A lightweight implementation of Policy Dual Averaging (PDA) for reinforcement learning in PyTorch.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Policy Dual Averaging (PDA)



Policy Dual Averaging (PDA) is an on-policy reinforcement learning algorithm with theoretical guarantees and competitive empirical performance. This package is a lightweight PyTorch implementation of PDA and actor-accelerated PDA for problems with discrete and continuous action space. The environment wrappers and on-policy training loops are adapted from CleanRL and Tianshou. We use Gymnasium for environment simulation.
The algorithm is based on paper Actor-Accelerated Policy Dual Averaging for Reinforcement Learning in Continuous Action Spaces, and Policy Optimization over General State and Action Spaces.
PDA
On-policy RL methods (e.g., TRPO, PPO) under the Policy Mirror Descent (PMD) framework regularize the new policy toward the previous iterate. PDA instead regularizes (through Bregman divergence $D(\cdot,\cdot)$) toward a fixed prox-center policy $\pi_0$ and accumulates all past advantages $\psi^{\pi_t}$ with weights $\beta_t$:
$$ \pi_{k+1}(s) = \arg\min_{a \in \mathcal{U}} \sum_{t=0}^{k} \beta_t , \psi^{\pi_t}(s, a) + \lambda_k , D\bigl(\pi_0(s), a\bigr). $$
Acceleration: PDA's policy is defined implicitly. Every time an action $\pi_{k+1}(s)$ is needed (at every environment step), we have to solve the optimization subproblem over the action space $\mathcal{U}$, which is theoretically clean but computationally challenging for deep RL at scale. Actor-accelerated PDA addresses this by training a neural network actor $\hat{\pi}\theta$ to approximate the minimizer of the cumulative regularized objective: $\hat{\pi}{k+1}(s;\theta^\pi) \approx \pi_{k+1}(s)$.
Benchmarks
Comparison with on-policy methods: Actor-accelerated PDA consistently outperforms on-policy baselines (PPO, TRPO, NPG) on MuJoCo-v4 and OR-Gymnasium. Hyperparameters are kept fixed across all environments. Benchmarks are conducted using our Tianshou (V1.2.0) implementation using Tianshou tuned hyperparameters. Benchmark results table records average episodic return over the final 5 epochs, 10 seeds × 10 evaluations per seed, 1M (or 3M) environment steps.
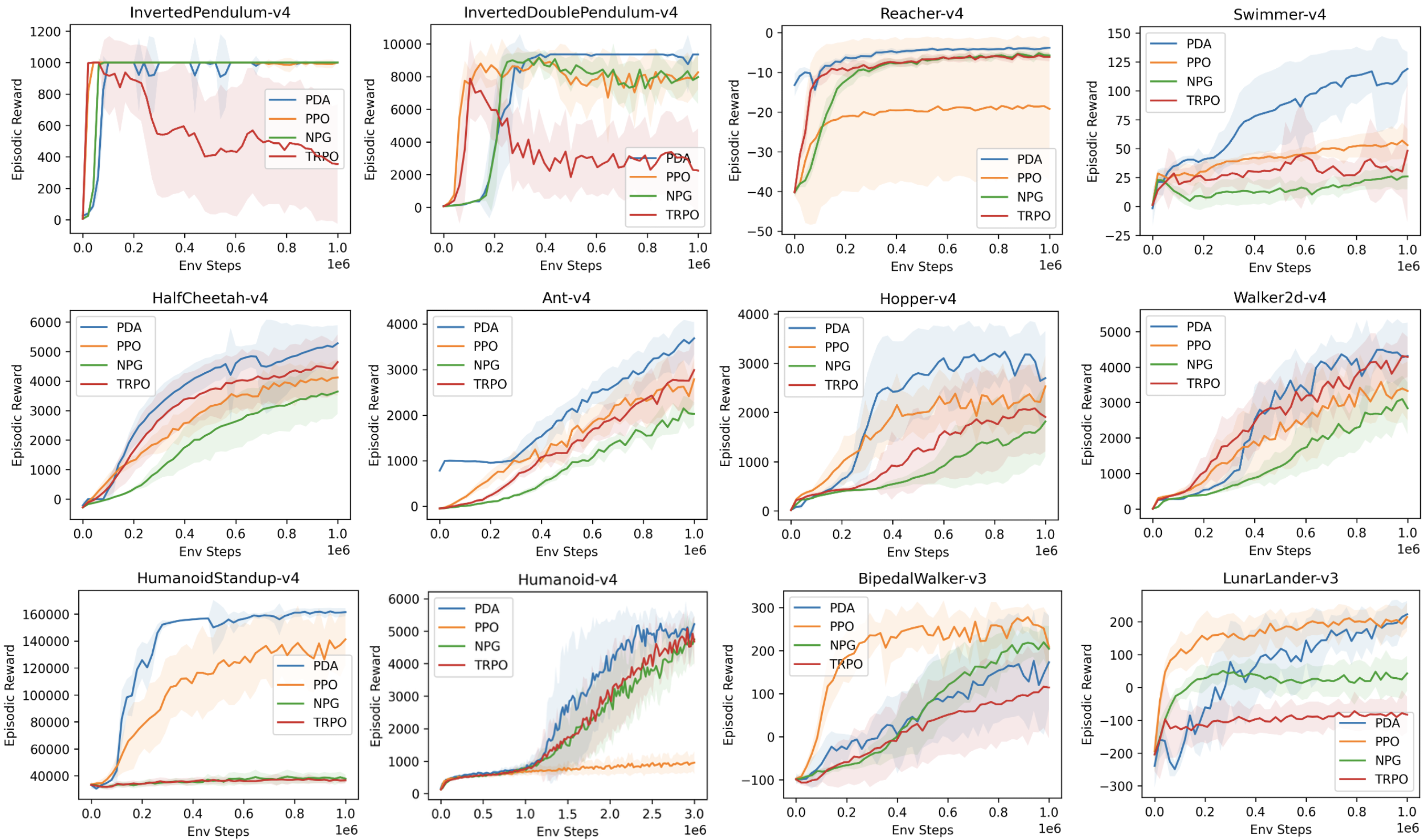
| Environment | NPG | PPO | TRPO | PDA |
|---|---|---|---|---|
| HalfCheetah-v4 | 3556.4 ± 837.9 | 4067.5 ± 572.3 | 4496.8 ± 969.7 | 5174.6 ± 686.7 |
| Ant-v4 | 2002.5 ± 300.6 | 2589.5 ± 445.8 | 2807.1 ± 645.5 | 3568.2 ± 449.7 |
| Hopper-v4 | 1650.8 ± 726.4 | 2329.7 ± 572.9 | 2017.0 ± 849.0 | 2944.3 ± 787.4 |
| Walker2d-v4 | 2923.2 ± 707.2 | 3277.0 ± 762.6 | 4128.8 ± 638.1 | 4367.1 ± 915.9 |
| InvertedPendulum-v4 | 1000.0 ± 0.0 | 993.3 ± 20.2 | 380.3 ± 391.6 | 1000.0 ± 0.0 |
| InvertedDoublePendulum-v4 | 7967.2 ± 1205.3 | 7926.8 ± 1241.8 | 2723.4 ± 2393.5 | 9167.5 ± 552.6 |
| Reacher-v4 | -5.7 ± 0.9 | -18.7 ± 17.5 | -6.1 ± 1.0 | -4.0 ± 0.4 |
| Swimmer-v4 | 25.1 ± 9.7 | 54.2 ± 14.2 | 35.0 ± 28.3 | 111.3 ± 29.7 |
| Humanoid-v4 (1M) | 745.1 ± 141.4 | 669.2 ± 107.4 | 719.5 ± 107.0 | 760.1 ± 139.9 |
| Humanoid-v4 (3M) | 4650.6 ± 686.8 | 933.3 ± 294.5 | 4745.1 ± 592.5 | 5020.0 ± 501.5 |
| HumanoidStandup-v4 | 38364.7 ± 3926.9 | 135853.7 ± 21036.7 | 36737.7 ± 2413.4 | 161184.5 ± 3275.5 |
| LunarLander-v3 | 34.1 ± 59.5 | 204.4 ± 44.7 | -83.0 ± 53.3 | 204.7 ± 54.6 |
| BipedalWalker-v3 | 212.3 ± 39.8 | 251.6 ± 44.8 | 106.3 ± 103.0 | 149.0 ± 117.4 |
| NewsvendorEnv-v0 (3M) | -1.0e7 ± 2.3e7 | -37225.9 ± 48015.8 | -5.3e7 ± 10.0e7 | 21857.9 ± 11382.1 |
| PortfolioOptEnv-v0 | 10095.3 ± 1522.9 | 10062.3 ± 1230.8 | 10195.6 ± 1496.7 | 10550.9 ± 1277.1 |
| InvManagementBacklogEnv-v0 | 430.4 ± 31.0 | 496.4 ± 6.8 | 397.5 ± 25.4 | 491.6 ± 11.8 |
| InvManagementLostSalesEnv-v0 | 431.5 ± 7.0 | 447.4 ± 16.8 | 432.3 ± 8.8 | 472.3 ± 10.3 |
Comparison with off-policy methods: PDA is an on-policy algorithm yet remains competitive with SAC and TD3 on many tasks, with 10–40× faster wall-clock time.
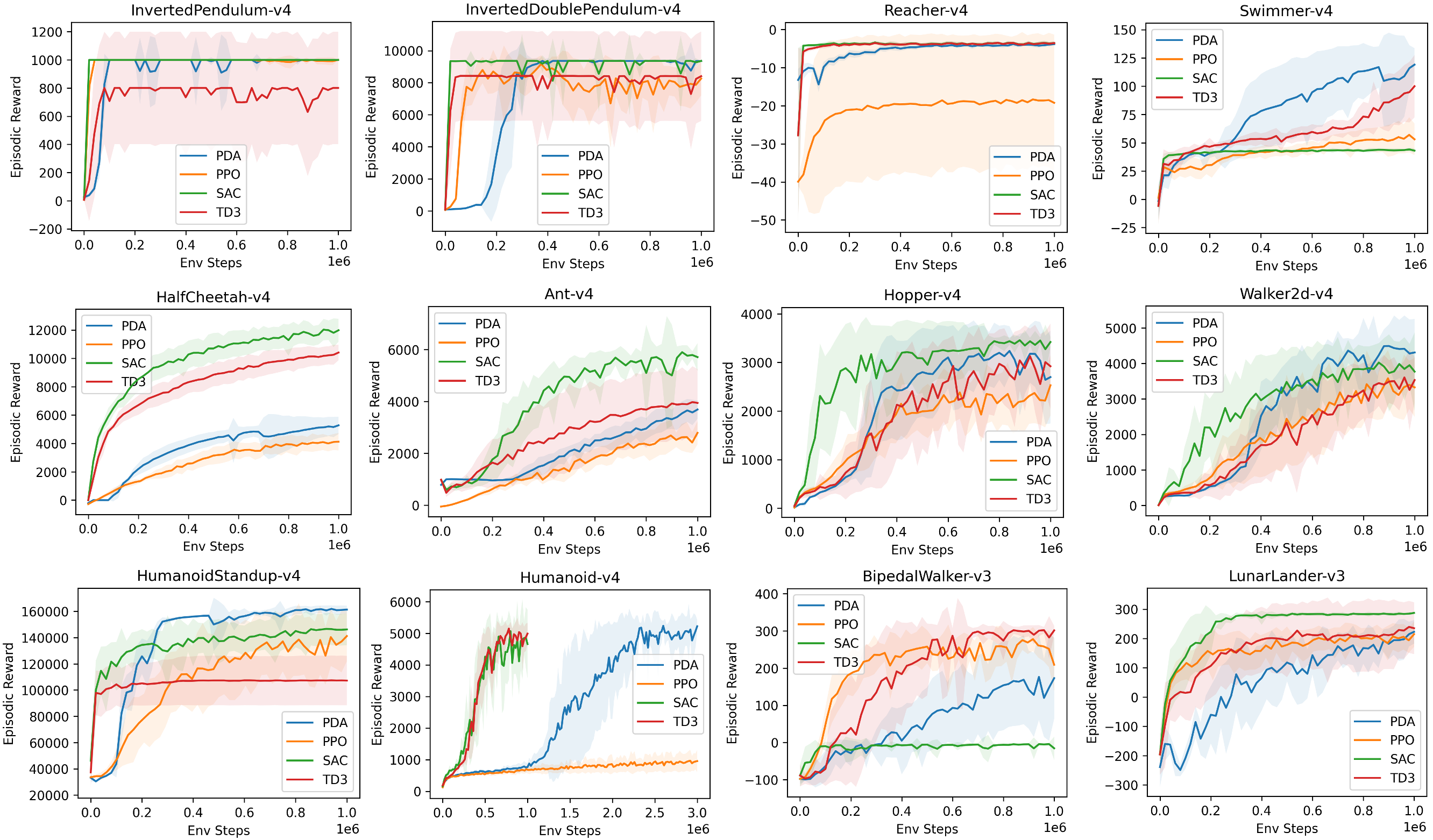
| Environment | SAC | TD3 | PPO | PDA |
|---|---|---|---|---|
| HalfCheetah-v4 | 11892.1 ± 789.8 | 10228.4 ± 636.2 | 4067.5 ± 572.3 | 5174.6 ± 686.7 |
| Ant-v4 | 5764.8 ± 358.6 | 3914.1 ± 1330.9 | 2589.5 ± 445.8 | 3568.2 ± 449.7 |
| Hopper-v4 | 3387.0 ± 205.7 | 2896.6 ± 801.0 | 2329.7 ± 572.9 | 2944.3 ± 787.4 |
| Walker2d-v4 | 3864.3 ± 816.6 | 3435.5 ± 712.5 | 3277.0 ± 762.6 | 4367.1 ± 915.9 |
| InvertedPendulum-v4 | 1000.0 ± 0.0 | 783.5 ± 401.9 | 993.3 ± 20.2 | 1000.0 ± 0.0 |
| InvertedDoublePendulum-v4 | 9183.2 ± 524.0 | 8134.8 ± 2914.5 | 7926.8 ± 1241.8 | 9167.5 ± 552.6 |
| Reacher-v4 | -3.6 ± 0.4 | -3.7 ± 0.5 | -18.7 ± 17.5 | -4.0 ± 0.4 |
| Swimmer-v4 | 43.5 ± 1.5 | 93.3 ± 25.2 | 54.2 ± 14.2 | 111.3 ± 29.7 |
| Humanoid-v4 (1M) | 4785.3 ± 953.5 | 4846.9 ± 437.6 | 669.2 ± 107.4 | 760.1 ± 139.9 |
| HumanoidStandup-v4 | 146249.0 ± 12118.1 | 107311.1 ± 18845.0 | 135853.7 ± 21036.7 | 161184.5 ± 3275.5 |
| LunarLander-v3 | 284.6 ± 5.1 | 229.0 ± 98.1 | 204.4 ± 44.7 | 204.7 ± 54.6 |
| BipedalWalker-v3 | -9.1 ± 14.2 | 295.2 ± 23.9 | 251.6 ± 44.8 | 149.0 ± 117.4 |
| NewsvendorEnv-v0 | -19212.1 ± 4213.5 | -19758.2 ± 3821.4 | -1.9e5 ± 4.1e5 | -1.5e5 ± 1.9e5 |
| PortfolioOptEnv-v0 | 9010.2 ± 1255.1 | — | 10062.3 ± 1230.8 | 10550.9 ± 1277.1 |
| InvManagementBacklogEnv-v0 | 281.8 ± 37.9 | -1575.7 ± 665.3 | 496.4 ± 6.8 | 491.6 ± 11.8 |
| InvManagementLostSalesEnv-v0 | 356.5 ± 13.0 | -311.9 ± 469.4 | 447.4 ± 16.8 | 472.3 ± 10.3 |
Algorithm runtime on MuJoCo-v4: Average runtime (5 parallel runs) for 1M environment steps of training and testing. GPU is used for off-policy methods (SAC and TD3) for acceleration due to larger neural network sizes. Times are reported in seconds (mean ± standard deviation). Hardware: 14700K, RTX 4070.
| Algorithm | MuJoCo-v4 (w/o humanoid) | MuJoCo-v4 (humanoid variants) |
|---|---|---|
| PDA | 423.4 ± 104.8 (1.00x) | 1480.7 ± 178.2 (1.00x) |
| PPO | 932.1 ± 120.1 (2.20x) | 1960.8 ± 167.2 (1.32x) |
| NPG | 344.1 ± 108.4 (0.81x) | 1011.3 ± 137.0 (0.68x) |
| TRPO | 349.5 ± 112.6 (0.83x) | 1009.6 ± 127.6 (0.68x) |
| SAC | 20335.9 ± 1878.3 (48.03x) | 19531.4 ± 2181.6 (13.19x) |
| TD3 | 11571.7 ± 510.6 (27.33x) | 29113.7 ± 596.8 (19.66x) |
Installation
Install with:
pip install pdarl
pip install "pdarl[mujoco]" # MuJoCo envs
pip install "pdarl[track]" # Weights & Biases
pip install "pdarl[all]" # MuJoCo + W&B
For other envs, see Gymnasium for installation details.
Quickstart
Copy the config folder or create your own and train actor-accelerated PDA (default) with a config file:
pdarl-run --config config/pda_act.yaml
Use the config files for other PDA variants and PMD:
pdarl-run --config config/pda_opt_rgd.yaml
pdarl-run --config config/pda_opt_acfgm.yaml
pdarl-run --config config/pda_bcd.yaml
pdarl-run --config config/pda_dsc.yaml
pdarl-run --config config/pmd_act.yaml
Customization
To customize the agents and training process, customize agents like PDA_ACT and Trainer class directly. See pdarl/trainer.py for more details.
import numpy as np
from pdarl.utils.args import load_args_from_yaml
from pdarl.trainer import Trainer
from pdarl import PDA_ACT
args = load_args_from_yaml("config/pda_act.yaml")
class CustomPDA(PDA_ACT):
# Override agent for custom behavior
def __init__(self, obs_dim, act_dim, args, device):
super().__init__(obs_dim, act_dim, args, device)
print("Custom PDA initialized!")
def compute_act(self, obs):
return super().compute_act(obs)
class CustomTrainer(Trainer):
# Override trainer setup to use CustomPDA
def _setup_agent(self):
obs_space = self.env.env.observation_space
act_space = self.env.env.action_space
obs_dim = int(np.array(obs_space.shape).prod())
act_dim = int(np.prod(act_space.shape))
self.agent = CustomPDA(obs_dim, act_dim, self.args, self.device).to(self.device)
print("Custom Trainer agent changed to CustomPDA!")
trainer = CustomTrainer(args)
trainer.setup()
trainer.run()
Logging
When logging: true (default), TensorBoard scalars are written under runs/. View them with:
tensorboard --logdir runs
Set track: true in a config file to log to Weights & Biases (wandb_project_name, wandb_entity).
Agents
agent_name |
Description |
|---|---|
PDA_ACT |
PDA with actor acceleration: a learned policy network approximates the action subproblem (default). |
PDA_DSC |
PDA for native discrete action spaces. |
PDA_OPT |
Direct subproblem optimization per action via randomized gradient descent (RGD) or Auto-Conditioned Fast Gradient Method (AC-FGM). |
PDA_BCD |
Direct subproblem optimization per action via Block-Coordinate Descent (BCD) on a discretized action grid. |
PMD_ACT |
Policy Mirror Descent (PMD) with actor acceleration. |
Key configs
See pdarl/utils/args.py and the files under config for the full schema.
| Parameter | Role |
|---|---|
exp_name |
Experiment name used for logging and tracking |
agent_name |
Agent variant (see table above) |
seed |
Random seed for reproducibility |
torch_deterministic |
Whether to use deterministic PyTorch operations |
device |
Compute device for training (e.g., cpu, cuda, or mps) |
logging |
Enable or disable TensorBoard logging |
env_id |
Gymnasium environment id |
env_kargs |
Additional keyword arguments for the environment |
total_timesteps |
Training horizon in environment steps |
learning_rate |
Base learning rate for neural network optimizers |
num_envs, num_steps |
Number of parallel environments and steps per rollout |
num_test_envs |
Number of parallel environments used for evaluation |
test_interval |
How often (in epochs) to run evaluation tests |
anneal_lr |
Whether to linearly anneal the learning rate during training |
gamma, gae_lambda |
Discount factor and Generalized Advantage Estimation lambda |
num_minibatches, update_epochs |
Minibatch splits and number of optimizer passes per rollout |
hidden_sizes, activation |
MLP architecture for value / sum-advantage / actor |
max_grad_norm |
Maximum gradient norm for clipping |
obs_norm, ret_norm, adv_norm |
Observation, return, and advantage normalization |
recompute_ret |
Recompute returns based on value function during updates |
step_size |
PDA regularization coefficient |
act_noise |
Exploration noise scale on actions |
action_opt |
For PDA_OPT: RGD or ACFGM |
action_opt_itr |
Iterations for PDA_OPT / PDA_BCD inner solves |
action_opt_params |
Parameters for the inner action solver |
discretization |
Grid resolution for PDA_BCD |
To cite this repository
@misc{gao2026actorpda,
title={Actor-Accelerated Policy Dual Averaging for Reinforcement Learning in Continuous Action Spaces},
author={Gao, Ji and Ju, Caleb and Lan, Guanghui and Tong, Zhaohui},
year={2026},
eprint={2603.10199},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2603.10199}
}
@misc{ju2022policyoptimizationgeneralstate,
title={Policy Optimization over General State and Action Spaces},
author={Ju, Caleb and Lan, Guanghui},
year={2022},
eprint={2211.16715},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2211.16715}
}
References
@article{huang2022cleanrl,
author = {Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo},
title = {CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms},
journal = {Journal of Machine Learning Research},
year = {2022},
volume = {23},
number = {274},
pages = {1--18},
url = {http://jmlr.org/papers/v23/21-1342.html}
}
@article{weng2022tianshou,
title = {Tianshou: A Highly Modularized Deep Reinforcement Learning Library},
author = {Weng, Jiayu and Chen, Hang and Yan, Dong and You, Kaiwen and Zhang, Chen and Gong, Yunchang and Zhu, Rongqing and Li, Sijin and Zhou, Yiwen and Liu, Qian and Song, Yueyang},
journal = {Journal of Machine Learning Research},
year = {2022},
volume = {23},
number = {267},
pages = {1--6},
url = {http://jmlr.org/papers/v23/21-1127.html}
}
@misc{towers2024gymnasium,
author = {Towers, Mark and Kwiatkowski, Ariel and Terry, Jordan and Balis, John U and De Cola, Gianluca and Deleu, Tristan and Goul{\~a}o, Manuel and Kallinteris, Andreas and Krimmel, Markus and KG, Arjun and others},
title = {Gymnasium: A Standard Interface for Reinforcement Learning Environments},
year = {2024},
eprint = {arXiv:2407.17032}
}
@misc{HubbsOR-Gym,
author={Christian D. Hubbs and Hector D. Perez and Owais Sarwar and Nikolaos V. Sahinidis and Ignacio E. Grossmann and John M. Wassick},
title={OR-Gym: A Reinforcement Learning Library for Operations Research Problems},
year={2020},
Eprint={arXiv:2008.06319}
}
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pdarl-0.1.0.tar.gz.
File metadata
- Download URL: pdarl-0.1.0.tar.gz
- Upload date:
- Size: 2.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
be95a212f6d8ba8b1797e45b258dd231cca5d7422e9f40206d7a79ecce56ea41
|
|
| MD5 |
6f6bc9b50f0c7b42e3828ffa50dd9d20
|
|
| BLAKE2b-256 |
7016297e28a20868c79cf81d4a66502099f04eced188f58db1ec58324c694144
|
Provenance
The following attestation bundles were made for pdarl-0.1.0.tar.gz:
Publisher:
workflow.yml on JGIoA/pdarl
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pdarl-0.1.0.tar.gz -
Subject digest:
be95a212f6d8ba8b1797e45b258dd231cca5d7422e9f40206d7a79ecce56ea41 - Sigstore transparency entry: 1615240487
- Sigstore integration time:
-
Permalink:
JGIoA/pdarl@7326c97d7a6a4526f168d60fea6c60816cb6dc8c -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/JGIoA
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
workflow.yml@7326c97d7a6a4526f168d60fea6c60816cb6dc8c -
Trigger Event:
push
-
Statement type:
File details
Details for the file pdarl-0.1.0-py3-none-any.whl.
File metadata
- Download URL: pdarl-0.1.0-py3-none-any.whl
- Upload date:
- Size: 32.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
87575874c6d5cd7ba4c35a990c872d7702f6a707a1f7a4091b1dcf4fb90e9b38
|
|
| MD5 |
2894af79fcdfb61627e2aebd98095e77
|
|
| BLAKE2b-256 |
310fde763db2e7cbabfb623a75ffaedbd5cd01ee399cca64e3d34f811003f003
|
Provenance
The following attestation bundles were made for pdarl-0.1.0-py3-none-any.whl:
Publisher:
workflow.yml on JGIoA/pdarl
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pdarl-0.1.0-py3-none-any.whl -
Subject digest:
87575874c6d5cd7ba4c35a990c872d7702f6a707a1f7a4091b1dcf4fb90e9b38 - Sigstore transparency entry: 1615240498
- Sigstore integration time:
-
Permalink:
JGIoA/pdarl@7326c97d7a6a4526f168d60fea6c60816cb6dc8c -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/JGIoA
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
workflow.yml@7326c97d7a6a4526f168d60fea6c60816cb6dc8c -
Trigger Event:
push
-
Statement type:







