Simulates which strategy evolves when agents are connected with each others via social network

Project description
Norm Evolution in Social Networks
This library is used to understand which strategy can evolve as a potential norm when agents are connected with each other through a specific social network. Agents take actions based upon their interactions with other agents with some randomness in their actions. The strategy followed most frequently is a potential candidate for setting the norm.
How to use it?
# Install
pip install norm-evolution-network
# Import
from norm_evolution_network import simulation
# Execute
simulation.network_simulations(num_neighbors=4,
num_agents=23,
prob_edge_rewire=0.25,
grid_network_m=6,
grid_network_n=4,
name_len=7,
num_of_rounds=25,
num_of_trials=50,
fixed_agents_ratio=0.15,
perturb_ratio=0.05,
cutoff_norms=50,
network_name='small_world1',
random_seed=4578,
function_to_use='perturbed_response2',
iteration_name='test',
path_to_save_output='C:\\Users\\Downloads\\'
)
Function parameters
Following are the parameters which are required to be specified. At the end in the parenthesis, it shows the data type of the parameter which is required or the possible values which is required to be used.
- num_neighbors: Number of neighbours. (Integer)
- num_agents: Number of agents. (Integer)
- prob_edge_rewire: Probability of rewiring each edge. It"s a small world network parameter. We talk more about small world network in below section (Float)
- grid_network_m: Number of nodes. It"s a 2-dimensional grid network parameter. We talk more about grid network in below section (Integer)
- grid_network_n: Number of nodes. It"s a 2-dimensional grid network parameter. We talk more about grid network in below section (Integer)
- name_len: Length of random keywords created by the game. (Integer)
- num_of_rounds: Number of rounds. (Integer)
- num_of_trials: Number of trials. (Integer)
- fixed_agents_ratio: Percentage of agents assumed as fixed. (Float)
- perturb_ratio: Probability of agents taking action randomly. (Float)
- cutoff_norms: Minimum threshold for norm emergence. A number between 1 and 100. E.g., 50 implies the specific norm has been played at least 50% of times. (Integer)
- network_name: Specify one of these values from the list. ["small_world1","small_world2","small_world3","complete","random","grid2d"]. We talk more about what these values mean in the below section (String)
- random_seed: Random seed value. (Integer)
- function_to_use: Specify one of these values from the list ["perturbed_response1","perturbed_response2","perturbed_response3","perturbed_response4"]. We talk more about what these values mean in the below section. (String)
- iteration_name: Iteration name. (String)
- path_to_save_output: Path to save output files. (String)
In the "function_to_use" parameter above, below is the explanation for what these different values mean inside the list specified above.
- perturbed_response1: Agents select the best response (1-perturb_ratio)*100% times among the strategies which are most frequently used. If there is more than one such strategy, then agents select any one strategy randomly. Agents select random strategy (perturb_ratio)*100% times among the strategies which are not most frequently used. Here also, if there is more than one such strategy, then agents select any one strategy randomly out of these.
- perturbed_response2: Agent selects strategy randomly according to the relative weightage of different strategies. These relative weights are the % of times the respective strategy has been used by opponents in the past.
- perturbed_response3: This is same as "perturbed_response1" function except agent selects random strategy (perturb_ratio)*100% times from all the possible strategies and not only from the ones which were not used most frequently by their opponents.
- perturbed_response4: Agent selects the best response 100% of times among the strategies which are most frequently used. If there is more than one such strategy, then agents select any one strategy randomly. There is no perturbation element (perturb_ratio is considered as zero).
In the "network_name" parameter above, below is the explanation for what these different values mean inside the list specified above.
- small_world1: Returns a Watts Strogatz small-world graph. Here number of edges remained constant once we increase the prob_edge_rewire value. Shortcut edges if added would replace the existing ones. But total count of edges remained constant.
- small_world2: Returns a Newman Watts Strogatz small-world graph. Here number of edges increased once we increase the prob_edge_rewire value. It would add more shortcut edges in addition to what already exist.
- small_world3: Returns a connected Watts Strogatz small-world graph. Rest of the explanation remains as small_world1.
- complete: Returns the complete graph.
- random: Compute a random graph by swapping edges of a given graph. The given graph used is Watts Strogatz small-world graph (the one produced by "small_world1").
- grid2d: Return the 2d grid graph of mxn nodes, each connected to its nearest neighbors.
We have used the networkx python library to populate these graphs. For more information around these graphs and how these are produced please refer to the link in the reference section.
Function explanation
Here we explain the underlying functioning of this library with the help of an example. But the logic can be replicated to any coordination game where there is a positive reward if agents follow the same strategy as their neighbour/opponent, and zero/negative reward if agents follow different strategy.
We assume agents play naming game as defined in Young (2015). Naming game is a coordination game wherein two agents are shown a picture of a face and they simultaneously and independently suggest names for it. If agents provide same name, they earn a positive reward and if they provide different names, they pay a small penalty (negative reward). There is no restriction on the names that agents can provide, this is left to their imagination. Agents do not know with whom they are paired or their identities. Agents can recollect the names provided by their partners in previous rounds.
We assume a ring network with 24 agents (num_agents). Each agent is connected with 4 agents (num_neighbors) in the neighbourhood. We assume that the positive reward and negative reward are constant values. The network looks like as in below figure. For instance, agent 0 relates to 4 agents, agent 1,2,23 and 22. Similarly, agent 5 is connected with agents 6,7,4 and 3. We assume the network to be undirected.
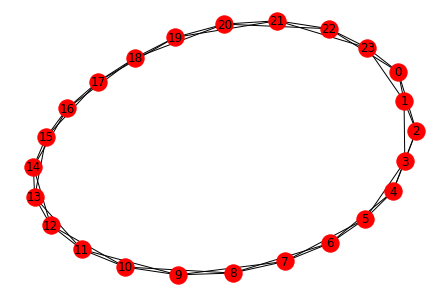
We start the game assuming that each edge of the network is selected at random. Edge of the network is represented as (0,1), (5,4) etc, implying agents 0 and 1 are connected with each other, agents 5 and 4 are connected with each other. These pairs or edges are selected randomly from the possible pool of edges. During each round, one of the edges is selected at random and the agents associated with those edges play the game.
To begin with, agents do not have history to look back into, hence agents propose names randomly. Agents do not know the identity of the other agents with whom they are being paired. At the end of a given round, agents do know the names proposed by other agents. Once agents have history of names proposed by other agents, they take into consideration the names proposed by their opponents in the next successive rounds. This way agents get to know the names which are popular among the agents.
We assume name to be any string of length name_len, a combination of alpha and numeric characters generated randomly. Agents keep track of names proposed by other agents and accordingly update their actions in the successive rounds of play. We assume agents have bounded rationality and engaged in limited calculations to decide upon what action to take.
We have considered different combinations of strategies that agents can adopt while taking actions. We assume that agents use perturbed best response implying agents can take action randomly with a certain probability (Young, 2015). At each time when agents require to take action, they look at the names proposed in the past by their opponents and decide what name to propose in the current period. We have tested four different ways which agents can use to decide what action to take. The "function_to_use" parameter provides details about these and how these are different to each other.
When the simulations are run for 'num_of_rounds' rounds and 'num_of_trials' trials, we get the percentage distribution of different names (strategies) which agents proposed. The names which have been proposed the most are potential candidates for norm. We can see the output like below.
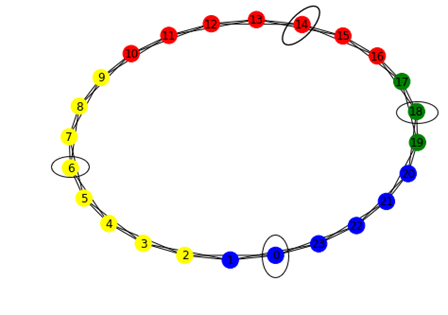
In above figure, agents 17, 18 and 19 proposed same name majority of the times, hence these are coloured in same color (green). Color itself has no significance here, it is used to demonstrate which agents taking same action. Same color agents taking same action majority of the times. The agents encircled demonstrates which agent proposed that name first. The detailed explanation of the output generated is provided in the next section.
How to interpret output?
There are total 12 files generated in the output.
agent_norm_trail_round_test_2022-06-29-11-21-16.xlsx
aggregate_data_consolidated_test_2022-06-29-11-21-16.xlsx
aggregate_data_detailed_test_2022-06-29-11-21-16.xlsx
aggregate_norm_trail_round_test_2022-06-29-11-21-16.xlsx
fixedagents_data_detailed_test_2022-06-29-11-21-16.xlsx
parameters_test_2022-06-29-11-21-16.xlsx
agent_distribution_test_2022-06-29-11-21-16.xlsx
agent_pairs_distribution_test_2022-06-29-11-21-16.xlsx
firstagent_test_2022-06-29-11-21-16.xlsx
opponentagent_distribution_test_2022-06-29-11-21-16.xlsx
normsgraph_test_2022-06-29-11-21-16.png
agent_mostfrequent_percentshare_test_2022-06-29-11-21-16.txt
The image file (.png) is the network graph which is being considered for the simulation. The nodes in the png file follow the logic specified in "agent_mostfrequent_percentshare_.....txt" file. This text file contains the information on the most frequent strategy used by agents and the % of times it was used. Agents following the same strategy most frequently, they would be coloured in the same colour in the png file.
Parameters file "parameters_.." lists all the parameters which have been specified in the function call.
File "aggregate_data_consolidated_.." has the percentage frequency distribution of all the strategies that have been used during the simulation run. File "aggregate_data_detailed_.." gives detailed information on how this was achieved by giving agents information by each trail and round. File "aggregate_norm_trail_.." provides information on trial and round for the specific strategy which has met the cut off ('cutoff_norms') for calling it as a norm. This is the trail and round when the specific strategy has first met the cut off specified at the aggregate level (irrespective of which agent has proposed that strategy). On the other hand, "agent_norm_trail_round_..." provides this information at the agent level. This gives information on if a specific agent individually has proposed that name at least 'cutoff_norms' % of times in the entire simulation run and if yes, what is that round and trail.
Distribution file "agent_distribution_test_..." shows how many % of times the agent has come in the simulations tried. Similarly, "opponentagent_distribution_test_..." provides this information for the opponent agent. File "agents_pairs_distribution_.." provides information at the pair level (agent, opponent agent).
File "firstagent_..." provides information on which agent proposed the name first which are the candidates for potential norm. File "fixedagents_data_detailed_..." provides information on the agents which are assumed to be fixed as per 'fixed_agents_ratio' specified. Fixed agents follow the same strategy irrespective of what other agents follow. This file also provides information on when they used that strategy for the first time (trail and round details)
References
- Young, H.P. "The evolution of social norms" Annual Review of Economics. 2015 (7),pp.359-387
- https://pypi.org/project/networkx/
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file norm-evolution-network-0.3.tar.gz.
File metadata
- Download URL: norm-evolution-network-0.3.tar.gz
- Upload date:
- Size: 13.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.7.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8bb9788dbe75861b385419d3a3eaf9fbbe8c224dd0b12078fa5aaf45bb78f3c2
|
|
| MD5 |
85d40fe6314bcd3dddece4a70a916089
|
|
| BLAKE2b-256 |
5c44bf6cecc0582e6d01a3d963c2eb19be1e8adefc4119d25fceec1d872f38f1
|







