This blueprint serves as a reference solution for a foundational Retrieval Augmented Generation (RAG) pipeline.

Project description
NVIDIA RAG Blueprint
Retrieval-Augmented Generation (RAG) combines the reasoning power of large language models (LLMs) with real-time retrieval from trusted data sources. It grounds AI responses in enterprise knowledge, reducing hallucinations and ensuring accuracy, compliance, and freshness.
Overview
The NVIDIA RAG Blueprint is a reference solution and foundational starting point for building Retrieval-Augmented Generation (RAG) pipelines with NVIDIA NIM microservices. It enables enterprises to deliver natural language question answering grounded in their own data, while meeting governance, latency, and scalability requirements. Designed to be decomposable and configurable, the blueprint integrates GPU-accelerated components with NeMo Retriever models, Multimodal and Vision Language Models, and guardrailing services, to provide an enterprise-ready framework. With a pre-built reference UI, open-source code, and multiple deployment options — including local docker (with and without NVIDIA Hosted endpoints) and Kubernetes — it serves as a flexible starting point that developers can adapt and extend to their specific needs.
For complex, multi-hop, or ambiguous questions, Agentic RAG adds a LangGraph plan-and-execute pipeline alongside the standard retrieve-then-generate chain — with scope discovery, parallel sub-tasks, synthesis, optional verification, and streaming stage events in the UI and API.
Key Features
Agentic RAG
- LangGraph plan-and-execute pipeline for multi-hop, ambiguous, and cross-document queries
- Scope discovery, parallel task execution, synthesis, and optional verification
- Enable per request (
agentic: trueon/v1/generate) or deployment-wide (ENABLE_AGENTIC_RAG); select Pipeline → Agentic in the reference UI - Streaming stage events and reasoning traces — see Agentic RAG documentation
Data Ingestion
- Multimodal content extraction - Documents with text, tables, charts, infographics, and audio. For the full list of supported file types, see NeMo Retriever Extraction Overview.
- Custom metadata support
Search and Retrieval
- Agentic RAG pipeline — plan-and-execute retrieval with scope discovery, parallel sub-task search, retries, and optional verification for multi-hop and cross-document queries
- Multi-collection searchability
- Hybrid search with dense and sparse search
- Reranking to further improve accuracy
- GPU-accelerated Index creation and search
- Pluggable vector database
Query Processing
- Query decomposition
- Dynamic filter expression creation
Generation and Enrichment
- Opt-in for Multimodal and Vision Language Model Support in the answer generation pipeline.
- Document summarization with multiple strategies, flexible page filtering, and real-time progress tracking
- Improve accuracy with optional reflection
- Optional programmable guardrails for content safety
Evaluation
- Evaluation scripts (RAGAS framework)
User Experience
- Sample user interface
- Multi-turn conversations
- Multi-session support
Deployment and Operations
- Telemetry and observability
- Decomposable and customizable
- NIM Operator support
- Python library mode support
- OpenAI-compatible APIs
Software Components
The RAG blueprint is built from the following complementary categories of software:
-
NVIDIA NIM microservices – Deliver the core AI functionality. Large-scale inference (e.g. for example, Nemotron LLM models for response generation), retrieval and reranking models, and specialized extractors for text, tables, charts, and graphics. Optional NIMs extend these capabilities with OCR, content safety, topic control, and multimodal embeddings.
-
The integration and orchestration layer – Acts as the glue that binds the system into a complete solution.
This modular design ensures efficient query processing, accurate retrieval of information, and easy customization.
NVIDIA NIM Microservices
-
Response Generation (Inference)
-
Retriever and Extraction Models
-
Optional NIMs
Integration and Orchestration Layer
-
RAG Orchestrator Server – Coordinates interactions between the user, retrievers, vector database, and inference models, ensuring multi-turn and context-aware query handling. This is LangChain-based.
-
Vector Database (accelerated with NVIDIA cuVS) – Stores and searches embeddings at scale with GPU-accelerated indexing and retrieval for low-latency performance. The default is Elasticsearch. Another alternative is Milvus (GPU-accelerated).
-
NeMo Retriever Extraction – A high-performance ingestion microservice for parsing multimodal content. For more information about the ingestion pipeline, see NeMo Retriever Extraction Overview.
-
RAG User Interface (rag-frontend) – A lightweight user interface that demonstrates end-to-end query, retrieval, and response workflows for developers and end users. For more information, see the RAG UI documentation.
Technical Diagram
The following image represents the architecture and workflow.
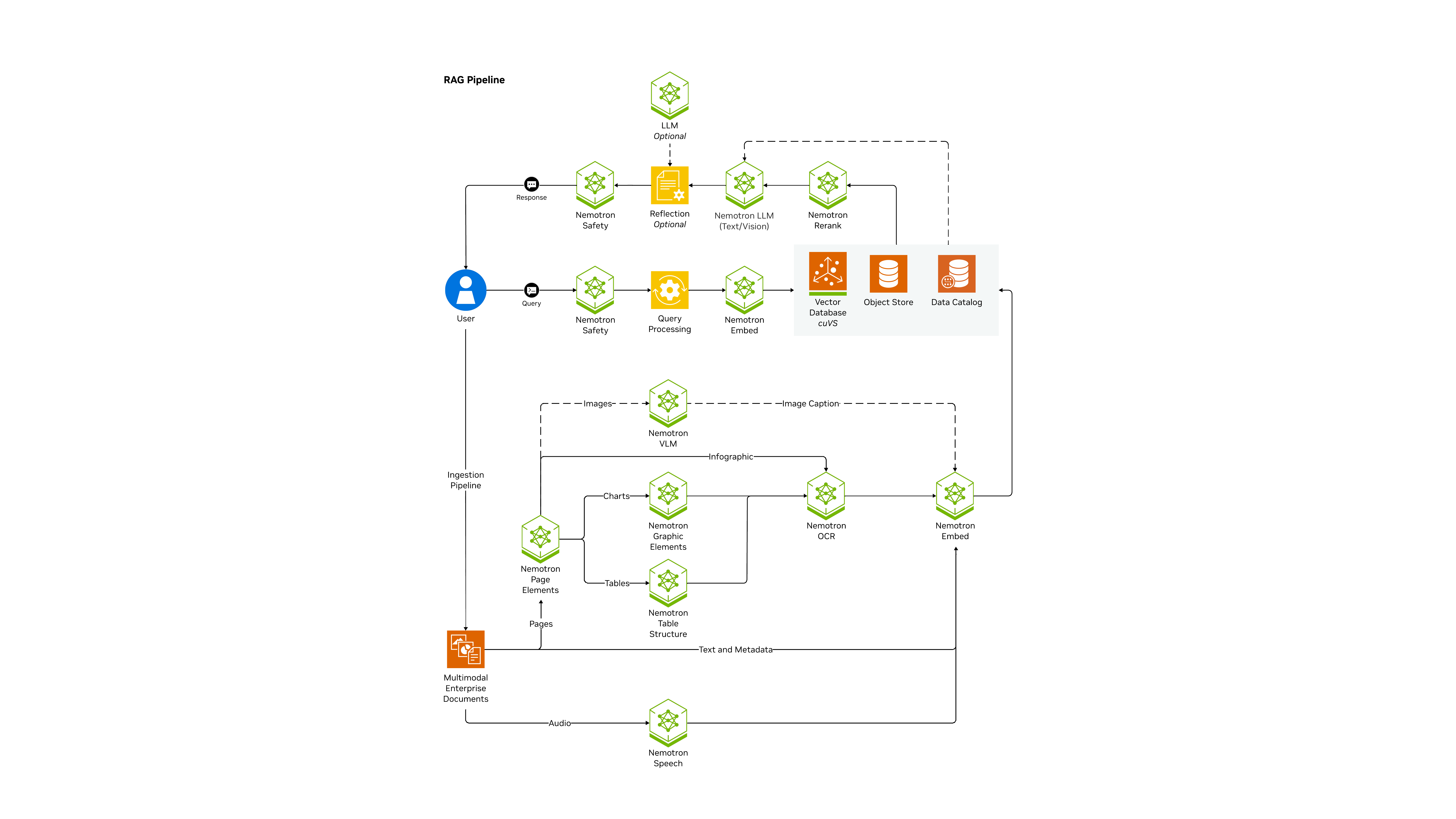
Workflow
The following is a step-by-step explanation of the workflow from the end-user perspective:
-
Data Ingestion & Extraction Pipeline – Multimodal enterprise documents (text, images, tables, charts, infographics, and audio) are ingested.
-
User Query – The user interacts with the system through the UI or APIs, submitting a question. An optional NeMo Guardrails module can filter or reshape the query for safety and compliance before it enters the retrieval pipeline.
-
Query Processing – The query is processed by the Query Processing service, which may also leverage reflection (an optional LLM step) to improve query understanding or reformulation for better retrieval results.
-
Retrieval from Enterprise Data – The processed query is converted into embeddings using NeMo Retriever Embedding and matched against enterprise data stored in a cuVS accelerated Vector Database (cuVS) and associated S3-compatible object store. Relevant results are identified based on similarity.
-
Reranking for Precision – An optional NeMo Retriever Reranker reorders the retrieved passages, ensuring the most relevant chunks are selected to ground the response.
-
Response Generation – The selected context is passed into the LLM inference service (for example, Llama Nemotron models). An optional reflection step can further validate or refine the answer against the retrieved context. Guardrails may also be applied to enforce safety before delivery.
-
User Response – The generated, grounded response is sent back to the user interface, often with citations to retrieved documents for transparency.
Get Started With NVIDIA RAG Blueprint
The recommended way to get started with this Python package is to refer to the RAG library usage notebook.
Refer to the full documentation to learn about the following:
- Agentic RAG — plan-and-execute pipeline, API and UI usage, configuration, and limitations
- Minimum Requirements
- Deployment Options
- Configuration Settings
- Common Customizations
- Available Notebooks
- Troubleshooting
- Additional Resources
The full blueprint also supports Docker Compose, Kubernetes, and Red Hat OpenShift deployments. For deployment details, see the NVIDIA RAG Blueprint documentation.
Blog Posts
- NVIDIA NeMo Retriever Delivers Accurate Multimodal PDF Data Extraction 15x Faster
- Finding the Best Chunking Strategy for Accurate AI Responses
Inviting the Community to Contribute
We're posting these examples on GitHub to support the NVIDIA LLM community and facilitate feedback. We invite contributions! To open a GitHub issue or pull request, see the contributing guidelines.
License
This NVIDIA AI BLUEPRINT is licensed under the Apache License, Version 2.0.. This project will download and install additional third-party open source software projects and containers. Review the license terms of these open source projects before use.
Use of the models in this blueprint is governed by the NVIDIA AI Foundation Models Community License.
Terms of Use
This blueprint is governed by the NVIDIA Agreements | Enterprise Software | NVIDIA Software License Agreement and the NVIDIA Agreements | Enterprise Software | Product Specific Terms for AI Product. The models are governed by the NVIDIA Agreements | Enterprise Software | NVIDIA Community Model License and the NVIDIA RAG dataset is governed by the NVIDIA Asset License Agreement. The following models that are built with Llama are governed by the Llama 3.2 Community License Agreement: nvidia/llama-nemotron-embed-1b-v2, nvidia/llama-nemotron-rerank-1b-v2, and nvidia/llama-nemotron-embed-vl-1b-v2.
Additional Information
The Llama 3.1 Community License Agreement applies to the llama-3.1-nemoguard-8b-content-safety and llama-3.1-nemoguard-8b-topic-control models. The Llama 3.2 Community License Agreement applies to the nvidia/llama-nemotron-embed-1b-v2, nvidia/llama-nemotron-rerank-1b-v2, and nvidia/llama-nemotron-embed-vl-1b-v2 models. Built with Llama. Apache 2.0 applies to NVIDIA Ingest and to the nemotron-page-elements-v3, nemotron-table-structure-v1, nemotron-graphic-elements-v1, nemotron-parse, paddleocr, and nemotron-ocr-v1 models.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nvidia_rag-2.6.0-py3-none-any.whl.
File metadata
- Download URL: nvidia_rag-2.6.0-py3-none-any.whl
- Upload date:
- Size: 404.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ccf0414cfe92110c257967a065b17079d058e788a45da400976dfadfbb89bd5c
|
|
| MD5 |
dd100e44e11eb5b80d75ac6a5522f0da
|
|
| BLAKE2b-256 |
94faf6916027ff775f76c633f4f6630875b4640c2fc73f7ab07c054b20186ff6
|







