Simple, intuitive pipelining in Python


Project description
Conveyor - Intuitive Python pipelines
Conveyor is a multiprocessing framework for creating intuitive data pipelines. With Conveyor, you can easily create stream-based pipelines to efficiently perform a series of operations on data, a task especially useful in the fields of machine learning and scientific computing. Creating a pipelined job is as easy as writing a function.
Why use Conveyor?
The answer is simple: throughput. It's like putting a second load of laundry in the washer while a previous load is in the dryer. By breaking down a problem into smaller serial tasks, we perform the smaller tasks in parallel and increase the efficiency of whatever problem we're trying to solve.
Installation
Install Conveyor with pip install parallel-conveyor.
A quick and trivial example
Let's say we wanted to build a short pipeline that computed the fourth root of a number (done in two steps) and the cube of a number (in one step). In this case, we would describe this pipeline visually as such:
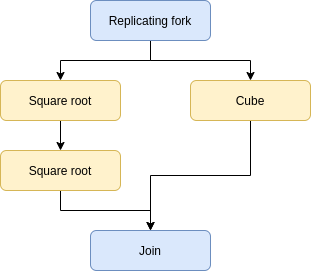
To express it with Conveyor, we simply build the pipeline as follows
from conveyor.pipeline import Pipeline
from conveyor.stages import Processor, Pipe, ReplicatingFork, Join
from math import sqrt
def square_root(arg):
return sqrt(arg)
def cube(arg):
return arg ** 3
with Pipeline() as pl:
# Duplicate the input
pl.add(ReplicatingFork(2))
# On first copy, compute the sqrt, on the second, the cube
pl.add(Processor(square_root), Processor(cube))
# On first copy, compute the sqrt, on the second, do nothing
pl.add(Processor(square_root), Pipe())
# Join the two data streams
pl.add(Join(2))
# Print the results
pl.add(Processor(print))
# Run the pipeline with three different inputs
pl.run([16, 3, 81])
$ python3 sample.py
2.0
1.3160740129524924
3.0
4096
27
531441
Other links
A note on stability
Conveyor is currently considered in alpha. Specifications will change, potentially in breaking ways.
Testing
To run the tests, ensure nose is installed and run nosetests from the project directory
pip3 install nose && nosetests
Building from source
To build the distribution archives, you will need the latest version of setuptools and wheel.
python3 -m pip install --user --upgrade setuptools wheel
Run setup.py to build using the following command:
python3 setup.py sdist bdist_wheel
The compiled .whl and .tar.gz files will be in the /dist directory.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file parallel-conveyor-0.1.3.tar.gz.
File metadata
- Download URL: parallel-conveyor-0.1.3.tar.gz
- Upload date:
- Size: 12.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.23.0 setuptools/46.4.0 requests-toolbelt/0.9.1 tqdm/4.45.0 CPython/3.8.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c97a7252e1219210747cb64a259e5decd037a372fa1b082fcbe513411bc726e9
|
|
| MD5 |
1c12ef6dfd7a2983949d936080443b36
|
|
| BLAKE2b-256 |
41c79d9e91272c8dab91a8e1319cdaf645cb3268697de00cbfe0a42ef5493b52
|
File details
Details for the file parallel_conveyor-0.1.3-py3-none-any.whl.
File metadata
- Download URL: parallel_conveyor-0.1.3-py3-none-any.whl
- Upload date:
- Size: 26.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.23.0 setuptools/46.4.0 requests-toolbelt/0.9.1 tqdm/4.45.0 CPython/3.8.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
60fb8a7873d99fc0510c6c7a4edb109599155c55114e995ee1511d1f1638f435
|
|
| MD5 |
003092afe5fe24fbf413577c961a2bc5
|
|
| BLAKE2b-256 |
5c76b8c15b4c38a8505e39c9efcb5a2e6bbc7c3e8a1f213907d9f8b0a0258637
|







