Local-first MCP server and CLI for turning PDFs into source-linked HTML readers with notes, highlights, and static publishing.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
PDF Card MCP





PDF Card MCP is a local-first MCP server and CLI for turning dense local PDFs into portable, source-linked HTML readers. An MCP host can ask it to convert a PDF path, validate notes/highlights, or publish a static annotated reader bundle. The converter preserves source text, renders source pages for verification, crops detected tables, figures, and display formulas as images, derives safe reader styling from the original PDF palette, and writes a standalone HTML file that can be moved across devices without losing assets.
Default conversion runs locally and does not require a hosted service. Optional MCP sampling is deliberately bounded: the host model may choose validated style tokens or suggest card-boundary polish operations, but raw CSS and source-text rewrites are rejected.
The default reader is designed for comfortable reading: large type, small cards, search, section navigation, next/previous controls, keyboard navigation, a font-size slider, and source-page previews.
PDF Card MCP is meant for PDFs you actually need to read, cite, or inspect. It turns long documents into smaller source-linked cards, keeps tables/figures/formulas as faithful image crops, and lets you export your own notes and highlights as Markdown.
Real Screenshots
These screenshots are from a generated reader for Agents in Software Engineering and the same source PDF opened side by side for comparison.
| Generated reader | Original PDF |
|---|---|
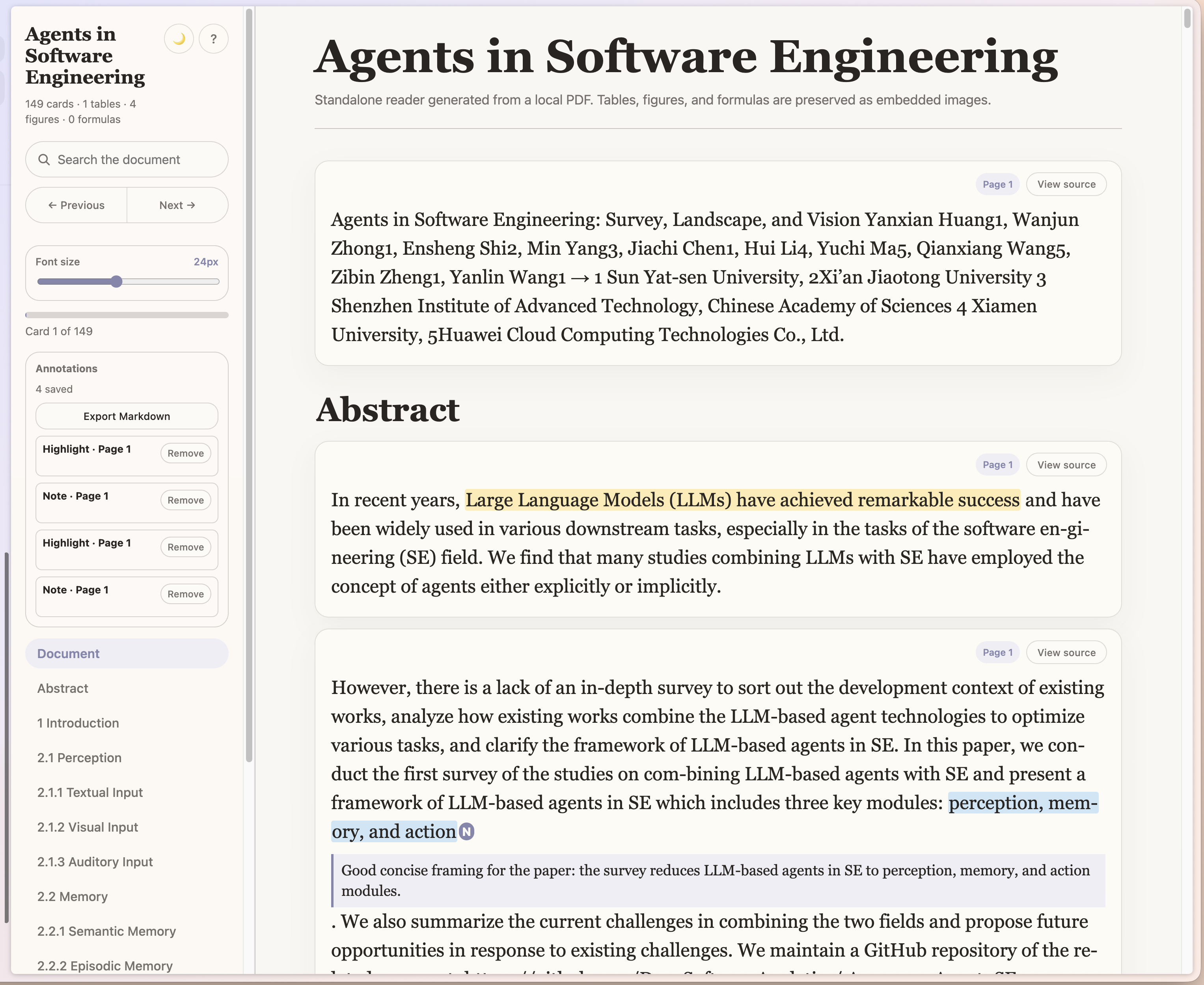 |
 |
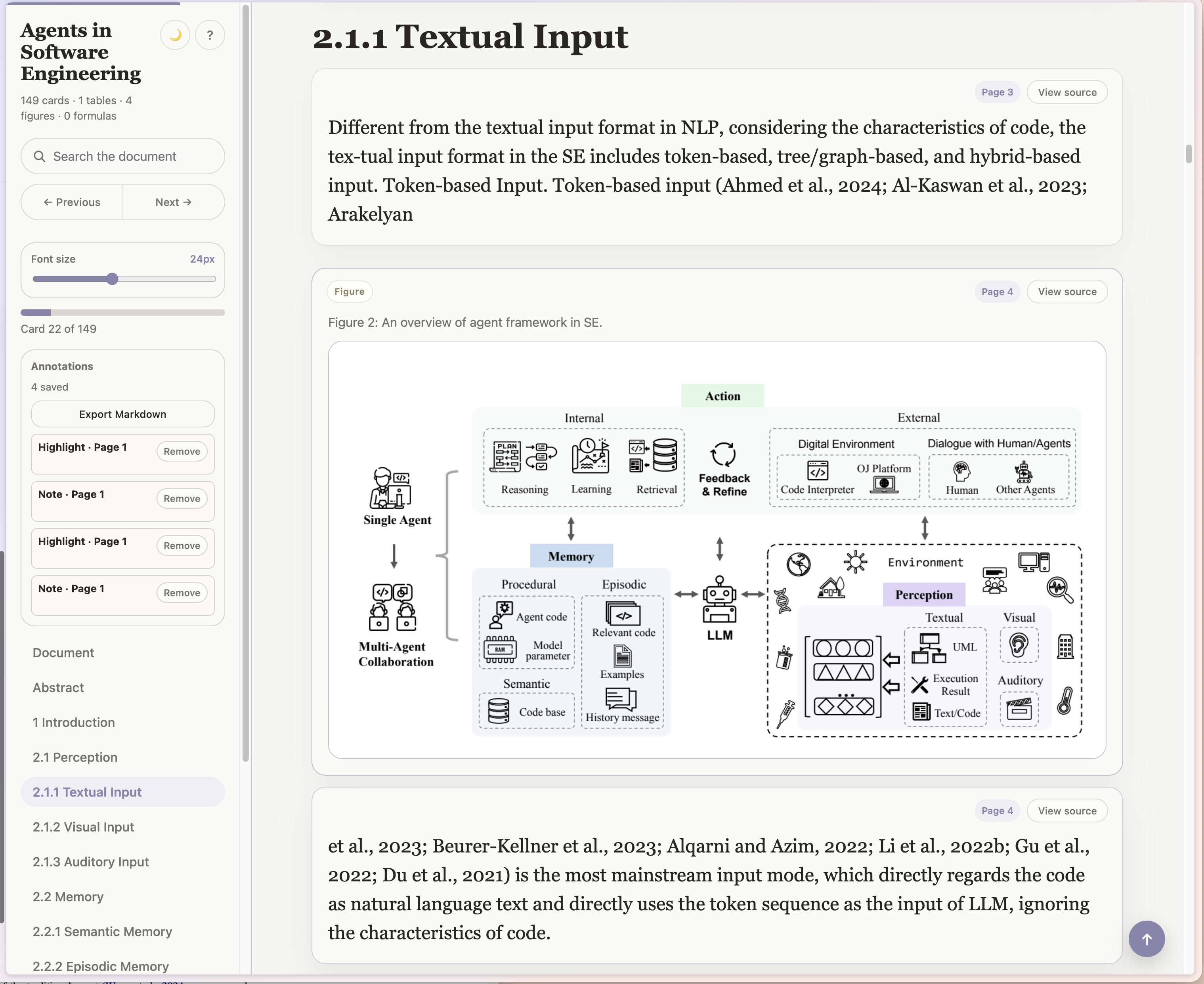 |
 |
Quick Examples
Convert a local PDF into one portable HTML reader:
pdf-card-mcp ./paper.pdf --output ./out/paper-reader.html
Use the explicit subcommand form with PDF-derived styling:
pdf-card-mcp convert ./paper.pdf \
--output ./out/paper-reader.html \
--style-engine pdf
Run the MCP server so a compatible host can generate readers from local PDF paths:
python -m pdf_card_mcp.server
Publish a read-only static reader with selected public annotations:
pdf-card-mcp publish ./out/paper-reader.html \
--annotations ./paper.annotations.json \
--output ./published/paper-reader.html
Output At A Glance
| Output | What it contains |
|---|---|
paper-reader.html |
Standalone reader with embedded CSS, JavaScript, page images, and detected crops. |
paper.manifest.json |
Structured metadata for cards, pages, warnings, and source anchors. |
| Markdown export | User-authored notes and highlights from the reader UI. |
| Published bundle | Read-only static HTML or a directory bundle for sharing public annotations. |
Status
This is an early open-source implementation. It is useful for text-layer PDFs now, with
best-effort table detection via pdfplumber, permissive raster rendering via pypdfium2,
and optional richer local table detection via gmft. Scanned PDFs need optional OCR support.
Install
From PyPI after the first public package release:
python -m pip install pdf-card-mcp
Until that release is published, install directly from the repository:
python -m pip install "pdf-card-mcp @ git+https://github.com/velyan/pdf-card-mcp.git"
For local development:
git clone https://github.com/velyan/pdf-card-mcp.git
cd pdf-card-mcp
python3 -m venv .venv
. .venv/bin/activate
python3 -m pip install -e ".[dev]"
uv is recommended for MCPB packaging:
uv sync
uv run pdf-card-mcp path/to/document.pdf --output out/document.html
Install the optional local ML table detector when you want stronger table crops:
uv sync --extra table-ml
uv run --extra table-ml pdf-card-mcp path/to/document.pdf --table-engine gmft
Use In An MCP Client
After the package is available on PyPI, add it to Claude Code or another CLI-compatible MCP
client with uvx:
claude mcp add pdf-card -- uvx --from pdf-card-mcp pdf-card-mcp-server
Generic MCP host configuration:
{
"mcpServers": {
"pdf-card": {
"command": "uvx",
"args": ["--from", "pdf-card-mcp", "pdf-card-mcp-server"]
}
}
}
For local development before the PyPI release, point the client at this checkout:
{
"mcpServers": {
"pdf-card-local": {
"command": "uv",
"args": [
"--directory",
"/path/to/pdf-card-mcp",
"run",
"python",
"-m",
"pdf_card_mcp.server"
]
}
}
}
Claude Desktop can also install the .mcpb bundle from the latest GitHub release.
Docker / Registry Scanners
The repository includes a minimal Dockerfile so registries such as Glama can build the
server, start it over stdio, and inspect its MCP tool schemas. The server still works on local
file paths, so container users must mount any PDFs and output directories they want the tool to
read or write:
docker build -t pdf-card-mcp .
docker run --rm -i \
-v "$PWD/examples:/docs" \
pdf-card-mcp
CLI Usage
pdf-card-mcp path/to/document.pdf --output examples/out/document.html
The command writes:
document.html: standalone reader with embedded CSS, JavaScript, table crops, figure crops, formula crops, and source-page images.document.manifest.json: structured metadata without embedded image payloads.
The explicit subcommand form is also supported:
pdf-card-mcp convert path/to/document.pdf --output examples/out/document.html
Notes, Highlights, And Static Publishing
Generated readers include a local annotation overlay:
- A highlight is selected source text.
- A note is selected source text plus your own typed note text.
Select text in a text card, choose Highlight or Note, and use Export Markdown to download
a readable .annotations.md file. Import is intentionally not exposed in the reader UI yet.
Notes and highlights are user-authored data and are kept separate from the source-derived
document.manifest.json.
The lower-level CLI and MCP publishing tools still accept a structured annotation bundle when you need to build a read-only static reader with embedded annotations. Validate that bundle against a reader:
pdf-card-mcp validate-annotations examples/out/document.html document.annotations.json
Publish a shareable static reader with public annotations:
pdf-card-mcp publish examples/out/document.html \
--annotations document.annotations.json \
--output published/document-reader.html
If --output is a directory instead of an .html file, the command writes a static bundle:
index.htmlreader.manifest.jsonreader.annotations.jsonbundle.json
Publishing includes only visibility: public annotations by default, redacts the local
source_pdf path by default, and renders the published reader read-only by default. Use
--include-private only when you intentionally want private local notes included in the
published output. Publishing fails if any included annotation cannot be anchored to the reader;
run validate-annotations to inspect mismatches before publishing.
MCP Tool
The MCP server is the automation layer around the same local converter. It accepts local file paths from an MCP client and returns generated reader paths, manifest metadata, warnings, and publishing/validation results.
The server exposes three tools:
convert_pdf_to_card_html
validate_reader_annotations
publish_reader_bundle
Inputs:
pdf_path: local PDF path.output_path: optional HTML output path.title: optional title override.standalone: defaults totrue; asset-folder output is reserved for a later release.ocr: optional OCR fallback ifpytesseractis installed.max_pages: optional processing limit.theme: defaults tosoft.style_engine:fixed,pdf, orsampling; defaults topdf.fixedpreserves the original soft palette,pdfderives bounded colors and typography hints locally from the source PDF, andsamplingasks the host LLM to choose validated style tokens from those local hints.table_engine:auto,pdfplumber, orgmft;autousesgmftwhen installed.text_engine:char_geometryorpdfplumber_words; defaults tochar_geometryso missing spaces are repaired from PDF character positions instead of trusting fused words.postprocess_engine:noneorsampling; defaults tonone. When set tosampling, the MCP server asks the host LLM for boundary-only card polish operations, validates exact source-text preservation, and rewrites the generated reader. If the MCP client does not support sampling, deterministic output is returned with a warning.model_cache_dir: optional cache directory for local ML table model weights.offline: use only already-cached optional ML models.
validate_reader_annotations checks a notes/highlights sidecar against a generated reader.
publish_reader_bundle writes a publish-ready static HTML file or directory bundle from an
existing generated reader and an optional annotation sidecar.
Sampling post-processing is intentionally narrow. For card boundaries, the host LLM may
suggest merges, heading extraction, or front-matter/footnote classification, but Python
validation rejects any operation that rewrites, deletes, invents, or reorders source text.
For style_engine=sampling, the host LLM may only choose bounded style tokens and palette
candidate IDs; it cannot return raw CSS, JavaScript, or arbitrary colors. If sampling is
unavailable, the reader keeps deterministic PDF-derived styling and returns a warning.
Run the server locally:
python -m pdf_card_mcp.server
MCPB Packaging
This repo is arranged so the root can be packed directly:
python scripts/build_mcpb.py --variant all
The slim bundle writes dist/pdf-card-mcp-lite.mcpb. The full-quality UV-powered bundle writes
dist/pdf-card-mcp.mcpb and installs the table-ml extra. Neither bundle vendors ML model
weights; gmft downloads and caches them locally on first use unless offline=true is set
with a prewarmed cache.
The MCPB manifests declare a Python runtime and execute through uv, so compatible hosts can
install dependencies from pyproject.toml instead of relying on a user-managed Python setup.
Privacy
Default PDF processing is local. The deterministic converter does not upload document contents or call external APIs. Optional OCR runs locally when the user has installed OCR dependencies.
When style_engine=sampling or postprocess_engine=sampling is enabled through MCP, the host
LLM may receive bounded style hints or card text snippets so it can return validated style-token
or boundary-operation plans. Use deterministic fixed/pdf style and postprocess_engine=none
when no document-derived text should leave the local process.
Published readers may contain extracted PDF text, source-page images, table/figure/formula crops, and any included public notes or highlights. Only publish generated readers when you have the rights to share the source document content and your annotations.
How It Works
See docs/how-it-works.html for a self-contained visual explainer
of the conversion pipeline, including page rendering, table/figure crops, overlap suppression,
text-card merging, and standalone HTML output.
How Tables Are Handled
All detected tables are rendered as image cards. The converter uses pdfplumber to find table
regions and can optionally use gmft/Table Transformer for stronger local detection. It then
uses pypdfium2 to rasterize only the source table region into PNG. Captions are preserved as
reader text and alt text, but the table itself remains an image so layout and numeric alignment
survive conversion.
If a document mentions tables but no reliable table regions are found, the manifest includes a warning so callers can decide whether to inspect the source pages.
How Formulas Are Handled
Display formulas are treated as image cards when the PDF exposes them as centered, formula-like text blocks. The extracted formula string is retained for alt/search metadata, but the reader shows the source crop so subscripts, superscripts, arrows, and math spacing remain faithful.
License
MIT
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pdf_card_mcp-0.1.2.tar.gz.
File metadata
- Download URL: pdf_card_mcp-0.1.2.tar.gz
- Upload date:
- Size: 364.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7d46da17752f98c8cb36fecd33d66ec0cfae9b1824b5defa0bdae06bf35abd1b
|
|
| MD5 |
5ee58118c782be531d0afcf198f291d8
|
|
| BLAKE2b-256 |
5d1912f390beaa2ec9253e877f5f978744290605238482b5d019ea2f5efb3a65
|
Provenance
The following attestation bundles were made for pdf_card_mcp-0.1.2.tar.gz:
Publisher:
publish-pypi.yml on velyan/pdf-card-mcp
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pdf_card_mcp-0.1.2.tar.gz -
Subject digest:
7d46da17752f98c8cb36fecd33d66ec0cfae9b1824b5defa0bdae06bf35abd1b - Sigstore transparency entry: 1816277551
- Sigstore integration time:
-
Permalink:
velyan/pdf-card-mcp@72daff4de45bd4df960cbbc901c1cd9047a33aa0 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/velyan
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@72daff4de45bd4df960cbbc901c1cd9047a33aa0 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file pdf_card_mcp-0.1.2-py3-none-any.whl.
File metadata
- Download URL: pdf_card_mcp-0.1.2-py3-none-any.whl
- Upload date:
- Size: 88.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0bf00d7ebf3f518f082128215fcc3ab537a5265e024e722f9eb2235549e1b007
|
|
| MD5 |
29a99d277ff72e1ff6e9bbaa88dcdc6e
|
|
| BLAKE2b-256 |
99d44c3fa1d1f9d519f7faf3b64bce63f85d3b6e6d9fd608dbc0ca1b0a28edad
|
Provenance
The following attestation bundles were made for pdf_card_mcp-0.1.2-py3-none-any.whl:
Publisher:
publish-pypi.yml on velyan/pdf-card-mcp
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pdf_card_mcp-0.1.2-py3-none-any.whl -
Subject digest:
0bf00d7ebf3f518f082128215fcc3ab537a5265e024e722f9eb2235549e1b007 - Sigstore transparency entry: 1816277830
- Sigstore integration time:
-
Permalink:
velyan/pdf-card-mcp@72daff4de45bd4df960cbbc901c1cd9047a33aa0 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/velyan
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@72daff4de45bd4df960cbbc901c1cd9047a33aa0 -
Trigger Event:
workflow_dispatch
-
Statement type:







