Turn any recording into a 7.1 surround mix: a model designs a per-song spatial placement and renders a lossless 8-channel FLAC.

Reason this release was yanked:
Installer didn't work easily on a new macbook.
Project description
Natural Perspective Spatial Audio
Turn any recording into a 7.1 surround mix. After a song is split into its instrument stems, a model invents a scene and decides where each instrument sits around you — then a deterministic renderer builds a lossless 8-channel (7.1) FLAC for your media server.
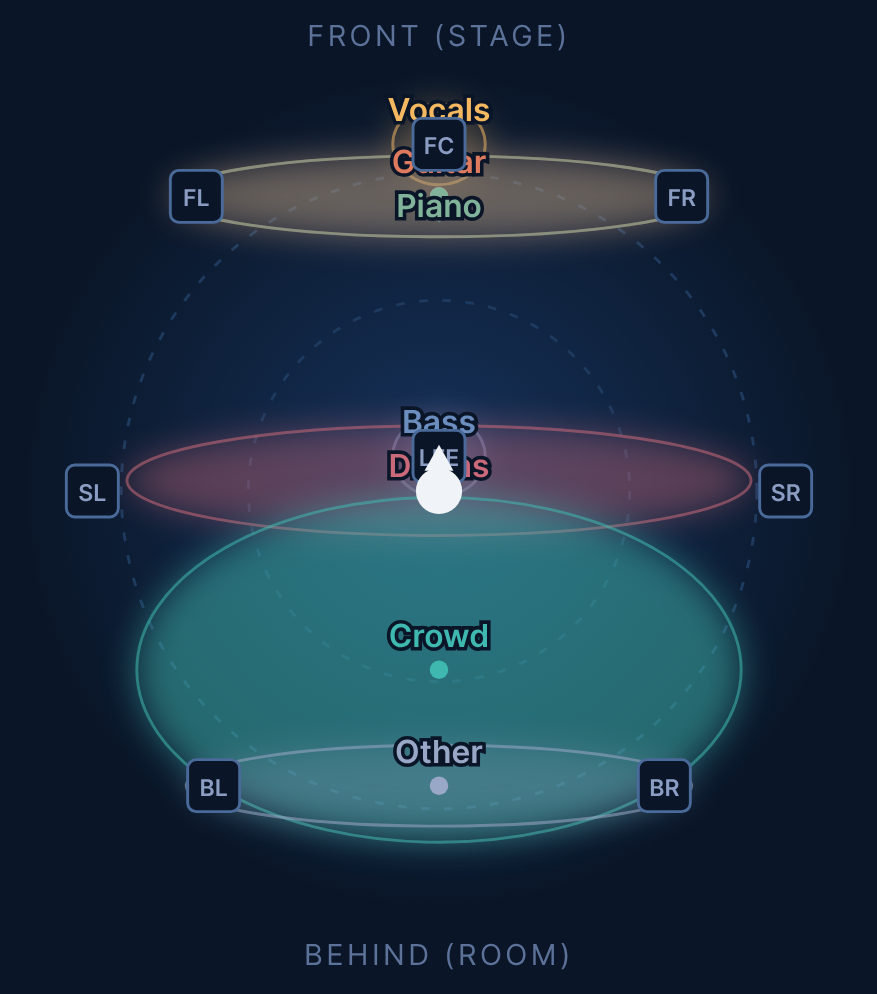
One real mix: every stem placed on the stage, the crowd behind you.
See it — no install
Open examples/index.html in any browser, on any OS.
It's a finished mix's scene, soundstage, routing, and stem levels — the actual
output of the tool.
Run it
Easiest — install from PyPI with pipx, no clone needed (needs Python 3.10+):
pipx install 'natural-perspective-spatial-audio[full]'
spatial-standards-gui # or: spatial-standards song.flac
Or from a clone — one command (macOS/Linux) sets up a private virtualenv and installs everything; on a Mac with Homebrew it installs Python for you too:
./install.sh
./gui # the GUI (or: .venv/bin/spatial-standards song.flac)
Manual / Windows
Needs Python 3.10+ (3.12 recommended — widest wheel coverage):
python3 -m venv .venv && source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install '.[full]' # quote it — the [..] is a shell glob otherwise
spatial-standards song.flac # also: a folder, or a URL
spatial-standards-gui # or the GUI
The GUI uses Tkinter: it ships with the python.org installer (recommended on
macOS), with Homebrew add python-tk, on Debian/Ubuntu apt install python3-tk.
[full] brings everything as Python packages — FFmpeg + ffprobe (via
static-ffmpeg), Demucs, the crowd model (audio-separator), and yt-dlp —
so a fresh machine works after one install, no system setup. It's CPU by
default; for an NVIDIA GPU install a CUDA build of PyTorch from pytorch.org
and pip install 'audio-separator[gpu]' (much faster). The first run
downloads model weights (a few hundred MB).
Prefer your own tools? pip install . has no required Python packages and
just calls ffmpeg, demucs, audio-separator, and yt-dlp from your PATH.
The model layer needs an ANTHROPIC_API_KEY; without one the tool falls back to
a built-in mix and runs fully offline.
Output drops straight into Plex/Jellyfin/Kodi:
<Artist>/Natural Perspective Spatial Audio/<Title> [...].flac (+ per-album index.html)
How it works
Separate stems → measure each stem's level → a model invents a scene and emits a
full mix configuration → a safety-clamped renderer builds the
7.1 FLAC. No audio is uploaded — only metadata, cover art, and the measured
stem levels inform the design. Every track saves its config and an index.html
documenting the scene, routing, and the exact model prompt/response.
Your responsibility, and credits
By processing a file or URL you affirm you have the right to it. This tool hosts
no content and ships no audio. See NOTICE for that and full credit to
the projects it builds on — FFmpeg, Demucs, audio-separator, yt-dlp, and the
Mel-Band RoFormer crowd model.
License
Apache-2.0 — see LICENSE and NOTICE. Provided as is,
without warranty of any kind.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file natural_perspective_spatial_audio-0.1.0.tar.gz.
File metadata
- Download URL: natural_perspective_spatial_audio-0.1.0.tar.gz
- Upload date:
- Size: 55.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7b995a16a039af924b7413d33cc5e70fc5e74e8580c6f5b98e7309d92a1b9fa3
|
|
| MD5 |
5ccc0a5e3fff1f3160d87f2099a21412
|
|
| BLAKE2b-256 |
f5c512c2bf9ccef138962d89bc53fe1510db6de76d89250e9cad8470f660d975
|
File details
Details for the file natural_perspective_spatial_audio-0.1.0-py3-none-any.whl.
File metadata
- Download URL: natural_perspective_spatial_audio-0.1.0-py3-none-any.whl
- Upload date:
- Size: 61.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
69708ec333972d19f19b15f07236e33d4a55ea4eb132e438f7ff828174acc23b
|
|
| MD5 |
f31a360cbf745ce73bd7e16089d877a3
|
|
| BLAKE2b-256 |
f0fc1629d4206ddd1becc13688b44518d22de17ec6c4427dd742ee11fa773563
|







