Extract skills from job ads and maps them onto a skills taxonomy of your choice.


Project description
Skills Extractor
Welcome to Nesta's Skills Extractor Library
Welcome to the documentation of Nesta's skills extractor library.
This page contains information on how to install and use Nesta's skills extraction library. The skills library allows you to extract skills phrases from job advertisement texts and maps them onto a skills taxonomy of your choice.

We currently support three different taxonomies to map onto: the European Commission’s European Skills, Competences, and Occupations (ESCO), Lightcast’s Open Skills and a “toy” taxonomy developed internally for the purpose of testing.
If you'd like to learn more about the models used in the library, please refer to the model card page.
Installation
You can use pip to install the library:
pip install ojd-daps-skills
You will also need to download spaCy's en_core_web_sm model:
python -m spacy download en_core_web_sm
AWS CLI
When the package is first used it will automatically download a folder of neccessary data and models. This file is ~ 1GB. Although you don't need to have AWS credentials for this to work, you will need to download the AWS CLI.
TL;DR: Using Nesta's Skills Extractor library
The library supports three key skills extraction functionalities :
- Extract AND map skills to a taxonomy of your choice;
- Extract skills from job adverts;
- Map a list of skills to a taxonomy of your choice.
The option local=False can only be used by those with access to Nesta's S3 bucket.
1. Extract AND map skills
If you would like to extract AND map skills in one step, you are able to do so with the extract_skills method.
from ojd_daps_skills.pipeline.extract_skills.extract_skills import ExtractSkills #import the module
es = ExtractSkills(config_name="extract_skills_toy", local=True) #instantiate with toy taxonomy configuration file
es.load() #load necessary models
job_adverts = [
"The job involves communication skills and maths skills",
"The job involves Excel skills. You will also need good presentation skills"
] #toy job advert examples
job_skills_matched = es.extract_skills(job_adverts) #match and extract skills to toy taxonomy
The outputs are as follows:
job_skills_matched
>>> [{'SKILL': [('communication skills', ('communication, collaboration and creativity', 'S1')), ('maths skills', ('working with computers', 'S5'))]}, {'SKILL': [('Excel skills', ('working with computers', 'S5')), ('presentation skills', ('communication, collaboration and creativity', 'S1'))]}]
2. Extract skills
You can simply extract skills from a job advert or list of job adverts:
from ojd_daps_skills.pipeline.extract_skills.extract_skills import ExtractSkills #import the module
es = ExtractSkills(config_name="extract_skills_toy", local=True) #instantiate with toy taxonomy configuration file
es.load() #load necessary models
job_adverts = [
"The job involves communication skills and maths skills",
"The job involves Excel skills. You will also need good presentation skills"
] #toy job advert examples
predicted_skills = es.get_skills(job_adverts) #extract skills from list of job adverts
The outputs are as follows:
predicted_skills
[{'EXPERIENCE': [], 'SKILL': ['communication skills', 'maths skills'], 'MULTISKILL': []}, {'EXPERIENCE': [], 'SKILL': ['Excel skills', 'presentation skills'], 'MULTISKILL': []}]
3. Map skills
You can map either the predicted_skills output from get_stills or simply map a list of skills to a taxonomy of your choice. In this instance, we map a list of skills:
from ojd_daps_skills.pipeline.extract_skills.extract_skills import ExtractSkills #import the module
es = ExtractSkills(config_name="extract_skills_toy", local=True) #instantiate with toy taxonomy configuration file
es.load() #load necessary models
skills_list = [
"Communication",
"Excel skills",
"working with computers"
] #list of skills (and/or multiskills) to be matched
skills_list_matched = es.map_skills(skills_list) #match formatted skills to toy taxonomy
The outputs are as follows:
skills_list_matched
>>> [{'SKILL': [('Excel skills', ('working with computers', 'S5')), ('Communication', ('use communication techniques', 'cdef')), ('working with computers', ('communication, collaboration and creativity', 'S1'))]}]
App
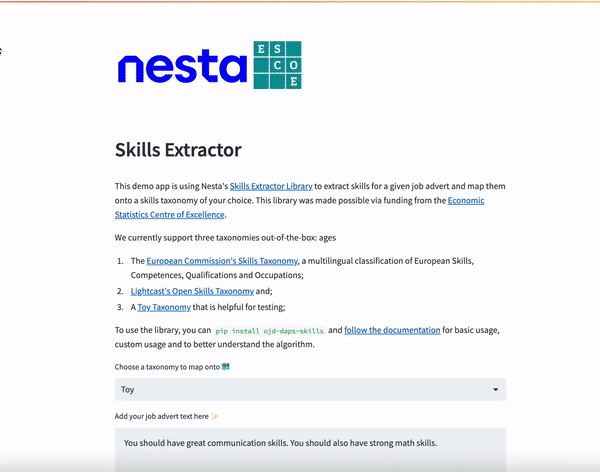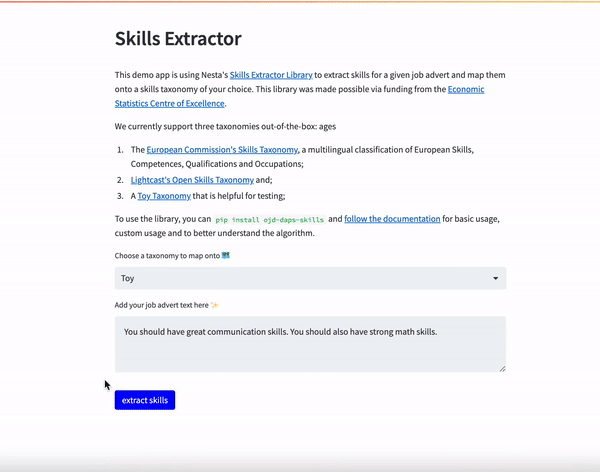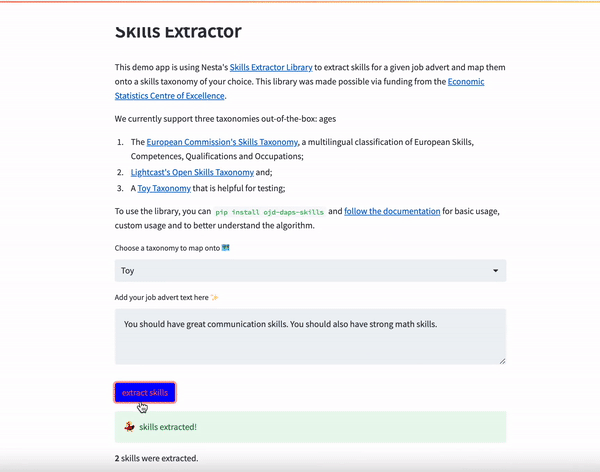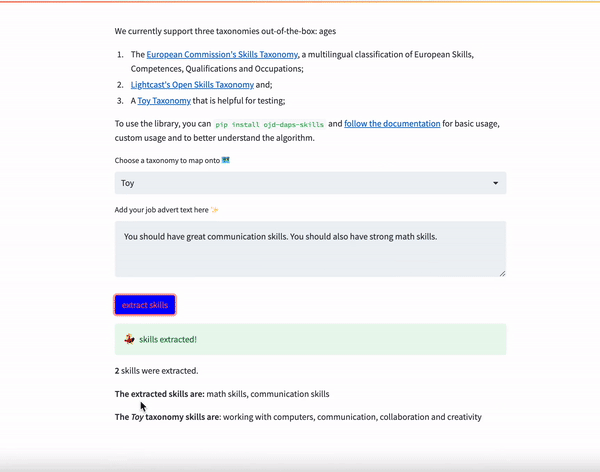
If you would like to demo the library using a front end, we have also built a streamlit app that allows you to extract skills for a given text. The app allows you to paste a job advert of your choice, extract and map skills onto any of the configurations: extract_skills_toy, extract_skills_lightcast and extract_skills_esco.
Development
If you'd like to modify or develop the source code you can clone it by first running:
git clone git@github.com:nestauk/ojd_daps_skills.git
Setup
- Meet the data science cookiecutter requirements, in brief:
- Install:
direnvandconda
- Install:
- Create a blank cookiecutter conda log file:
mkdir .cookiecutter/statetouch .cookiecutter/state/conda-create.log
- Run
make installto configure the development environment - Download spacy model:
python -m spacy download en_core_web_sm
If you don't have the AWS CLI installed - you can download a zipped folder of the data by clicking here. After downloading and unzipping, it is important that this folder is moved to the project's parent folder - i.e. ojd_daps_skills/.
Project structure
The project is split into three core pipeline folders:
- skill_ner - Training a Named Entity Recognition (NER) model to extract skills from job adverts.
- skill_ner_mapping - Matching skills to an existing skills taxonomy using semantic similarity.
- extract_skills - User friendly functionality to extract and map skills from job adverts.
Much more about these steps can be found in each of the pipeline folder READMEs.


Testing
Some functions have tests, these can be checked by running
pytest
Analysis
Various pieces of analysis are done in the analysis folder. These require access to various datasets from Nesta's private S3 bucket and are therefore only designed for internal Nesta use.
Contributor guidelines
The technical and working style guidelines can be found here.
This project was made possible via funding from the Economic Statistics Centre of Excellence
Project template is based on Nesta's data science project template (Read the docs here).


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ojd_daps_skills-1.0.1.tar.gz.
File metadata
- Download URL: ojd_daps_skills-1.0.1.tar.gz
- Upload date:
- Size: 49.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f191017dd66bbee1d9afaf6ab5e654708fb9d95bd3217f27e92b865f3acb6e5d
|
|
| MD5 |
4fca9ee6c0c26c72af45377848b39177
|
|
| BLAKE2b-256 |
893d9d310a831fb51c524c9f0d3012eff0bec994563b90e4e294ec527f08aa31
|
File details
Details for the file ojd_daps_skills-1.0.1-py3-none-any.whl.
File metadata
- Download URL: ojd_daps_skills-1.0.1-py3-none-any.whl
- Upload date:
- Size: 60.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
23adac82f8a82870f91ff14cf163a7fe712e4dd74e4a96e5a4399656a1feddff
|
|
| MD5 |
5a4bf16e804818cb04a3930da69cc0a3
|
|
| BLAKE2b-256 |
607d9ec12cea19795e7e194c9d1ea1cd98d516fcb1e401bfd7e41b607affc7a8
|







