Fraunhofer HHI implementation of the Neural Network Coding (NNC) Standard

Project description

A Software Implementation of the ISO/IEC 15938-17 Neural Network Coding (NNC) Standard
Table of Contents
Information
This repository hosts a beta version of NNCodec 2.0, which incorporates new compression tools for incremental neural network data, as introduced in the second edition of the NNC standard. It also supports coding "Tensors in AI-based Media Processing" (TAIMP), addressing recent MPEG requirements for coding individual tensors rather than entire neural networks or differential updates to a base neural network.
The repository also includes a novel use case demonstrating federated learning (FL) for tiny language models in telecommunications.
The official NNCodec 1.0 git repository, which served as the foundation for this project, can be found here:

It also contains a Wiki-Page providing further information on NNCodec.
Upon approval, this second version will update the official git repository.
The Fraunhofer Neural Network Encoder/Decoder (NNCodec)
NNCodec is an efficient implementation of NNC (Neural Network Coding ISO/IEC 15938-17), the first international standard for compressing (incremental) neural network data. It provides the following main features:
- Standard-compliant encoder/decoder including, e.g., DeepCABAC, quantization, and sparsification
- Built-in support for common deep learning frameworks (e.g., PyTorch)
- Integrated support for data-driven compression tools on common datasets (ImageNet, CIFAR, PascalVOC)
- Federated AI support via Flower, a prominent and widely used framework
- Compression pipelines for:
- Neural Networks (NN)
- Tensors (TAIMP)
- Federated Learning (FL)
Quick Start
Install and run a tensor compression example:
pip install nncodec
python example/tensor_coding.py
Installation
Requirements
- Python >= 3.8 with working pip
- Windows: Visual Studio 2015 Update 3 or later
Package Installation from PyPI
NNCodec 2.0 supports pip installation:
pip install nncodec
will install packages from install_requires list in setup.py
Package Installation from Source
To install NNCodec from source, we recommend creating a virtual Python environment and install via pip from the root of the cloned repository:
python3 -m venv env
source env/bin/activate
pip install --upgrade pip
pip install -e .
NNCodec Usage
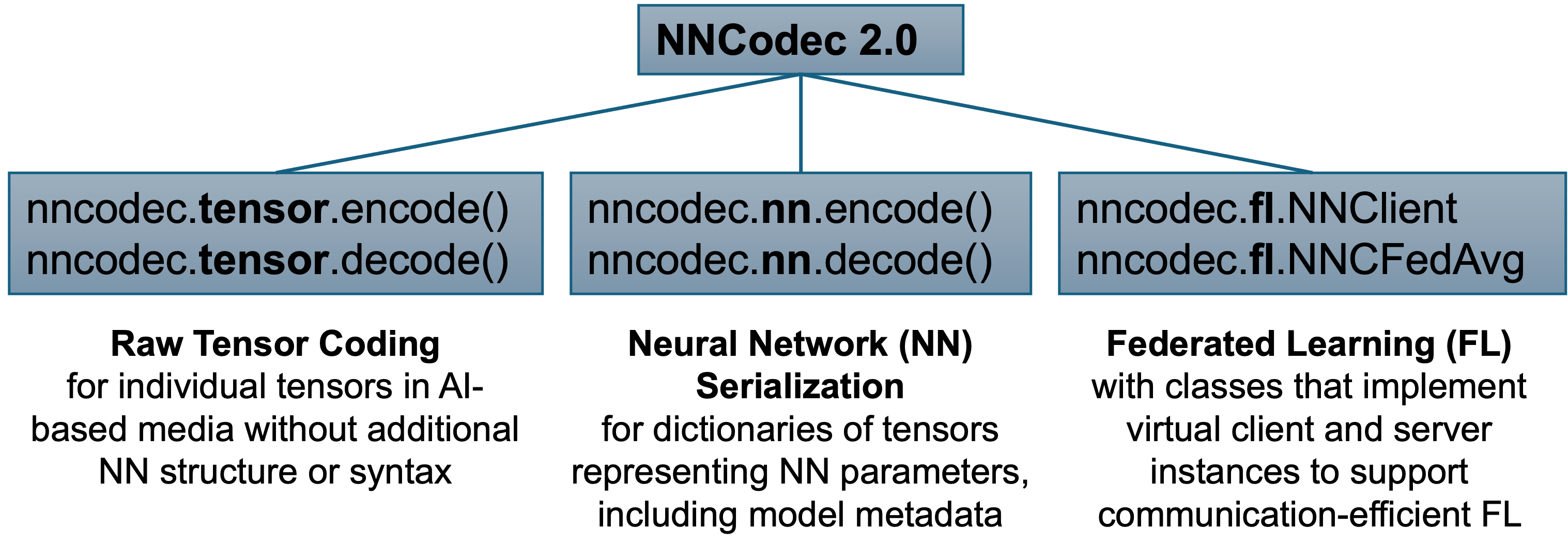
NNCodec 2.0, as depicted above, includes three main pipelines:
- One for tensorial data in AI-based media processing (e.g., function coefficients, feature maps, ...),
from nncodec.tensor import encode, decode
- one for coding entire neural networks (or their differential updates), and
from nncodec.nn import encode, decode
- one for federated learning scenarios.
from nncodec.fl import NNClient, NNCFedAvg
Coding Tensors in AI-based Media Processing (TAIMP)
The tensor_coding.py script provides encoding and decoding examples of random tensors. The first example codes a random PyTorch tensor (which could also be an integer tensor or a numpy array):
example_tensor = torch.randn(256, 64, 64) # torch.randint(0, 255, (3, 3, 32, 32)) # example 8-bit uint tensor
bitstream = encode(example_tensor, args_dict)
dec_tensor = torch.tensor(decode(bitstream, args_dict["tensor_id"]))
here, args_dict is a python dictionary that specifies the encoding configuration. The default configuration is:
args_dict = { 'approx_method': 'uniform', # Quantization method ['uniform' or 'codebook']
'qp': -32, # main quantization parameter (QP)
'nonweight_qp': -75, # QP for non-weights, e.g., 1D or BatchNorm params (default: -75, i.e., fine quantization)
'use_dq': True, # enables dependent scalar / Trellis-coded quantization
'bitdepth': None, # Optional: integer-aligned bitdepth for limited precision [1, 31] bit; note: overwrites QPs.
'quantize_only': False, # if True encode() returns quantized parameter instead of bitstream
'tca': False, # enables Temporal Context Adaptation (TCA)
'row_skipping': True, # enables skipping tensor rows from arithmetic coding if entirely zero
'sparsity': 0.0, # introduces mean- & std-based unstructured sparsity [0.0, 1.0]
'struct_spars_factor': 0.0, # introduces structured per-channel sparsity (based on channel means); requires sparsity > 0.0
'job_identifier': 'TAIMP_coding', # Name extension for generated *.nnc bitstream files and for logging
'results': '.', # path where results / bitstreams shall be stored
'tensor_id': '0', # identifier for tensor
'tensor_path': None, # path to tensor to be encoded
'compress_differences': False, # if True bitstream represents a differential update of a base tensor; set automatically if TCA enabled
'verbose': True # print stdout process information.
}
An exemplary minimal config:
args_dict = {
'approx_method': 'uniform', 'bitdepth': 4, 'use_dq': True, 'sparsity': 0.5, 'struct_spars_factor': 0.9, 'tensor_id': '0'
}
The second example targets incremental tensor coding with the coding tool Temporal Context Adaptation (TCA).
Running tensor_coding.py with --incremental updates 50% of the example tensor's elements for num_increments
iterations and stores the previously decoded, co-located tensor in approx_param_base.
approx_param_base must be initialized with
approx_param_base = {"parameters": {}, "put_node_depth": {}, "device_id": 0, "parameter_id": {}}
Coding Neural Networks and Neural Network Updates
The nn_coding.py script provides
encoding and decoding examples of entire neural networks (NN) (--uc=0), incremental full NN (--uc=1)
and incremental differential dNN (--uc=2).
Minimal example: In its most simple form, an NN's parameters can be represented as a python dictionary of float32 or int32 numpy arrays:
from nncodec.nn import encode, decode
import numpy as np
model = {f"parameter_{i}": np.random.randn(np.random.randint(1, 36),
np.random.randint(1, 303)).astype(np.float32) for i in range(5)}
bitstream = encode(model)
rec_mdl_params = decode(bitstream)
Hyperparameters can be inserted (like in the nncodec.tensor pipeline above) by passing an args_dict
to encode() containing one or more configurations, e.g.,
bitstream = encode(model, args={'qp': -24, 'use_dq': True, 'sparsity': 0.4})
or instead of a qp also a bitdepth can be used:
bitstream = encode(model, args={'bitdepth': 4, 'use_dq': True, 'sparsity': 0.4})
Example CLI: For coding an actual NN, we included a ResNet-56 model pre-trained on CIFAR-100. Additionally, all torchvision models can be coded out of the box. To see a list of all available models, execute:
python example/nn_coding.py --help
The following example codes the mobilenet_v2 model from torchvision:
python example/nn_coding.py --model=mobilenet_v2
The following example codes ResNet-56 and tests the model's performance afterward:
python example/nn_coding.py --dataset_path=<your_path> --dataset=cifar100 --model=resnet56 --model_path=./models/ResNet56_CIF100.pt
Training a randomly initialized ResNet-56 from scratch and code the incremental updates with temporal context adaptation (TCA) is achieved by:
python example/nn_coding.py --uc=1 --dataset_path=<your_path> --model=resnet56 --model_rand_int --dataset=cifar100 --tca
For coding incremental differences with respect to the base model, i.e., 
--uc=2.
--max_batches can be used to decrease the number of batches used per train epoch.
Other available hyperparameters and coding tools like --sparsity, --use_dq, --opt_qp, --bitdepth, --approx_method=codebook, and others are described in nn_coding.py.
Federated Learning with NNCodec
The nnc_fl.py file implements a base script for communication-efficient
Federated Learning with NNCodec. It imports the NNClient and NNCFedAvg classes — specialized NNC-Flower objects — that
are responsible for establishing and handling the compressed FL environment.
Important: Install Flower before using, e.g., by issuing:
pip install -U "flwr[simulation]>=1.5"
The default configuration launches FL with two ResNet-56 clients learning the CIFAR-100 classification task. The CIFAR dataset
is automatically downloaded if not available under --dataset_path (~170MB).
python example/nnc_fl.py --dataset_path=<your_path> --model_rand_int --epochs=30 --compress_upstream --compress_downstream --err_accumulation --compress_differences
Main coding tools and hyperparameter settings for coding are:
--qp 'Quantization parameter (QP) for NNs (default: -32)'
--diff_qp 'Quantization parameter for dNNs. Defaults to QP if unspecified (default: None)'
--nonweight_qp 'QP for non-weights, e.g., 1D or BatchNorm params (default: -75)'
--opt_qp 'Enables layer-wise QP modification based on relative layer size within NN'
--use_dq 'Enables dependent scalar / Trellis-coded quantization'
--bitdepth 'Optional: integer-aligned bitdepth for limited precision [1, 31] bit; note: overwrites QPs.'
--bnf 'Enables incremental BatchNorm Folding (BNF)'
--sparsity 'Introduces mean- & std-based unstructured sparsity [0.0, 1.0] (default: 0.0)'
--struct_spars_factor 'Introduces structured per-channel sparsity (based on channel means); requires sparsity > 0 (default: 0.9)'
--row_skipping 'Enables skipping tensor rows from arithmetic coding that are entirely zero'
--tca 'Enables Temporal Context Adaptation (TCA)'
Additional important hyperparameters for FL (among others in nnc_fl.py):
--compress_differences 'Weight differences wrt. to base model (dNN) are compressed, otherwise full base models (NN) are communicated'
--model_rand_int 'If set, model is randomly initialized, i.e., w/o loading pre-trained weights'
--num_clients 'Number of clients in FL scenario (default: 2)'
--compress_upstream 'Compression of clients-to-server communication'
--compress_downstream 'Compression of server-to-clients communication'
--err_accumulation 'If set, quantization errors are locally accumulated ("residuals") and added to NN update prior to compression'
Section Paper results (EuCNC) below introduces an additional use case and implementation of NNCodec 2.0 FL with tiny language models collaboratively learning feature predictions in cellular data.
Logging results using Weights & Biases
We used Weights & Biases (wandb) for experimental results logging. Enable --wandb if you want to use it. Add your wandb key and optionally an experiment identifier for the run:
--wandb --wandb_key="my_key" --wandb_run_name="my_project"
Important: Install wandb before using, e.g., by issuing:
pip install wandb
Paper results
-
EuCNC 2025 Poster Session
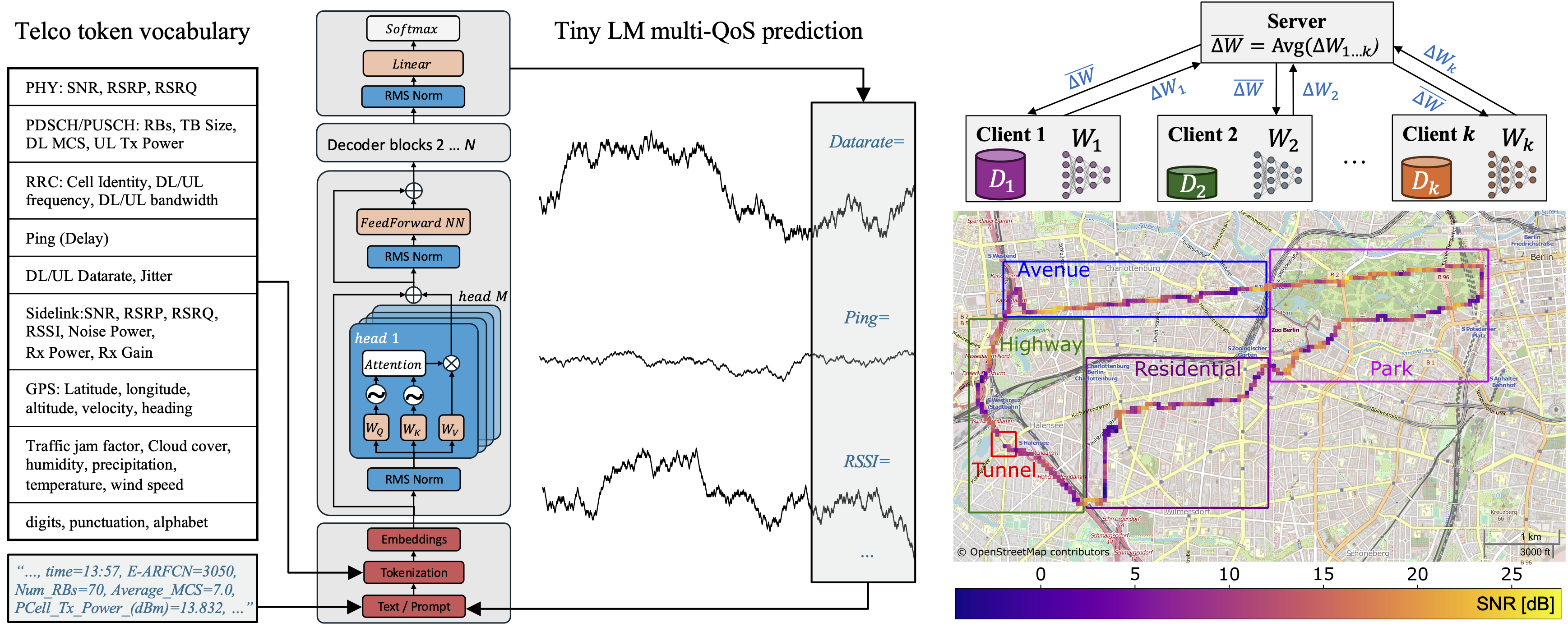
We presented "Efficient Federated Learning Tiny Language Models for Mobile Network Feature Prediction" at the Poster Session I of the 2025 Joint European Conference on Networks and Communications & 6G Summit (EuCNC/6G Summit).
TL;DR - This work introduces a communication-efficient Federated Learning (FL) framework for training tiny language models (TLMs) that collaboratively learn to predict mobile network features (such as ping, SNR or frequency band) across five geographically distinct regions from the Berlin V2X dataset. Using NNCodec, the framework reduces communication overhead by over 99% with minimal performance degradation, enabling scalable FL deployment across autonomous mobile network cells.
To reproduce the experimental results and evaluate NNCodec in the telco FL setting described above, execute:
python example/nnc_fl.py --dataset=V2X --dataset_path=<your_path>/v2x --model=tinyllama --model_rand_int \ --num_clients=5 --epochs=30 --compress_upstream --compress_downstream --err_accumulation --compress_differences \ --qp=-18 --batch_size=8 --max_batches=300 --max_batches_test=150 --sparsity=0.8 --struct_spars_factor=0.9 \ --TLM_size=1 --tca --tokenizer_path=./example/tokenizer/telko_tokenizer.model
The pre-tokenized Berlin V2X dataset can be downloaded here: https://datacloud.hhi.fraunhofer.de/s/CcAeHRoWRqe5PiQ and the pre-trained Sentencepiece Tokenizer is included in this repository at telko_tokenizer.model.
Resulting bitstreams and the best performing global TLM of all communication rounds will be stored in a
resultsdirectory (with path set via--results). To evaluate this model, execute:python example/eval.py --model_path=<your_path>/best_tinyllama_.pt --batch_size=1 --dataset=V2X \ --dataset_path=<your_path>/v2x --model=tinyllama --TLM_size=1 --tokenizer_path=./example/tokenizer/telko_tokenizer.model
-
ICML 2023 Neural Compression Workshop
Our paper titled "NNCodec: An Open Source Software Implementation of the Neural Network Coding ISO/IEC Standard" was awarded a Spotlight Paper at the ICML 2023 Neural Compression Workshop.
TL;DR - The paper presents NNCodec 1.0, analyses its coding tools with respect to the principles of information theory and gives comparative results for a broad range of neural network architectures. The code for reproducing the experimental results of the paper and a software demo are available here:



Citation and Publications
If you use NNCodec in your work, please cite:
@inproceedings{becking2023nncodec,
title={{NNC}odec: An Open Source Software Implementation of the Neural Network Coding {ISO}/{IEC} Standard},
author={Daniel Becking and Paul Haase and Heiner Kirchhoffer and Karsten M{\"u}ller and Wojciech Samek and Detlev Marpe},
booktitle={ICML 2023 Workshop Neural Compression: From Information Theory to Applications},
year={2023},
url={https://openreview.net/forum?id=5VgMDKUgX0}
}
Additional Publications (chronological order)
- D. Becking et al., "Neural Network Coding of Difference Updates for Efficient Distributed Learning Communication", IEEE Transactions on Multimedia, vol. 26, pp. 6848–6863, 2024, doi: 10.1109/TMM.2024.3357198, Open Access
- H. Kirchhoffer et al. "Overview of the Neural Network Compression and Representation (NNR) Standard", IEEE Transactions on Circuits and Systems for Video Technology, pp. 1-14, July 2021, doi: 10.1109/TCSVT.2021.3095970, Open Access
- P. Haase et al. "Encoder Optimizations For The NNR Standard On Neural Network Compression", 2021 IEEE International Conference on Image Processing (ICIP), 2021, pp. 3522-3526, doi: 10.1109/ICIP42928.2021.9506655.
- K. Müller et al. "Ein internationaler KI-Standard zur Kompression Neuronaler Netze", FKT- Fachzeitschrift für Fernsehen, Film und Elektronische Medien, pp. 33-36, September 2021
- S. Wiedemann et al., "DeepCABAC: A universal compression algorithm for deep neural networks", in IEEE Journal of Selected Topics in Signal Processing, doi: 10.1109/JSTSP.2020.2969554.
License
Please see LICENSE.txt file for the terms of the use of the contents of this repository.
For more information and bug reports, please contact: nncodec@hhi.fraunhofer.de
Copyright (c) 2019-2025, Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. & The NNCodec Authors.
All rights reserved.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nncodec-2.1.1.tar.gz.
File metadata
- Download URL: nncodec-2.1.1.tar.gz
- Upload date:
- Size: 129.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c3bd7fa31ed0ee0e0196f7e2e7fa7c758fd88a7c9236c306f3e95dfabad61e21
|
|
| MD5 |
935950b121a4ff63ee7c12c933645dc5
|
|
| BLAKE2b-256 |
128baa1e2c066a4124dbabb63e72ca1fc97f5e864d884d96c3e33ef1223d65e3
|
File details
Details for the file nncodec-2.1.1-cp39-cp39-macosx_11_0_arm64.whl.
File metadata
- Download URL: nncodec-2.1.1-cp39-cp39-macosx_11_0_arm64.whl
- Upload date:
- Size: 360.1 kB
- Tags: CPython 3.9, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fde8d7ecae3af494a33405025957b45435e4775f456293fe9df83dc2bd1593d3
|
|
| MD5 |
7c325c3b3c10b06652750665629bd121
|
|
| BLAKE2b-256 |
e2fa22fae8eea6b61f191a33224129a0447d44313c656e924eeb1014951218db
|







