're on Atlas with
Search-index slots to spare, but the embedding pipeline is still on
you: chunking, batching, re-embedding on update, model upgrades. The
managed alternatives are constrained — Atlas auto-embedding is a metered
preview tied to one model family, and the Community 8.2 search preview
requires running a separate
mongotbinary. - Send documents to an embedding API — your data leaves your machines, and you pay per token, forever.
mongosemantic is the missing pipeline-and-product layer on top of the
database you already have: free local embeddings (your data never leaves
the box), any MongoDB 7.0+ topology with zero extra infrastructure, and
all the unglamorous parts handled — change-stream sync, a self-healing job
queue, chunking, index management, online model migration. Search by
meaning is one apply away.
Why you'd pick it
- Local-first and free — embeddings are computed on your machine with sentence-transformers; documents never leave your network and there is no per-token meter. OpenAI/Ollama models are opt-in, not required.
- Any MongoDB, zero new infra — Atlas, replica set, or standalone 7.0+. No vector database, no sidecar process, no ETL. Embeddings live in MongoDB next to your data (a shadow collection, or inline on the doc).
- Fast without Atlas — an embedded HNSW index makes self-hosted search ~15 ms over 45k chunks instead of a 2.5 s brute-force scan.
- Search quality built in — hybrid semantic+keyword search on every topology, metadata filters that need no reindex, and a local cross-encoder reranker. Capabilities that usually require Atlas Search tiers or external services, all local.
- Never stale — change streams (or polling on standalone) re-embed documents as they change; a self-healing job queue reclaims stalled work automatically.
- Model freedom — five models from free-local to OpenAI, and an online migration command that swaps a collection to a new model with near-zero downtime and a rollback archive.
- Three interfaces, one state — CLI for scripts, a web dashboard for humans, and an MCP server so Claude Desktop / Cursor / any AI agent can query your data by meaning. All share the same saved connection.
How to use it
pip install mongosemantic
export MONGOSEMANTIC_URI="mongodb+srv://user:pass@cluster.mongodb.net/my_db"
export MONGOSEMANTIC_DB="my_db"
mongosemantic inspect --collection articles # 1. score fields for suitability
mongosemantic apply --collection articles --field body # 2. configure + create indexes
mongosemantic index --collection articles # 3. bulk-embed existing docs
mongosemantic worker & # 4. keep embeddings in sync
mongosemantic search "budget travel" # 5. search by meaning
That's the whole loop: inspect tells you which fields are worth
embedding, apply configures the collection (and creates Atlas indexes
where applicable), index enqueues existing documents, the worker
embeds them and stays running to catch changes, and search queries by
meaning — with --filter, --rerank, and --hybrid available from day
one.
Prefer a UI? The dashboard does everything the CLI does, plus observability:
mongosemantic ui # http://127.0.0.1:8080
It runs an embedded worker, so ui alone is a complete deployment.
Localhost-bound by default with CSRF protection, rate limiting, and
security headers — bind to a non-loopback address only behind your own
auth proxy.
Wiring it into an AI agent is one command:
mongosemantic integrate claude # writes Claude Desktop config (restart Claude)
mongosemantic serve --transport sse # or run as a standalone SSE server on :8090
Want data to try it on? See Demo data below — a seeded movies collection makes every example in the next section reproducible.
See it in action
A tour of every feature, in the order you'd meet them. Every screenshot is
real and reproducible — .capture.yaml defines each shot and
capture run regenerates
the full set against a seeded database.
docs/test-evidence-0.9.md collects the
feature-by-feature proof for the 0.9.0 search upgrades.
Connect — with topology detection
Paste a MongoDB URI (or rely on env vars) and mongosemantic detects what it's talking to — Atlas, self-hosted replica set, or standalone — and adapts everything downstream: which search engine to use, whether sync can use change streams or must poll, which indexes to create. The connection is saved once and shared by the CLI, the dashboard, and the MCP server.
Browse collections
Every collection in the database, with its configured/not-configured status at a glance. Configured collections show their embedding model and storage mode (shadow or inline); the rest are one click away from setup. The migrate action lives here too.
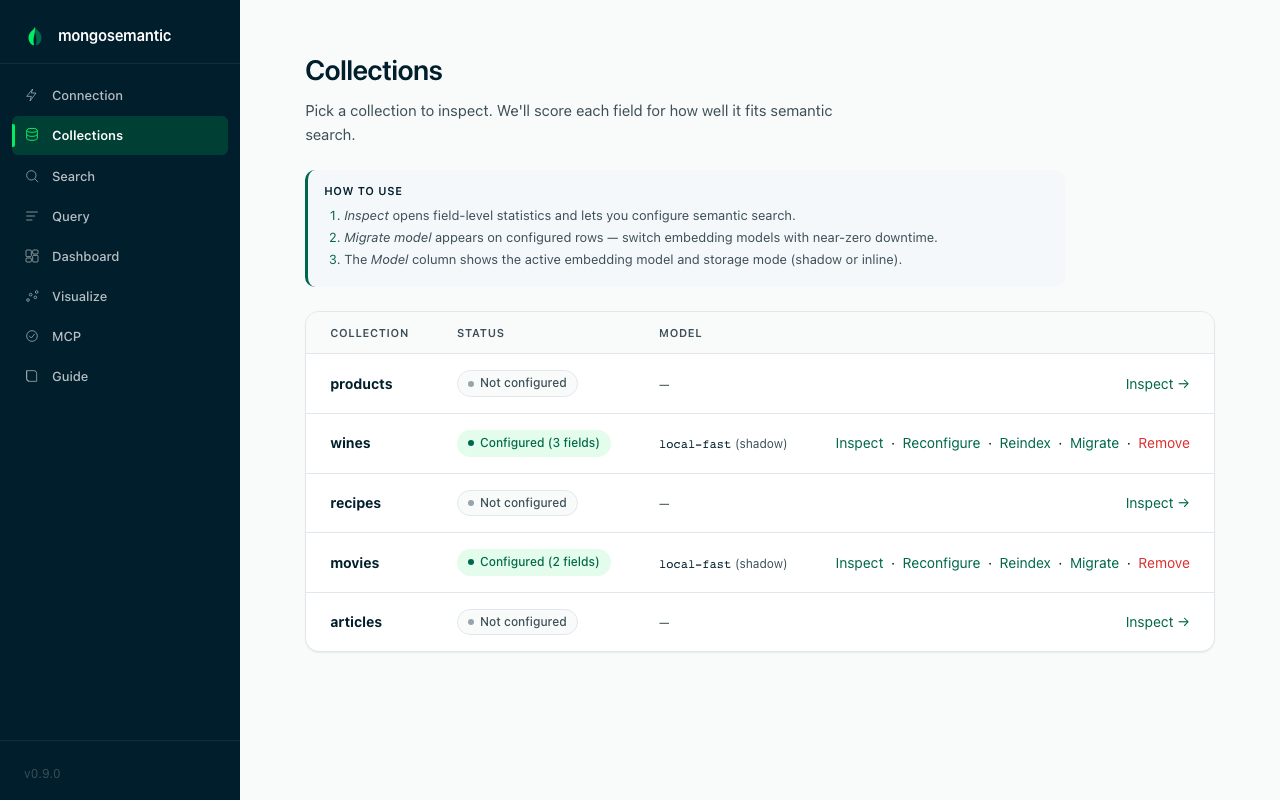
Inspect fields before you commit
Embedding the wrong field wastes hours of compute. The inspect page scores
every field of a collection for semantic-search suitability — text length,
fill rate, type consistency — and shows sample documents underneath, so
you pick the right fields the first time. Also available as
mongosemantic inspect -c <coll> and the inspect_collection MCP tool.
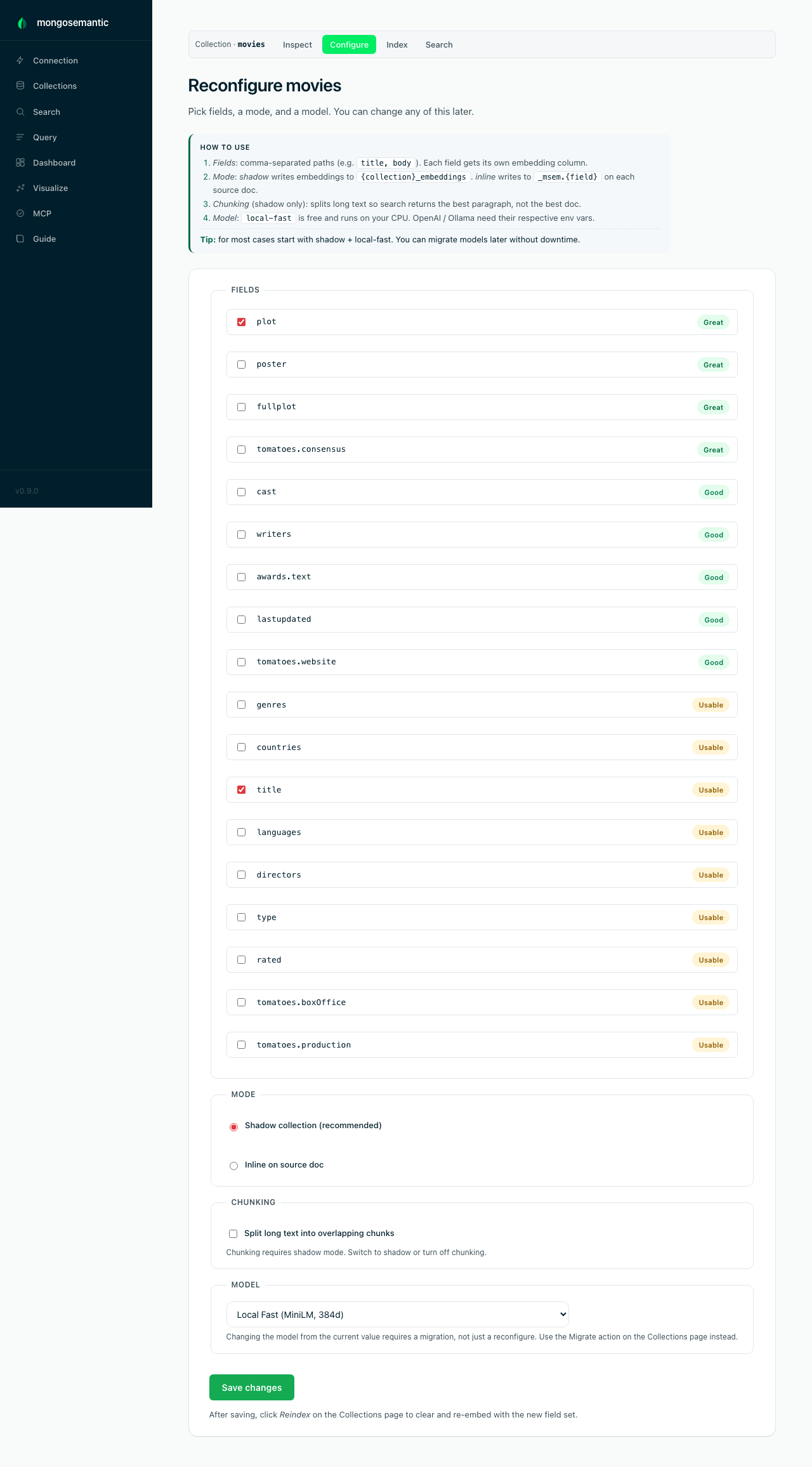
Configure semantic search
One form: discovered fields as checkboxes (with their suitability badges),
shadow vs. inline storage, optional chunking for long documents, and the
embedding model. On Atlas, apply auto-creates the vector and BM25 Search
indexes; on every topology it creates the $text index that powers the
hybrid keyword leg.
Watch the indexing pipeline
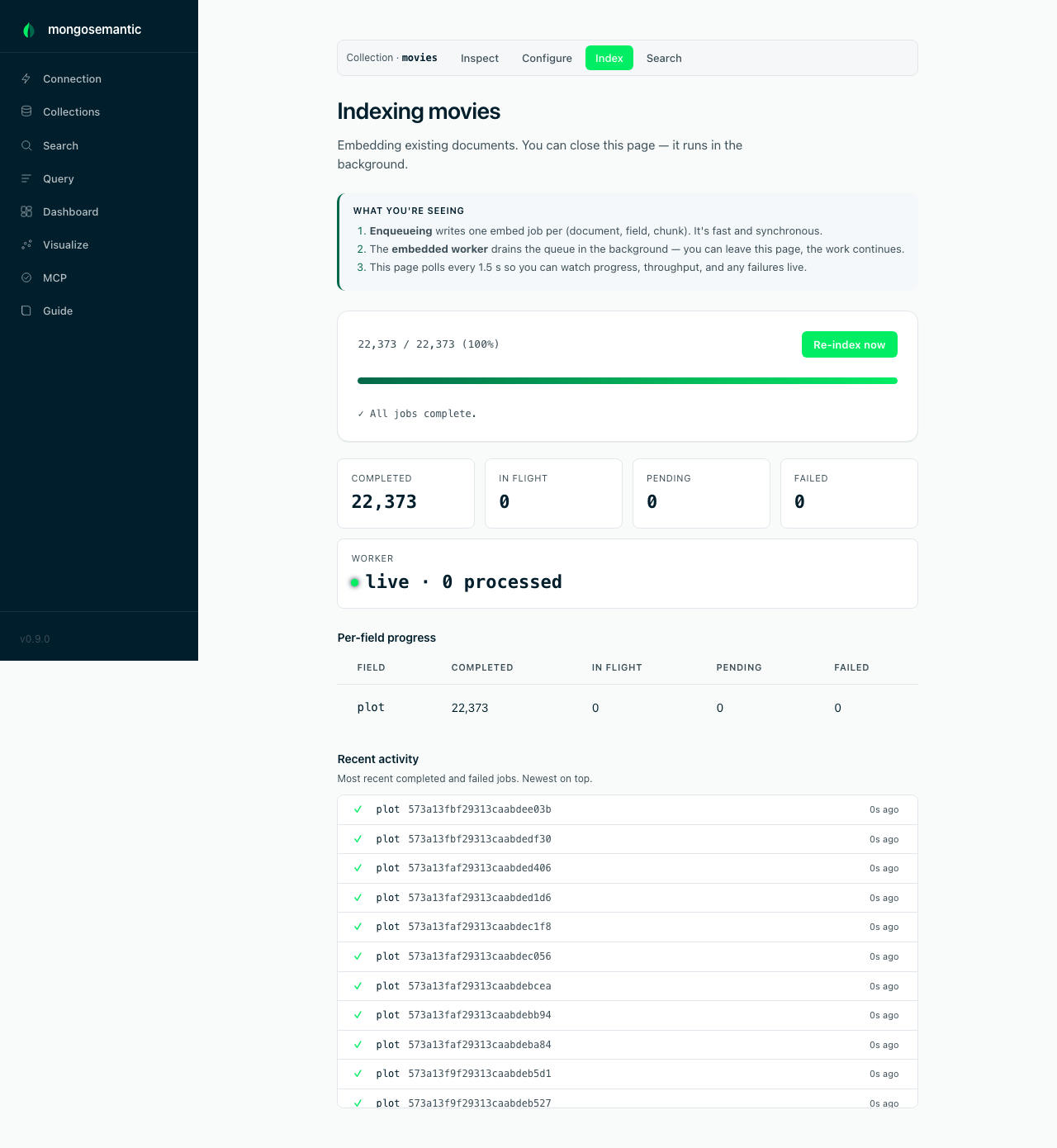
Bulk-embedding 23k documents shouldn't be a black box. The indexing dashboard shows completed / in-flight / pending / failed tiles, a live worker heartbeat, per-field progress bars, and a recent-activity feed — with retry and reindex one click away. The job queue is self-healing: stale in-flight jobs are reclaimed and dead worker heartbeats pruned automatically.
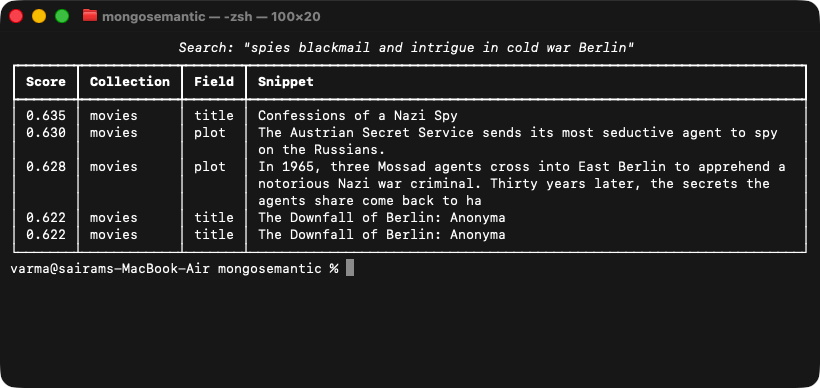
Search by meaning
The core feature, everywhere you work. The web version is the hero shot at the top of this page; here is the same engine from the CLI — a meaning-only query finding Cold-War spy thrillers with no keyword overlap:
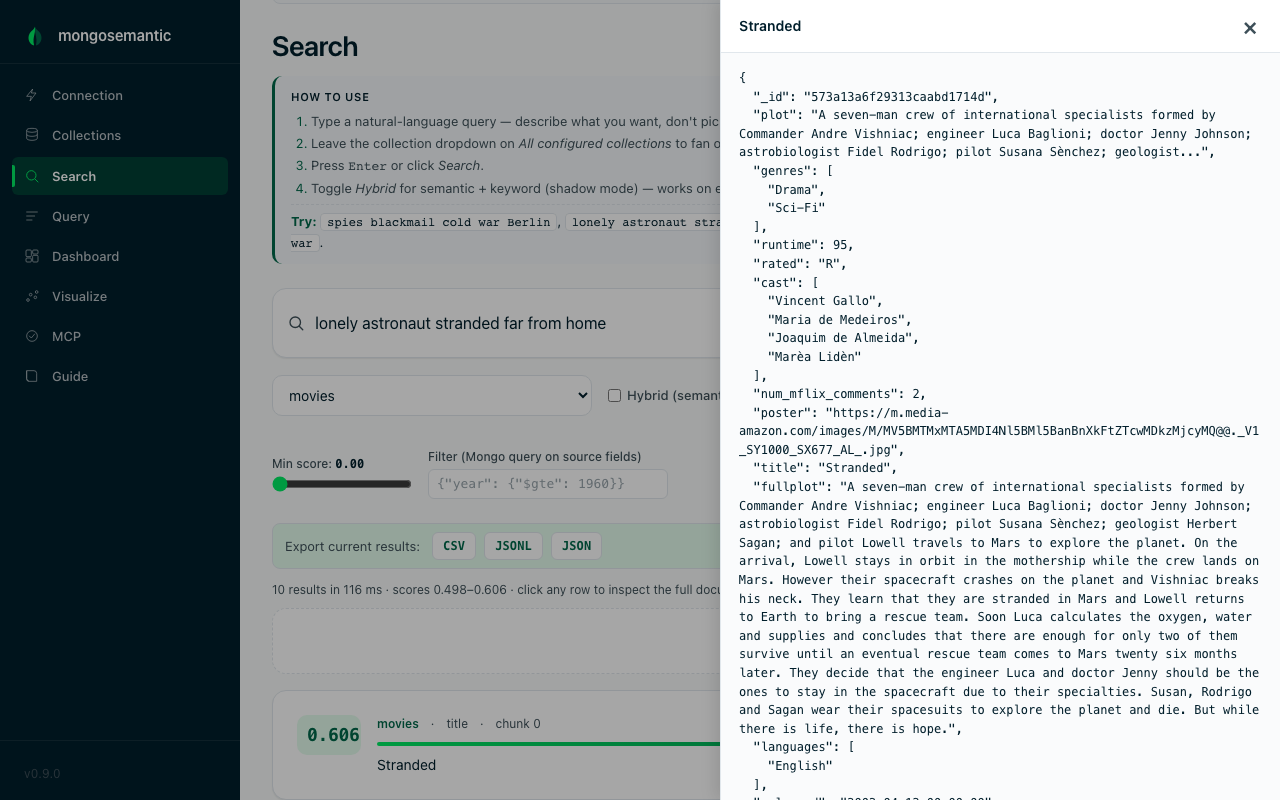
Open the full document behind a result
Search results show the matched chunk and its score; clicking any row slides in the complete source document, so you never lose the connection between a match and the record it came from.
Filter with plain MongoDB queries
Narrow any semantic search with a regular MongoDB query over the source documents — no reindex, no schema change, works on every search path:
mongosemantic search "a detective hunting a serial killer" -c movies \
--filter '{"year": {"$lt": 1960}}'
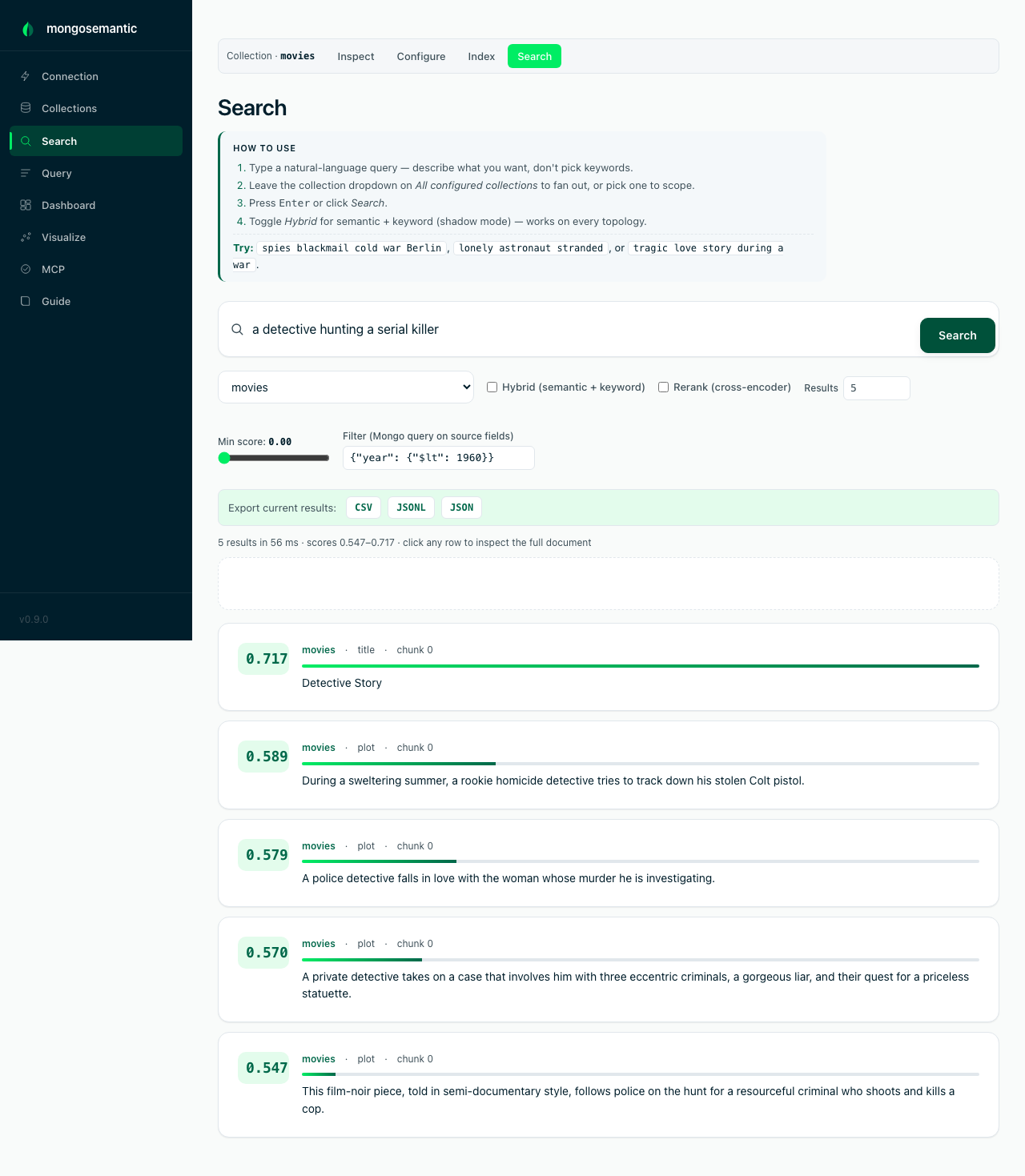
The shot below is exactly that: the same noir query, constrained to
pre-1960 — every modern serial-killer film drops out and the classics
surface. Local paths (brute-force, embedded HNSW) pre-filter the matching
_ids and are exact; Atlas paths over-fetch ×5 and post-match.
$where/$function/$accumulator/$text/$expr are rejected; invalid
filters error loudly (exit 2 on the CLI, HTTP 400 in the web UI).
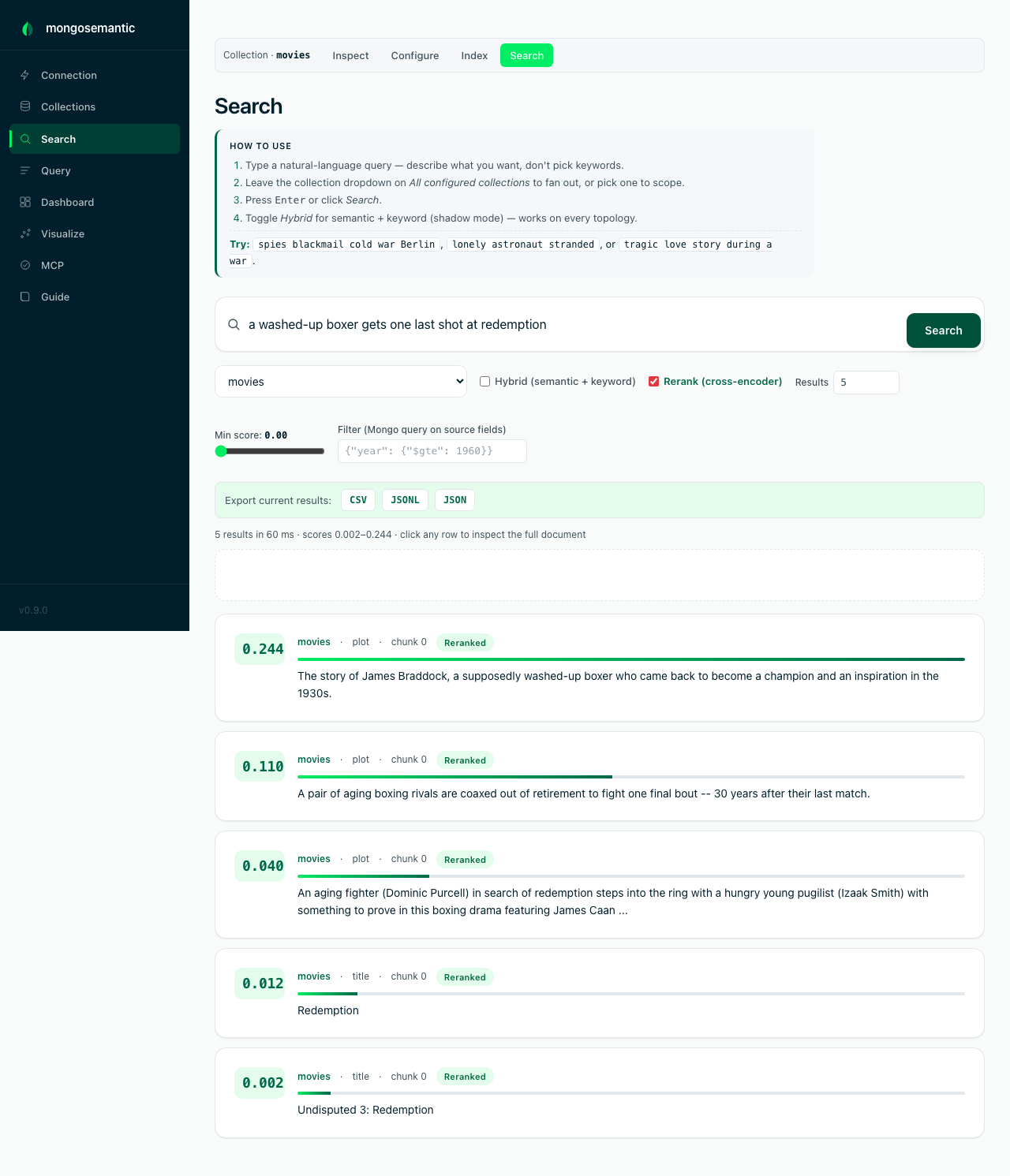
Rerank with a local cross-encoder
Vector similarity is a great first pass but a mediocre judge of final
order. --rerank turns search into two-stage retrieval: over-fetch
limit×5 candidates, re-score each (query, chunk) pair with a local
cross-encoder (cross-encoder/ms-marco-MiniLM-L-6-v2, ~80 MB, CPU,
loaded once per process), and return the top hits — original similarity
kept as vector_score:
mongosemantic search "a washed-up boxer gets one last shot at redemption" \
-c movies --rerank
In the shot: the Reranked badge on every row, the decisive winner (an actual washed-up-boxer redemption plot), and score bars normalized per result set. A bonus: cross-encoder scores are comparable across collections, even ones embedded with different models.
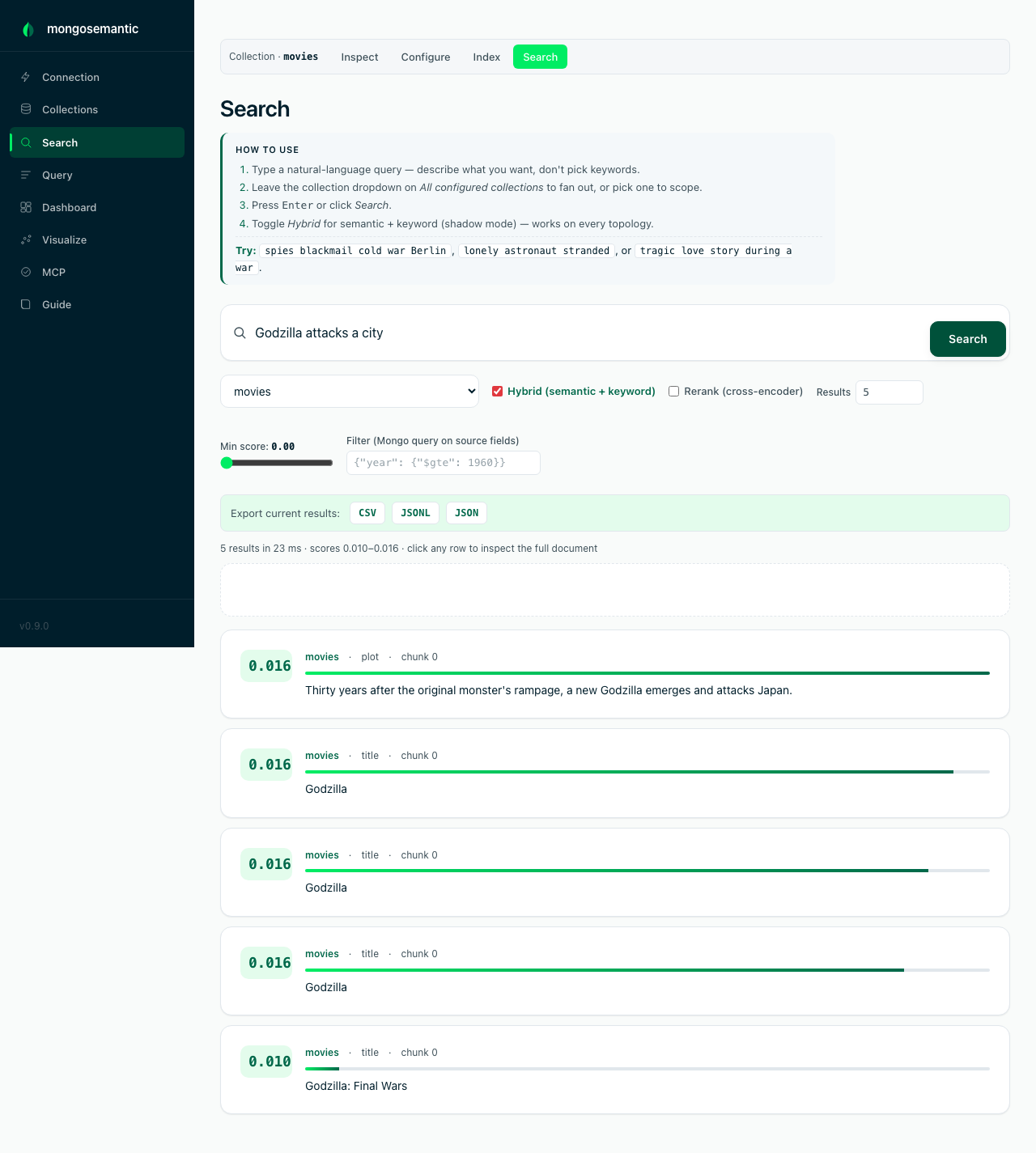
Hybrid search — on every topology
Combine semantic similarity with keyword matching for queries that mix meaning and specific terms — "MongoDB 7.0 replica set issues" benefits from semantic (catches "replica set" → "replication") plus keyword (anchors on "7.0").
mongosemantic search "Godzilla attacks a city" -c movies --hybrid
Two paths, picked automatically:
- Atlas with Search indexes — native
$rankFusionover$vectorSearchplus BM25$search; the search path verifies both indexes actually exist before relying on them. - Everywhere else — self-hosted 7.0+ (standalone or replica set), and
Atlas clusters whose Search indexes are cap-blocked (e.g. the free-tier
3-index budget): client-side reciprocal-rank fusion over a classic
MongoDB
$textindex on the shadow's chunk text plus the vector leg, with the same 1/(60+rank), 0.6/0.4 weighting as$rankFusion.
The shot below is hybrid running against a plain self-hosted replica set — no Atlas anywhere. Inline-mode collections fall back to pure semantic with a clear notice. Filter, rerank, and hybrid all compose, and all three are available in the CLI, the web UI, and the MCP tools.
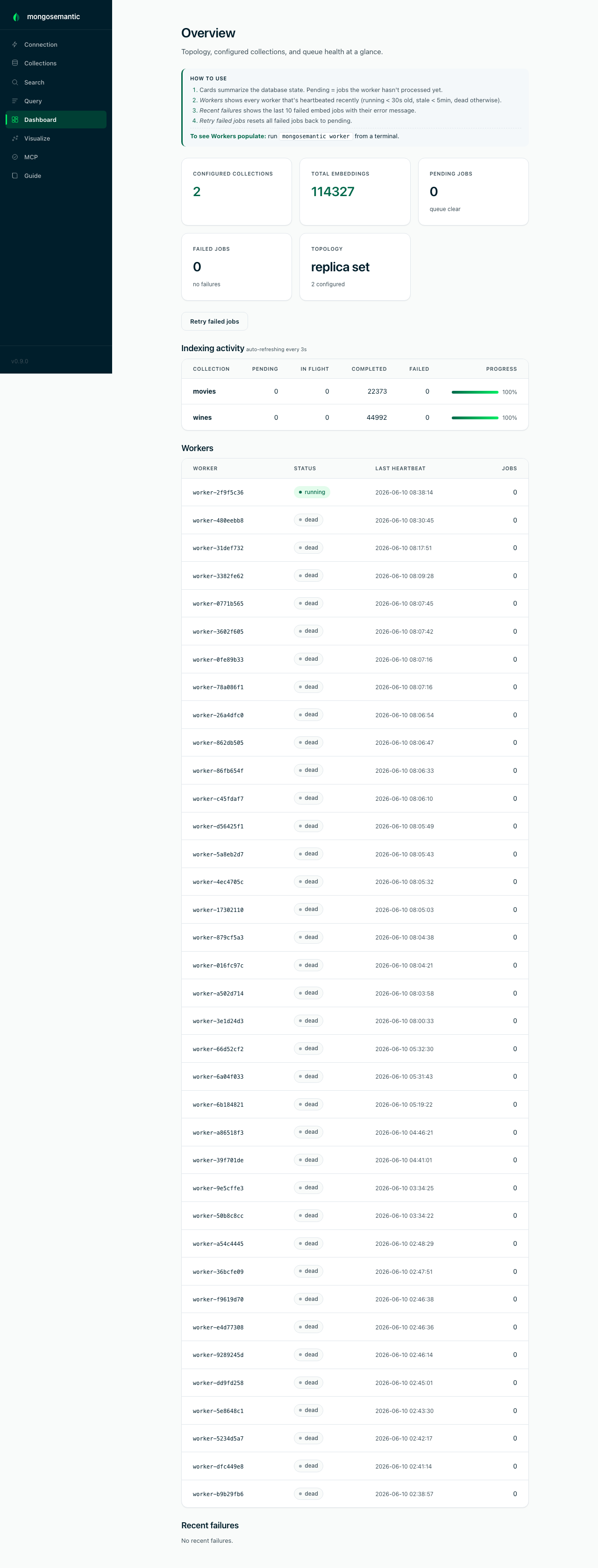
Keep an eye on the whole system
The overview dashboard answers "is everything healthy?" in one screen: detected topology, total embeddings, job-queue depth and failures, per-collection indexing activity, and live worker heartbeats.
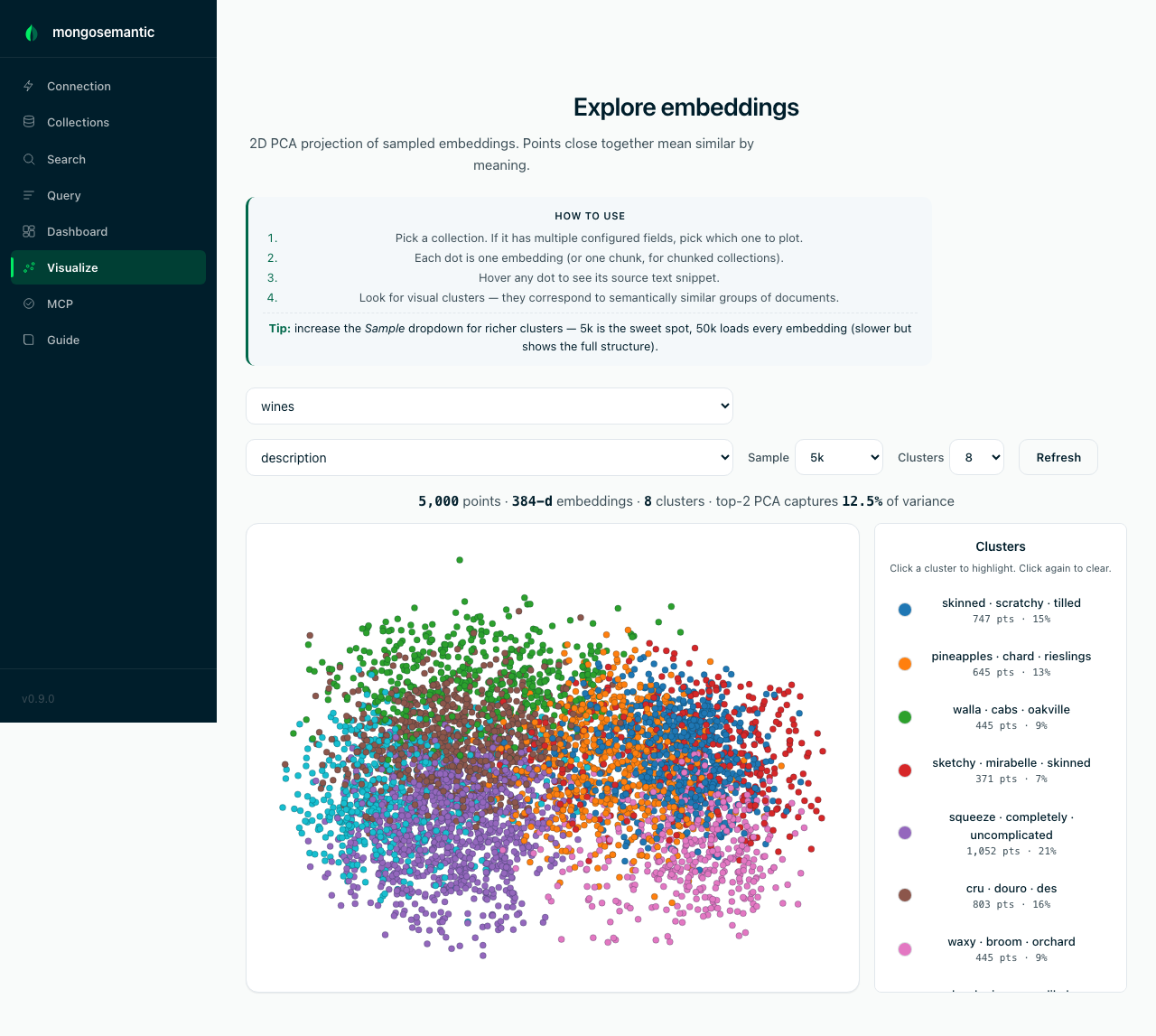
Explore the embedding space
A 2D PCA projection of sampled embeddings with K-means clusters and TF-IDF keyword labels per cluster — the fastest way to sanity-check that your embeddings actually capture structure (movie genres, product categories) before you build on them. Click any point to inspect the document behind it.
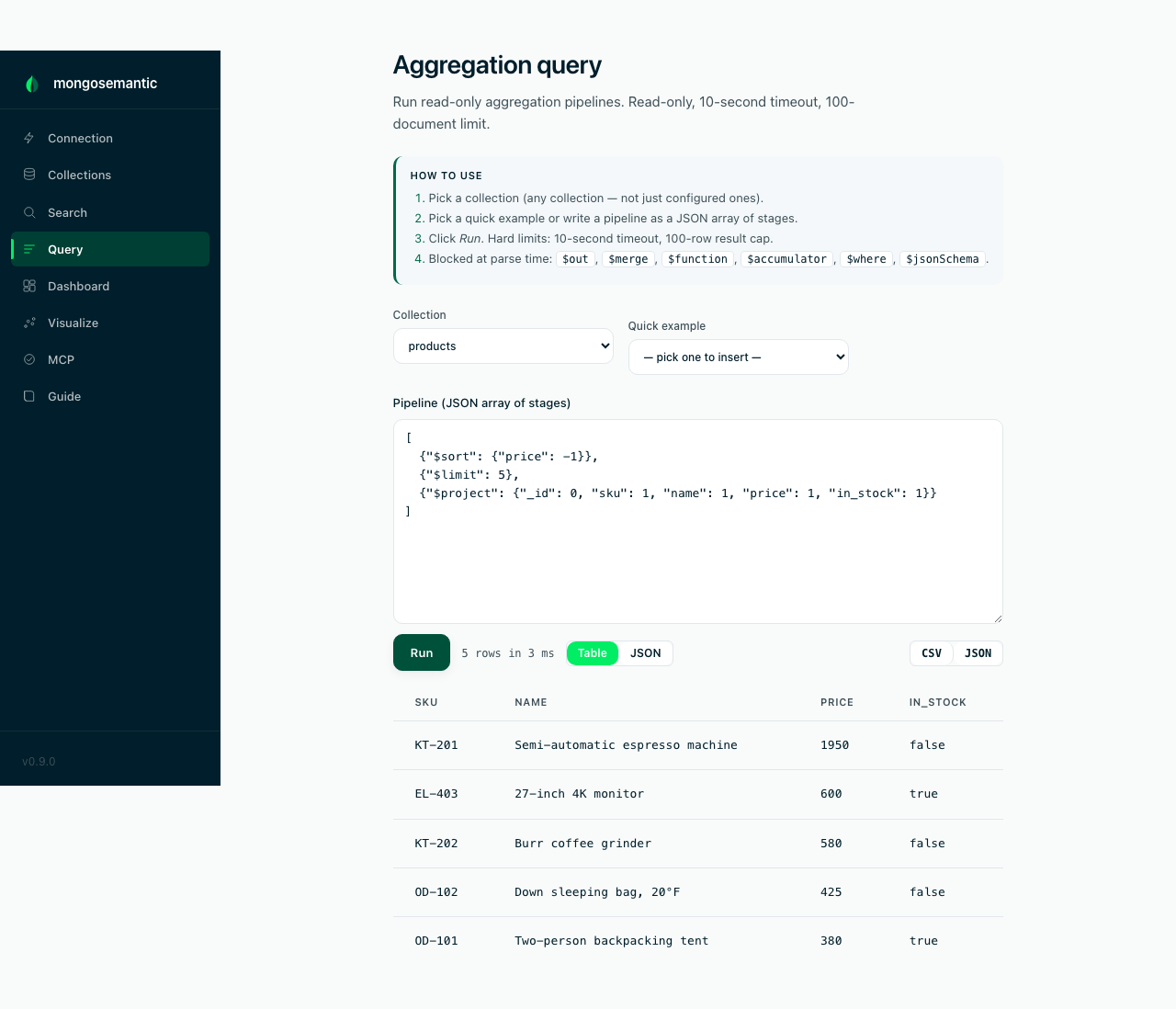
Run safe aggregations
A read-only pipeline runner for poking at your data without leaving the
dashboard: quick examples, table/JSON views, stats line, CSV/JSON export.
Hard-capped at 10 s and 100 documents, with $out/$merge/$function
blocked — safe to expose to teammates.
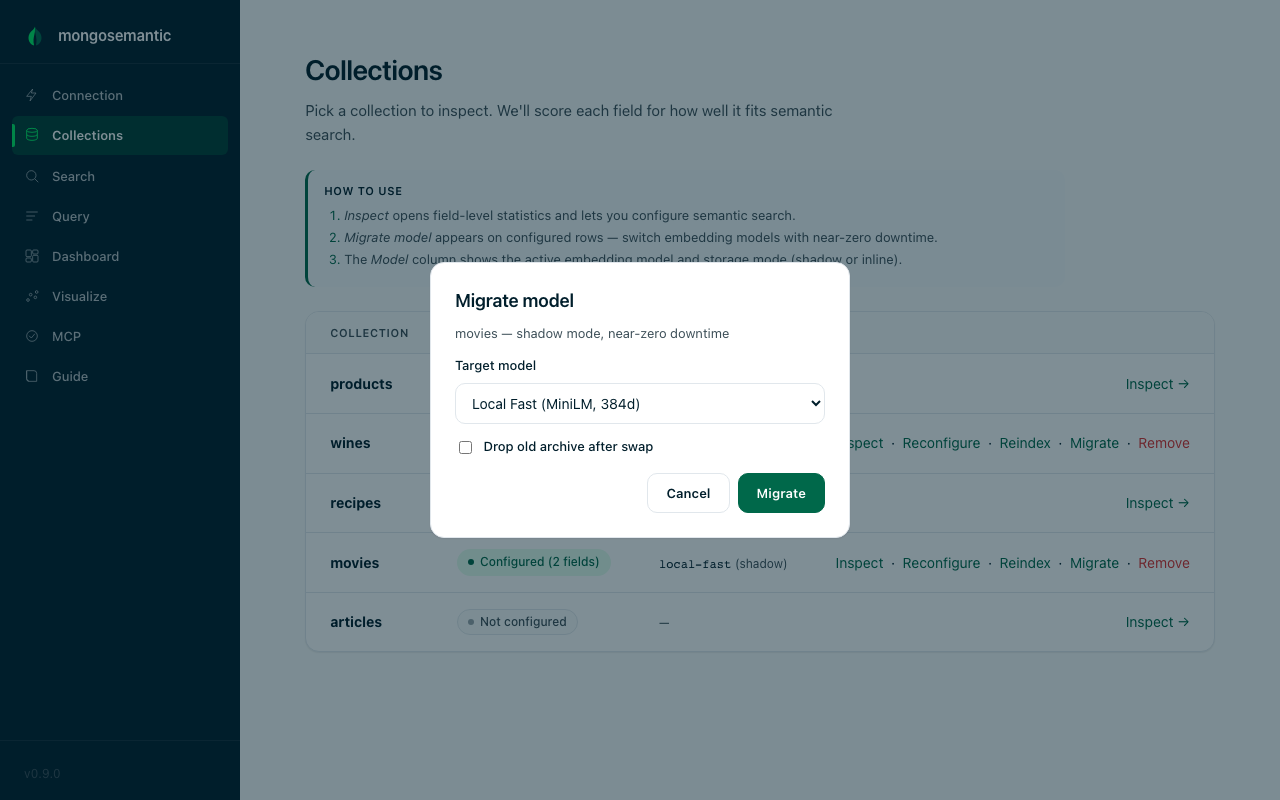
Migrate models with near-zero downtime
Embedding models improve; your search should too. migrate re-embeds a
shadow-mode collection with a new model into a temp shadow, then swaps it
into place with an atomic renameCollection — search serves the old model
up to the swap instant, the new model immediately after. The previous
shadow is archived (articles_embeddings_archive_{timestamp}) for
rollback; drop it with --drop-archive once verified.
mongosemantic migrate --collection articles --model local-better
Let AI agents query your MongoDB over MCP
mongosemantic integrate claude writes the Claude Desktop config in one
command; serve runs the same server over stdio or SSE for Cursor and any
other MCP client. Agents get meaning-based search over your data — with
filter, rerank, and hybrid — plus safe read-only introspection tools.
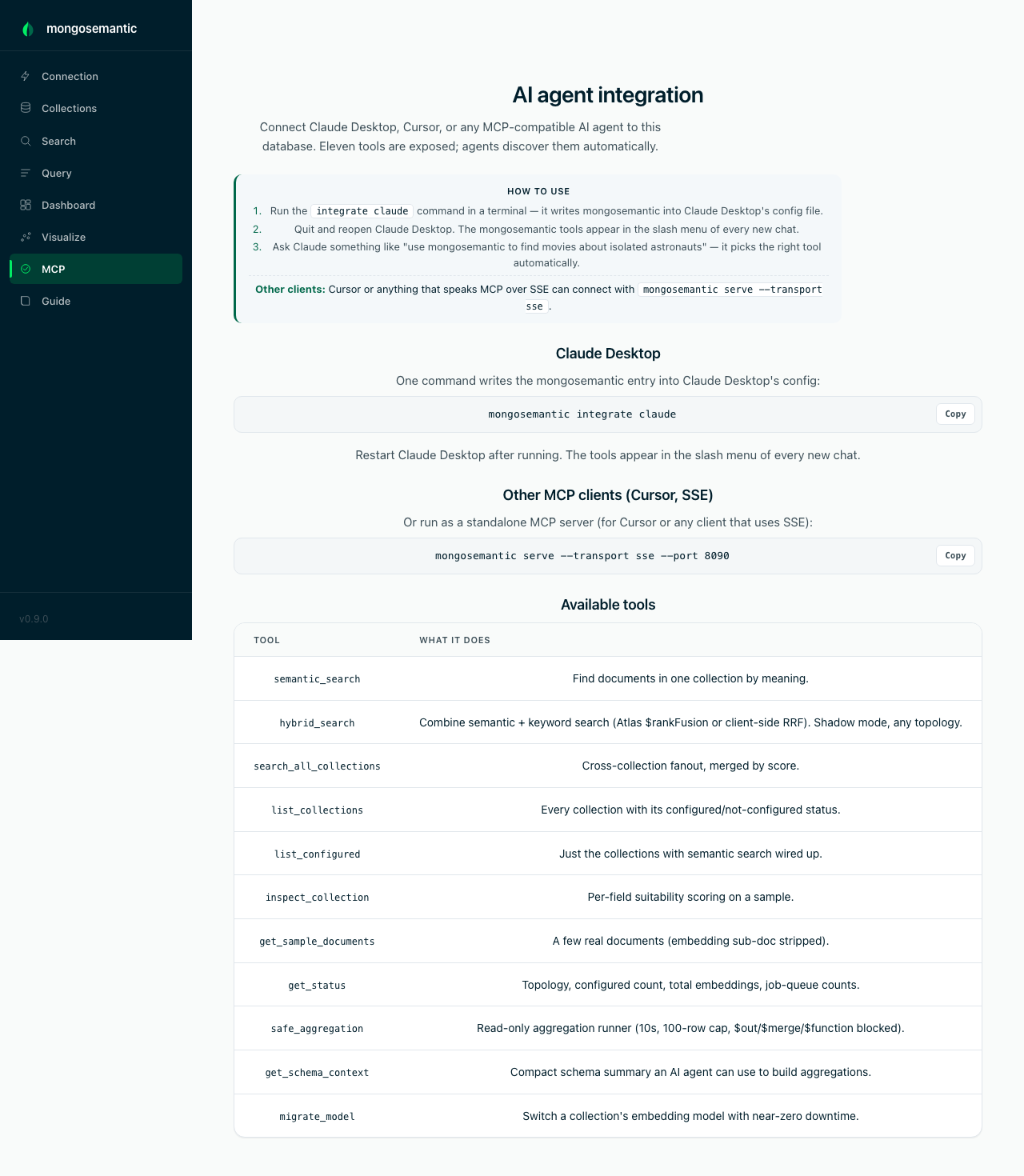
Eleven tools are exposed:
| Tool | What it does |
|---|---|
semantic_search |
Find rows in one collection by meaning; optional filter (MongoDB query) and rerank params |
hybrid_search |
Semantic + keyword, fused via Atlas $rankFusion or client-side RRF on every other topology; takes filter / rerank too |
search_all_collections |
Cross-collection fanout, merged by score; rerank makes scores comparable across models |
list_collections |
Every collection + its configured/not-configured status |
list_configured |
Just the ones with semantic search wired up |
inspect_collection |
Field-by-field suitability scoring |
get_sample_documents |
Real rows, embedding sub-doc stripped |
get_status |
Topology + total embeddings + job-queue counts |
safe_aggregation |
Read-only pipeline runner (10s, 100-row, no $out/$merge/$function) |
get_schema_context |
Compact schema summary for AI-generated aggregations |
migrate_model |
Switch a collection's embedding model with near-zero downtime |
Status (v0.9.0)
- Connect to Atlas / replica set / standalone — saved connection shared by UI, CLI, and MCP server
- Inspect a collection, score fields for suitability
- Configure shadow-mode or inline-mode semantic search on one or more fields
- Real chunking — long documents split into overlapping chunks, search ranks per chunk
- Bulk-embed existing documents
- Sync in real time (change streams) or on a schedule (polling)
- Search via native Atlas
$vectorSearch, embedded HNSW (non-Atlas), or brute-force aggregation - CLI: inspect / apply / index / search / worker / status / retry / reindex / reindex-hnsw / migrate / teardown / ui / serve / integrate
- Web UI — connection, collections, inspect, configure, indexing, search, query, dashboard, visualize, MCP, guide
- Embedded worker —
mongosemantic uialone keeps embeddings in sync; no second terminal - Self-healing job queue — stale in-flight jobs reclaimed, dead worker heartbeats pruned automatically
- MCP server for Claude Desktop / Cursor / any MCP client (stdio + SSE)
- Hybrid search on every topology — Atlas
$rankFusion(live-verified on 8.0.24) or client-side RRF with a$textindex elsewhere (--hybrid/ UI toggle /hybrid_searchMCP tool) - Metadata filtering — plain MongoDB queries over source fields on every search path (
--filter/ UI input / MCPfilterparam), no reindex needed - Local cross-encoder reranking — two-stage retrieval with
ms-marco-MiniLM-L-6-v2(--rerank/ UI toggle / MCPrerankparam) - Online model migration —
mongosemantic migrate+migrate_modelMCP tool, atomicrenameCollectionswap - Visualize page — K-means clusters over a 2D PCA projection, TF-IDF keyword labels, click-to-inspect
- Search & query export — CSV / JSONL / JSON from the search page, CSV / JSON from the aggregation runner
Known limitations
- Free-tier Atlas (M0/M2/M5) caps search indexes at 3 per cluster.
Each shadow-mode field costs 2 (vectorSearch + BM25), each inline field 1.
applyandmigratedetect the cap and degrade gracefully — cap-blocked collections keep hybrid search via client-side RRF over a classic$textindex, so keyword matching survives the cap. The Atlas paths —$vectorSearch, hybrid$rankFusion, migration index carry-over — are live-verified against a free-tier M0 on MongoDB 8.0.24; seedocs/atlas-setup.mdfor the runbook. Inline-mode with a real Atlas vector index is the one path verified only through its brute-force fallback (the M0 cap leaves it no index slot). - Atlas-path filters are over-fetch + post-match. On
$vectorSearchpaths a--filteris applied after the source$lookup, over a ×5 over-fetched candidate set — a highly selective filter may return fewer thanlimitrows. Local paths (brute-force, embedded HNSW) pre-filter the matching_ids and are exact.
Embedding models
| Model | Dimensions | Cost | Notes |
|---|---|---|---|
local-fast (MiniLM) |
384 | Free | Default. Runs on your machine. |
local-better (MPNet) |
768 | Free | Higher quality, slower. |
openai-small |
1536 | ~$0.02/1M tokens | Multilingual. |
openai-large |
3072 | ~$0.13/1M tokens | Highest quality. |
ollama-nomic |
768 | Free | Self-hosted via Ollama. |
Select via MONGOSEMANTIC_MODEL or --model on apply.
Deployment topologies
| Topology | Sync | Search (shadow mode) | Search (inline mode) | Realistic scale |
|---|---|---|---|---|
| Atlas | Change streams | $vectorSearch (HNSW, native) |
$vectorSearch |
Millions |
| Self-hosted replica set | Change streams | Embedded HNSW (in-process) | Brute-force aggregation | Hundreds of thousands |
| Self-hosted standalone | Polling (updated_at watermark) |
Embedded HNSW (in-process) | Brute-force aggregation | Hundreds of thousands |
Embedded HNSW: when you run mongosemantic ui against a non-Atlas
cluster, an HNSW graph is built from the shadow collection in a
background thread and persisted under ~/.cache/mongosemantic/hnsw/.
Queries hit the graph at ~O(log N) — ~15 ms warm on 45k chunks vs
~2.5 s brute-force. Indexes rebuild automatically when enough rows
go stale; force a rebuild with mongosemantic reindex-hnsw --all.
Inline-mode collections still take the brute-force path on non-Atlas (HNSW for inline is a follow-up). For datasets in the hundreds of thousands, prefer shadow mode or Atlas.
Development
git clone https://github.com/varmabudharaju/mongosemantic
cd mongosemantic
pip install -e ".[dev,openai]"
docker compose up -d # replica set + standalone
MONGOSEMANTIC_RUN_INTEGRATION=1 python3 -m pytest -v
The README screenshots are reproducible: .capture.yaml at the repo root
defines every shot (real Chromium renders of the dashboard, real Terminal
captures of the CLI). Regenerate them with
capture run against a
seeded database.
Demo data
Two seed scripts ship with the repo:
# Small hand-curated corpus (~185 articles + 38 products + 10 recipes).
# Fast, offline, good for fast iteration.
python3 scripts/seed_demo.py
# MongoDB's official sample_mflix — 23,539 movies with plots, genres, cast.
# ~40 MB download, ideal for realistic semantic-search demos.
python3 scripts/seed_mflix.py
After seeding either dataset:
# For mflix:
mongosemantic apply -c movies -f title -f plot
mongosemantic index -c movies
mongosemantic worker --once # processes all pending jobs, then exits
mongosemantic search "spies blackmail and intrigue in cold war Berlin" -c movies
Project docs
If you want to dig in further:
docs/ARCHITECTURE.md |
Module map, data flow diagrams, storage layout, key design decisions. The technical reference. |
docs/HANDOFF.md |
Current state: what's working, what's not live-tested, what was intentionally left out, what's worth shipping next. |
CONTRIBUTING.md |
Dev setup, test strategy, where to add a new CLI command / embedding provider / web route / MCP tool / search mode. |
docs/atlas-setup.md |
10-minute runbook for verifying the Atlas-specific paths ($vectorSearch, hybrid $rankFusion, migration index name carry-over) against a free-tier M0 cluster. |
CHANGELOG.md |
Per-version summary of what landed and why. |
License
MIT
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mongosemantic-0.9.0.tar.gz.
File metadata
- Download URL: mongosemantic-0.9.0.tar.gz
- Upload date:
- Size: 225.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
15f63837c4b715bf53db8b7199db80e6e454fe16267b68764f0d633b04fe307a
|
|
| MD5 |
e05237a71d65dd4ca797901d5fb2407c
|
|
| BLAKE2b-256 |
3fae26c4967b839e576008f06e73c0641f97f8d11e342ad563c0985578046fa5
|
Provenance
The following attestation bundles were made for mongosemantic-0.9.0.tar.gz:
Publisher:
publish.yml on varmabudharaju/mongosemantic
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mongosemantic-0.9.0.tar.gz -
Subject digest:
15f63837c4b715bf53db8b7199db80e6e454fe16267b68764f0d633b04fe307a - Sigstore transparency entry: 1945538070
- Sigstore integration time:
-
Permalink:
varmabudharaju/mongosemantic@46870acb903bd76c1db64744e4246a7414ef8153 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/varmabudharaju
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@46870acb903bd76c1db64744e4246a7414ef8153 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file mongosemantic-0.9.0-py3-none-any.whl.
File metadata
- Download URL: mongosemantic-0.9.0-py3-none-any.whl
- Upload date:
- Size: 167.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
297a13ff64c6fab2285a8c35c2c9cb47621d6872a17932ad45ac7a69964102c3
|
|
| MD5 |
6cbc103bddd9c0d87490ffc398584090
|
|
| BLAKE2b-256 |
180e0f0b7c7165876af84e20e9a389c3f9c41a600165e41fb6851d8abb87cf4b
|
Provenance
The following attestation bundles were made for mongosemantic-0.9.0-py3-none-any.whl:
Publisher:
publish.yml on varmabudharaju/mongosemantic
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
mongosemantic-0.9.0-py3-none-any.whl -
Subject digest:
297a13ff64c6fab2285a8c35c2c9cb47621d6872a17932ad45ac7a69964102c3 - Sigstore transparency entry: 1945538105
- Sigstore integration time:
-
Permalink:
varmabudharaju/mongosemantic@46870acb903bd76c1db64744e4246a7414ef8153 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/varmabudharaju
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@46870acb903bd76c1db64744e4246a7414ef8153 -
Trigger Event:
workflow_dispatch
-
Statement type:







