A re-implementation of NACE, as a pypi package, with a cleaner more general interface.

Project description
NACE: Non-Axiomatic Causal learnEr
An observational learner, creating a model of the world from subsequent observations, which can resolve
conflicting information, and plan many steps ahead, in an extremely sample efficient manner.
Background
This project builds upon an implementation of X's NACE work (Paper under review) observational learner, which in turn was based on Berick Cook's AIRIS, with added support for partial observability, capabilities to handle non-deterministic and non-stationary environments, as well as changes external to the agent. X achieved this by incorporating relevant components of Non-Axiomatic Logic (NAL).
The aim of this project is to convert the above work, into a foundation that extra experiments can be performed on.
Installation
pip install nace
Output
The agent will be seen to move near randomly (BABBLE), until it works out want its actions do. It can then get CURIOUS, heading for an interacting with objects it is uncertain about, or old objects that are too far away and need to be visited again to see if their state changed. If a set of actions increases the Score, it will attempt to repeat actions to continue to increase the score (ACHIEVE).
An example screenshot is given below where it is on Task 1, the agent is rewarded for getting to the food(f). In the agents views (blue and red), not the whole board is updated from the ground truth, only the area local to the agent, so the agent must (and does) search.
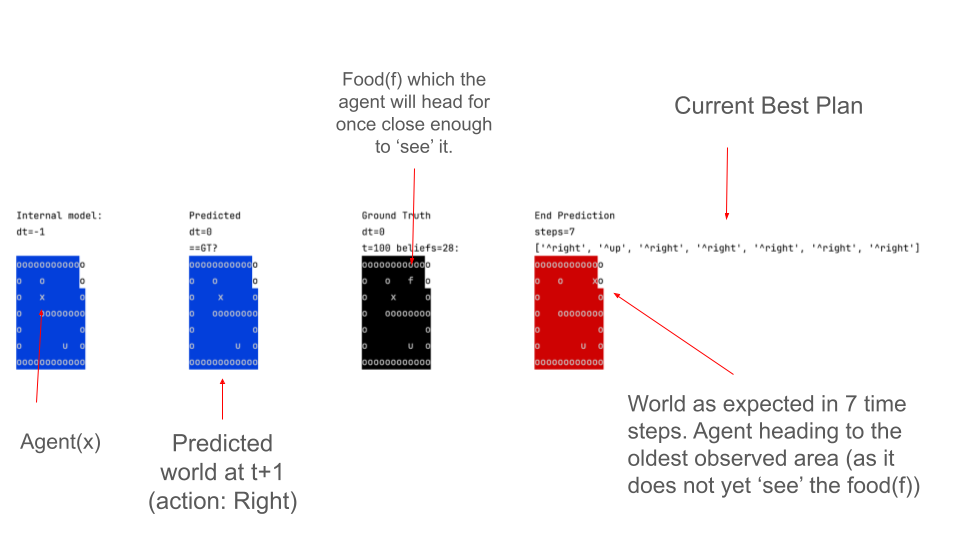
Examples
import os
import copy
import glob
import time
import datetime
import collections
import numpy as np
import pylab as pl
import ale_py
import gymnasium as gym # python3 -m pip install gymnasium
gym.register_envs(ale_py)
import minigrid # python3 -m pip install minigrid
gym.register_envs(minigrid)
import nace.color_codes
from nace.stepper_v4 import StepperV4
from nace.world_module_numpy import NPWorld
from nace.actions_module import NaceGymActionMapper
try:
import cv2 # pip install opencv-python. Not supported by pypy, and not central, so disabled when using pypy.
is_cv2_installed = True
except ImportError as e:
is_cv2_installed = False
# used to display what the environment for the user
global image_being_displayed
image_being_displayed = None
# for mujoco run pip install "gymnasium[mujoco]"
# or pip install "gymnasium[all]" (which was ron into 0040_nace_clean)
# No module named 'pygame'
def save_as_png(rendered_rgb, #: np.ndarray,
filename="screen.png", path="~/Downloads/"):
try:
fn = os.path.join(os.path.expanduser(path), filename)
if is_cv2_installed:
cv2.imwrite(fn, rendered_rgb)
# display the image just saved to user
global image_being_displayed
im = pl.imread(fn)
# image_being_displayed = pl.imshow(im)
if image_being_displayed is not None:
image_being_displayed.set_data(im)
else:
image_being_displayed = pl.imshow(im)
pl.pause(.1)
pl.draw()
else:
print("WARN: cv2 not installed. Can not save or draw board images.")
except:
print("WARN: Can not save or draw board images.")
pass
def print_list(action_list):
for i, action in enumerate(action_list):
if i == 0:
print("INFO print_list() ", "#".rjust(6), "Action")
print("INFO print_list() ", str(i).rjust(6), action_list[i])
def get_values_exc_score_exc_term_from_observation(observation):
if isinstance(observation, int):
values_exc_score_exc_term = [observation]
elif isinstance(observation, list):
values_exc_score_exc_term = []
for v in observation:
values_exc_score_exc_term.append(v)
else:
values_exc_score_exc_term = []
print("WARN get_values_exc_score_from_observation() unknown type.")
return values_exc_score_exc_term
def extract_agent_attributes_from_environment(env):
"""
@param env:
@return: a value array for the agent, that excluded reward and terminated flags (first 2 values).
"""
key_index_values = {'red':0,'blue':1,'yellow':2,'purple':3,'grey':4,'green':5}
values_exc_prefix = [0] * (1+max(key_index_values.values())) # set all values to zero
if env.has_wrapper_attr("carrying"):
if env.get_wrapper_attr("carrying") is not None and env.get_wrapper_attr("carrying").type == 'key':
index = key_index_values[env.get_wrapper_attr("carrying").color]
values_exc_prefix[index] = 1
return values_exc_prefix
if __name__ == "__main__":
gym.pprint_registry() # print all the valid IDs and environments
render_mode = "rgb_array"
"""
Some environments have the goal, terminate as often as possible with max Return
Some never terminate and gather as much reward as possible.
"""
env_list = [
{
"code": "CliffWalking-v0",
"cell_shape_rc": (60, 60, 3),
"start_rc": (3, 0),
"action_map": {0: 'up', 1: 'right', 2: 'down', 3: 'left'},
"planning_max_num_actions": 12,
"max_queue_length": 300,
"died_vs_survived_on_termination_threshold": -2,
# on termination, use this to determine died (<= threshold) or survived
"use_sticky_plans": True, # if True use all of last plan before re-planning
"terminate_on_teleport": True, # if the agent teleports mark the episode terminated
"use_user_keyboard_input": False, # if True will wait for user guidance keys w,a,s,d and c to continue
# Documentation: https://gymnasium.farama.org/environments/toy_text/cliff_walking/
# NOTE Can-NOT be learned by reward alone, as there is no difference between moving (-1) and succeeding (-1)
# succeeding (-1) and dying (-100) are differentiated by the 'died_vs_survived_on_termination_threshold'
# LIMIT: cause on success reward is < 0, ACHIEVE behaviour never triggered.
},
{
"code": "FrozenLake8x8-v1",
"cell_shape_rc": (64, 64, 3),
"start_rc": (0, 0),
"action_map": {0: 'left', 1: 'down', 2: 'right',
3: 'up'},
"planning_max_num_actions": 12,
"max_queue_length": 300,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans":True, # if True use all of last plan before re-planning
# Documentation https://gymnasium.farama.org/environments/toy_text/frozen_lake/
# Reward: reach goal +1, reach hole 0, reach frozen 0.
# NOTE must learn to terminate episode, but not to 'die'
"kwargs":{"is_slippery":False},
# == params that allow debugging below
"use_user_keyboard_input": False, # if True will wait for user guidance w=up/forward,a=left/turn_left,d=right/turn_right,s=down
},
{
"code": "MiniGrid-Empty-6x6-v0", # used in patricks paper
"cell_shape_rc": (int(192 / 6), int(192 / 6), 3),
"start_rc": (1, 1),
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward'},
"planning_max_num_actions": 12,
"max_queue_length": 300,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans":True, # if True use all of last plan before re-planning
# documentation : https://minigrid.farama.org/environments/minigrid/EmptyEnv/
# Reward, 0 unless at goal when reward is ‘1 - 0.9 * (step_count / max_steps)’
# NOTE No pressure to learn the shortest path to the goal in current NACE algo.
"use_user_keyboard_input": False,
# if True will wait for user guidance w=up/forward,a=left/turn_left,d=right/turn_right,s=down
},
{
"code": "MiniGrid-Empty-8x8-v0", #
"cell_shape_rc": (int(192 / 6), int(192 / 6), 3),
"start_rc": (1, 1),
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward'},
"planning_max_num_actions": 12,
"max_queue_length": 300,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans":True, # if True use all of last plan before re-planning
# documentation : https://minigrid.farama.org/environments/minigrid/EmptyEnv/
},
{
"code": "MiniGrid-Dynamic-Obstacles-8x8-v0",
"cell_shape_rc": (int(256 / 8), int(256 / 8), 3),
"start_rc": (1, 1),
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward'},
# 0 turn left , 1 turn right, 2 forward, 3 pick up, 4 drop, 5 unused, 6 unused
"planning_max_num_actions": 12,
"max_queue_length": 30,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans":True, # if True use all of last plan before re-planning
# Documentation: https://minigrid.farama.org/environments/minigrid/DynamicObstaclesEnv/
# Rewards A reward of ‘1 - 0.9 * (step_count / max_steps)’ is given for success,
# and ‘0’ for moving to a 'safe' sqare, and -1 for failure.
# A ‘-1’ penalty is subtracted if the agent collides with an obstacle.
# NOTE: NACE can not learn this as 1) it does not 'look' far enough away (will not avoid a circle 2 away)
# and 2) it does not model other agents.
"use_user_keyboard_input": True,
# if True will wait for user guidance w=up/forward,a=left/turn_left,d=right/turn_right,s=down
},
{
"code": "MiniGrid-Unlock-v0", # used by patrick
"cell_shape_rc": (int(192 / 6), int(352 / 11), 3),
"start_rc": None,
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward', 3:'pickup', 5:'toggle/activate'},
# 0 turn left , 1 turn right, 2 forward, 3 pick up, 4 drop, 5 toggle/activate, 6 unused
"planning_max_num_actions": 8,
"max_queue_length": 10,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans":True, # if True use all of last plan before re-planning
# "observation_to_state_converter": True,
"environment_state_converter":True,
# "kwargs": {"highlight":False, "agent_pov":True}
# "kwargs": {"agent_pov": True},
# Documentation https://minigrid.farama.org/environments/minigrid/UnlockEnv/
# Reward A reward of ‘1 - 0.9 * (step_count / max_steps)’ is given for reaching goal,
# reward of ‘0’ otherwise,
# == params that allow debugging below
"use_user_keyboard_input": True, # if True will wait for user guidance keys w,a,s,d and c to continue
},
{
"code":"MiniGrid-LavaGapS7-v0", # used by patrick
"cell_shape_rc": (int(192 / 6), int(352 / 11), 3),
"start_rc": None,
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward' },
# 0 turn left , 1 turn right, 2 forward, 3 unused, 4 unused, 5 unused, 6 unused
"planning_max_num_actions": 12,
"max_queue_length": 30,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans":True, # if True execute all of last plan before re-planning
# documentation https://minigrid.farama.org/environments/minigrid/LavaGapEnv/
# Rewards A reward of ‘1 - 0.9 * (step_count / max_steps)’ is given for success, and ‘0’ otherwise.
# NOTE similar to frozen lake, should be very learnable.
# == params that allow debugging below
"use_user_keyboard_input": True, # if True will wait for user guidance keys w,a,s,d and c to continue
},
{
"code": "MiniGrid-DistShift2-v0", # used by patrick
"cell_shape_rc": (int(192 / 6), int(352 / 11), 3),
"start_rc": None,
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward'},
"planning_max_num_actions": 12,
"max_queue_length": 300,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans": True, # if True execute all of last plan before re-planning
# documentation https://minigrid.farama.org/environments/minigrid/DistShiftEnv/
# reward ‘1 - 0.9 * (step_count / max_steps)’ is given for reaching goal, else ‘0’ for move, or
# stepping in lava.
# NOTE should be very learnable by NACE
# == params that allow debugging below
"use_user_keyboard_input": True, # if True will wait for user guidance keys w,a,s,d and c to continue
},
{
"code": "MiniGrid-SimpleCrossingS11N5-v0", # used by patrick
"cell_shape_rc": (int(192 / 6), int(352 / 11), 3),
"start_rc": None,
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward'},
"planning_max_num_actions": 12,
"max_queue_length": 30,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans": True, # if True execute all of last plan before re-planning
# documentation https://minigrid.farama.org/environments/minigrid/CrossingEnv/
# Similar to Lava, except more maze like, and with walls rather than lava.
# Reward: A reward of ‘1 - 0.9 * (step_count / max_steps)’ is given for success, and ‘0’ otherwise.
# == params that allow debugging below
"use_user_keyboard_input": True, # if True will wait for user guidance keys w,a,s,d and c to continue
},
{
"code": "MiniGrid-DoorKey-8x8-v0", # used by patrick
"cell_shape_rc": (int(192 / 6), int(352 / 11), 3),
"start_rc": None,
"action_map": {0: 'turn_left', 1: 'turn_right', 2: 'forward', 3:'pickup', 5:'toggle/activate'}, #
"planning_max_num_actions": 21,
"max_queue_length": 30,
"died_vs_survived_on_termination_threshold": 0, # if <= this assumed died else survived
"use_sticky_plans": True, # if True execute all of last plan before re-planning
# documentation https://minigrid.farama.org/environments/minigrid/DoorKeyEnv/
# reward A reward of ‘1 - 0.9 * (step_count / max_steps)’ is given for success, and ‘0’ for failure
#
# == params that allow debugging below
"use_user_keyboard_input": True, # if True will wait for user guidance keys w,a,s,d and c to continue
},
{
"code":"MountainCarContinuous-v0",
# Documentation https://gymnasium.farama.org/environments/classic_control/mountain_car_continuous/
}
]
# code = "CliffWalking-v0" # Succeeds but does not seek treasure, as reward is same an wandering around : episode_count= 22 success_count= 2 frame_number= 639 frames per success= 319.5
# code = "FrozenLake8x8-v1" # Succeeds : episode_count= 451 success_count= 418 frame_number= 9073 frames per success= 21.705741626794257
code = "MiniGrid-DoorKey-8x8-v0" # Succeeds, but slowly, episode_count= 1 success_count= 1 frame_number= 922 frames per success= 922.0 cumulative_pos_gym_reward= 0.37421874999999993 cumulative_gym_reward= 0.37421874999999993
# code = "MiniGrid-DistShift2-v0" # Still Failing after 6 episodes, 300 frames
# code = "MiniGrid-Dynamic-Obstacles-8x8-v0" # needs luck: episode_count= 27 success_count= 1 frame_number= 1001 frames per success= 1001.0 cumulative_pos_gym_reward= 0.0 cumulative_gym_reward= -26.0
# code = "MiniGrid-Empty-6x6-v0" # Succeeds, episode_count= 14 success_count= 14 frame_number= 763 frames per success= 54.5 (why so slow?)
# code = "MiniGrid-LavaGapS7-v0" # Succeeds, episode_count= 9 success_count= 2 frame_number= 471 frames per success= 235.5 cumulative_pos_gym_reward= 1.2836734693877552 cumulative_gym_reward= 1.2836734693877552
# code = "MiniGrid-SimpleCrossingS11N5-v0" # ? episode_count= 2 success_count= 2 frame_number= 1001 frames per success= 500.5 cumulative_pos_gym_reward= 0.0 cumulative_gym_reward= 0.0 Why 0.0 reward?
# code = "MiniGrid-Unlock-v0" # Succeeds, approx: episode_count= 9 success_count= 9 frame_number= 1091 frames per success= 121.22222222222223 cumulative_pos_gym_reward= 5.51875 cumulative_gym_reward= 5.51875
# code = "MountainCarContinuous-v0" # in progress
env_num = [ i for i, settings in enumerate(env_list) if settings["code"] == code][0]
print("\n\n=====================================")
print("INFO main() Building Environment:", env_num,",", env_list[env_num]["code"])
param = {"id":env_list[env_num]["code"], "render_mode":render_mode}
if "kwargs" in env_list[env_num]:
param = {**param, **env_list[env_num]["kwargs"]}
env = gym.make(**param)
allow_move_off_map_edge = False
save_images = True
observation, info = env.reset() # seed= ...
gymnasium_world = env.render()
load_past_evidence = False # seems to load evidence that predicts no change for action forward when it should.
if save_images:
save_as_png(gymnasium_world, filename="screen_at_initialisation.png")
env_rendered = gymnasium_world
# check shapes divide evenly
for dim in [0, 1]:
if int(gymnasium_world.shape[dim] / env_list[env_num]["cell_shape_rc"][dim]) != (
gymnasium_world.shape[dim] / env_list[env_num]["cell_shape_rc"][dim]):
print("ERROR", "cell does not divide into screen evenly:", gymnasium_world.shape, "vs",
env_list[env_num]["cell_shape_rc"])
assert int(gymnasium_world.shape[dim] / env_list[env_num]["cell_shape_rc"][dim]) == (
gymnasium_world.shape[dim] / env_list[env_num]["cell_shape_rc"][dim])
if render_mode == 'rgb_array':
cell_shape_rc = env_list[env_num]["cell_shape_rc"]
start_rc = env_list[env_num]["start_rc"]
cell_w = cell_shape_rc[1]
cell_h = cell_shape_rc[0]
if start_rc is not None:
r = start_rc[0] # agent start location
c = start_rc[1] # agent start location
_raw_agent_location_indicator_value = gymnasium_world[r * cell_h:(r + 1) * cell_h,
c * cell_w:(c + 1) * cell_w]
else:
_raw_agent_location_indicator_value = np.zeros((cell_h, cell_w, 3))
agent_indication_raw_value_list = []
fn_list = glob.glob("./data/agents/*.npy")
for fn in fn_list:
cell = np.load(fn)
if cell.shape[0] == cell_shape_rc[0] and cell.shape[1] == cell_shape_rc[1]:
agent_indication_raw_value_list.append(cell)
found = False
for cell in agent_indication_raw_value_list:
comp = cell == _raw_agent_location_indicator_value
if comp.all():
found = True
break
if not found:
print("WARN main() Agent location wrong, or not in agent list stored from disk")
else:
raise Exception("Mode " + render_mode + " not supported.")
mapping_counts = collections.defaultdict(int)
# need to map the NACE action space to the Gym action space
action_mapper = NaceGymActionMapper(
env.action_space,
extend_beyond_configured_actions=False, # could be cleaned up and joined with above code better
gym_to_nace_name_mapping = env_list[env_num]["action_map"]
)
stepper = StepperV4(agent_indication_raw_value_list=agent_indication_raw_value_list,
available_actions_function=action_mapper.get_full_action_list)
print("DEBUG main() Available actions",stepper.available_actions_function())
planning_max_num_actions = env_list[env_num]["planning_max_num_actions"]
max_queue_length = env_list[env_num]["max_queue_length"]
# this will load the evidence from past runs
if load_past_evidence:
print("WARN loading evidence from past runs. This will affect statistics.")
stepper.add_rules_and_evidence_from_file_to_memory("./data/rule_evidence.json")
# Terminology
# embedded space : with options walls, in the reduced dimension space
# raw : in the input space, i.e. what the environment knows
# get the agents initial location
external_ground_truth_npworld, agent_rc_locations_embedded_space = NPWorld.from_gymnasium_rgb(
gym_np_world=env_rendered,
embedded_wall_code=nace.world_module_numpy.EMBEDDED_WALL_CODE,
agent_indication_raw_value_list=agent_indication_raw_value_list,
cell_shape_rc=env_list[env_num]["cell_shape_rc"],
store_raw_cell_data=save_images # On a new game/environment this needs to be true so that agent images can be found manually, but it is slow
)
if len(agent_rc_locations_embedded_space) == 0:
# start location not found via files on disk, use config location
if start_rc is None:
print("WARN main() No agent location, setting start agent location incorrectly to (1,1)")
start_rc = (1, 1)
agent_rc_locations_embedded_space = [start_rc]
cumulative_gym_reward = 0.0
cumulative_pos_gym_reward = 0.0
use_user_keyboard_input_after_frame = -1
died_count = 0
num_frames = 40000 # Patrick converges at 10k steps, and uses movement assumptions, so * 4 advantage.
episode_count = 0
success_count = 0
print_maps = True
show_board_interactively = True # will disable the creation of charts if true
force_optimal_path = env_list[env_num]["force_optimal_path"] if "force_optimal_path" in env_list[env_num] else False
use_user_keyboard_input = env_list[env_num]["use_user_keyboard_input"] if "use_user_keyboard_input" in env_list[env_num] else False
use_sticky_plans = env_list[env_num]["use_sticky_plans"] if "use_sticky_plans" in env_list[env_num] else False
terminate_on_teleport = env_list[env_num]["terminate_on_teleport"] if "terminate_on_teleport" in env_list[env_num] else False
if force_optimal_path:
print("WARNING main() Planning is ignored, optimal path being hardcoded.")
nace_action_list = env_list[env_num]["optimal_path"]
for frame_number in range(num_frames):
frame_start_time = datetime.datetime.now()
if force_optimal_path and frame_number == len(nace_action_list):
# forced actions complete. this is the first actual plan.
print("INFO main() First real plan (after forced actions)")
if force_optimal_path and frame_number == len(nace_action_list)-1:
# last forced action. will 'learn' from this action
print("INFO main() Last forced action. will 'learn' from this action")
# Step 1 - get the best possible action in this state
print("INFO main() get_next_action() START frame_number="+str(frame_number))
t1 = time.time()
nace_action, nace_behaviour = stepper.get_next_action(
ground_truth_external_world=external_ground_truth_npworld,
new_rc_loc=agent_rc_locations_embedded_space[-1],
print_debug_info=print_maps, # will print the 'Maps' if True
max_num_actions=planning_max_num_actions, # planning search depth
max_queue_length=max_queue_length,
use_sticky_plans=use_sticky_plans
)
if force_optimal_path and frame_number < len(nace_action_list):
print("WARNING main() planning is ignored, optimal path being hardcoded.")
nace_action = nace_action_list[frame_number % len(nace_action_list)]
elif use_user_keyboard_input:
print("INFO main() planning is ignored.\nWaiting on keypress and ENTER for movement (w/a/s/d w=up/forward,a=left,d=right,s=down,t=toggle,p=pick) (c=continue) (100=proceed for 100 time steps) :")
key = input() # User input, but not displayed on the screen 3:'pickup', 5:'toggle/activate'
if 'turn_left' in action_mapper.get_full_action_list() and key in ['a','s','d','w','t','p']:
key_mappings = {'a':'turn_left','d':'turn_right','w':'forward', 'p':'pickup', 't':'toggle/activate'}
nace_action = key_mappings[key]
stepper.overide_best_action(nace_action)
elif key in ['a','s','d','w']:
key_mappings = {'a':'left','s':'down','d':'right','w':'up'}
nace_action = key_mappings[key]
stepper.overide_best_action(nace_action)
elif key in ['c']:
print("INFO c pressed. No longer waiting for user input")
use_user_keyboard_input = False
elif key.isdigit():
use_user_keyboard_input = False
use_user_keyboard_input_after_frame = frame_number + int(key)
else:
print("WARNING key unknown, and ignored. key=",key)
if use_user_keyboard_input_after_frame > 0 and frame_number > use_user_keyboard_input_after_frame:
use_user_keyboard_input = True
use_user_keyboard_input_after_frame = -1
env_pre_step_rendered = env.render()
if save_images:
save_as_png(env_pre_step_rendered, filename="screen_pre_action.png")
gym_action, nace_action_name = action_mapper.convertToGymAction(nace_action)
print("INFO main() get_next_action() END ", "time_taken=",(time.time()-t1) )
# Step 2 - Apply selected action in 'real' environment or world
observation, gym_reward, terminated, truncated, info = env.step(gym_action)
# env.get_wrapper_attr("x")
env_post_step_rendered = env.render()
if save_images:
save_as_png(env_post_step_rendered, filename="screen_post_action.png")
# Step 3 - Update our version of the 'external' world with from the data from the 'real' external world
update_mode = "VIEW"
pre_action_rc_locations, post_action_rc_locations, modified_count, pre_update_world = external_ground_truth_npworld.update_world_from_ground_truth_NPArray(
env_post_step_rendered,
update_mode=update_mode,
cell_shape_rc=cell_shape_rc,
add_surrounding_walls=True,
wall_code=nace.world_module_numpy.EMBEDDED_WALL_CODE,
agent_indication_raw_value_list=agent_indication_raw_value_list,
observed_at=frame_number
)
# Step 4 - Let stepper update it's internal world state, only within view_distance of the agent
# if the agent moved lots or was teleported, we need current and last locations
view_rc_locs = copy.deepcopy(pre_action_rc_locations)
view_rc_locs.extend(post_action_rc_locations)
stepper.set_world_ground_truth_state(external_ground_truth_npworld,
view_rc_locs=view_rc_locs,
time_counter=frame_number)
# Step 5 - check if we teleported
if post_action_rc_locations == []:
# On some patterns (Frozen Lake) the agent disappears on success
print("ERROR main() The agent disappeared, suggests we are missing an image of the agent in a particular state. Using the configured start location, which is not absolutely correct.")
# raise Exception("Could not find agent - we are probably missing an image of them in their current state.
# i.e. fallen in a hole, so the hole should be used as the agent. Hmm does work for the treasure, they disappear.")
post_action_rc_locations = [copy.deepcopy(start_rc)]
teleported = True
else:
r_delta = post_action_rc_locations[-1][0] - pre_action_rc_locations[-1][0]
c_delta = post_action_rc_locations[-1][1] - pre_action_rc_locations[-1][1]
teleported = abs(r_delta)+abs(c_delta) > 1 # Manhattan distance
if teleported:
print("DEBUG main() agent teleported")
if terminate_on_teleport:
print("WARNING main() agent teleported, so episode is being terminated.")
terminated = True
# Step 6 - environment specific logic
if gym_reward > 0.0:
print("gym_reward=",gym_reward)
# Step 7 - Calculate cumulative reward - used to learn good from bad
if terminated or truncated:
if terminated and gym_reward == 0:
print("WARN main() terminated with reward == 0.0. We need to know difference between success and death at termination, if reward is always the same at termination, this can not be done.) ")
episode_count += 1
if "died_vs_survived_on_termination_threshold" in env_list[env_num]: # when terminated, did we die? or was it better than that?
if terminated and gym_reward <= env_list[env_num]["died_vs_survived_on_termination_threshold"]:
# fell in hole, or otherwise died somehow, but env did not tell us.
died_count += 1
else:
success_count += 1
else: # use gym_reward > 0 == lived else died
if gym_reward > 0:
success_count += 1
else:
died_count += 1
print("INFO main() TERMINATED/TRUNCATED. episode_count=", episode_count, "frame_number=", frame_number,
"success_count=", success_count, "died_count=", died_count)
# add to statistics (saved to disk, for graphs, and analysis)
stepper.add_to_series_record({"success_count":success_count, "died_count":died_count, "frame_number":frame_number, "episode_count":episode_count, "cumulative_gym_reward":cumulative_gym_reward },
prefix=code, create_charts=frame_number%10==0 and not show_board_interactively)
cumulative_gym_reward += gym_reward
if gym_reward > 0.0:
cumulative_pos_gym_reward += gym_reward
print("INFO main() We were given +ve gym reward.")
print("INFO main() Selected action:", nace_action_name, "cumulative_gym_reward", cumulative_gym_reward, "gym_reward=",
gym_reward, "success_count=", success_count,
"post_action_rc_locations=", post_action_rc_locations
)
# Step 7 - pass the current Agent state to the stepper
if "environment_state_converter" in env_list[env_num] and env_list[env_num]["environment_state_converter"] is not None:
# values_exc_score_exc_term = get_values_exc_score_exc_term_from_observation(observation)
values_exc_prefix = extract_agent_attributes_from_environment(env)
else:
values_exc_prefix = []
stepper.set_agent_ground_truth_state(
rc_loc=post_action_rc_locations[-1], #
score=cumulative_gym_reward,
values_exc_prefix=values_exc_prefix,
terminated=terminated
)
# Step 8 - Compare predicted and reality find differences to update our model of how the world works.
stepper.predict_and_observe(print_out_world_and_plan=print_maps) # build new rules, check those we have.
# Step 9 - if terminated or truncated
if terminated or truncated:
env_rendered = env.render()
if save_images:
save_as_png(env_rendered, filename="screen_pre_reset_"+str(frame_number)+".png")
# when we succeed, terminated==True, truncated==False, gym_reward==-1
# we should not move back to the start position but only AFTER we have learnt the
# consequence of the last action
# perform reset on external world
observation, info = env.reset()
# Step a) Copy gym deltas into NPworld format
env_rendered = env.render()
if save_images:
save_as_png(env_rendered, filename="screen_post_reset.png")
_1, post_rest_agent_location_list, modified_count, pre_update_world = (
external_ground_truth_npworld.update_world_from_ground_truth_NPArray(
env_rendered,
cell_shape_rc=cell_shape_rc,
wall_code=nace.world_module_numpy.EMBEDDED_WALL_CODE,
agent_indication_raw_value_list=agent_indication_raw_value_list,
update_mode=update_mode
))
if len(post_rest_agent_location_list) == 0:
post_rest_agent_location_list = [start_rc] # could not find agent via rgb, use configured location
# Step b) Let stepper update it's internal world state (as we may have been reset)
view_rc_locs = []
view_rc_locs.extend(post_action_rc_locations)
view_rc_locs.extend(pre_action_rc_locations)
view_rc_locs.extend(post_rest_agent_location_list)
stepper.set_world_ground_truth_state(external_ground_truth_npworld,
view_rc_locs=view_rc_locs,
# if the agent moved lots, this update would not update around the agents old location, add this so that it does.
time_counter=frame_number)
# Step c) let stepper get the latest agent state
if "environment_state_converter" in env_list[env_num] and env_list[env_num][
"environment_state_converter"] is not None:
values_exc_prefix = extract_agent_attributes_from_environment(env)
else:
values_exc_prefix = []
# reset the parts of the agent that need to be on termination (location, terminated)
stepper.set_agent_ground_truth_state(
rc_loc=post_rest_agent_location_list[-1],
score=cumulative_gym_reward,
terminated=0, # Episode still live, agnet? alive or dead? unknown.
values_exc_prefix=values_exc_prefix
)
fps = (frame_number / success_count) if success_count != 0 else float('inf')
print("INFO main() TERMINATED or TRUNCATED. episode_count=", episode_count, "success_count=", success_count,
"frame_number=", frame_number, "frames per success=", fps,
"cumulative_pos_gym_reward=", cumulative_pos_gym_reward,
"cumulative_gym_reward=", cumulative_gym_reward)
# print("INFO main() statistics", json.dumps(stepper.statistics))
predict_next_world_state_call_count_during_observe = stepper.statistics["predict_next_world_state_call_count_during_observe"] / (frame_number+1)
predict_next_world_state_call_count_during_plan = stepper.statistics['nacev3_get_next_action.plan.predict_next_world_state_call_count_during_plan'] / (frame_number + 1)
frame_end_time = datetime.datetime.now()
fps = (frame_number / success_count) if success_count != 0 else float('inf')
print("DEBUG main() episode_count=", episode_count, "success_count=", success_count,
"frame_number=", frame_number, "frames per success=", fps,
"cumulative_pos_gym_reward=", cumulative_pos_gym_reward,
"cumulative_gym_reward=", cumulative_gym_reward,
"predict_next_world_state_call_count_during_observe=", predict_next_world_state_call_count_during_observe,
"predict_next_world_state_call_count_during_plan=", predict_next_world_state_call_count_during_plan,
"time_taken=", (frame_end_time - frame_start_time)
)
# Step 10 save the state to human-readable file
stepper.save_rules_to_file("./data/rule_evidence.json", "./data/stepper_rules_and_state.json")
print("DEBUG main() end of loop")
fps = (frame_number / success_count) if success_count != 0 else float('inf')
print("INFO main() Statistics episode_count", episode_count, "success_count", success_count,
"frame_number", frame_number, "frames per success=", fps,
"cumulative_pos_gym_reward=", cumulative_pos_gym_reward,
"cumulative_gym_reward=", cumulative_gym_reward,
"predict_next_world_state_call_count_during_observe=", predict_next_world_state_call_count_during_observe,
"predict_next_world_state_call_count_during_plan=", predict_next_world_state_call_count_during_plan
)
env.close()
Internal Data Structures
These took me a while to get my head round, so I made notes while I did in order to understand the code. This may be useful for you as well.
= Rule Object =:
Action_Value_Precondition: Prediction: State Value Deltas
Action State Preconditions (old world) y x board score key
values precondition0 precondition1 precondition2 value delta delta
excl y x y x
score
((left, (0,), (0, 0, ' '), (0, 1, 'x'), (0, 2, 'u')), (0, 0, 'x', (0, 0))),
((right, (0,), (0, -1, 'x'), (0, 0, 'o')), (0, 0, 'o', (0, 0))),
The following Action_Value_Precondition:
((right, (0,), (0, -1, 'x'), (0, 0, 'o'))
can be read: Match if there is a 'o' at the focus point, and a 'x' to the left of it, and the action is right.
The following Action_Value_Precondition, Prediction:
((left, (0,), (0, 0, ' '), (0, 1, 'x'), (0, 2, 'u')), (0, 0, 'x', (0, 0))),
can be read: Match if there is a ' ' at the focus point,
and a 'x' to the right of it,
and a 'u' to the right of the 'x',
and the action is left
And the prediction after the action is:
the 'x' will appear at 0,0 relative to the focus point.
and there is no change to our score
The following Action_Value_Precondition, Prediction:
((right, (0,), (0, -1, 'x'), (0, 0, 'f')), (0, 0, 'x', (1, 0))),
can be read: Match if there is a 'f' at the focus point,
and a 'x' to the left of it,
and the action is right
And the prediction after the action is:
the 'x' will appear at 0,0 relative to the focus point.
the first State Delta (score) will be +1
the first State Delta (key) will be +0
Rule_Evidence Object Dictionary
positive negative
evidence evidence
counter counter
{ ((right, ... )) : ( 1, 0 ) }
{ ((left, (), (0, 0, ' '), (0, 1, 'x')), (0, 0, 'x', (0,))): (1,0) }
Positive Evidence, and Negative Evidence can be used to calculate:
Frequency = positive_count / (positive_count + negative_count)
Confidence = (positive_count + negative_count) / (positive_count + negative_count + 1)
Truth_expectation = confidence * (frequency - 0.5) + 0.5
Location:
xy_loc tuple (x,y) note (0,0) is top left
State Values
tuple of values, the first is score, the second is number of keys held.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file nace-0.0.20.tar.gz.
File metadata
- Download URL: nace-0.0.20.tar.gz
- Upload date:
- Size: 115.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.10.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9b28064b3d3e58b159d7c58dfe214c092ff547327ba7328f517314ca2e89443c
|
|
| MD5 |
939379280406b83336604c397dc9dfbd
|
|
| BLAKE2b-256 |
bcfa60fef808b8fbab4b657b79ca78067bece44bcb96297b0ecb517b75fe4da0
|







