Idiomatic-PyTorch rewrite of NeuralGCM: nn.Module models, converted checkpoints 🌍⚡

Project description
neuralgcm-torch









NeuralGCM is a hybrid ML + physics
global circulation model that pairs a differentiable spectral dynamical core
with learned physics to forecast weather and run climate-scale simulations,
originally written in JAX.
This package brings it to PyTorch: load the published NeuralGCM checkpoints
(converted to torch) and forecast in a few lines.
import neuralgcm_torch as neuralgcm
from neuralgcm_torch import pretrained
path = pretrained.fetch_checkpoint('deterministic_2_8_deg') # cached download
model = neuralgcm.PressureLevelModel.from_checkpoint(path, device='cuda')
state = model.encode(model.inputs_from_xarray(era5_slice),
model.forcings_from_xarray(era5_slice), rng=42)
state, outputs = model.unroll(state, forcings, steps=4,
timedelta='24 hours', start_with_input=True)
predictions = model.data_to_xarray(outputs, times=range(0, 96, 24))
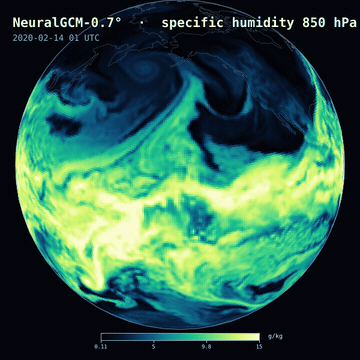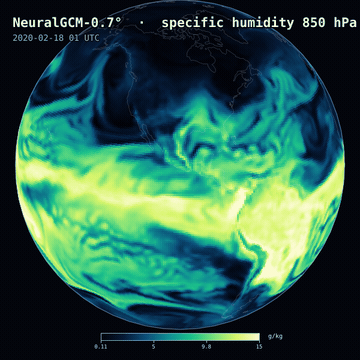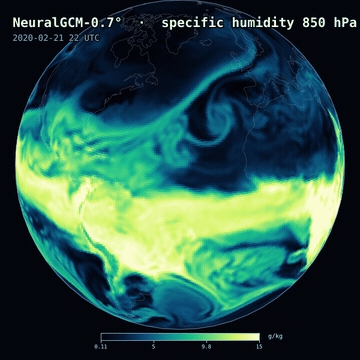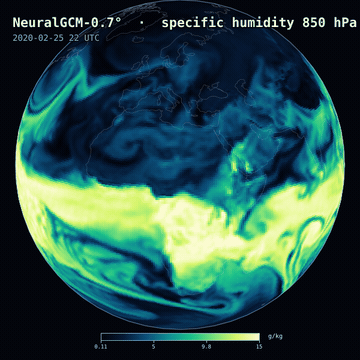
A 12-day NeuralGCM-0.7° forecast — 850 hPa specific humidity — on a slowly rotating globe.
NOTA BENE: This port is not affiliated with, endorsed by, or connected to the NeuralGCM authors or Google. It is a PyTorch reimplementation built on top of their published research and open-source weights. All credit for the models and science goes to the original team — see Acknowledgements. The original (JAX) project lives at github.com/neuralgcm/neuralgcm.
Why this exists
The large PyTorch weather-and-climate community deserves a hybrid ML-GCM they can drop into their own stacks:
- 🌐 A hybrid ML GCM, natively in PyTorch. A real
torch.nn.Modulewith registered parameters — composes withtorch.compile, CUDA graphs, autograd, DDP and the rest of the ecosystem out of the box. - 📦 Run the original checkpoints. All six published NeuralGCM v1 models (deterministic 0.7°/1.4°/2.8°, stochastic 1.4°, and the 2.8° precipitation / evaporation models) plus the TL63 toy, converted once and hosted on the Hugging Face Hub.
- ⚡ Performance close to JAX. With the
torch.compile+ CUDA-graph + max-autotune recipe the advance step runs up to 15× faster than eager and lands within ~1.25× of the original JAX/XLA model on the same GPU (2.8°: 12.5 ms vs ~9.9 ms; see Performance).
neuralgcm-torch specific enhancements:
- 🎲 Batched ensembles (new here). Stochastic ensemble members run through one batched model call instead of a Python loop over member (see Ensembles).
- 🖧 Multi-GPU training with DDP (new here). The full rollout loss wraps
as a DDP forward pass, so fine-tuning scales across GPUs with
torchrun(see DDP). - 📈 Differentiable & trainable with
torch.optim— a latitude-weighted rollout loss and a spectral rollout loss (the objective NeuralGCM trains with upstream), plus an end-to-end ERA5 fine-tuning script. - 📓 Every upstream notebook ported and executed, plus new ones for ensembles, climate-stability runs, and higher resolutions.
Idiomatic throughout: models are nn.Modules (no path-based parameter trees),
training is plain autograd + torch.optim, and randomness is integer seeds +
torch.Generator rather than key plumbing. Checkpoints are converted once,
offline, so this package has no jax (nor gin or haiku) dependency at runtime.
Quick start
pretrained.fetch_checkpoint pulls a converted checkpoint from the Hub and
caches it; from there it's the xarray-in / xarray-out API shown above. The
forecast_quickstart.ipynb notebook is the
complete, executed example — ERA5 from the public ARCO archive, conservative
regridding via dinosaur_torch.xarray_utils, and a forecast-vs-ERA5 comparison
(a PyTorch port of the upstream inference_demo, with day-4 2.8° T850 RMSE
≈ 1.0 K vs 4.2 K for persistence).
Notebooks
All upstream documentation notebooks are ported to PyTorch and executed end to end in notebooks/, alongside new ones unique to this port. They are also rendered online at dsip-fbk.github.io/neuralgcm-torch:
| notebook | what it shows |
|---|---|
forecast_quickstart |
2.8° deterministic forecast on real ERA5 (ported inference_demo) |
forecast_1_4_deg, forecast_0_7_deg |
higher-resolution forecasts (the 0.7° TL255 core, 512×256, 31M params) |
forecast_ens_1_4_deg 🎲 |
a NeuralGCM-ENS ensemble with spread and ensemble-mean skill |
forecast_precip_2_8_deg, forecast_evap_2_8_deg |
precipitation / evaporation from the learned water-budget closure |
climate_stability 🌡️ |
long stable rollouts — 1.4° stochastic for 6 months, 2.8° precip for 2 years — with seasonal ERA5 forcing, global stability indicators, T850 snapshots and the zonal-mean jet |
data_preparation |
regridding and xarray conversions |
deepdive_into_models |
model internals, autograd, encoded state, randomness (runs offline) |
checkpoint_modifications |
adding a surface-pressure output / global-mean filter by editing the converted config — plain dict edits, no gin |
Checkpoints on the Hub
The converted weights are hosted on the Hugging Face Hub, so loading needs
no legacy package, no GCS access and no conversion — just
pip install 'neuralgcm-torch[hub]' and pretrained.fetch_checkpoint(name)
(cached). pretrained.CHECKPOINTS lists the published set (six v1 models + the
TL63 toy). To pre-populate the notebooks' checkpoints/ directory in one shot:
uv run --no-sync python neuralgcm-torch/tools/fetch_checkpoints.py
The weights are derivative works of Google's NeuralGCM checkpoints
(CC BY-SA 4.0); the Hub
model card carries that license and attribution, separate from this package's
Apache-2.0 code. Override the default Hub repo with the
NEURALGCM_TORCH_HF_REPO environment variable.
Checkpoint format
Each checkpoint is converted once, offline from the original NeuralGCM JAX
pickle (gin config + dm-haiku params) into a plain torch.save dictionary (see
neuralgcm_torch/checkpoint.py): a structured
config (grids, sigma/pressure levels, nondimensional physics constants, time
step, variable lists, and the original config bindings as plain data),
auxiliary arrays (orography, land-sea mask, covariates), and the parameter
tensors keyed by their original paths. Loading needs only torch.load;
model_builder.from_checkpoint builds a ready, weight-loaded nn.Module from
it. Network input sizes are read from the checkpoint's parameter shapes and
weights are imported along the same paths, so any wiring mismatch fails loudly
rather than silently.
Performance
PressureLevelModel.compile wraps the advance step's two heavy submodules (the
dycore corrector and the neural physics parameterization) with torch.compile;
the stochastic-field update stays eager. With cudagraphs=True each compiled
submodule is additionally captured as a CUDA graph (inductor cudagraph trees),
removing per-kernel launch overhead — outputs are cloned out of the graph's
memory pool after each replay because the advanced state outlives the next
replay (it is the next step's input, and the step after that's memory).
Inductor's max-autotune mode (autotuned GEMM/conv kernels) composes on top via
compile(..., options=torch._inductor.list_mode_options('max-autotune-no-cudagraphs')).
Advance step on an RTX 5090 (torch 2.12 / cu13), every published checkpoint,
measured by tools/benchmark.py [--cudagraphs] [--max-autotune]:
| checkpoint | eager | compiled | + CUDA graphs | + max-autotune | days/min* |
|---|---|---|---|---|---|
| TL63 toy (stochastic) | 112 ms | 21.8 ms | 7.3 ms | 6.5 ms | 387 |
| 2.8° deterministic | 152 ms | 26.0 ms | 14.5 ms | 12.5 ms | 200 |
| 2.8° precipitation | 126 ms | 32.0 ms | 13.0 ms | 11.9 ms | 210 |
| 2.8° evaporation | 123 ms | 28.9 ms | 12.2 ms | 11.2 ms | 223 |
| 1.4° deterministic | 367 ms | 103 ms | 98 ms | 95 ms | 26 |
| 1.4° ENS (stochastic) | 373 ms | 106 ms | 101 ms | 97 ms | 26 |
| 0.7° deterministic | 1207 ms | 759 ms | 756 ms | 732 ms | 3 |
*simulated days per minute in the fastest mode (1-hour outer steps).
For reference, the original JAX/XLA model runs the same 2.8° advance step in ~9.9 ms on this hardware, so the compiled-and-captured torch model (12.5 ms) sits within ~1.3× of it.
Two regimes are visible: the TL63/2.8° models are launch-bound — graph capture is the big win (10–15× total) and max-autotune shaves another ~10% — while the 1.4°/0.7° models are compute-bound — compilation buys 1.6–3.7× and capture/autotuning only a few percent more. Plain compilation costs ~0.5–4 minutes one-time; max-autotune raises that to ~3–13 minutes (cached across runs by inductor). Compiled-vs-eager differences are float32 reassociation (~1e-7 of range per step) amplified chaotically over rollouts, exactly as for any kernel reordering.
Ensembles
Stochastic-model ensemble members differ only in their random state, so members can be batched through one model call instead of looped:
state = model.encode_ensemble(inputs, forcings, rngs=range(8))
state, outputs = model.unroll(state, forcings, steps=4, timedelta='24 hours')
predictions = model.data_to_xarray(outputs, times=times,
members=range(8)) # 'member' dim
The batched state carries a leading member axis on every tensor (shared
sim_time, one RNG key chain per member); advance/unroll/decode work
unchanged, and each member draws bitwise the same noise its sequential
encode(rng=r) run would, so trajectories match the member loop up to float
reassociation in the batched kernels. Individual members extract back to regular
states with ensembles.member_state(state, i).
Training
The model is differentiable end to end (encoder → physics network → dycore → decoder), so fine-tuning is a plain PyTorch loop:
from neuralgcm_torch import data, training
dataset = data.TrajectoryDataset(era5, model, outer_steps=2)
optimizer = torch.optim.AdamW(model.model.parameters(), lr=1e-5)
for example in torch.utils.data.DataLoader(dataset, batch_size=None,
shuffle=True):
loss = training.train_step(model, optimizer, example, rng=0)
training.rollout_loss is a latitude-weighted, per-variable-normalized MSE on
the decoded pressure-level outputs over short rollouts;
training.spectral_rollout_loss accumulates the same normalized errors in
spherical-harmonic space instead (exact area weighting by Parseval, optional
wavenumber_cutoff to fit only the resolvable scales — the spectral form of the
objectives NeuralGCM trains with upstream). Models operate on single examples
(no batch axis) — use batch_size=None and accumulate gradients.
tools/finetune_era5.py is the end-to-end demonstration: it samples short rollout windows from a month of ARCO-ERA5 (streamed at 0.25° and regridded to the model's data grid, ~15 MB cached), fine-tunes with the spectral loss, and reports held-out day-3 T850/Z500 RMSE before and after.
Multi-GPU (DDP)
Data parallelism is the right scaling strategy at NeuralGCM sizes (full replica
per GPU, different examples per rank). Because training drives the model through
encode/advance/decode rather than a forward, distributed.wrap wraps
the whole rollout loss as the DDP forward pass:
rank, world = distributed.init() # under torchrun
ddp_loss = distributed.wrap(model) # find_unused_parameters on
sampler = distributed.example_sampler(dataset)
loss = distributed.train_step(ddp_loss, optimizer, example, rng=step)
torchrun --nproc_per_node=N tools/finetune_era5.py ... shards the example
sampler across ranks. Correctness is locked by a 2-process gloo test asserting
the DDP step equals a single-process step on the averaged gradients.
Status
All six published NeuralGCM v1 checkpoints plus the TL63 toy convert, build with exact parameter counts (0.19M toy up to 31M for the 0.7° model), and match the original JAX models end to end:
- End-to-end equivalence: encode / 3×advance / decode deviations of 1e-4–1e-3 of each field's range vs the original JAX models, with the learned AR(1) stochastic parameters exercised (statistical equivalence for random draws; deterministic comparisons run with noise zeroed on both sides).
- Full model stack ported with per-module
import_haiku(params, prefix)loaders reproducing the original parameter paths: layers/towers, transforms/filters, features, embeddings, mappings, orographies, forcings, stochastic fields, diagnostics (surface pressure; constrained precipitation/evaporation), encoders, decoders,DivCurlNeuralParameterization, correctors, steps,StochasticModularStepModel. - Inference API (
api.PressureLevelModel): xarray in/out, units and time conversions,encode/advance/decode/unroll,compile— validated against the original NeuralGCM API end to end.
Built on dinosaur-torch, the idiomatic-PyTorch port of the Dinosaur spectral dynamical core.
Acknowledgements
NeuralGCM is the work of its authors at Google Research and collaborators. This PyTorch port stands entirely on their research and their decision to open-source the models and weights — thank you. Please cite the original work:
Kochkov, D., Yuval, J., Langmore, I. et al. Neural general circulation models for weather and climate. Nature 632, 1060–1066 (2024).
- Original NeuralGCM (JAX): https://github.com/neuralgcm/neuralgcm
- Dinosaur dynamical core (JAX): https://github.com/neuralgcm/dinosaur
License
Apache-2.0 for the code. The converted model weights are derivative works of NeuralGCM checkpoints and are distributed separately on the Hugging Face Hub under CC BY-SA 4.0.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file neuralgcm_torch-0.1.2.tar.gz.
File metadata
- Download URL: neuralgcm_torch-0.1.2.tar.gz
- Upload date:
- Size: 1.6 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.19 {"installer":{"name":"uv","version":"0.11.19","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
508a20210bf54209257b036bd693ba4abc5d25a26df0715f58b5046e83aec711
|
|
| MD5 |
fafd641bccd09750b870beae0158d261
|
|
| BLAKE2b-256 |
71018c996477078218ce36103e0ed2ab4a548e555ffb464b359f63d0b80c299b
|
File details
Details for the file neuralgcm_torch-0.1.2-py3-none-any.whl.
File metadata
- Download URL: neuralgcm_torch-0.1.2-py3-none-any.whl
- Upload date:
- Size: 1.6 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.19 {"installer":{"name":"uv","version":"0.11.19","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a405e0c7a853142ee0f8f1c8114c08867c575a004a9be3507968314b6bfe587f
|
|
| MD5 |
0312f0c354be3685e0c8410c0f954a64
|
|
| BLAKE2b-256 |
9c61eab98302ba0201828cbbf1bb4da8807b517917816bfefa512e329e04de8d
|







