paperscraper: Package to scrape papers.


Project description







paperscraper
paperscraper is a python package for scraping publication metadata or full text files (PDF or XML) from
PubMed or preprint servers such as arXiv, medRxiv, bioRxiv and chemRxiv.
It provides a streamlined interface to scrape metadata, allows to retrieve citation counts
from Google Scholar, impact factors from journals and comes with simple postprocessing functions
and plotting routines for meta-analysis.
Table of Contents
Getting started
pip install paperscraper
This is enough to query PubMed, arXiv or Google Scholar.
Local development
uv sync
This installs the project and dev tooling into .venv. Use uv run to execute commands, for example:
uv run python -c "import paperscraper"
Download X-rxiv Dumps
However, to scrape publication data from the preprint servers biorxiv, medrxiv and chemrxiv, the setup is different. The entire history of papers is downloaded and stored in the server_dumps folder in a .jsonl format (one paper per line). This takes a while, as of November 2025:
from paperscraper.get_dumps import biorxiv, medrxiv, chemrxiv
chemrxiv() # Takes 30min -> +30K papers (~50 MB file)
medrxiv() # Takes <1h -> +90K papers (~200 MB file)
biorxiv() # Up to 6h -> +400K papers (~800 MB file)
NOTE: Once the dumps are stored, please make sure to restart the python interpreter so that the changes take effect.
NOTE: If you experience API connection issues, since v0.2.12 there are automatic retries which you can even control and raise from the default of 10, as in biorxiv(max_retries=20).
Since v0.2.5 paperscraper also allows to scrape {med/bio/chem}rxiv for specific dates.
medrxiv(start_date="2023-04-01", end_date="2023-04-08")
But watch out. The resulting .jsonl file will be labelled according to the current date and all your subsequent searches will be based on this file only. If you use this option you might want to keep an eye on the source files (paperscraper/server_dumps/*jsonl) to ensure they contain the paper metadata for all papers you're interested in.
Arxiv local dump
If you prefer local search rather than using the arxiv API:
from paperscraper.get_dumps import arxiv
arxiv(start_date='2024-01-01', end_date=None) # scrapes all metadata from 2024 until today.
Afterwards you can search the local arxiv dump just like the other x-rxiv dumps.
The direct endpoint is paperscraper.arxiv.get_arxiv_papers_local. You can also specify the
backend directly in the get_and_dump_arxiv_papers function:
from paperscraper.arxiv import get_and_dump_arxiv_papers
get_and_dump_arxiv_papers(..., backend='local')
Examples
paperscraper is build on top of the packages arxiv, pymed, and scholarly.
Publication keyword search
Consider you want to perform a publication keyword search with the query:
COVID-19 AND Artificial Intelligence AND Medical Imaging.
- Scrape papers from PubMed:
from paperscraper.pubmed import get_and_dump_pubmed_papers
covid19 = ['COVID-19', 'SARS-CoV-2']
ai = ['Artificial intelligence', 'Deep learning', 'Machine learning']
mi = ['Medical imaging']
query = [covid19, ai, mi]
get_and_dump_pubmed_papers(query, output_filepath='covid19_ai_imaging.jsonl')
- Scrape papers from arXiv:
from paperscraper.arxiv import get_and_dump_arxiv_papers
get_and_dump_arxiv_papers(query, output_filepath='covid19_ai_imaging.jsonl')
- Scrape papers from bioRiv, medRxiv or chemRxiv:
from paperscraper.xrxiv.xrxiv_query import XRXivQuery
querier = XRXivQuery('server_dumps/chemrxiv_2020-11-10.jsonl')
querier.search_keywords(query, output_filepath='covid19_ai_imaging.jsonl')
You can also use dump_queries to iterate over a bunch of queries for all available databases.
from paperscraper import dump_queries
queries = [[covid19, ai, mi], [covid19, ai], [ai]]
dump_queries(queries, '.')
Or use the harmonized interface of QUERY_FN_DICT to query multiple databases of your choice:
from paperscraper.load_dumps import QUERY_FN_DICT
print(QUERY_FN_DICT.keys())
QUERY_FN_DICT['biorxiv'](query, output_filepath='biorxiv_covid_ai_imaging.jsonl')
QUERY_FN_DICT['medrxiv'](query, output_filepath='medrxiv_covid_ai_imaging.jsonl')
- Scrape papers from Google Scholar:
Thanks to scholarly, there is an endpoint for Google Scholar too. It does not understand Boolean expressions like the others, but should be used just like the Google Scholar search fields.
from paperscraper.scholar import get_and_dump_scholar_papers
topic = 'Machine Learning'
get_and_dump_scholar_papers(topic)
NOTE: The scholar endpoint does not require authentication but since it regularly prompts with captchas, it's difficult to apply large scale.
Full-Text Retrieval (PDFs & XMLs)
paperscraper allows you to download full text of publications using DOIs. The basic functionality works reliably for preprint servers (arXiv, bioRxiv, medRxiv, chemRxiv), but retrieving papers from PubMed dumps is more challenging due to publisher restrictions and paywalls.
Standard Usage
The main download functions work for all paper types with automatic fallbacks:
from paperscraper.pdf import save_pdf
paper_data = {'doi': "10.48550/arXiv.2207.03928"}
save_pdf(paper_data, filepath='gt4sd_paper.pdf')
To batch download full texts from your metadata search results:
from paperscraper.pdf import save_pdf_from_dump
# Save PDFs/XMLs in current folder and name the files by their DOI
save_pdf_from_dump('medrxiv_covid_ai_imaging.jsonl', pdf_path='.', key_to_save='doi')
Automatic Fallback Mechanisms
When the standard text retrieval fails, paperscraper automatically tries these fallbacks:
- BioC-PMC: For biomedical papers in PubMed Central (open-access repository), it retrieves open-access full-text XML from the BioC-PMC API.
- eLife Papers: For eLife journal papers, it fetches XML files from eLife's open GitHub repository.
These fallbacks are tried automatically without requiring any additional configuration.
Enhanced Retrieval with Publisher APIs
For more comprehensive access to papers from major publishers, you can provide API keys for:
- Wiley TDM API: Enables access to Wiley publications (2,000+ journals).
- Elsevier TDM API: Enables access to Elsevier publications (The Lancet, Cell, ...).
- bioRxiv TDM API Enable access to bioRxiv publications (since May 2025 bioRxiv is protected with Cloudflare)
To use publisher APIs:
- Create a file with your API keys:
WILEY_TDM_API_TOKEN=your_wiley_token_here
ELSEVIER_TDM_API_KEY=your_elsevier_key_here
AWS_ACCESS_KEY_ID=your_aws_access_key_here
AWS_SECRET_ACCESS_KEY=your_aws_secret_key_here
NOTE: The AWS keys can be created in your AWS/IAM account. When creating the key, make sure you tick the AmazonS3ReadOnlyAccess permission policy.
NOTE: If you name the file .env it will be loaded automatically (if it is in the cwd or anywhere above the tree to home).
- Pass the file path when calling retrieval functions:
from paperscraper.pdf import save_pdf_from_dump
save_pdf_from_dump(
'pubmed_query_results.jsonl',
pdf_path='./papers',
key_to_save='doi',
api_keys='path/to/your/api_keys.txt'
)
For obtaining API keys:
- Wiley TDM API: Visit Wiley Text and Data Mining (free for academic users with institutional subscription)
- Elsevier TDM API: Visit Elsevier's Text and Data Mining (free for academic users with institutional subscription)
NOTE: While these fallback mechanisms improve retrieval success rates, they cannot guarantee access to all papers due to various access restrictions.
Citation search
You can fetch the number of citations of a paper from its title or DOI
from paperscraper.citations import get_citations_from_title, get_citations_by_doi
title = 'Über formal unentscheidbare Sätze der Principia Mathematica und verwandter Systeme I.'
print(get_citations_from_title(title))
doi = '10.1021/acs.jcim.3c00132'
get_citations_by_doi(doi)
NOTE: This uses the Semantic Scholar API which is bandwidth-limited. If you have an API Key set it via:
export SS_API_KEY=YOUR_API_KEY
This will increase your throughput for using paperscraper.citations based on the rate limits of your key.
Journal impact factor
You can also retrieve the impact factor for all journals:
>>>from paperscraper.impact import Impactor
>>>i = Impactor()
>>>i.search("Nat Comms", threshold=85, sort_by='impact')
[
{'journal': 'Nature Communications', 'factor': 17.694, 'score': 94},
{'journal': 'Natural Computing', 'factor': 1.504, 'score': 88}
]
This performs a fuzzy search with a threshold of 85. threshold defaults to 100 in which case an exact search
is performed. You can also search by journal abbreviation, E-ISSN or NLM ID.
i.search("Nat Rev Earth Environ") # [{'journal': 'Nature Reviews Earth & Environment', 'factor': 37.214, 'score': 100}]
i.search("101771060") # [{'journal': 'Nature Reviews Earth & Environment', 'factor': 37.214, 'score': 100}]
i.search('2662-138X') # [{'journal': 'Nature Reviews Earth & Environment', 'factor': 37.214, 'score': 100}]
# Filter results by impact factor
i.search("Neural network", threshold=85, min_impact=1.5, max_impact=20)
# [
# {'journal': 'IEEE Transactions on Neural Networks and Learning Systems', 'factor': 14.255, 'score': 93},
# {'journal': 'NEURAL NETWORKS', 'factor': 9.657, 'score': 91},
# {'journal': 'WORK-A Journal of Prevention Assessment & Rehabilitation', 'factor': 1.803, 'score': 86},
# {'journal': 'NETWORK-COMPUTATION IN NEURAL SYSTEMS', 'factor': 1.5, 'score': 92}
# ]
# Show all fields
i.search("quantum information", threshold=90, return_all=True)
# [
# {'factor': 10.758, 'jcr': 'Q1', 'journal_abbr': 'npj Quantum Inf', 'eissn': '2056-6387', 'journal': 'npj Quantum Information', 'nlm_id': '101722857', 'issn': '', 'score': 92},
# {'factor': 1.577, 'jcr': 'Q3', 'journal_abbr': 'Nation', 'eissn': '0027-8378', 'journal': 'NATION', 'nlm_id': '9877123', 'issn': '0027-8378', 'score': 91}
# ]
Plotting
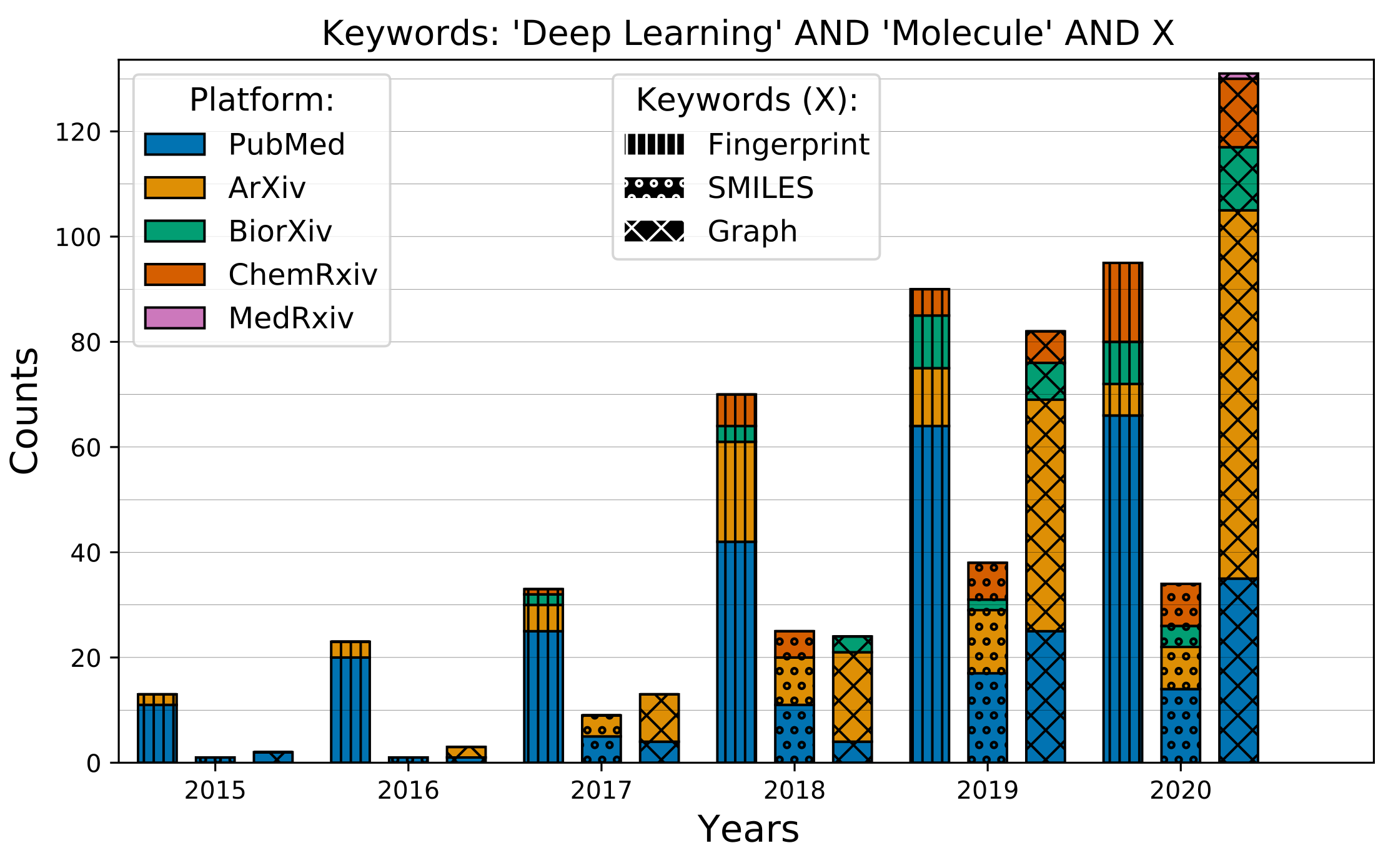
When multiple query searches are performed, two types of plots can be generated automatically: Venn diagrams and bar plots.
Barplots
Compare the temporal evolution of different queries across different servers.
from paperscraper import QUERY_FN_DICT
from paperscraper.postprocessing import aggregate_paper
from paperscraper.utils import get_filename_from_query, load_jsonl
# Define search terms and their synonyms
ml = ['Deep learning', 'Neural Network', 'Machine learning']
mol = ['molecule', 'molecular', 'drug', 'ligand', 'compound']
gnn = ['gcn', 'gnn', 'graph neural', 'graph convolutional', 'molecular graph']
smiles = ['SMILES', 'Simplified molecular']
fp = ['fingerprint', 'molecular fingerprint', 'fingerprints']
# Define queries
queries = [[ml, mol, smiles], [ml, mol, fp], [ml, mol, gnn]]
root = '../keyword_dumps'
data_dict = dict()
for query in queries:
filename = get_filename_from_query(query)
data_dict[filename] = dict()
for db,_ in QUERY_FN_DICT.items():
# Assuming the keyword search has been performed already
data = load_jsonl(os.path.join(root, db, filename))
# Unstructured matches are aggregated into 6 bins, 1 per year
# from 2015 to 2020. Sanity check is performed by having
# `filtering=True`, removing papers that don't contain all of
# the keywords in query.
data_dict[filename][db], filtered = aggregate_paper(
data, 2015, bins_per_year=1, filtering=True,
filter_keys=query, return_filtered=True
)
# Plotting is now very simple
from paperscraper.plotting import plot_comparison
data_keys = [
'deeplearning_molecule_fingerprint.jsonl',
'deeplearning_molecule_smiles.jsonl',
'deeplearning_molecule_gcn.jsonl'
]
plot_comparison(
data_dict,
data_keys,
title_text="'Deep Learning' AND 'Molecule' AND X",
keyword_text=['Fingerprint', 'SMILES', 'Graph'],
figpath='mol_representation'
)
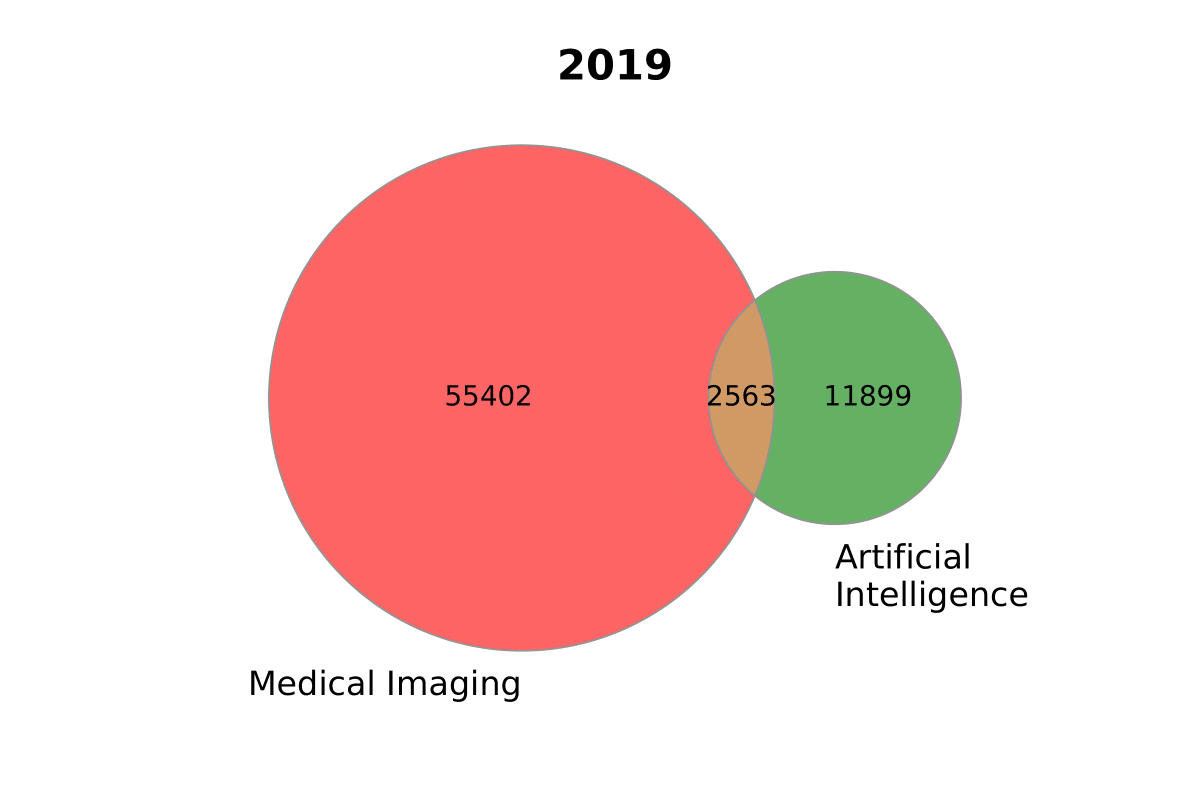
Venn Diagrams
from paperscraper.plotting import (
plot_venn_two, plot_venn_three, plot_multiple_venn
)
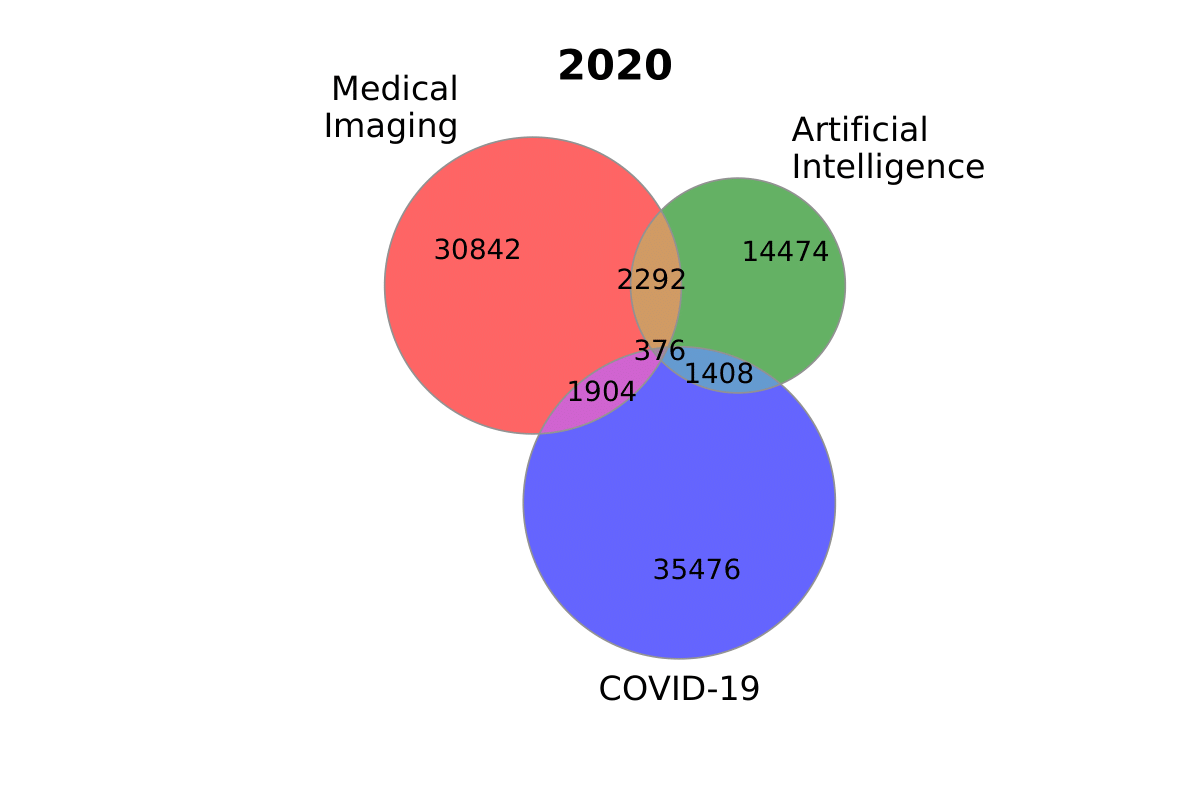
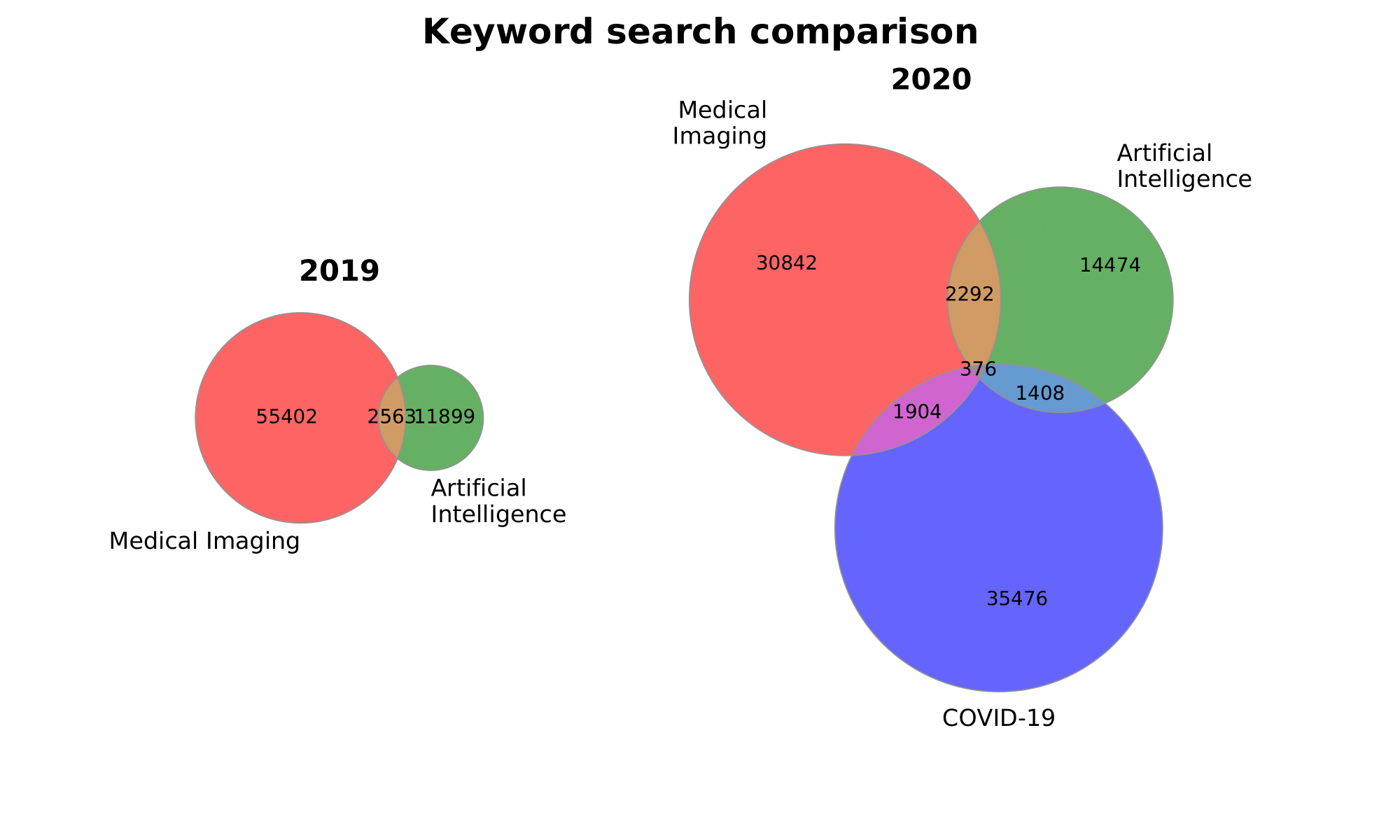
sizes_2020 = (30842, 14474, 2292, 35476, 1904, 1408, 376)
sizes_2019 = (55402, 11899, 2563)
labels_2020 = ('Medical\nImaging', 'Artificial\nIntelligence', 'COVID-19')
labels_2019 = ['Medical Imaging', 'Artificial\nIntelligence']
plot_venn_two(sizes_2019, labels_2019, title='2019', figname='ai_imaging')
plot_venn_three(
sizes_2020, labels_2020, title='2020', figname='ai_imaging_covid'
)
Or plot both together:
plot_multiple_venn(
[sizes_2019, sizes_2020], [labels_2019, labels_2020],
titles=['2019', '2020'], suptitle='Keyword search comparison',
gridspec_kw={'width_ratios': [1, 2]}, figsize=(10, 6),
figname='both'
)
Citation
If you use paperscraper, please cite a paper that motivated our development of this tool.
@article{born2021trends,
title={Trends in Deep Learning for Property-driven Drug Design},
author={Born, Jannis and Manica, Matteo},
journal={Current Medicinal Chemistry},
volume={28},
number={38},
pages={7862--7886},
year={2021},
publisher={Bentham Science Publishers}
}
Contributions
Thanks to the following contributors:
-
@mathinic: Since
v0.3.0improved PubMed full text retrieval with additional fallback mechanisms (BioC-PMC, eLife and optional Wiley/Elsevier APIs). -
@memray: Since
v0.2.12there are automatic retries when downloading the {med/bio/chem}rxiv dumps. -
@achouhan93: Since
v0.2.5{med/bio/chem}rxiv can be scraped for specific dates! -
@daenuprobst: Since
v0.2.4PDF files can be scraped directly (paperscraper.pdf.save_pdf) -
@oppih: Since
v0.2.3chemRxiv API also provides DOI and URL if available -
@lukasschwab: Enabled support for
arxiv>1.4.2in paperscraperv0.1.0. -
@juliusbierk: Bugfixes
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file paperscraper-0.3.5.tar.gz.
File metadata
- Download URL: paperscraper-0.3.5.tar.gz
- Upload date:
- Size: 68.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cdf07aaf69b0c8686f418ddabcd86d1d7081530b485db4779feea9446f2e6f3e
|
|
| MD5 |
e2a784fe15c148b51fccb59b04431b14
|
|
| BLAKE2b-256 |
c42d22083baaf16ba9d124e66be191efe139a0f1b1e4c3ba975e293eb21069d1
|
File details
Details for the file paperscraper-0.3.5-py3-none-any.whl.
File metadata
- Download URL: paperscraper-0.3.5-py3-none-any.whl
- Upload date:
- Size: 82.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a08c79d19e49f9ecc8ee048e8daf7a319d866bea74769529de0002ec088ab0fd
|
|
| MD5 |
c365c3fedf3b2b7667d4d4be16702060
|
|
| BLAKE2b-256 |
f006ae7310236896b48e6143f7dda87253b00d2fd14afcb81dc951d686e3de35
|







