Open Book Genome Project

Project description
Welcome to the Open Book Genome Project (OBGP) Sequencer™, an open-source Book Processing Pipeline of responsibly vetted community "modules" which classify, sequence, and fingerprint book fulltext to reveal public insights about Books.
Quickstart
Want to get started immediately?
Try the OBGP Sequencer™ Google Colab Notebook:
How it Works
Each month, the OBGP Sequencer™ gets run against the fulltext of more than 1M books, generating valuable public insights for book lovers and researchers around the globe. OBGP Sequencer™ consists of carefully vetted community-contributed modules which aim to responsibly help increase the discoverability and usefulness of books, e.g.:
- Identifying urls, isbns, and citations within the text
- Generating word frequency mappings
- Guessing grade reading levels
Who we are
OBGP is an independent, community-run, not-for-profit committee of open-source and book enthusiasts who want to responsibly further the effort of making books as useful and accessible as possible.
Installation
Production
If you want to run the OBGP Sequencer™ pipeline, run:
pip install obgp
Local Development
git clone https://github.com/Open-Book-Genome-Project/sequencer.git # get the code
virtualenv venv && source venv/bin/activate # setup a virtual environment
cd sequencer # change into project directory
pip install -e . # install the library (and re-run in project root as you make changes)
Docker Usage
First, create a directory called obgp_dir if it doesn't already exist.
mkdir -p obgp_dir
Next, while in the sequencer directory, run:
export OBGP_S3=~/.config/ia.ini OBGP_DIR=./obgp_dir;docker-compose up
Use docker container ls to get container ID.
Then docker exec -it obgp /bin/sh replacing the container ID with the actual ID
You should now be in the container shell and can execute commands!
Usage
Once you've install either the production code or build your developer code, you may proceed to start python and import the runner.pipeline with whatever modules you'd like.
Let's say you want to process the book https://archive.org/details/hpmor which has identifier hpmor on Archive.org. First, you would define your Sequencer as follows:
from bgp import Sequencer, STOP_WORDS
from bgp.modules.terms import NGramProcessor, WordFreqModule
s = Sequencer({
'words': NGramProcessor(modules={
'term_freq': WordFreqModule()
}, n=1, stop_words=STOP_WORDS)
})
Then, you would pass this book identifier into the Sequencer to sequence the book to get back a genome Sequence object:
genome = s.sequence('hpmor')
genome.results
Saving & Uploading Results
If your internetarchive tool is configured against an account with sufficient permissions, you can then upload your genome results back to an Archive.org item (we'll arbitrarily pick the identifier bgp) by running:
>>> genome.write_results_to_item('bgp')
This will upload the genome.results as json to <book_identifier>_results.json (e.g. hpmor_results.json) unless otherwise specified by overriding params.
You will then be able to see your file hpmor_results.json within the bgp item's file downloads: https://archive.org/download/bgp
If you want to run a default test to make sure everything works, try:
from bgp import DEFAULT_SEQUENCER
genome = DEFAULT_SEQUENCER.sequence('9780262517638OpenAccess')
genome.results
Using pipeline.py
This pipeline allows a user to sequence a list of books from a jsonl in the following format:
{"identifier": "samplebook"}
{"identifier": "9780262517638OpenAccess"}
The pipeline then automatically chooses the most probable isbn for the book and attempts to update ia metadata accordingly while keeping a filesystem based database of all these actions.
| Record | Filesystem Action |
|---|---|
| How do we determine which books we've successfully uploaded a genome | Touches GENOME_UPDATED_{identifier} |
| How do we determine the ISBNs of all books we’ve sequenced so far | Touches ISBN_1234567890_{identifier} |
| How do we determine which books were sequenced but had no ISBN | Touches UPDATE_NONE_{identifier} |
| How do we know which books attempted updating but failed | UPDATE_FAILED_{identifier} |
| How do we know which books succeeded at updating and succeed | UPDATE_SUCCEED_{identifier} |
| How do we know if item already has isbn metadata and is skipped | UPDATE_CONFLICT_{identifier} |
| How do we know how many new urls were found in a book | URLS_{number_of_urls}_{identifier} |
The user can can grep and pipe to wc -l which tells them how many for each status and lists those items
Example Usage
Here is a archive item with the identifier samplebook. It has an isbn in the text of the book but no isbn metadata.
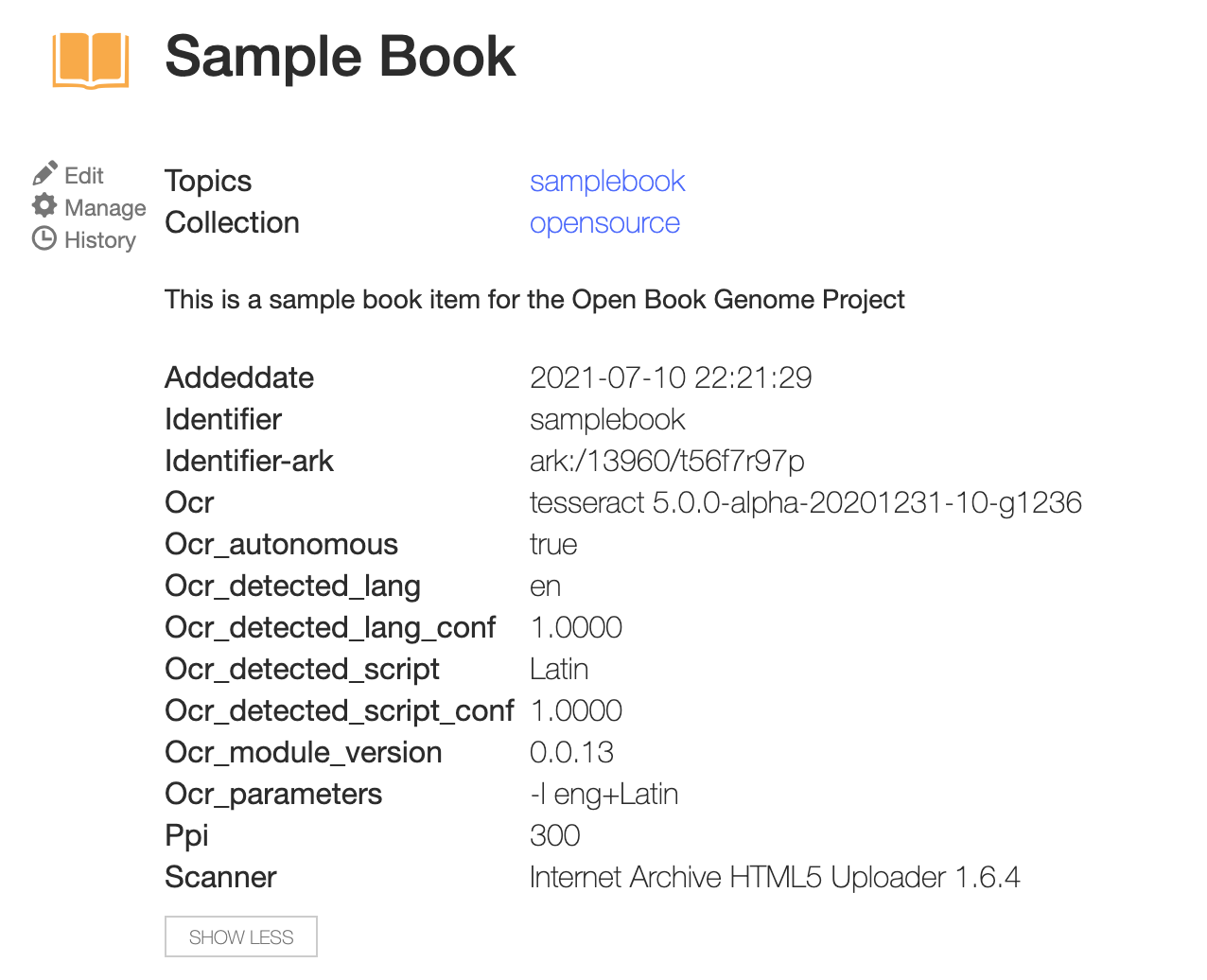
There is a jsonl file with the items to be sequenced listed on new lines.
{"identifier": "samplebook"}
{"identifier": "9780262517638OpenAccess"}
To use the pipeline, run python pipeline.py samplebook.jsonl
You can specify the amount of pipeline processes to run concurrently with --p {number of processes} as a parameter. For example: python pipeline.py --p 4 samplebook.jsonl
If we tree results/bgp_results now we get:
results/bgp_results
├── 9780262517638OpenAccess
│ ├── ISBN_9780262517638_9780262517638OpenAccess
│ ├── UPDATE_CONFLICT_9780262517638OpenAccess
│ ├── URLS_290_9780262517638OpenAccess
│ └── book_genome.json
└── samplebook
├── ISBN_0787959529_samplebook
├── UPDATE_SUCCEED_samplebook
├── URLS_0_samplebook
└── book_genome.json
2 directories, 8 files
If we check the metadata for the book on archive.org again we can see that the isbn field has been updated.
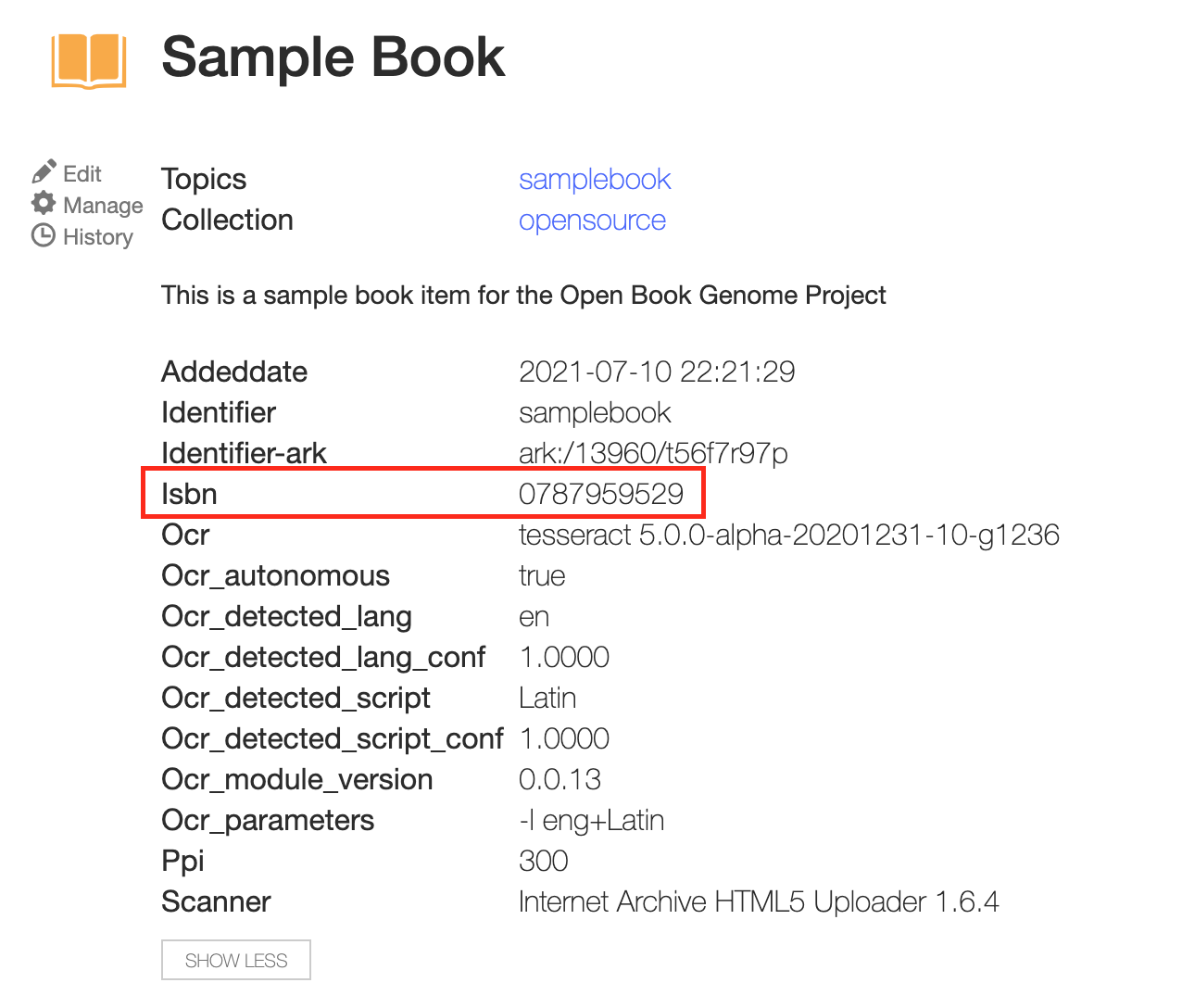
There is also a file generated named URLS_0_samplebook which indicates that 0 non 'archive.org' were extracted.
In the case of another item like 9780262517638OpenAccess, the filename indicates that 290 new urls were extracted. If we look at the contents of that file we will see all the unique urls extracted separated by newlines.
http://blogs.law.harvard.edu/pamphlet/2009/05/29/what-percentage
http://www.sherpa.ac.uk/romeo
http://www.library.yale.edu/~llicense/listarchives/0405/msg00038
http://dash.harvard.edu/bitstream/handle/l/4552050/suber_nofee
http://dx.doi.org/10.1371/journal.pone.0013636
http://doctorrw.blogspot.com/2007/05/tabloid-based-medicine
... etc.
The 9780262517638OpenAccess directory also shows that a url was extracted with the ISBN_9780262517638_9780262517638OpenAccess record, but was the ia item was not updated because a isbn already existed with the UPDATE_CONFLICT_9780262517638OpenAccess
Contributing a Module
- Please read the whitepaper and look through our community list of proposed or requested modules
- Propose a "module" by creating a github issue
- Get the code: Fork this git repository and clone it to your workspace. Create a new branch for your module (named after its corresponding github issue number and title: e.g.
git checkout -b 12/module/find-isbns). Install - Create a new module to the
modules/directory - Test your module locally using Internet Archive's unrestricted collection of ~800k books
- open a Pull Request so your contribution may be reviewed.
Technical Overview
- Book Genome Project extends/overloads @jjjake's
internetarchivetool (invisibly using bad practices) in bgp/init.py with functions to fetch xml / plaintext (in a smart, memoized way) - Programmer builds a Sequencer (which is a list) of Sequences (a Sequence essentially does 1-pass on the data). Currently, the only sequences we have are 1gram and 2gram and these could be done in a single pass.
- Each Sequence specified a list of modules to get run as it steps
- The result is the top-level Sequencer can print out its
.resultsas a dict
Sequencers, Processors & Modules
A Sequencer tells the Book Genome Project what tasks should be run and what results should be derived when processing a book's genome.
When a OGBP Sequencer is defined, it is loaded with a list of Processors, and these Processors with Modules.
A Processor is an abstraction which is responsible for fetching a specific representation of a Book (e.g. plaintext, xml, abbyy), splitting it into predefined logical units (e.g. characters, words, sentences, paragraphs, pages, chapters, entire text), stepping over each of these logical units, and sending them to it's registered Modules.
One example hypothetrical Processor might be called XMLSentenceProcessor. This Processor may be responsible for fetching (i.e. downloading) a Book in XML format with word-level markup. The run() method of the Processor's interface might parse and split the structured XML data into sentences, iterate through each sentence, and forward them to each of its registered Modules for processing. This hypothetical SentenceProcessor might be loaded with several Modules, such as a TotalSentenceCountModule and an SentenceWordCountStatsModule which, respectively, keeps track of the total number of sentences within the book and calculates the average number of words per sentence, etc.
In many cases a developer may find that the package's out-of-the-box bgp.DEFAULT_SEQUENCER is a great place to start, either as a Sequencer to run or a good example for extending.
Genome Schema
This is the reference schema used in genome json files:
{
"metadata": {
"identifier": "(ia identifier)",
"version": "(commit)",
"timestamp": "r(Unix Epoch)",
"sequence_time": "r(sequence process seconds)",
"source": {
"txt": {
"time": "r(txt download seconds)",
"bytes": "r(txt bytes)"
},
"xml": {
"time": "r(xml download seconds)",
"bytes": "r(xml bytes)"
}
},
"processors": {
"1gram": {
"tokenization_time": "r(1gram tokenization process seconds)",
"total_tokens": "r(1gram count)",
"total_time": "r(1gram processor process seconds)",
"modules": {
"urls": {
"time": "r(url process seconds)"
},
"1grams": {
"time": "r(1gram frequency process seconds)"
}
}
},
"2gram": {
"tokenization_time": "r(2gram tokenization process seconds)",
"total_tokens": "r(2gram count)",
"total_time": "r(2gram processor process seconds)",
"modules": {
"2grams": {
"time": "r(2gram frequency process seconds)"
}
}
},
"fulltext": {
"total_time": "r(fulltext processor process seconds)",
"modules": {
"readinglevel": {
"time": "r(reading level process seconds)"
}
}
},
"pagetypes": {
"total_time": "r(pagetype processor process seconds)",
"modules": {
"copyright_page": {
"time": "r(copyright page process seconds)"
},
"backpage_isbn": {
"time": "r(copyright page process seconds)"
}
}
}
}
},
"urls": [
"(url)"
],
"1grams": [
[
"(1gram)",
"r(1gram frequency)"
]
],
"2grams": [
[
"(2gram)",
"r(2gram frequency)"
]
],
"readinglevel": {
"readability": {
"flesch_kincaid_score": "r(flesch kincaid score)",
"smog_score": "r(smog score)"
},
"lexile": {
"min_age": "(Lower age in range)",
"max_age": "(Upper age in range)"
}
},
"copyright_page": [
{
"page": "(copyright page)",
"isbns": [
"(isbn)"
]
}
],
"backpage_isbn": [
"(isbn)"
]
}
Public Testing Data sets
Here's a corpus of ~800k Archive.org item identifiers of public domain books (of varying quality/appearance/language) which may be used for testing your module:
Questions?
Please open an issue and request a slack invite
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file obgp-0.0.42-py2.py3-none-any.whl.
File metadata
- Download URL: obgp-0.0.42-py2.py3-none-any.whl
- Upload date:
- Size: 15.2 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f436f1ab49d06b2926f61a9e2f9f72d1a2241ea95fcf35d3105a34dabeae64aa
|
|
| MD5 |
3c4d00567204acf2f12971619929a59b
|
|
| BLAKE2b-256 |
0af2a68a611f2e8b738da4bbb9315a9d460201615caab270ad74860740b4efde
|







