Cut memory footprint by half in just 2 lines of code.

Project description
pandazip





Go minimal, go green, go pandazip.
Cut memory footprint by forth in just 2 lines of code. Compress Pandas DataFrames without losing information or go smaller in expense of losing a bit of information. Swift parallel execution makes pandazip very fast.
"A 2018 blog post from OpenAI revealed that the amount of compute required for the largest AI training runs has increased by 300,000 times since 2012. And while that post didn’t calculate the carbon emissions of such training runs, others have done so. According to a paper by Emma Strubel and colleagues, an average American is responsible for about 36,000 tons of CO2 emissions per year; training and developing one machine translation model that uses a technique called neural architecture search was responsible for an estimated 626,000 tons of CO2."
"According to the American Council for an Energy-Efficient Economy it takes 5.12 kWh of electricity per gigabyte of transferred data. And according to the Department of Energy the average US power plant expends 600 grams of carbon dioxide for every kWh generated. That means that transferring 1GB of data produces 3kg of CO2."
plus storage and processing = Huge impact on environment without even noticing.
Take action now!
Install
pandazip can be installed from PyPI:
pip install pandazip
Compressing Pandas DataFrame using Pandazip
from pandazip import Pandazip
compressed_dataframe = Pandazip().zip(raw_dataframe)
Lossless Compression
Compression level can be tuned with level parameter. Default is level="low", which is lossless. Every column is converted to the smallest datatype that can store column's data without losing information.
compressed_dataframe = Pandazip().zip(raw_dataframe, level="low")
Lossly Compression
When level parameter is set to "mid" or "high", Pazdazip limits numeric datatypes to 32 and 16 bits respectively. Also, string columns are converted to categoric datatype, if feasable.
compressed_dataframe = Pandazip().zip(raw_dataframe, level="high")
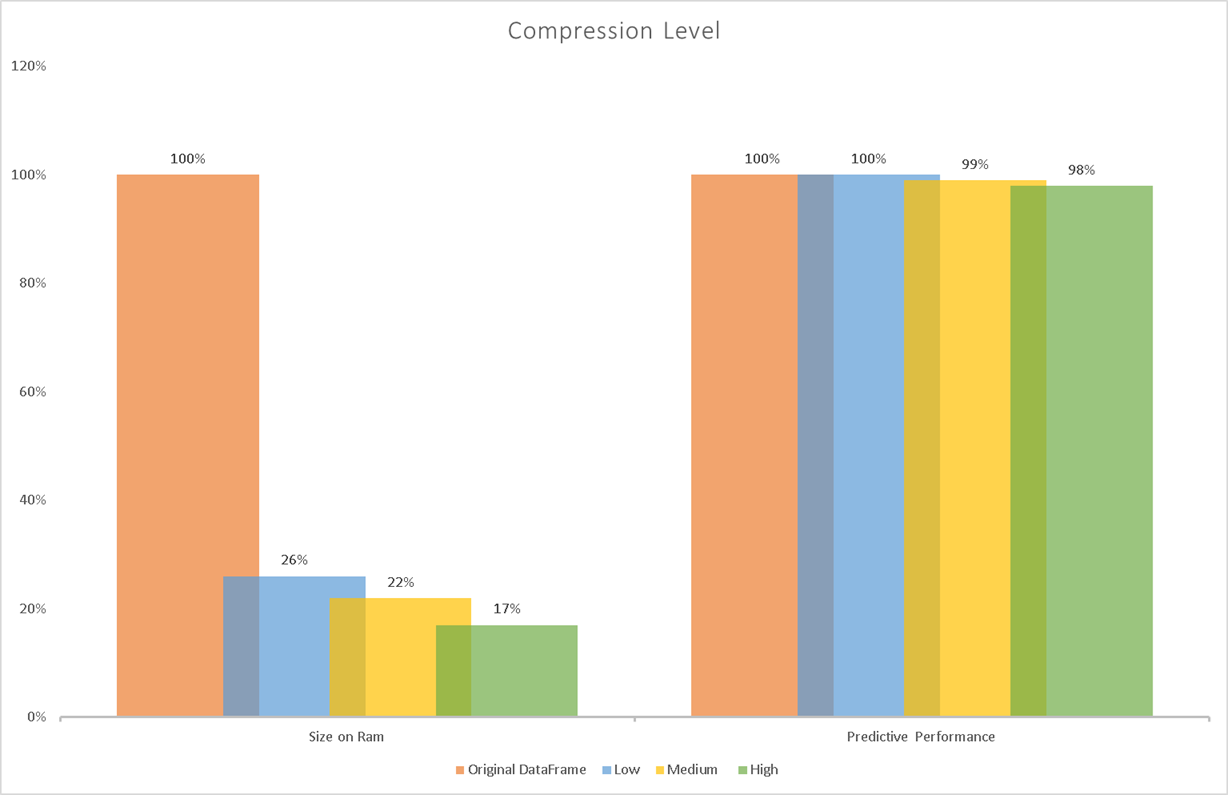
Results
Pandazip is tested on more than 100 Kaggle datasets and notebooks, feel free to share your results.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file pandazip-0.0.11.tar.gz.
File metadata
- Download URL: pandazip-0.0.11.tar.gz
- Upload date:
- Size: 4.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.7.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1c1eba49f7a80f90925ee5a74edb50d17ee911d317111ebfbc346ed346ddb4f1
|
|
| MD5 |
cd783d5e055edc4eb1bf78fe7ffd7198
|
|
| BLAKE2b-256 |
2a4dbffe54523af8bdc12fccf822ef69dd0c939af0b6e1745bb66d19b2bd2256
|







