Real-time digital human framework with FlashTalk 14B inference


Project description
OpenTalking
面向实时对话的开源数字人产线:LLM、TTS、WebRTC、角色音色与可插拔模型后端






快速开始 · 部署路线 · 模型支持 · Roadmap · 架构 · 文档与社区 · 致谢
项目简介
OpenTalking 是一个开源实时数字人对话编排框架,目标是构建 数字人对话产品 的核心链路:前端交互、会话状态、LLM 回复、TTS/音色选择、打断控制、字幕事件、WebRTC 音视频播放,以及本地或远端模型服务调用。
OpenTalking 专注 数字人产线编排,可以根据不同层级的需求,快速构建属于你的数字人:
- 快速体验:
mock / 无驱动模式,适合第一次打通 API、TTS、WebRTC 全链路,但缺少视频推理渲染。 - 轻量单机部署:面向消费级 GPU 单机,提供快速接入
Wav2Lip/MuseTalk/QuickTalk能力,具备视频渲染效果。 - 高质量部署:通过 OmniRT 接入
FlashTalk等高质量模型,面向多卡和分布式推理部署,提供更佳使用体验。
更多文档:
- 在线文档:https://datascale-ai.github.io/opentalking/
- 英文文档:https://datascale-ai.github.io/opentalking/en/
WebUI 与效果展示
OpenTalking 提供 Web 服务界面,用于管理数字人对话链路:可以选择或新建数字人物,配置音色、LLM、TTS、STT 和数字人驱动模型,查看模型连接状态,并在同一页面完成实时对话、字幕和音视频播放验证。

Demo 视频
以下是 OpenTalking 典型场景演示视频,覆盖实时对话、视频创作和视频克隆三类前端工作流。
| A. 实时对话 | ||
|---|---|---|
|
电商带货 |
陪伴案例 |
新闻主播 |
| B. 视频创作 | ||
|---|---|---|
|
语音 drive |
文字 drive |
克隆音色 drive |
| C. 视频克隆 | |
|---|---|
|
摄像头实时模仿 |
上传视频模仿 |
快速开始
OpenTalking 的 编排层(API / Worker / 前端)和 数字人合成后端(mock、local、direct_ws 或 OmniRT)可以独立部署。第一次接触项目时,建议先用 Mock 模式跑通完整链路,再按显卡和模型需求切换到更多数字人渲染模型。
0. 安装 OpenTalking
export DIGITAL_HUMAN_HOME=/opt/digital_human
mkdir -p "$DIGITAL_HUMAN_HOME"
cd "$DIGITAL_HUMAN_HOME"
git clone https://github.com/datascale-ai/opentalking.git && cd opentalking
# 设置国内源提升依赖包下载速度(样例为清华源,可按需切换)
export UV_DEFAULT_INDEX=https://pypi.tuna.tsinghua.edu.cn/simple
# 依赖包安装
uv sync --extra dev --python 3.11
source .venv/bin/activate
cp .env.example .env
要求:Python 3.10+(推荐 3.11)、Node.js 18+、FFmpeg。若环境不便使用 uv,可用兼容安装:
python3 -m venv .venv
source .venv/bin/activate
pip install --index-url https://pypi.tuna.tsinghua.edu.cn/simple -e ".[dev]"
编辑 .env,至少配置 LLM / TTS;edge TTS 不需要 key:
# LLM模型配置(百炼、DeepSeek、豆包等)
OPENTALKING_LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENTALKING_LLM_API_KEY=sk-your-key
OPENTALKING_LLM_MODEL=qwen-flash
# 语音识别(若使用 DashScope STT;本地 SenseVoice 不需要 key)
OPENTALKING_STT_DEFAULT_PROVIDER=dashscope
OPENTALKING_STT_DASHSCOPE_MODEL=paraformer-realtime-v2
OPENTALKING_STT_DASHSCOPE_API_KEY=sk-your-key
# 声音合成/声音复刻(若使用 DashScope TTS)
OPENTALKING_TTS_DASHSCOPE_API_KEY=sk-your-key
# 其他声音合成选项
OPENTALKING_TTS_DEFAULT_PROVIDER=edge
OPENTALKING_TTS_EDGE_VOICE=zh-CN-XiaoxiaoNeural
注意:
edgeTTS 不需要 key。LLM、STT、TTS 不再共享 fallback key;即使用同一把 DashScope key,也要分别写入对应的OPENTALKING_*_API_KEY。
1. 快速上手
适用:不下载模型权重、不部署推理后端,先验证前端、API、LLM、TTS、STT、WebRTC 和浏览器播放链路。数字人画面使用内置 Mock 静态帧,LLM 回复、流式 TTS、字幕事件和 WebRTC 传输仍是完整链路,启动服务:
cd "$DIGITAL_HUMAN_HOME/opentalking"
bash scripts/start_unified.sh --mock
默认前端地址是 http://localhost:5173。如果需要改端口请额外指定端口:
bash scripts/start_unified.sh --mock --api-port 8210 --web-port 5280
停止服务:
bash scripts/quickstart/stop_all.sh
2. 常用启动参数
scripts/start_unified.sh 是推荐入口;旧的 scripts/quickstart/* 脚本继续保留,适合更细的模型服务调试。
| 参数 | 作用 | 示例 |
|---|---|---|
--mock |
使用内置 Mock,不需要模型权重或视频推理后端 | --mock |
--backend <mock|local|omnirt|direct_ws> |
指定模型的推理后端 | --backend local |
--model <name> |
指定要使用推理的模型 | --model quicktalk |
--omnirt <url> |
接入 OmniRT 推理服务的url | --omnirt http://127.0.0.1:9000 |
--api-port <port> |
OpenTalking服务后端端口 | --api-port 8010 |
--web-port <port> |
OpenTalking WebUI端口 | --web-port 5180 |
--host <host> |
WebUI 监听地址(可选) | --host 0.0.0.0 |
--env <file> |
指定 env 文件位置(可选) | --env scripts/quickstart/env |
示例:
# 初阶1:消费级卡单机路线,权重放在仓库根目录 models/ (需要先按下方教程完成部署)
bash scripts/start_unified.sh --backend local --model quicktalk
# 初阶2:消费级卡单机 Wav2Lip 路线,使用 OpenTalking 内置 local runtime
bash scripts/start_unified.sh --backend local --model wav2lip
# 高阶2:OmniRT 远端推理路线,先启动 OmniRT,再连接 endpoint (需要先按下方教程完成部署)
bash scripts/start_unified.sh --backend omnirt --model flashtalk --omnirt http://<gpu-server>:9000
选择部署路线
Mock 模式跑通后,建议按以下部署场景选择其中一条路线继续。
| 路线 | 推荐模型 | 是否部署推理后端 | 适合场景 |
|---|---|---|---|
| 初阶1:消费级显卡单机部署 | quicktalk |
不需要独立推理服务 | 单机 3090 / 4090 机器上实时视频渲染 |
| 初阶2:消费级显卡单机部署 | wav2lip |
不需要独立推理服务 | 轻量的口型同步、快速验证自定义形象 |
| 高阶1:全本地音频 + QuickTalk | sensevoice + local_cosyvoice + quicktalk |
需要本地 STT/TTS 权重和 CosyVoice service | 私有化验证、本地语音输入和本地音色合成 |
| 高阶2:远端高质量推理 | flashtalk |
需要 | 多卡、远端 GPU/NPU、私有化和高质量画面 |
如果想在初阶1的 QuickTalk 单机部署基础上,把语音识别和语音合成也改成本地模型,可以继续走高阶1,参考 本地 STT/TTS + QuickTalk。LLM 默认仍通过 OpenAI-compatible endpoint 接入;如果已有本地 LLM 服务,也可以把 OPENTALKING_LLM_BASE_URL 指向本地服务。
初阶1:消费级显卡单机部署
适用:在本地 GPU 机器上运行真实数字人实时渲染,不想一开始就引入如OmniRT等推理服务,推荐从 QuickTalk 开始。若对 Wav2Lip 感兴趣,移步初阶2,初阶1与初阶2内容非常相似。
1. 安装本地模型依赖
如果前面只安装了 --extra dev,这里补装本地模型依赖:
cd "$DIGITAL_HUMAN_HOME/opentalking"
uv sync --extra dev --extra models --python 3.11
source .venv/bin/activate
2. 准备 QuickTalk 权重
本地权重、第三方 HuBERT / InsightFace 依赖和缓存统一放到仓库根目录 models/quicktalk/。QuickTalk 权重和 HuBERT 依赖可从 Hugging Face 下载:
cd "$DIGITAL_HUMAN_HOME/opentalking"
mkdir -p models/quicktalk/checkpoints
uv pip install -U "huggingface_hub[cli]"
# 可选:网络慢时使用镜像
export HF_ENDPOINT=https://hf-mirror.com
hf download datascale-ai/quicktalk \
quicktalk.pth \
repair.npy \
chinese-hubert-large/config.json \
chinese-hubert-large/preprocessor_config.json \
chinese-hubert-large/pytorch_model.bin \
--local-dir models/quicktalk/checkpoints
QuickTalk 权重和 HuBERT 文件已经包含在 datascale-ai/quicktalk 中。QuickTalk 仍需要单独准备 InsightFace buffalo_l 依赖权重:
# 下载并解压 InsightFace buffalo_l 到 QuickTalk auxiliary 目录。
mkdir -p /tmp/opentalking-insightface models/quicktalk/checkpoints/auxiliary/models
curl -L \
-o /tmp/opentalking-insightface/buffalo_l.zip \
https://github.com/deepinsight/insightface/releases/download/v0.7/buffalo_l.zip
unzip -q -o /tmp/opentalking-insightface/buffalo_l.zip \
-d /tmp/opentalking-insightface
rsync -a /tmp/opentalking-insightface/buffalo_l/ \
models/quicktalk/checkpoints/auxiliary/models/buffalo_l/
如果 Hugging Face 或 GitHub 访问不稳定,可以使用内部镜像或手动同步离线文件;只要最终目录结构与下方一致即可。
整理后目录应类似:
models/
quicktalk/
checkpoints/
quicktalk.pth
repair.npy
chinese-hubert-large/
config.json
preprocessor_config.json
pytorch_model.bin
auxiliary/models/buffalo_l/
det_10g.onnx
...
建议校验关键文件 SHA256:
quicktalk.pth: fc8a7ea025c99a471ef00738874be5ecb6b5dfaf88ff6a1255a5d45a05d73001
repair.npy: 9ea50edde851bf3b12aa22d67b6f0db4f2930f3d9b7b3febcbd383e14117bfca
chinese-hubert-large/config.json: 8511d73054ac289ef47a527efdfd6738d2cb60f69f2973fdc9277492d9ff854b
chinese-hubert-large/preprocessor_config.json: 6334d6e0c5f2084c9a99b85ddff243cbc79dbaa4aa790bcddf8c41c496fab6fb
chinese-hubert-large/pytorch_model.bin: 9cf43abec3f0410ad6854afa4d376c69ccb364b48ddddfd25c4c5aa16398eab0
检查关键文件(若文件不存在会提示No such file or directory):
stat models/quicktalk/checkpoints/quicktalk.pth
stat models/quicktalk/checkpoints/repair.npy
stat models/quicktalk/checkpoints/chinese-hubert-large/pytorch_model.bin
stat models/quicktalk/checkpoints/auxiliary/models/buffalo_l/det_10g.onnx
更完整的 QuickTalk 权重来源、第三方依赖说明和离线同步方式见 Talking-Head 模型部署。
3. 启动 OpenTalking(推理后端为 QuickTalk)
export OPENTALKING_TORCH_DEVICE=cuda:0
export OPENTALKING_QUICKTALK_ASSET_ROOT="$DIGITAL_HUMAN_HOME/opentalking/models/quicktalk"
export OPENTALKING_QUICKTALK_WORKER_CACHE=1
cd "$DIGITAL_HUMAN_HOME/opentalking"
bash scripts/start_unified.sh --backend local --model quicktalk --api-port 8210 --web-port 5280
打开 http://localhost:5280,选择 QuickTalk Local 形象和 quicktalk 模型。若不指定 --web-port,默认前端地址是 http://localhost:5173。首次启动会构建 face cache 和 worker,可能需要几十秒;后续会复用缓存。
4. 上传自己的数字人形象
WebUI 的“形象库”支持从本地上传参考图创建自定义形象。进入页面后点击 从本地上传新形象,填写名称并上传正脸或半身参考图,系统会基于当前选择的形象生成一个可删除的自定义形象。
选中 QuickTalk 作为驱动模型,再上传自己的参考图,给数字人命名,产生一个新的形象。随后可以按照需要在左侧调整音色等,最后点击开始对话即可(下图是一个gif演示,可能加载较慢)。
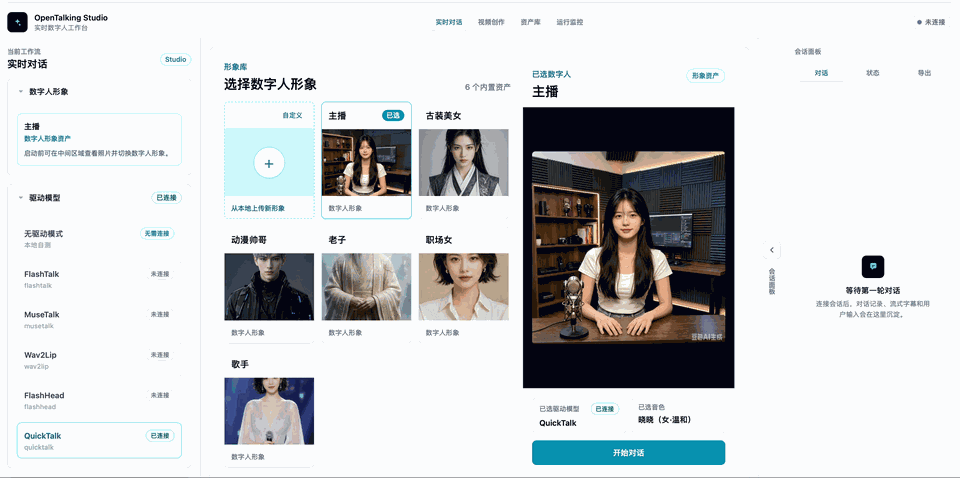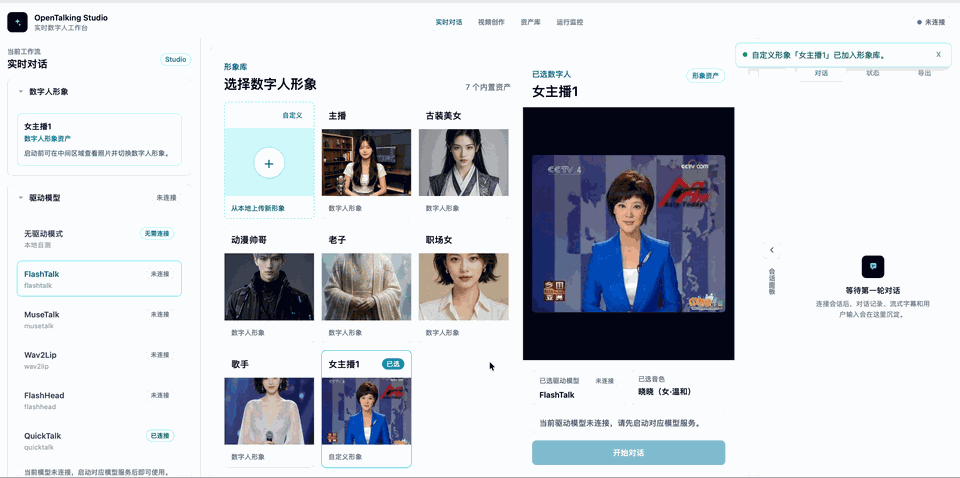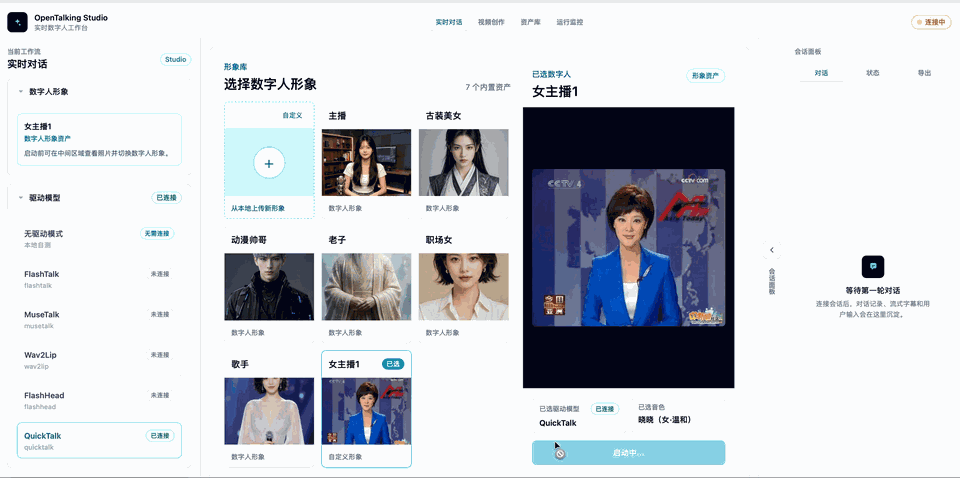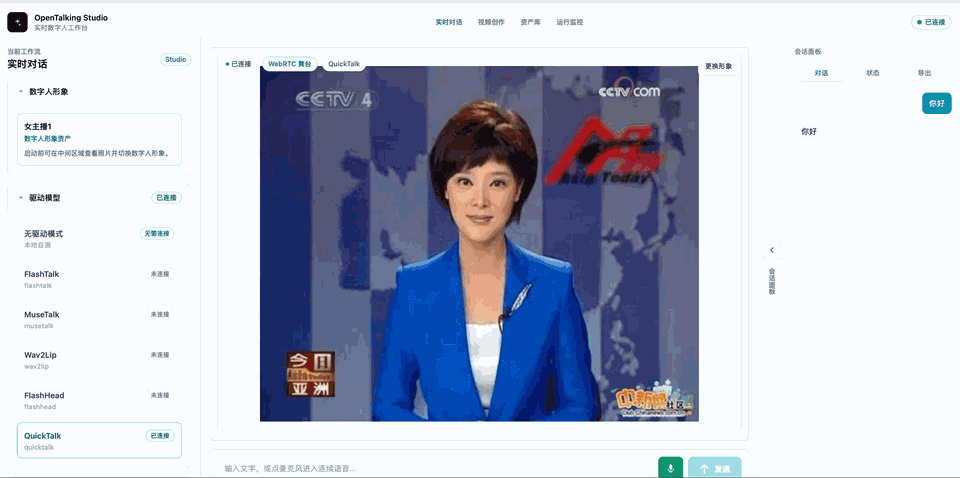
5. 消费级卡调优
如果显存紧张或首帧太慢,优先调这些参数:
注意,调整完后需要重新启动服务
| 参数 | 默认建议 | 作用 |
|---|---|---|
OPENTALKING_QUICKTALK_MAX_TEMPLATE_SECONDS |
留空 | 默认使用完整模板视频;显式填秒数时限制模板视频预处理时长 |
OPENTALKING_QUICKTALK_RESOLUTION |
256 |
降低可减少显存和推理压力 |
OPENTALKING_QUICKTALK_HUBERT_DEVICE |
留空或 cuda:1 |
多卡时可把 HuBERT 放到另一张卡 |
OPENTALKING_PREWARM_AVATARS |
quicktalk-local |
服务启动时提前预热 avatar |
高阶1:全本地音频 + QuickTalk
适用:在初阶1的 QuickTalk 单机视频驱动基础上,把 STT 和 TTS 也切到本地部署,用于私有化验证、本地语音输入和本地音色合成。这条路线需要额外准备 SenseVoiceSmall、Fun-CosyVoice3-0.5B-2512 权重,并启动 CosyVoice service;部署成本高于初阶路线,但不依赖百炼 STT/TTS。
完整步骤见 本地 STT/TTS + QuickTalk。
高阶2:远端高质量推理
适用:当你需要更高画质、远端 GPU/NPU、多卡调度或生产隔离时,再引入 OmniRT。OmniRT 完整部署见 模型部署文档。
当 OmniRT 已在远端 GPU 机器启动,并暴露端口(如 http://<gpu-server>:9000),就可以在 OpenTalking 中连接这个 endpoint:
cd "$DIGITAL_HUMAN_HOME/opentalking"
bash scripts/start_unified.sh \
--backend omnirt \
--model flashtalk \
--api-port 8210 \
--web-port 5280 \
--omnirt http://<gpu-server>:9000
高阶路线推荐模型:
- FlashTalk / FlashHead:高质量数字人视频生成模型,推荐通过 OmniRT 部署在远端 GPU/NPU 或多卡机器上。
- Wav2Lip / MuseTalk:如果你希望用 OmniRT 管理所有轻量模型,也可以通过同一个 endpoint 接入。
路线速览
| 阶段 | 推荐模型 | 启动方式 | 结果 |
|---|---|---|---|
| 快速上手 | mock |
bash scripts/start_unified.sh --mock |
验证 API、LLM、TTS、WebRTC |
| 初阶1 | quicktalk |
bash scripts/start_unified.sh --backend local --model quicktalk |
消费级显卡真实视频渲染 |
| 初阶2 | wav2lip |
bash scripts/start_unified.sh --backend local --model wav2lip |
轻量口型同步和自定义形象验证 |
| 高阶1 | sensevoice + local_cosyvoice + quicktalk |
见 本地 STT/TTS + QuickTalk | 全本地音频链路和私有化验证 |
| 高阶2 | flashtalk |
bash scripts/start_unified.sh --backend omnirt --model flashtalk --omnirt ... |
高质量、多卡、生产部署 |
模型支持
| 模型 | 输入 | 推荐 backend | 资源建议 |
|---|---|---|---|
mock |
参考图 / 静态帧 | mock |
不需要 GPU |
quicktalk |
template video + audio | local |
CUDA GPU,推荐 3090 / 4090 |
wav2lip |
参考图 / frames + audio | local / omnirt |
>= 8 GB GPU / NPU memory |
musetalk |
full frames + audio | omnirt / local |
>= 12 GB GPU memory |
soulx-flashtalk-14b |
portrait + audio | omnirt |
多卡 GPU / NPU |
soulx-flashhead-1.3b |
portrait + audio | omnirt |
多卡 GPU / NPU |
消费级显卡参考
下表是测试过的部署数据,后续会补充 4090 / 5090 或更多显卡数据,包括冷启动时间、首轮总延迟和显存等。
| 模型 | 硬件 | 输入 | 输出 | 显存占用 | 生成吞吐 |
|---|---|---|---|---|---|
quicktalk |
RTX 3090 | template video + audio | 720x900 / 25fps | 约 3.8 GiB | 约 35 fps |
更多的权重下载、Docker、故障排查和模型配置见 索引、模型部署文档、部署文档。
云端模型 API:Atlas Cloud

🎁 Atlas Cloud 是一个全模态 AI 推理平台,用一套 API 即可访问视频生成、图像生成和 LLM,无需分别对接多家厂商,一次接入即可统一调用全模态的 300+ 精选模型。
OpenTalking 的 LLM 走 OpenAI-compatible 接口,把 OPENTALKING_LLM_BASE_URL 指向 https://api.atlascloud.ai/v1 即可直接使用 Atlas 托管的 DeepSeek / Qwen 等模型,配置见 LLM 与 STT。更多预算友好的 API 方案见 Atlas Cloud coding plan。
能力进展与 Roadmap
Coming soon
-
更自然的实时对话体验 继续打磨打断、低延迟响应、音画同步、长会话恢复和运行状态可见性。
-
消费级显卡多模型路线 完善 QuickTalk / Wav2Lip / MuseTalk local 的资产检查、预热、缓存复用、低显存参数和更多 3090 / 4090 / WSL2 benchmark,并继续补齐 FasterLivePortrait 的视频创作与视频克隆评测数据。
-
Windows / WSL2 一键化部署 在现有 Windows 部署文档和测试记录基础上,继续降低模型下载、运行时安装、环境检查和诊断门槛。
-
高质量私有化部署 完善外部 OmniRT 推理服务、多模型 endpoint、容量调度、健康检查、生产监控和 GPU / NPU 部署指引。
-
更多云端语音与多模态 provider 在现有 OpenAI-compatible、DashScope、Xiaomi MiMo 等 profile 基础上,继续扩展可插拔 STT / TTS / LLM provider、统一前端选择体验和 provider 级健康检查。
-
Agent、记忆与平台能力 对接 OpenClaw 或外部 Agent,复用 memory、工具调用和知识库能力,并逐步补齐多会话调度、观测指标、安全合规、授权音色和合成内容标识。
已完成进展
-
2026-06-05:OpenAI-compatible 音频接口与 Xiaomi MiMo profile 新增 OpenAI-compatible STT / TTS 适配层、小米 MiMo STT / TTS / voice clone profile、前端 provider 选择与音色列表、provider 级 key/base_url 校验,并把
.env.example整理为 LLM / STT / TTS 独立 profile 模板,避免通用 OpenAI-compatible 配置与小米配置混用。 -
2026-06-04:FasterLivePortrait 视频创作与视频克隆 在现有实时对话链路外,补充 FasterLivePortrait 视频创作参数面板、视频克隆页面、自定义 source 资产上传、摄像头/上传视频 driving 输入和文档截图,复用 OmniRT + FasterLivePortrait runtime 路线。
-
2026-05-28:Windows / WSL2 部署文档与 benchmark 口径 新增 Windows / WSL2 部署指南、WSL2 显存统计修复说明、benchmark 指标定义和测试记录,并接入文档站导航。
-
2026-05-26:本地 STT/TTS + QuickTalk 私有化路线 新增 SenseVoiceSmall 本地 STT、local CosyVoice3 TTS service、前端 provider 切换、启动前 key 校验、本地音频模型下载脚本和完整部署文档。
-
2026-05-25:MuseTalk local backend 增加 MuseTalk 本地 adapter、资产准备脚本、支持矩阵和启动入口,用于轻量全帧数字人验证。
-
2026-05-22:统一 audio2video runner 将 local adapter 与 OmniRT 路线统一到 audio2video client / runner,减少 QuickTalk、Wav2Lip、MuseTalk 等模型在会话链路中的分叉逻辑。
-
2026-05-21:Avatar 资产预热与缓存 完善 QuickTalk / Wav2Lip 自定义形象资产预处理、预热、缓存命中和前端状态展示,减少首次会话等待时间。
-
2026-05-13:模型 backend 解耦 将
mock、local、direct_ws、omnirt从架构上拆开,支持不同模型按部署形态选择后端。 -
2026-04-16:实时数字人基础体验 建立 Web 控制台、LLM 对话、TTS、字幕事件和 WebRTC 音视频播放的主链路。
系统架构与项目结构

opentalking/
├── opentalking/ # 编排层 Python 包(flat layout,根目录直接 import)
│ ├── core/ # 接口协议、类型、配置、registry
│ ├── providers/ # 能力适配器(按"能力域 / 提供方"两级)
│ │ ├── stt/dashscope/ # 语音识别
│ │ ├── tts/{edge,dashscope_qwen,cosyvoice_ws,...}/ # 语音合成 + 复刻
│ │ ├── llm/openai_compatible/ # 大语言模型
│ │ ├── rtc/aiortc/ # WebRTC 推流
│ │ └── synthesis/{flashtalk,flashhead,omnirt,mock}/ # 远端/协议型合成 provider
│ ├── models/ # local adapter 代码(quicktalk / wav2lip / musetalk 等)
│ ├── avatar/ # 数字人形象资产管理
│ ├── voice/ # 音色资产管理
│ ├── media/ # 中性算子工具
│ ├── pipeline/{session,speak,recording}/ # 业务编排
│ └── runtime/ # 进程胶水(task_consumer / bus / timing)
├── models/ # 本地权重、模板、缓存和用户资产
├── apps/
│ ├── api/ # FastAPI 服务
│ ├── unified/ # 单进程模式(开发友好)
│ ├── web/ # React 前端
│ └── cli/ # download_models / doctor / ...
├── configs/ # YAML 配置(profiles / inference / synthesis)
├── docker/ + docker-compose.yml # 容器化部署
├── scripts/ # start_unified.sh / quickstart / run_omnirt.sh 等
├── tests/ # 单元 / 集成测试
└── docs/ # 文档
文档与社区
- 快速开始
- 模型(权重下载、国内源、启动、验证)
- 架构说明
- 配置说明
- 部署文档(Docker Compose、分布式部署)
- 模型适配
- 贡献指南(开发环境、CLI 工具、ruff / mypy / pytest)
欢迎加入 QQ 交流群,讨论实时数字人、FlashTalk、OmniRT、模型部署和产品场景。

AI 数字人交流群 · 群号:1103327938
致谢
OpenTalking 参考并受益于实时数字人生态中的优秀项目:
License
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file opentalking-0.1.0.tar.gz.
File metadata
- Download URL: opentalking-0.1.0.tar.gz
- Upload date:
- Size: 2.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3016890d5f421eddd169badfbee3e668b56f90d8e833970df24ddf23d6a65ff7
|
|
| MD5 |
05c7fc3d69d5c2a2b82e5bf2f0872546
|
|
| BLAKE2b-256 |
1708b9b3bbd3bd6cc5513a42733e40e6c0e88a0006ad0190679514d83d5d6072
|
Provenance
The following attestation bundles were made for opentalking-0.1.0.tar.gz:
Publisher:
pypi-release.yml on datascale-ai/opentalking
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
opentalking-0.1.0.tar.gz -
Subject digest:
3016890d5f421eddd169badfbee3e668b56f90d8e833970df24ddf23d6a65ff7 - Sigstore transparency entry: 1832546518
- Sigstore integration time:
-
Permalink:
datascale-ai/opentalking@9ba17237c8efb4b65bf57efbe6f174c306697127 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/datascale-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi-release.yml@9ba17237c8efb4b65bf57efbe6f174c306697127 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file opentalking-0.1.0-py3-none-any.whl.
File metadata
- Download URL: opentalking-0.1.0-py3-none-any.whl
- Upload date:
- Size: 2.9 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
718f541a38d1c5b1398f1ca7084956ae53c0b0e469ae6e8fd7cdaa153b04dd53
|
|
| MD5 |
b0ec8628f8948f49af255302a8143914
|
|
| BLAKE2b-256 |
bde32582af9ef4dd5bea5937132f7479d7558f7eaf742919a357c4bb13d36080
|
Provenance
The following attestation bundles were made for opentalking-0.1.0-py3-none-any.whl:
Publisher:
pypi-release.yml on datascale-ai/opentalking
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
opentalking-0.1.0-py3-none-any.whl -
Subject digest:
718f541a38d1c5b1398f1ca7084956ae53c0b0e469ae6e8fd7cdaa153b04dd53 - Sigstore transparency entry: 1832546751
- Sigstore integration time:
-
Permalink:
datascale-ai/opentalking@9ba17237c8efb4b65bf57efbe6f174c306697127 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/datascale-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi-release.yml@9ba17237c8efb4b65bf57efbe6f174c306697127 -
Trigger Event:
workflow_dispatch
-
Statement type:







