Korean STT (Speech-to-Text) error rate calculation package

Project description



한국어 자동 음성 인식 평가를 위한 유사도 측정 함수 패키지
이 저장소에는 Amazon Transcribes와 같은 한글 문장 인식기의 출력 스크립트의 낱말 오류율(CER), 단어 오류율(WER)을 계산하는 간단한 Python 패키지가 포함되어있습니다. STT(speech-to-text) API의 실제(Ground truth)문장과 가설(hypothesis or transcribe)문장 사이의 최소 편집거리를 계산합니다. 최소편집거리는 Dynamic Programing 기법 중 Levenshtein을 사용하여 계산됩니다.
문자 오류율(CER/WER)은 자동 음성 인식 시스템의 성능에 대한 일반적인 메트릭입니다. CER은 WER(단어 오류율)과 유사하지만 단어 대신 문자에 대해 작동합니다. 자세한 내용은 WER 문서를 참조하십시오.[1] 문자 오류율은 다음과 같이 계산할 수 있습니다.
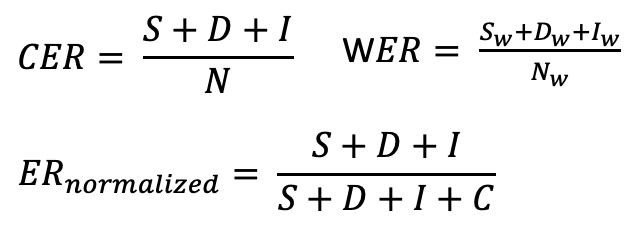
CER(WER) = (S + D + I) / N = (S + D + I) / (S + D + I + C)
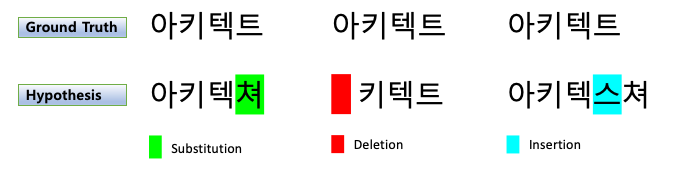
- S : 대체 오류, 철자가 틀린 외자(uniliteral)/단어(word) 횟수
- D : 삭제 오류, 외자/단어의 누락 횟수
- I : 삽입 오류, 잘못된 외자/단어가 포함된 횟수
- C : Ground truth와 hypothesis 간 올바른 외자/단어(기호)의 합계, (N - D - S)
- N : 참조의(Ground truth) 외자/단어 수
CER의 출력은 특히 삽입 수가 많은 경우 항상 0과 1 사이의 숫자가 아닙니다. 이 값은 종종 잘못 예측된 문자의 백분율과 연관됩니다. 값이 낮을수록 ASR 시스템의 성능이 향상되고 CER이 0이면 완벽한 점수입니다. 이 함수에서는 insertion에 따른 오류값 초과에 대해 normalized error rate으로 적용했습니다.[2]
CER은 자동 음성 인식(ASR) 및 광학 문자 인식(OCR)과 같은 작업에 대한 다양한 모델을 비교하는 데 유용하며, 특히 언어의 다양성으로 인해 WER이 적합하지 않은 다국어 데이터 세트의 경우에 유용합니다. CER 같은 경우, 번역 오류의 특성에 대한 세부 정보를 제공하지 않으므로 오류의 주요 원인을 식별하고 연구 노력에 집중하기 위해서는 추가 작업이 필요합니다. 또한 경우에 따라 원본 ER을 보고하는 대신 실수 수를 편집 작업 수(I + S + D)와 C(정확한 문자 수)의 합으로 나눈 정규화된 ER이 필요합니다. 그 결과 0–100% 범위에 속하는 CER 값이 생성됩니다.
국내관련발표기고
클라우드와 오픈소스 위스퍼를 이용한 한국어 음성 텍스트 변환
- http://www.itdaily.kr/news/articleView.html?idxno=213297
- http://www.comworld.co.kr/news/articleView.html?idxno=50818
개발 배경 글
이 패키지를 만들게 된 배경과 한국어 ASR/STT 평가 실험을 정리한 프롤로그 글입니다.
- Korean: https://hyeonsangjeon.github.io/job-transcribe/
- English: https://hyeonsangjeon.github.io/job-transcribe/en/
사용방법
가장 간단한 사용 사례는 두 문자열 간의 편집 거리를 계산하는 것입니다.
pip install nlptutti
평가 정책
get_cer("", ""),get_wer("", "")처럼 참조문장과 가설문장이 모두 비어 있으면 완전 일치로 보고 오류율0.0을 반환합니다.- 참조문장은 비어 있고 가설문장만 있는 경우에는 전체를 삽입 오류로 계산합니다.
- CER/CRR 계산에서는
rm_punctuation값과 관계없이 공백을 제거합니다.rm_punctuation은 문장부호 제거 여부만 제어합니다. - 키워드 패턴은 정규식 특수문자를 포함한 키워드도 안전하게 처리하며, 긴 단어 내부의 부분문자열 오탐을 줄이기 위해 키워드 앞뒤 경계를 검사합니다.
calculate_keyword_error_rate_with_pattern은 참조문장 리스트와 STT 결과 리스트의 길이가 다르면ValueError를 발생시킵니다.
CER
import nlptutti as metrics
refs = "아키택트"
preds = "아키택쳐"
# prints: [cer, substitutions, deletions, insertions] -> [CER = 1 / 4, S = 1, D = 0, I = 0]
import nlptutti as metrics
refs = "제이 차 세계 대전은 인류 역사상 가장 많은 인명 피해와 재산 피해를 남긴 전쟁이었다."
preds = "제이차 세계대전은 인류 역사상 가장많은 인명피해와 재산피해를 남긴 전쟁이었다."
result = metrics.get_cer(refs, preds)
cer = result['cer']
substitutions = result['substitutions']
deletions = result['deletions']
insertions = result['insertions']
# prints: [cer, substitutions, deletions, insertions] -> [CER = 0 / 34, S = 0, D = 0, I = 0]
WER
import nlptutti as metrics
refs = "대한민국은 주권 국가 입니다."
preds = "대한민국은 주권국가 입니다."
result = metrics.get_wer(refs, preds)
wer = result['wer']
substitutions = result['substitutions']
deletions = result['deletions']
insertions = result['insertions']
# prints: [wer, substitutions, deletions, insertions] -> [WER = 2 / 4, S = 1, D = 1, I = 0]
CRR
import nlptutti as metrics
refs = "제이 차 세계 대전은 인류 역사상 가장 많은 인명 피해와 재산 피해를 남긴 전쟁이었다."
preds = "제이차 세계대전은 인류 역사상 가장많은 인명피해와 재산피해를 남긴 전쟁이었다."
result = metrics.get_crr(refs, preds)
crr = result['crr']
substitutions = result['substitutions']
deletions = result['deletions']
insertions = result['insertions']
# prints: [crr, substitutions, deletions, insertions] -> [CRR = 1 - (0 / 34), S = 0, D = 0, I = 0]
전처리 예
띄어쓰기
가설 또는 정답 텍스트에 일부 전처리 단계를 적용해야 할 수 있습니다. 한국어 문장 구성은 단어간 띄어쓰기의 모호성으로 CER계산에서 공백을 계산하지 않았습니다. 근대 이전까지 동양의 언어에는 ‘띄어쓰기’ 개념이 존재하지 않았고, 한국어는 맞춤법 상 띄어쓰기 규칙이 정해져 있기는 하나, 띄어쓰기를 지키지 않아도 문장의 맥락을 이해하는데 큰 무리가 없는 언어입니다. 따라서 CER 계산에서 입력 변수의 whitespace는 제거합니다. 공백 문자는 \t, \n, \r, \x0b 및 \x0c와 whitespace입니다.
ref = '또 다른 방법으로 데이터를 읽는 작업과 쓰는 작업을 분리합니다'
refs -> 또다른방법으로데이터를읽는작업과쓰는작업을분리합니다
구두점 처리
STT 인식기에 따라 구두점을 처리하지 않는 경우가 많습니다. 입력 변수의 구두점 필터링은 flag처리로 사용할 수 있습니다. 필터링 기본값은 True입니다. 구두점 문자는:
구두점 filter-> '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
import nlptutti as metrics
refs = "또 다른 방법으로, 데이터를 읽는 작업과 쓰는 작업을 분리합니다!"
preds = "또! 다른 방법으로 데이터를 읽는 작업과 쓰는 작업을 분리합니다."
result = metrics.get_wer(refs, preds, rm_punctuation=True)
# prints: wer -> 0.0
한국어 고유명사 인식평가 (make_keyword_pattern)
make_keyword_pattern 함수는 한국어 자연어 처리(NLP)에서 매우 중요한 형태소의 변이와 띄어쓰기 오류를 robust하게 다루기 위해 설계된 함수입니다.
이 함수는 입력한 키워드가 실제 문장 내에서 조사(예: "의", "에서", "까지" 등), **어미(예: "다", "했다" 등)**와 결합하거나, 키워드 내부에 불규칙한 띄어쓰기가 포함되어 나타나는 다양한 형태 모두를 정규표현식 패턴으로 포괄적으로 인식할 수 있게 해줍니다.
특히 한국어 음성인식(STT) 결과에서는 띄어쓰기 오류나 조사·어미 결합이 빈번하게 발생해 키워드 매칭이 어렵기 때문에,
이 함수를 활용하면 키워드 기반 오류 분석이나 고유명사 인식 평가 등에서 훨씬 더 정확한 평가가 가능합니다.
import nlptutti as nt
from nlptutti.asr_metrics import make_keyword_pattern, COMPLEX_JOSA
# 조사 리스트 (기본 제공되는 COMPLEX_JOSA 사용 가능)
josa_list = ["의", "에서", "까지", "도", "만", "를", "을", "은", "는", "이", "가", "와", "과"]
# 어미 리스트 (선택사항)
eomi_list = ["다", "합니다", "했다", "한다", "한다면", "하고"]
# "삼성전자" 키워드에 대한 패턴 생성
pattern = make_keyword_pattern("삼성전자", josa_list, eomi_list)
# 테스트 문장들
test_sentences = [
"삼성전자", # True
"삼성전자의", # True
"삼 성 전 자의", # True (띄어쓰기 있어도 인식)
"삼성전자에서부터", # True (조사 확장 포함)
"삼성전자합니다", # True (어미 결합)
"삼성전자 했다", # True (어미 결합, 띄어쓰기)
"애플은" # False
]
for sentence in test_sentences:
is_matched = bool(pattern.search(sentence))
print(f"'{sentence}' → {is_matched}")
NLP적 의의
- 키워드와 조사, 어미, 띄어쓰기 등 다양한 실제 사용 맥락을 포괄적으로 처리
- 형태소 분석 없이도 정규표현식만으로 한국어의 대표적 변이현상(조사·어미 결합, 띄어쓰기 오류 등)에 강건
- 음성인식(STT) 결과물, 문서 검색, 정보추출 등에서 키워드 기반 평가 및 분석의 정밀도를 크게 향상
고유명사 인식 정확도 평가 사용 예시 (calculate_keyword_error_rate_with_pattern)
calculate_keyword_error_rate_with_pattern 함수는 여러 키워드에 대해 STT 인식 결과와 참조문장을 비교하여,
각 키워드별 인식 정확도 및 전체 요약 통계를 제공합니다.
조사·어미·띄어쓰기 등 한국어 변형을 유연하게 처리하므로, 고유명사/중요 단어의 STT 인식 품질 평가에 적합합니다.
from nlptutti.asr_metrics import calculate_keyword_error_rate_with_pattern, COMPLEX_JOSA
# 조사·어미 리스트 정의 (필요시 확장 가능)
josa = COMPLEX_JOSA + ["라는", "이라는", "에서의", "으로서의"]
eomi = ["다", "합니다", "했다", "한다면", "하고", "하는데", "했었다"]
# 참조(정답) 문장과 STT(가설) 문장
refs = [
"오늘은 메리츠화재의 주식이 올랐습니다.",
"애플은 새로운 아이폰을 발표했습니다.",
"구글에서 검색해보세요.",
"메리츠화재까지도 주가가 상승했다."
]
hyps = [
"오늘은 매리츠화제의 주식이 올랐습니다.", # 메리츠화재 → 매리츠화제 (오류)
"애플은 새로운 아이푼을 발표했습니다.", # 아이폰 → 아이푼 (오류)
"구글에서 검색해보세요.", # 정확 인식
"메리츠 화재까지도 주가가 상승했다." # 띄어쓰기 포함, 정확 인식
]
keywords = ["메리츠화재", "애플", "구글", "아이폰"]
# 오류율 계산 및 결과 출력
result = calculate_keyword_error_rate_with_pattern(refs, hyps, keywords, josa, eomi)
print("=== 개별 키워드 결과 ===")
for k, stats in result["keywords"].items():
print(f"'{k}': 총 {stats['total']}회, 정확 {stats['correct']}회, 오류 {stats['errors']}회")
print(f" 정확도: {stats['accuracy']:.1%}, 에러율: {stats['error_rate']:.1%}")
print("\n=== 전체 키워드 요약 ===")
s = result["summary"]
print(f"전체 키워드 등장 횟수: {s['total_keywords']}")
print(f"정확히 인식된 키워드: {s['correct_keywords']}")
print(f"오류가 발생한 키워드: {s['incorrect_keywords']}")
print(f"전체 키워드 에러율: {s['keyword_error_rate']:.1%}")
출력 예시
=== 개별 키워드 결과 ===
'삼성전자': 총 2회, 정확 1회, 오류 1회
정확도: 50.0%, 에러율: 50.0%
'애플': 총 1회, 정확 1회, 오류 0회
정확도: 100.0%, 에러율: 0.0%
'구글': 총 1회, 정확 1회, 오류 0회
정확도: 100.0%, 에러율: 0.0%
'아이폰': 총 1회, 정확 0회, 오류 1회
정확도: 0.0%, 에러율: 100.0%
=== 전체 키워드 요약 ===
전체 키워드 등장 횟수: 5
정확히 인식된 키워드: 3
오류가 발생한 키워드: 2
전체 키워드 에러율: 40.0%
반환값 구조
{
"keywords": {
"키워드명": {
"total": 등장횟수, # 참조 문장에서의 총 등장 횟수
"correct": 정확개수, # 정확히 인식된 횟수
"errors": 오류횟수, # 인식 실패 횟수
"accuracy": 정확도율, # correct/total
"error_rate": 에러율 # errors/total
}
},
"summary": {
"total_keywords": 전체등장횟수, # 모든 키워드의 총 등장 횟수
"correct_keywords": 전체정확횟수, # 전체 정확히 인식된 횟수
"incorrect_keywords": 전체오류횟수, # 전체 인식 실패 횟수
"keyword_error_rate": 전체에러율 # 전체 키워드 에러율
}
}
NLP적 의미
- 형태소 변이, 띄어쓰기 오류, 조사·어미 결합 등 한국어 STT 결과의 자연스러운 변형을 고려하여 키워드 인식 성능을 신뢰성 있게 평가합니다.
- 특히 고유명사, 신조어, 전문용어 등 특정 단어의 인식률 분석 시 유용합니다.
References
[1]. Word Error Rate, https://en.wikipedia.org/wiki/Word_error_rate[2]. Computing error rates, Text Digitisation, https://sites.google.com/site/textdigitisation/qualitymeasures/computingerrorrates
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nlptutti-0.0.0.11.tar.gz.
File metadata
- Download URL: nlptutti-0.0.0.11.tar.gz
- Upload date:
- Size: 18.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e1cf33014814b2e38d4f35a69fff1f972032f4268821e164aec1797203b228bf
|
|
| MD5 |
1f5b3aa1d49f54f68b71c3e5b1f8cda7
|
|
| BLAKE2b-256 |
c2d7d5bed9cda10839fd9cdf2f43b284aeff7ce7de1ba2a6af0927321f097a27
|
File details
Details for the file nlptutti-0.0.0.11-py3-none-any.whl.
File metadata
- Download URL: nlptutti-0.0.0.11-py3-none-any.whl
- Upload date:
- Size: 12.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4881b2e8c49dea572b739cced9f04e9276c0e6dd697eaa839639ac428dc053ef
|
|
| MD5 |
ceda5b3a43d85a0b3254189bb60213a1
|
|
| BLAKE2b-256 |
3283600c8b22ed61a8eb9ea4cd3b50860220c85eacab39d8185eeb3b0877c66c
|







