Non-invasive health checks for Pandas method chains

Project description
Pandas Checks


Pandas Checks adds .check methods to Pandas so you can inspect method chains without cutting them up.
As Fleetwood Mac says, you would never break the chain.
import pandas_checks
iris_processed = (
iris
.dropna()
.check.assert_positive(subset=["petal_length", "sepal_length"]) # 🐼🩺 Validate assumptions
.check.hist('petal_length') # 🐼🩺 Plot the distribution of a column after cleaning
.query("species=='setosa'")
.check.head(3) # 🐼🩺 Display the first few rows after more cleaning
.check.write("iris_processed.parquet") # 🐼🩺 Export the interim data, with type inferred from name
)
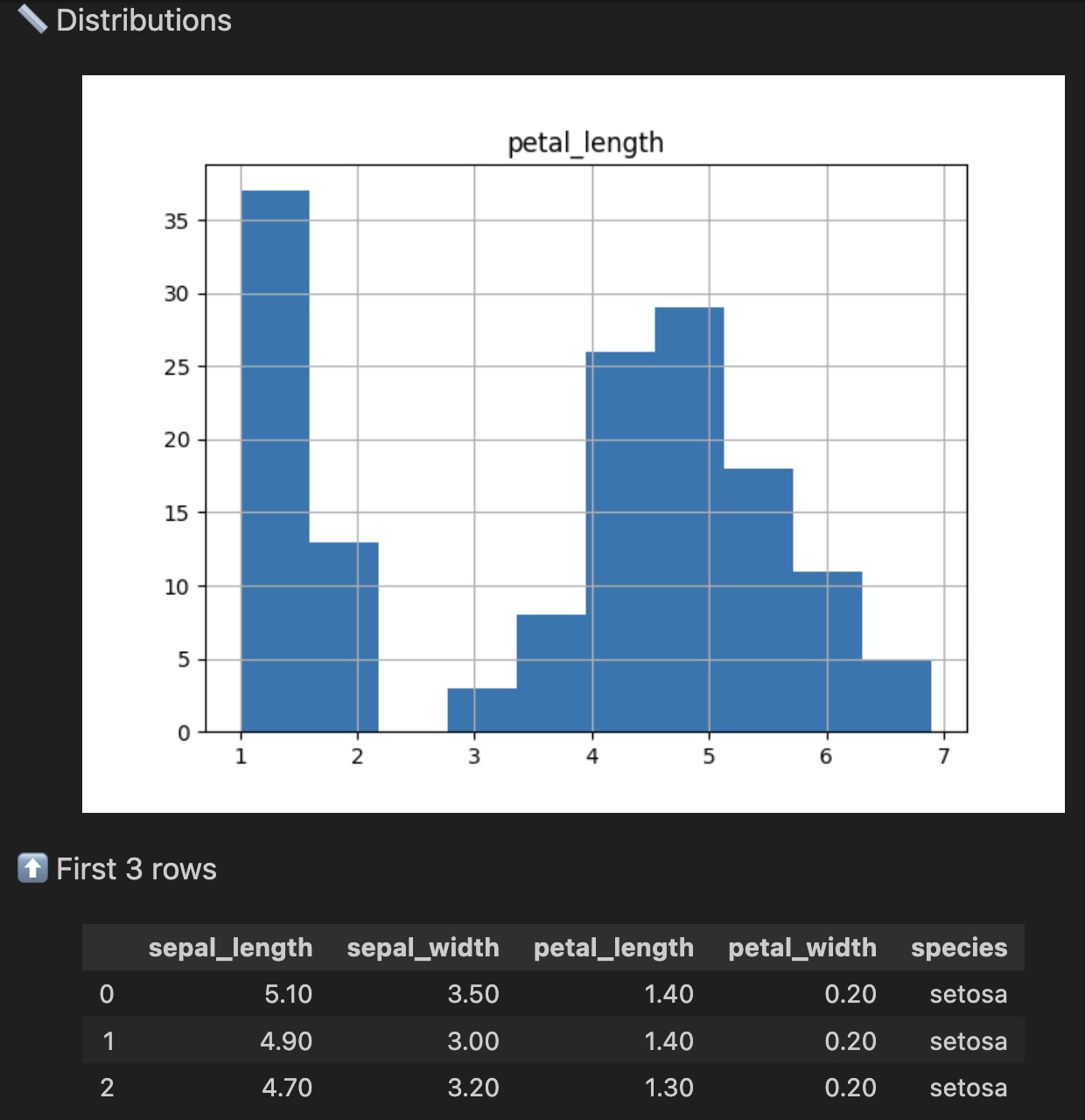
The .check methods didn't modify how iris data got processed. That's the difference between .head() and .check.head().
Table of Contents
💡 See the docs for details and configuration options.
Installation
# With uv
uv add pandas-checks
# Or with pip
pip install pandas-checks
.check methods
Here's what's in the doctor's bag.
Assertions
General:
.check.assert_data()- Check that data passes an arbitrary condition, expressed as a lambda function - DataFrame | Series
Type assertions:
.check.assert_datetime()- DataFrame | Series.check.assert_float()- DataFrame | Series.check.assert_int()- DataFrame | Series.check.assert_str()- DataFrame | Series.check.assert_timedelta()- DataFrame | Series.check.assert_type()- DataFrame | Series
Value assertions:
.check.assert_all_nulls()- DataFrame | Series.check.assert_less_than()- DataFrame | Series.check.assert_greater_than()- DataFrame | Series.check.assert_negative()- DataFrame | Series.check.assert_no_nulls()- DataFrame | Series.check.assert_nrows()- DataFrame | Series.check.assert_positive()- DataFrame | Series.check.assert_same_nrows()- Confirm that the DataFrame/Series has the same number of rows as that of another DF/Series - DataFrame | Series.check.assert_unique()- DataFrame | Series
Describe data
.check.columns()- DataFrame.check.describe()- DataFrame | Series.check.dtype()- Series.check.dtypes()- DataFrame.check.function()- Apply an arbitrary lambda function to your data and see the result - DataFrame | Series.check.head()- DataFrame | Series.check.info()- DataFrame | Series.check.memory_usage()- DataFrame | Series.check.ncols()- Count columns - DataFrame | Series.check.ndups()- Count rows with duplicate values - DataFrame | Series.check.nnulls()- Count rows with null values - DataFrame | Series.check.nrows()- Count rows - DataFrame | Series.check.nunique()- DataFrame | Series.check.print()- Print a string, a variable, or the current dataframe - DataFrame | Series.check.shape()- DataFrame | Series.check.tail()- DataFrame | Series.check.unique()- DataFrame | Series.check.value_counts()- DataFrame | Series
Disable Pandas Checks
These methods can disable Pandas Checks methods, temporarily or permanently.
.check.disable_checks()- Don't run checks. By default, still runs assertions. - DataFrame | Series.check.enable_checks()- Run checks again. - DataFrame | Series
Export interim files
Time your code
.check.print_time_elapsed(start_time)- Print the execution time since you calledstart_time = pdc.start_timer()- DataFrame | Series
💡 Tip: You can use this stopwatch anywhere in your Python code.
from pandas_checks import print_elapsed_time, start_timer start_time = start_timer() ... print_elapsed_time(start_time)
Visualize data
.check.hist()- A histogram - DataFrame | Series.check.plot()- An arbitrary plot you can customize - DataFrame | Series
Giving feedback and contributing
If you run into trouble or have questions, I'd love to know. Please open an issue.
Contributions are appreciated! Please see more details.
License
Pandas Checks is licensed under the BSD-3 License.
🐼🩺
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pandas_checks-2.0.1.tar.gz.
File metadata
- Download URL: pandas_checks-2.0.1.tar.gz
- Upload date:
- Size: 32.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.5 {"installer":{"name":"uv","version":"0.11.5","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
18f993c2644b301b51446c4f38396e2bffee43d956cb8e4781a484b20418c426
|
|
| MD5 |
391271fed0f41304db9a728e1c9ac2c6
|
|
| BLAKE2b-256 |
41402e1ab143f96e4c50c5a5184ad23b0c8ea5dbf6bdd99077517456f5d2b2b5
|
File details
Details for the file pandas_checks-2.0.1-py3-none-any.whl.
File metadata
- Download URL: pandas_checks-2.0.1-py3-none-any.whl
- Upload date:
- Size: 35.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.5 {"installer":{"name":"uv","version":"0.11.5","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
85a7e7f6353cf5a9851a63747c24e8a5e302192c69c8c9c5404aec9b49f56333
|
|
| MD5 |
a90f8a63df86fc2f831a24008cbc5894
|
|
| BLAKE2b-256 |
ce4c5cf75c8b89559f0c2f941357dcef4b7209a23d6de9989f078e44d4faa036
|







