PDF craft can convert PDF files into various other formats. This project will focus on processing PDF files of scanned books.

Project description






Introduction
pdf-craft converts PDF files into various other formats, with a focus on handling scanned book PDFs.
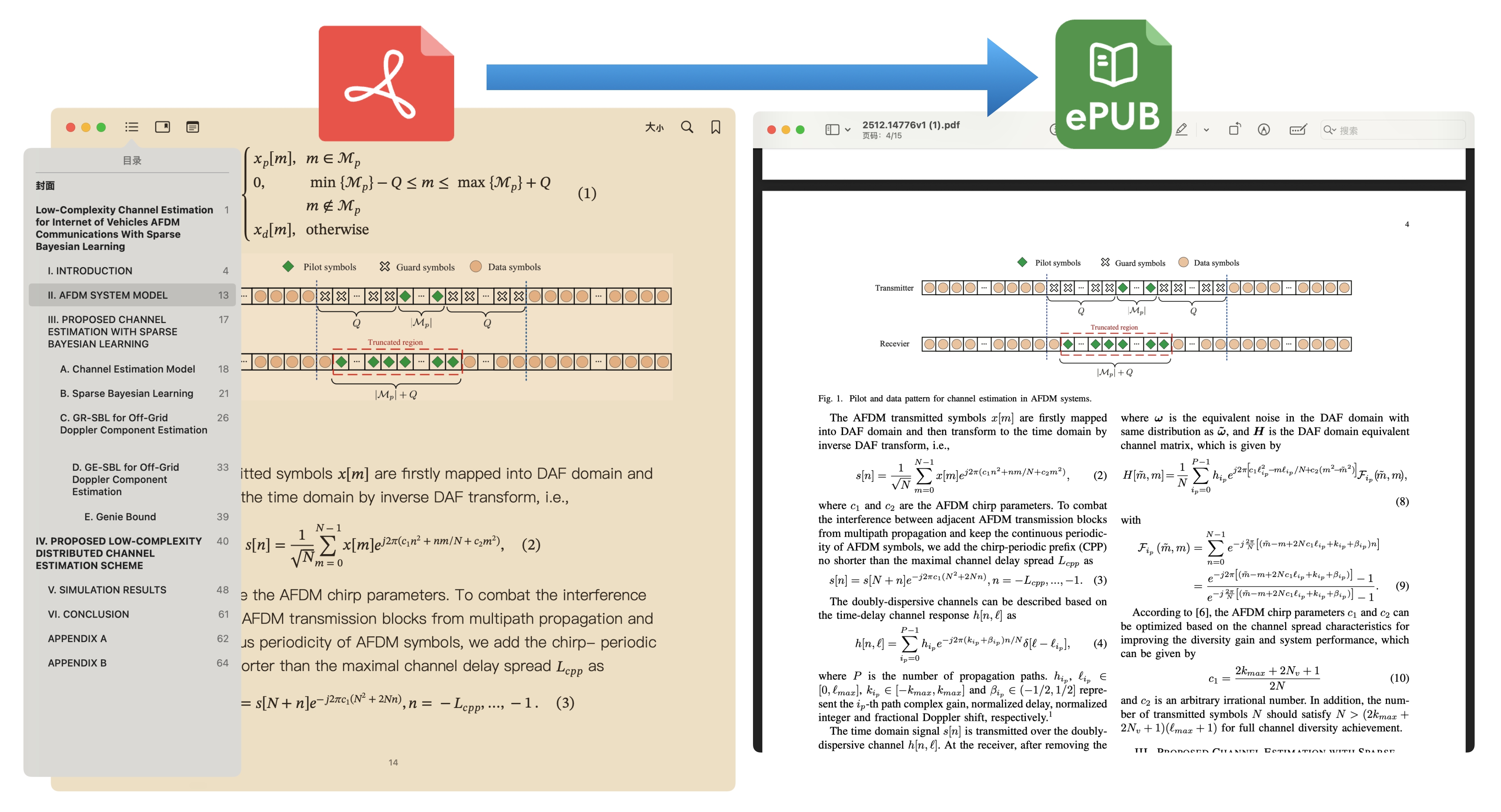
This project is based on DeepSeek OCR for document recognition. It supports the recognition of complex content such as tables and formulas. With GPU acceleration, pdf-craft can complete the entire conversion process from PDF to Markdown or EPUB locally. During the conversion, pdf-craft automatically identifies document structure, accurately extracts body text, and filters out interfering elements like headers and footers. For academic or technical documents containing footnotes, formulas, and tables, pdf-craft handles them properly, preserving these important elements (including images and other assets within footnotes). When converting to EPUB, the table of contents is automatically generated. The final Markdown or EPUB files maintain the content integrity and readability of the original book.
Lightweight and Fast
Starting from the official v1.0.0 release, pdf-craft fully embraces DeepSeek OCR and no longer relies on LLM for text correction. This change brings significant performance improvements: the entire conversion process is completed locally without network requests, eliminating the long waits and occasional network failures of the old version.
However, the new version has also removed the LLM text correction feature. If your use case still requires this functionality, you can continue using the old version v0.2.8.
Online Demo
We provide an online demo platform that lets you experience PDF Craft's conversion capabilities without any installation. You can directly upload PDF files and convert them.

Quick Start
Installation
pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu
pip install pdf-craft
The above commands are for quick setup only. To actually use pdf-craft, you need to install Poppler for PDF parsing (required for all use cases) and configure a CUDA environment for OCR recognition (required for actual conversion). Please refer to the Installation Guide for detailed instructions.
Quick Start
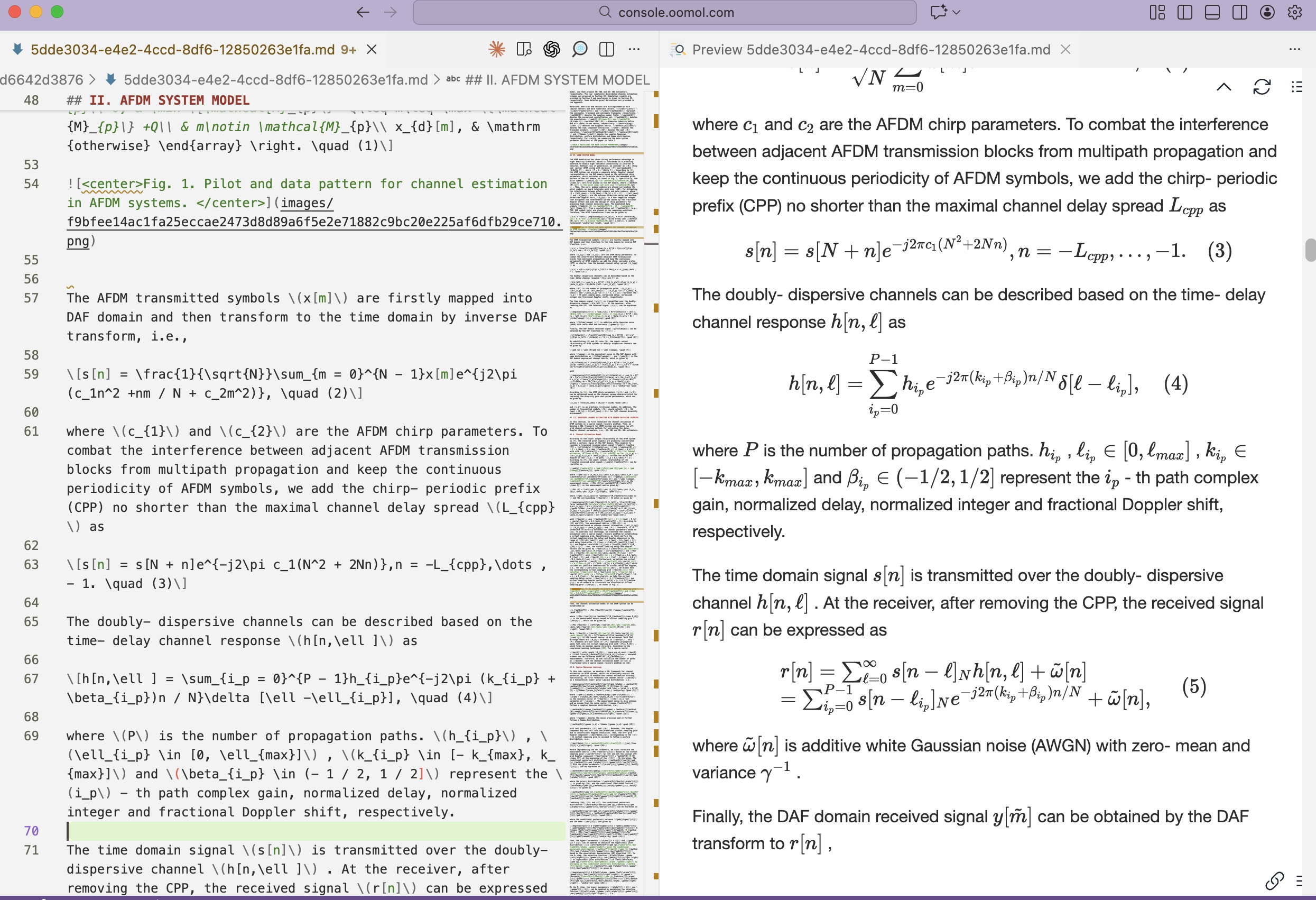
Convert to Markdown
from pdf_craft import transform_markdown
transform_markdown(
pdf_path="input.pdf",
markdown_path="output.md",
markdown_assets_path="images",
)
Convert to EPUB
from pdf_craft import transform_epub, BookMeta
transform_epub(
pdf_path="input.pdf",
epub_path="output.epub",
book_meta=BookMeta(
title="Book Title",
authors=["Author"],
),
)
Detailed Usage
Convert to Markdown
from pdf_craft import transform_markdown
transform_markdown(
pdf_path="input.pdf",
markdown_path="output.md",
markdown_assets_path="images",
analysing_path="temp", # Optional: specify temporary folder
ocr_size="gundam", # Optional: tiny, small, base, large, gundam
models_cache_path="models", # Optional: model cache path
includes_footnotes=True, # Optional: include footnotes
ignore_pdf_errors=False, # Optional: continue on PDF rendering errors
generate_plot=False, # Optional: generate visualization charts
toc_assumed=False, # Optional: assume PDF contains a table of contents page
)
Convert to EPUB
from pdf_craft import transform_epub, BookMeta, TableRender, LaTeXRender
transform_epub(
pdf_path="input.pdf",
epub_path="output.epub",
analysing_path="temp", # Optional: specify temporary folder
ocr_size="gundam", # Optional: tiny, small, base, large, gundam
models_cache_path="models", # Optional: model cache path
includes_cover=True, # Optional: include cover
includes_footnotes=True, # Optional: include footnotes
ignore_pdf_errors=False, # Optional: continue on PDF rendering errors
generate_plot=False, # Optional: generate visualization charts
toc_assumed=True, # Optional: assume PDF contains a table of contents page
book_meta=BookMeta(
title="Book Title",
authors=["Author 1", "Author 2"],
publisher="Publisher",
language="en",
),
lan="en", # Optional: language (zh/en)
table_render=TableRender.HTML, # Optional: table rendering method
latex_render=LaTeXRender.MATHML, # Optional: formula rendering method
inline_latex=True, # Optional: preserve inline LaTeX expressions
)
Model Management
pdf-craft depends on DeepSeek OCR models, which are automatically downloaded from Hugging Face on first run. You can control model storage and loading behavior through the models_cache_path and local_only parameters.
Pre-download Models
In production environments, it is recommended to download models in advance to avoid downloading on first run:
from pdf_craft import predownload_models
predownload_models(
models_cache_path="models", # Specify model cache directory
revision=None, # Optional: specify model version
)
Specify Model Cache Path
By default, models are downloaded to the system's Hugging Face cache directory. You can customize the cache location through the models_cache_path parameter:
from pdf_craft import transform_markdown
transform_markdown(
pdf_path="input.pdf",
markdown_path="output.md",
models_cache_path="./my_models", # Custom model cache directory
)
Offline Mode
If you have pre-downloaded the models, you can use local_only=True to disable network downloads and ensure only local models are used:
from pdf_craft import transform_markdown
transform_markdown(
pdf_path="input.pdf",
markdown_path="output.md",
models_cache_path="./my_models",
local_only=True, # Use local models only, do not download from network
)
API Reference
OCR Models
The ocr_size parameter accepts a DeepSeekOCRSize type:
tiny- Smallest model, fastest speedsmall- Small modelbase- Base modellarge- Large modelgundam- Largest model, highest quality (default)
Table Rendering Methods
TableRender.HTML- HTML format (default)TableRender.CLIPPING- Clipping format (directly clips table images from the original PDF scan)
Formula Rendering Methods
LaTeXRender.MATHML- MathML format (default)LaTeXRender.SVG- SVG formatLaTeXRender.CLIPPING- Clipping format (directly clips formula images from the original PDF scan)
Inline LaTeX
The inline_latex parameter (EPUB only, default: True) controls whether to preserve inline LaTeX expressions in the output. When enabled, inline mathematical formulas are preserved as LaTeX code, which can be rendered by compatible EPUB readers.
Table of Contents Detection
The toc_assumed parameter controls whether pdf-craft should assume the PDF contains a table of contents page:
- When
True(default for EPUB): pdf-craft attempts to locate and extract the table of contents from within the PDF, using it to build the document structure - When
False(default for Markdown): pdf-craft generates the table of contents based on document headings only
For books with a dedicated table of contents section, setting toc_assumed=True typically produces better chapter organization.
Custom PDF Handler
By default, pdf-craft uses Poppler (via pdf2image) for PDF parsing and rendering. If Poppler is not in your system PATH, you can specify a custom path:
from pdf_craft import transform_markdown, DefaultPDFHandler
# Specify custom Poppler path
transform_markdown(
pdf_path="input.pdf",
markdown_path="output.md",
pdf_handler=DefaultPDFHandler(poppler_path="/path/to/poppler/bin"),
)
If not specified, pdf-craft will use Poppler from your system PATH. For advanced use cases, you can also implement the PDFHandler protocol to use alternative PDF libraries.
Error Handling
You can use ignore_pdf_errors=True to continue processing when individual pages fail to render, inserting a placeholder message for failed pages instead of stopping the entire conversion.
Related Open Source Libraries
epub-translator uses AI large language models to automatically translate EPUB e-books while 100% preserving the original book's format, illustrations, table of contents, and layout. It also generates bilingual versions for convenient language learning or international sharing. When combined with this library, you can convert and translate scanned PDF books. For a demonstration, see this video: Convert PDF scanned books to EPUB format and translate to bilingual books.
License
This project is licensed under the MIT License. See the LICENSE file for details.
Starting from v1.0.0, pdf-craft has fully migrated to DeepSeek OCR (MIT license), removing the previous AGPL-3.0 dependency, allowing the entire project to be released under the more permissive MIT license. Note that pdf-craft has a transitive dependency on easydict (LGPLv3) via DeepSeek OCR. Thanks to the community for their support and contributions!
Acknowledgments
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pdf_craft-1.0.4.tar.gz.
File metadata
- Download URL: pdf_craft-1.0.4.tar.gz
- Upload date:
- Size: 57.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.3 CPython/3.13.4 Darwin/25.1.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4e397e5f2c965986f71c1ae7c56f37eb94df2afb06769e6261bd9715399d19ad
|
|
| MD5 |
a034d6a9d09e1528481a63cf5aa27b17
|
|
| BLAKE2b-256 |
cb4787792598e83a8fbeda5fd1b55b13a35988632bba1c5bee6b8c5f486640d3
|
File details
Details for the file pdf_craft-1.0.4-py3-none-any.whl.
File metadata
- Download URL: pdf_craft-1.0.4-py3-none-any.whl
- Upload date:
- Size: 70.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.3 CPython/3.13.4 Darwin/25.1.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fdf154136c41274c1e7e2981f11090fc84455ce9a68ae75e65c74baefd062dd8
|
|
| MD5 |
65902a29eca6723d24283dec2d9dd5e9
|
|
| BLAKE2b-256 |
a1491f8d920fcb740935fa76d18ac4ab03b2d498cad0ce4865a51f9df9ed8858
|







