Analyze PDFs with colors (and YARA). Visualize a PDF's inner tree-like data structure, check it against a library of YARA rules, force decodes of suspicious font binaries, and more.

Project description






THE PDFALYZER
A PDF analysis tool for visualizing the inner tree-like data structure[^1] of a PDF in spectacularly large and colorful diagrams as well as scanning the binary streams embedded in the PDF for hidden potentially malicious content. The Pdfalyzer makes heavy use of YARA (via The Yaralyzer) for matching/extracting byte patterns.
PyPi Users: This document renders a lot better on GitHub. Pictures, footnotes, etc.
Quick Start
You can use pip but pipx is a cleaner way to install for normal users. Developers should probably use poetry.
# If you don't care about extracting text, encrypted PDFs, images, etc. just do this:
pipx install pdfalyzer
# Or if you want to open encrypted PDFs or use the tools that ship with Pdfalyzer (e.g. extract_pdf_text):
pipx install pdfalyzer[extract]
# Then pdfalyze to your hearts content:
pdfalyze martin_heidegger-being_illmatic.pdf
# Consult the help screen if needed:
pdfalyze -h
# (Optional) Forcibly extract all text (including from embedded images) from a file:
extract_pdf_text martin_heidegger-being_illmatic.pdf
What It Do
- Generate in depth visualizations of PDF tree structures[^1]. Shows every property of every PDF object at a glance. See the Example Output section below for details.
- Scan for mad sus content with a bunch of PDF specific YARA rules.
- Forcibly decode suspect bytes. The Yaralyzer does the heavy lifting.
- Display detailed information about embedded fonts. With character maps.
- Extract pages and/or text (including from embedded images) with the included command line tools.
- Usable as a library for your own PDF related code.
If you're looking for one of these things this may be the tool for you.
What It Don't Do
This tool is mostly for examining/working with a PDF's data and logical structure. As such it doesn't have much to offer as far as extracting text, rendering[^3], writing, etc. etc.
If you suspect you are dealing with a malcious PDF you can safely run pdfalyze on it. Embedded javascript and /OpenAction nodes etc. will not be executed. If you want to actually look at the contents of a suspect PDF you can use dangerzone to sanitize the contents with extreme prejudice before opening it.
Installation
All Platforms
Installation with pipx[^4] is preferred though pip3 / pip should also work.
pipx install pdfalyzer
macOS Homebrew
If you are on macOS and use homebrew someone out there was kind enough to make Pdfalyzer available via homebrew so this should work:
brew install pdfalyzer
Troubleshooting
- If you used
pip3instead ofpipxand have an issue you should try to install withpipx. - If you run into an issue about missing YARA try to install yara-python.
- If you encounter an error building the python
cryptographypackage check yourpipversion (pip --version). If it's less than 22.0, upgradepipwithpip install --upgrade pip. - If you can't get the
pdfalyzecommand to work trypython -m pdfalyzer. It's an equivalent but more portable version of the same command that does not rely on your python script paths being set up in a sane way. - While Pdfalyzer has been tested on quite a few large and very complicated PDFs there are no doubt a bunch of edge cases that will trip up the code. Sifting through the various interconnected internal PDF objects and building the correct tree representation is much, much harder than it should be and requires multiple scans and a little bit of educated guessing. If a PDF fails to parse and you hit an error please open a GitHub issue with the compressed (
.zip,.gz, whatever) PDF that is causing the problem attached (if possible) and I'll take a look when I can. I will not take a look at any uncompressed PDFs due to the security risks so make sure you zip it before you ship it. - On Linux if you encounter an error building
wheelorcffiyou may need to install some packages:sudo apt-get install build-essential libssl-dev libffi-dev rustc
Usage
Run pdfalyze --help to see usage instructions. As of right now these are the options:
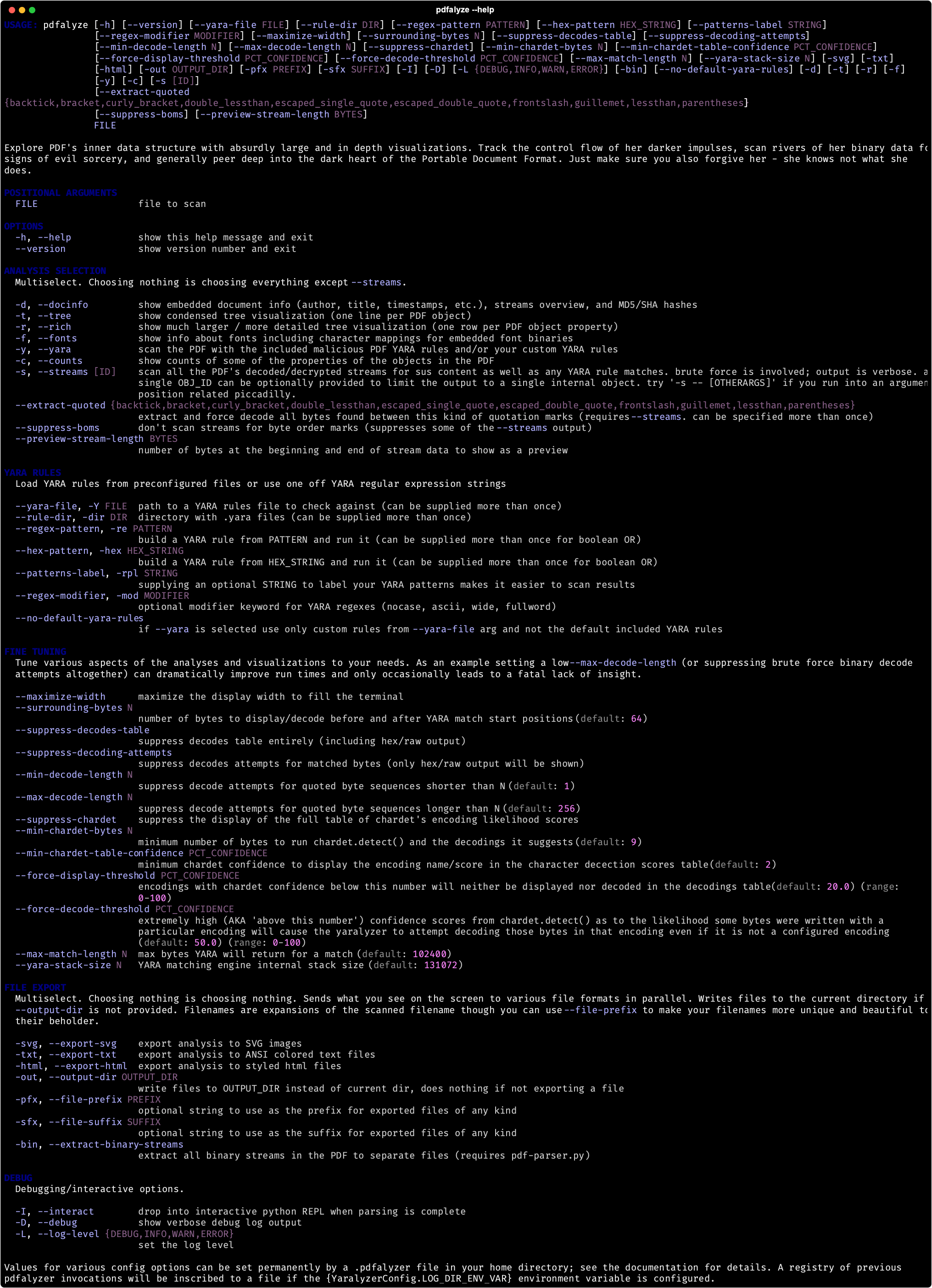
Runtime Options
If you provide none of the flags in the ANALYSIS SELECTION section of the --help then all of the analyses will be done except the --streams. In other words, these two commands are equivalent:
pdfalyze lacan_buys_the_dip.pdfpdfalyze lacan_buys_the_dip.pdf -d -t -r -f -y -c
The --streams output is the one used to hunt for patterns in the embedded bytes and can be extremely verbose depending on the --quote-char options chosen (or not chosen) and contents of the PDF. The Yaralyzer handles this task; if you want to hunt for patterns in the bytes other than bytes surrounded by backticks/frontslashes/brackets/quotes/etc. you may want to use The Yaralyzer directly. Yaralyzer is a prequisite for Pdfalyzer so you may already have the yaralyze command installed and available.
Setting Command Line Options Permanently With A .pdfalyzer File
When you run pdfalyze on some PDF the tool will check for a file called .pdfalyzer in these places in this order:
- the current directory
- the user's home directory
If it finds a .pdfalyzer file in either such place it will load configuration options from it. Documentation on the options that can be configured with these files lives in .pdfalyzer.example which doubles as an example file you can copy into place and edit to your needs. Handy if you find yourself typing the same command line options over and over again.
Guarantees
If any PDF object ID between 1 and the /Size reported by the PDF itself could not be successfully placed in the tree warnings will be printed and the pdfalyze command will return an error code (1, specifically) to the shell. If you do not get any warnings and/or pdfalyze returns success then all[^2] of the inner PDF objects should be seen in the output.
Example Malicious PDF Investigation
BUFFERZONE Team posted an excellent example of how one might use The Pdfalyzer in tandem with Didier Stevens' PDF tools to investigate a potentially malicious PDF (archived in the doc/ dir in this repo if the link rots).
Included Command Line Tools
The Pdfalyzer comes with a few command line tools for doing stuff with PDFs:
combine_pdfs- Combines multiple PDFs into a single PDF. Runcombine_pdfs --helpfor more info.extract_pdf_pages- Extracts page ranges (e.g. "10-25") from a PDF and writes them to a new PDF. Runextract_pdf_pages --helpfor more info.extract_pdf_text- Extracts text from a PDF, including applying OCR to all embedded images. Runextract_pdf_text --helpfor more info.
Running extract_pdf_text requires that you install The Pdfalyzer's optional dependencies:
pipx install pdfalyzer[extract]
As A Python Library
For info about setting up a dev environment see Contributing below.
At its core The Pdfalyzer is taking PDF internal objects gathered by PyPDF and wrapping them in AnyTree's NodeMixin class. Given that things like searching the tree or accessing internal PDF properties will be done through those packages' code it may be helpful to review their documentation.
As far as The Pdfalyzer's unique functionality goes, Pdfalyzer is the class at the heart of the operation. It holds the PDF's logical tree as well as a few other data structures. Chief among these are the FontInfo class which pulls together various properties of a font strewn across 3 or 4 different PDF objects and the BinaryScanner class which lets you dig through the embedded streams' bytes looking for suspicious patterns.
Here's a short intro to how to access these objects:
from pdfalyzer.pdfalyzer import Pdfalyzer
# Load a PDF and parse its nodes into the tree.
pdfalyzer = Pdfalyzer("/path/to/the/evil_or_non_evil.pdf")
actual_pdf_tree: PdfTreeNode = pdfalyzer.pdf_tree
# The PdfalyzerPresenter handles formatting/prettifying output
from pdfalyzer.output.pdfalyzer_presenter import PdfalyzerPresenter
PdfalyzerPresenter(pdfalyzer).print_everything()
# Iterate over all nodes in the PDF tree
for node in pdfalyzer.node_iterator():
do_stuff(node)
# Iterate over the fonts
for font in pdfalyzer.font_infos:
do_stuff(font)
# Iterate over all stream objects:
for node in pdfalyzer.stream_nodes():
do_stuff(node.stream_data)
# Find an internal PDF object by its ID in the PDF
node = pdfalyzer.find_node_by_idnum(44)
pdf_object: PdfObject = node.obj
# Use anytree's findall_by_attr() to find nodes with a given property
from anytree.search import findall_by_attr
page_nodes = findall_by_attr(pdfalyzer.pdf_tree, name='type', value='/Page')
# Iterate over backtick quoted strings from a font binary and process them
font_info: FontInfo = pdfalyzer.font_infos[0]
for backtick_quoted_string in font.binary_scanner.extract_backtick_quoted_bytes():
do_stuff(backtick_quoted_string)
Example Output
The Pdfalyzer can export visualizations to HTML, ANSI colored text, and both PNG and SVG vector images using the file export functionality that comes with Rich.
If you want to export .png images like the ones below directly from Pdfalyzer you'll need to do one of these things:
- Install Inkscape (homebrew users can install it with
brew install --cask inkscape) - Ask for the
imgextra when installing Pdfalyzer which will installcairosvg:pipx install pdfalyzer[img]. You'll also have to install the CairoSVG executable manually in different ways depending on your operating system, see the CairoSVG docs for the specifics.
In our experience Inkscape and CairoSVG both work though we've seen some glitchiness in the rendered output (along with straight up crashes) using CairoSVG on the SVGs rendered by Pdfalyzer so Inkscape is recommended.
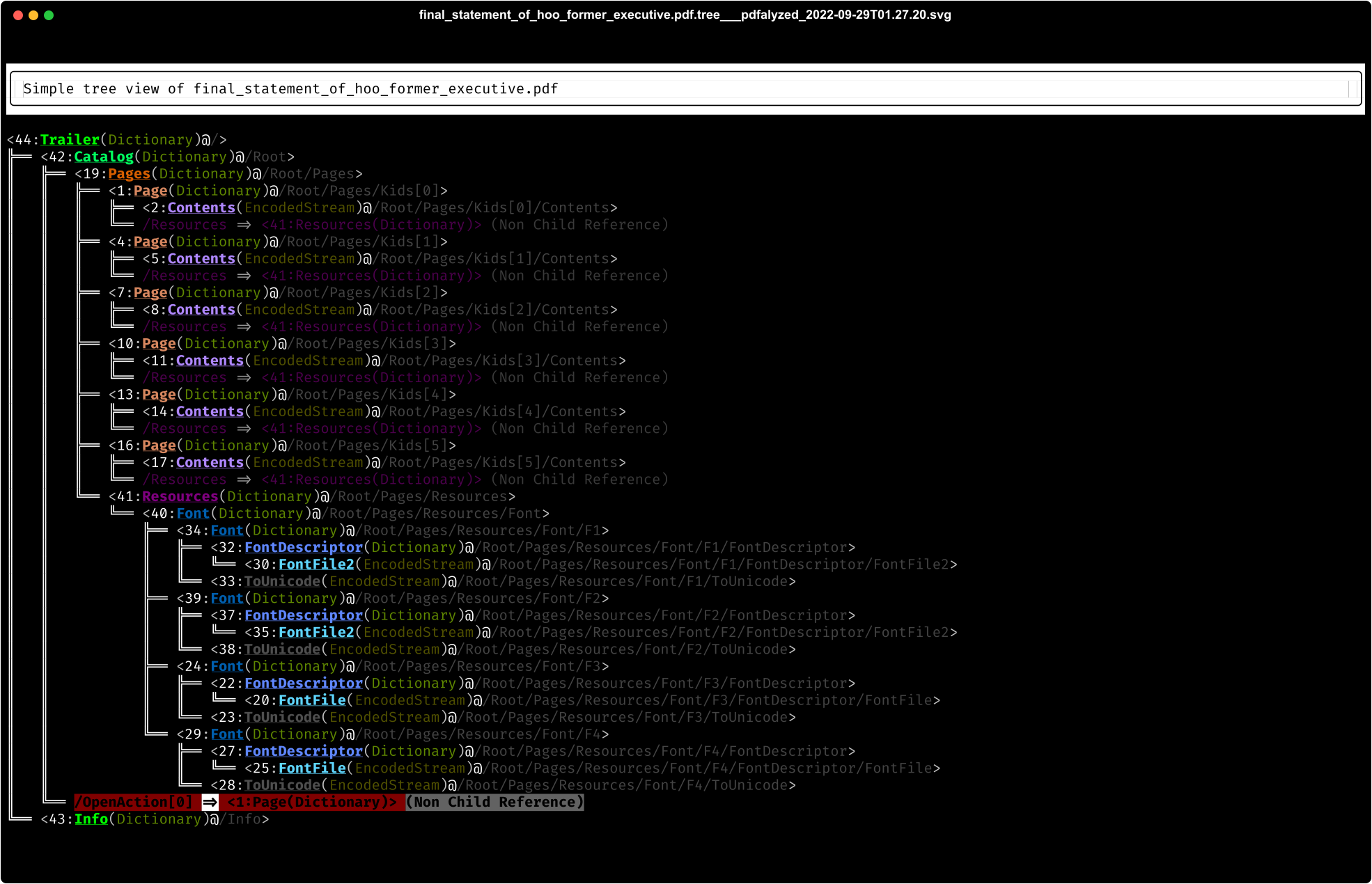
Basic Tree View
As you can see the suspicious /OpenAction relationship is highlighted bright red, as would be a couple of other sus PDF instructions like /JavaScript or /AcroForm if they exist in the PDF being pdfalyzed.
The dimmer (as in "harder to see") nodes[^5] marked with Non Child Reference give you a way to visualize the relationships between PDF objects that exist outside of the tree structure's parent/child relationships.
That's a pretty basic document. Here's the basic tree for a more complicated PDF containing an NMAP cheat sheet.
Rich Tree View
This image shows a more in-depth view of of the PDF tree for the same document shown above. This tree (AKA the "rich" tree) has almost everything. Shows all PDF object properties, all relationships between objects, and sizable previews of any binary data streams embedded or encrypted in the document. Note that in addition to /OpenAction, the Adobe Type1 font binary is also red (Google's project zero regards any Adobe Type1 font as "mad sus").

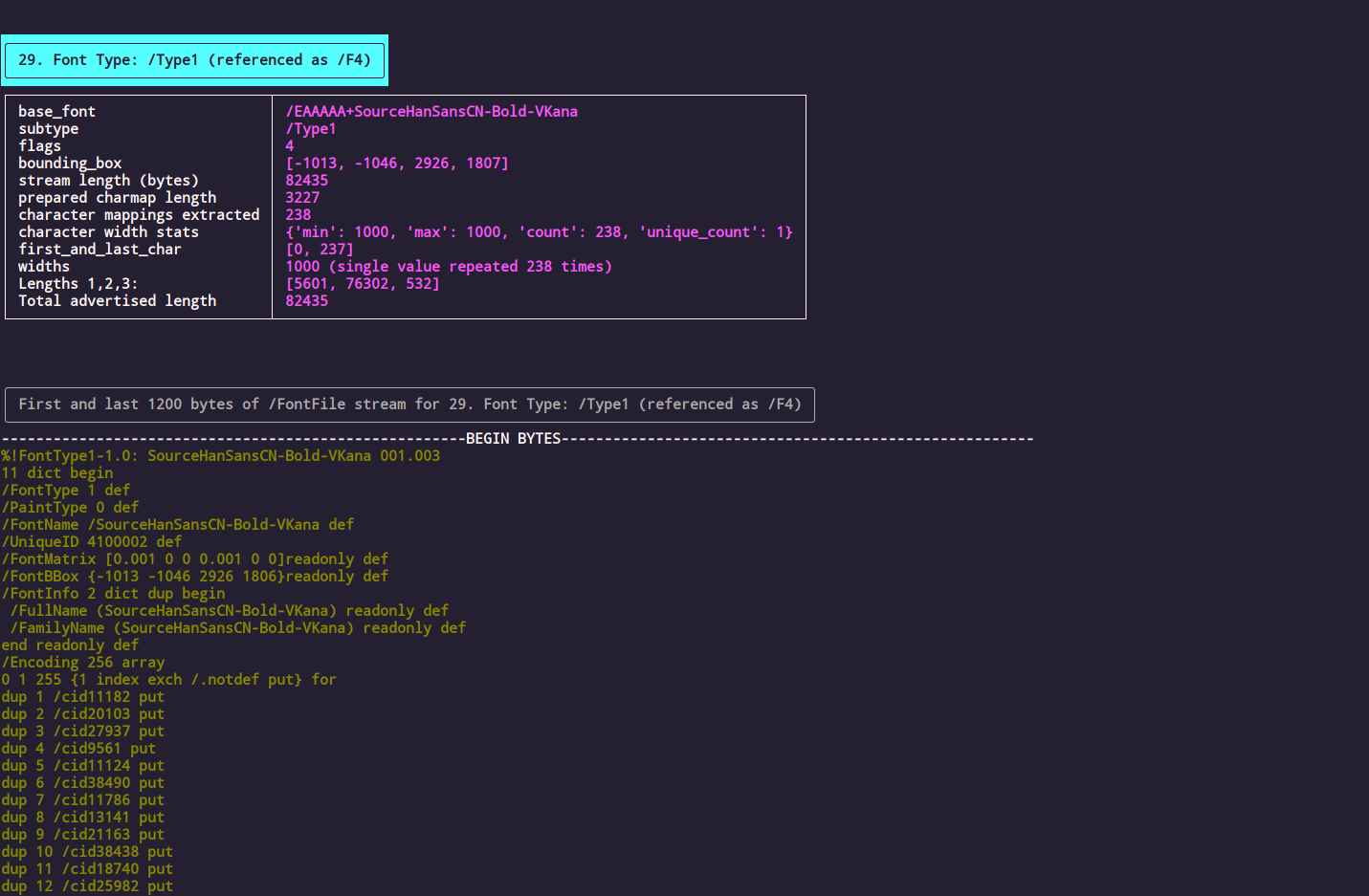
Fonts
Extract character mappings from ancient Adobe font formats. It's actually PyPDF doing the lifting here but we're happy to take the credit.
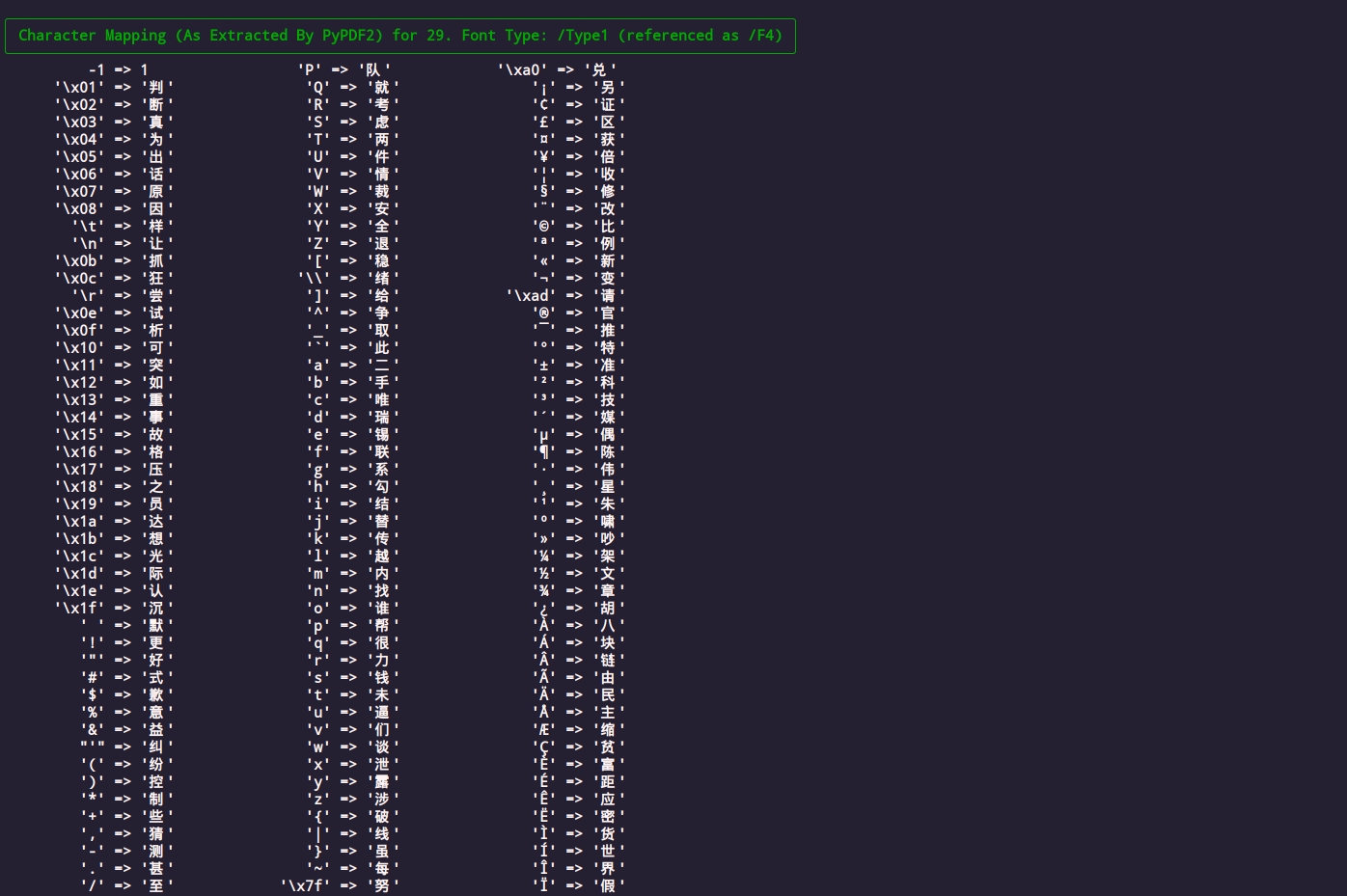
View the properties of the fonts in the PDF. Comes with a preview of the beginning and end of the font's raw binary data stream (if it's that kind of font).
Binary Analysis (And Lots Of It)
YARA Scan: Check PDF for malicious content.
This repo contains all the PDF specific YARA rules I could dig up that identify byte patterns indicating a PDF may have been modified for evil. While the real dangers exist in PDF modifications no one has seen yet (and thus we have no YARA rules for), there are still a bunch of 'sus' indicators (e.g. has a Type1 font, is incorrectly terminated, etc.) that will be tripped when you scan a PDF with The Pdfalyzer.
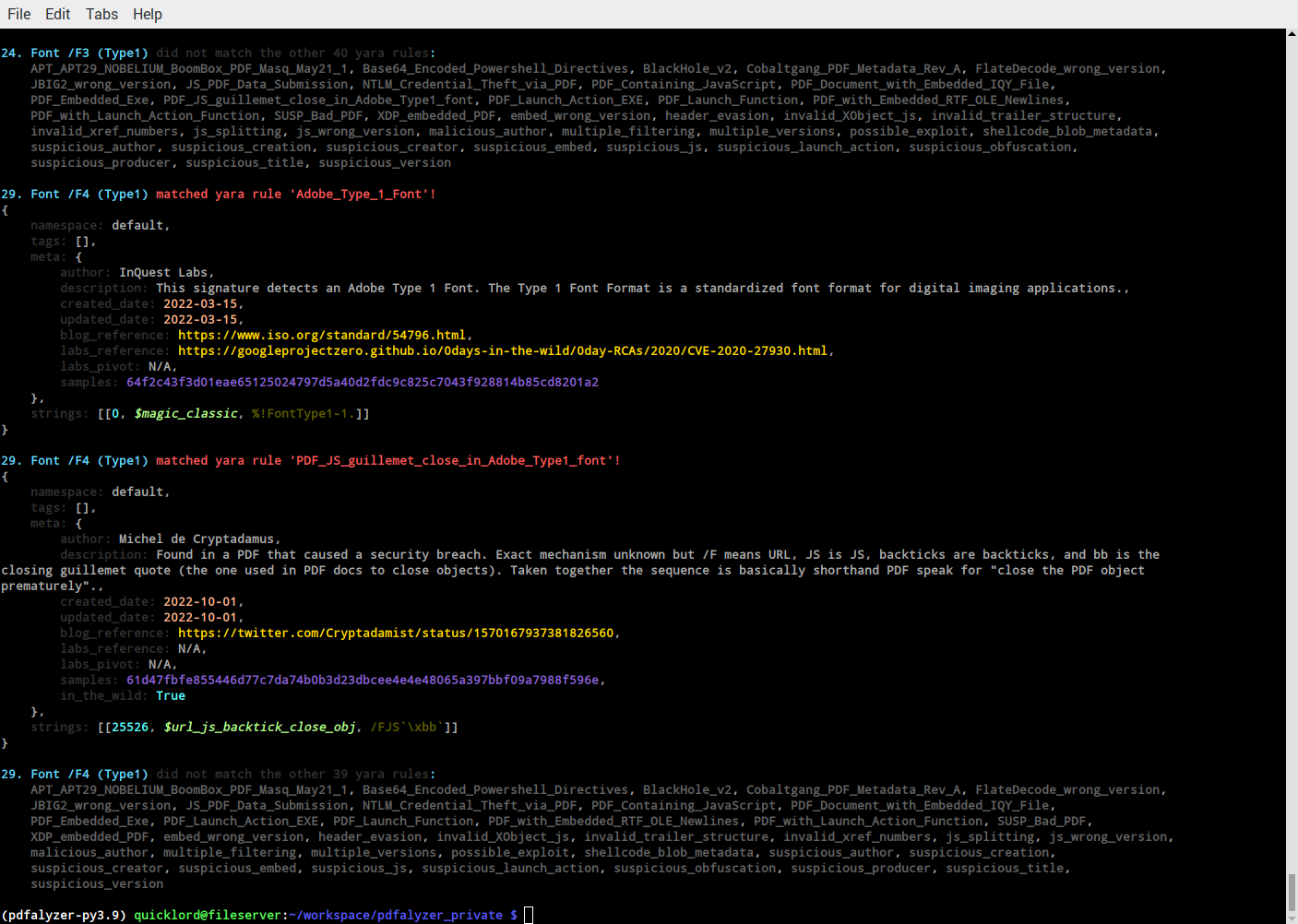
Search Internal Binary Data for Sus Content No Malware Scanner Will Catch[^6]:
Things like, say, a hidden binary /F (PDF instruction meaning "URL") followed by a JS (I'll let you guess what "JS" stands for) and then a binary » character (AKA "the character the PDF specification uses to close a section of the PDF's logical structure"). Put all that together and it says that you're looking at a secret JavaScript instruction embedded in the encrypted part of a font binary. A secret instruction that causes the PDF renderer to pop out of its frame prematurely as it renders the font.
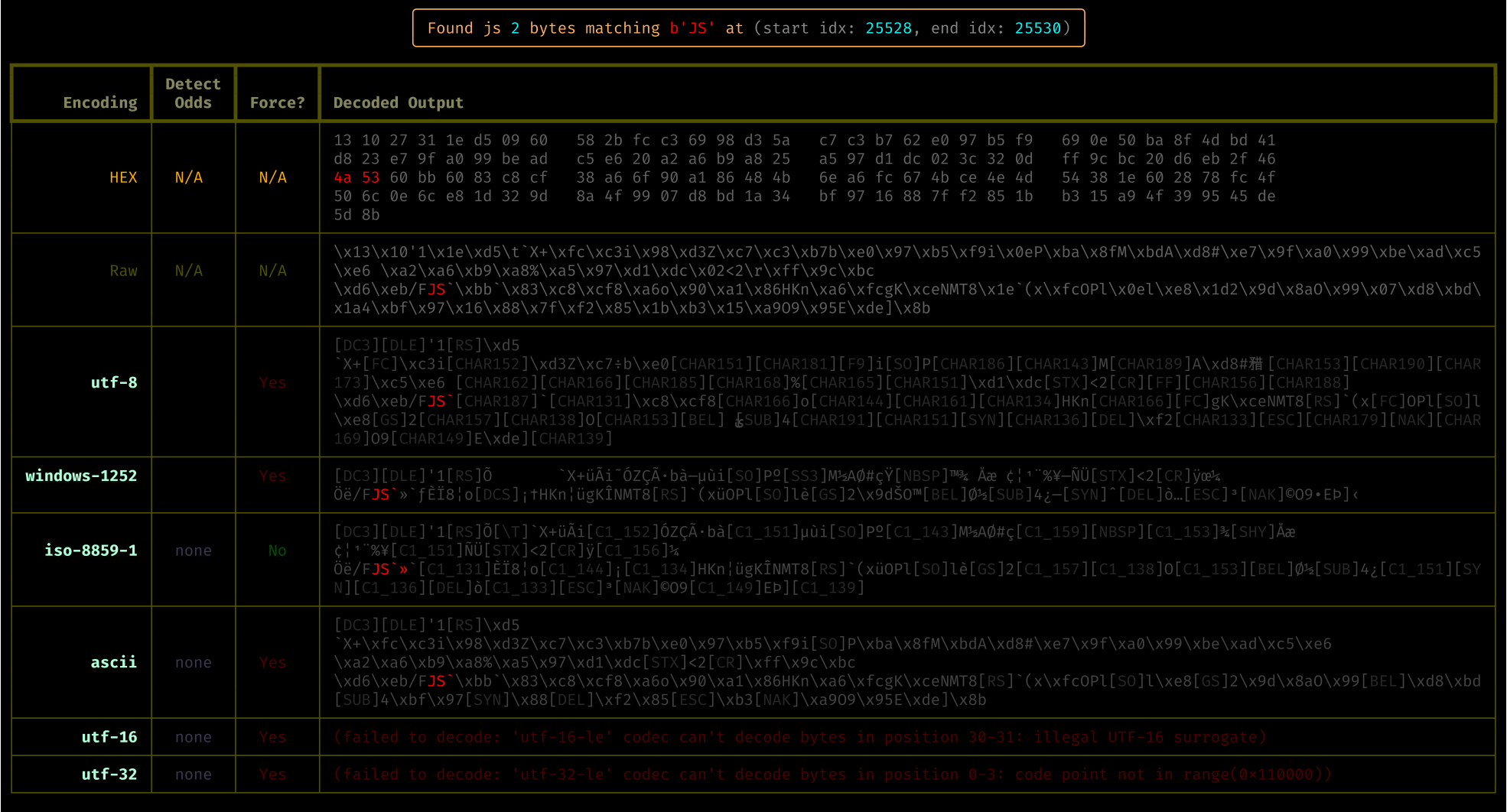
Extract And Decode Binary Patterns: Like, say, bytes between common regular expression markers that you might want to force a decode of in a lot of different encodings.

See stats: When all is said and done you can see some stats that may help you figure out what the character encoding may or may not be for the bytes matched by those patterns:
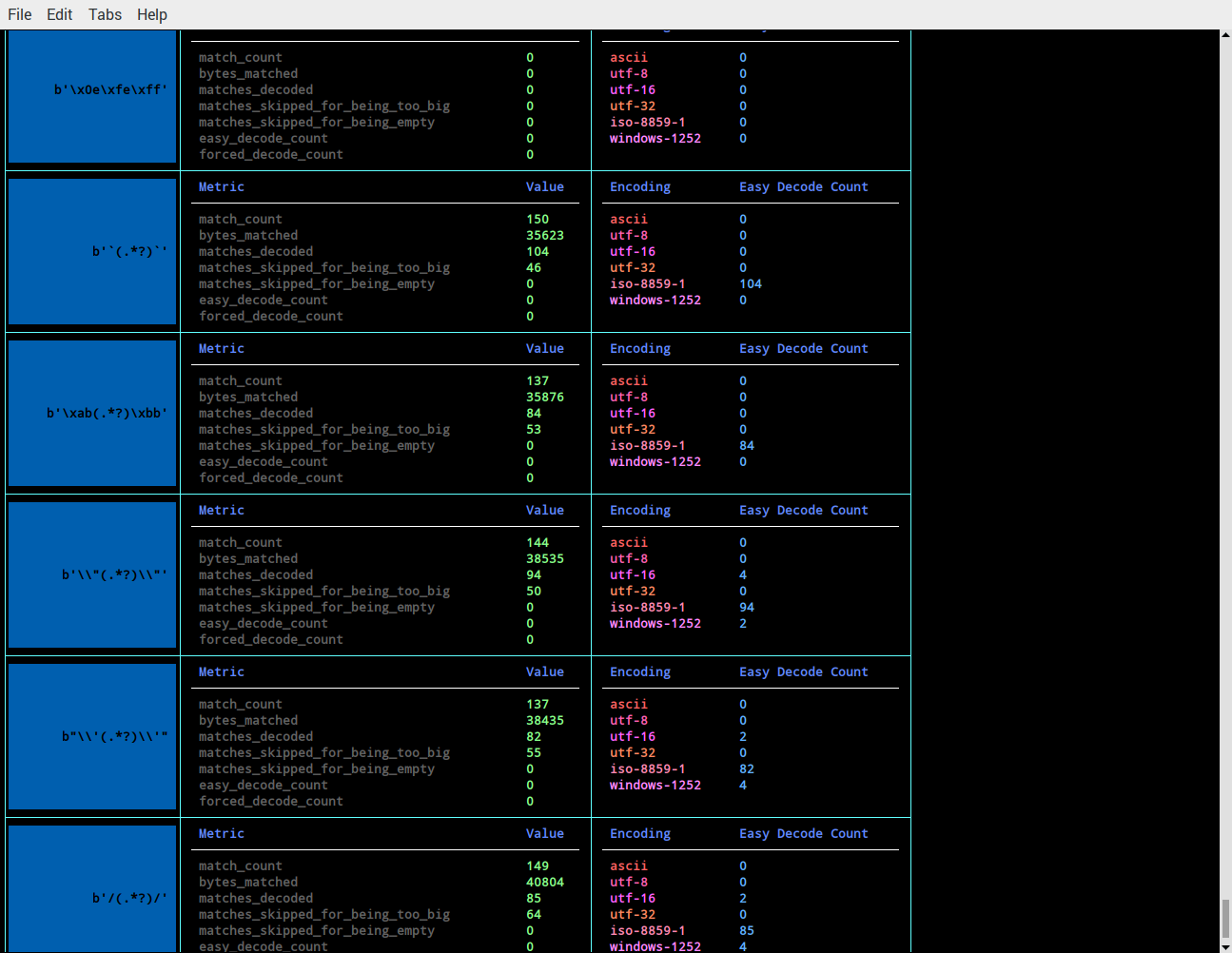
Fancy Table To Tell You What The chardet Library Would Rank As The Most Likely Encoding For A Chunk Of Binary Data
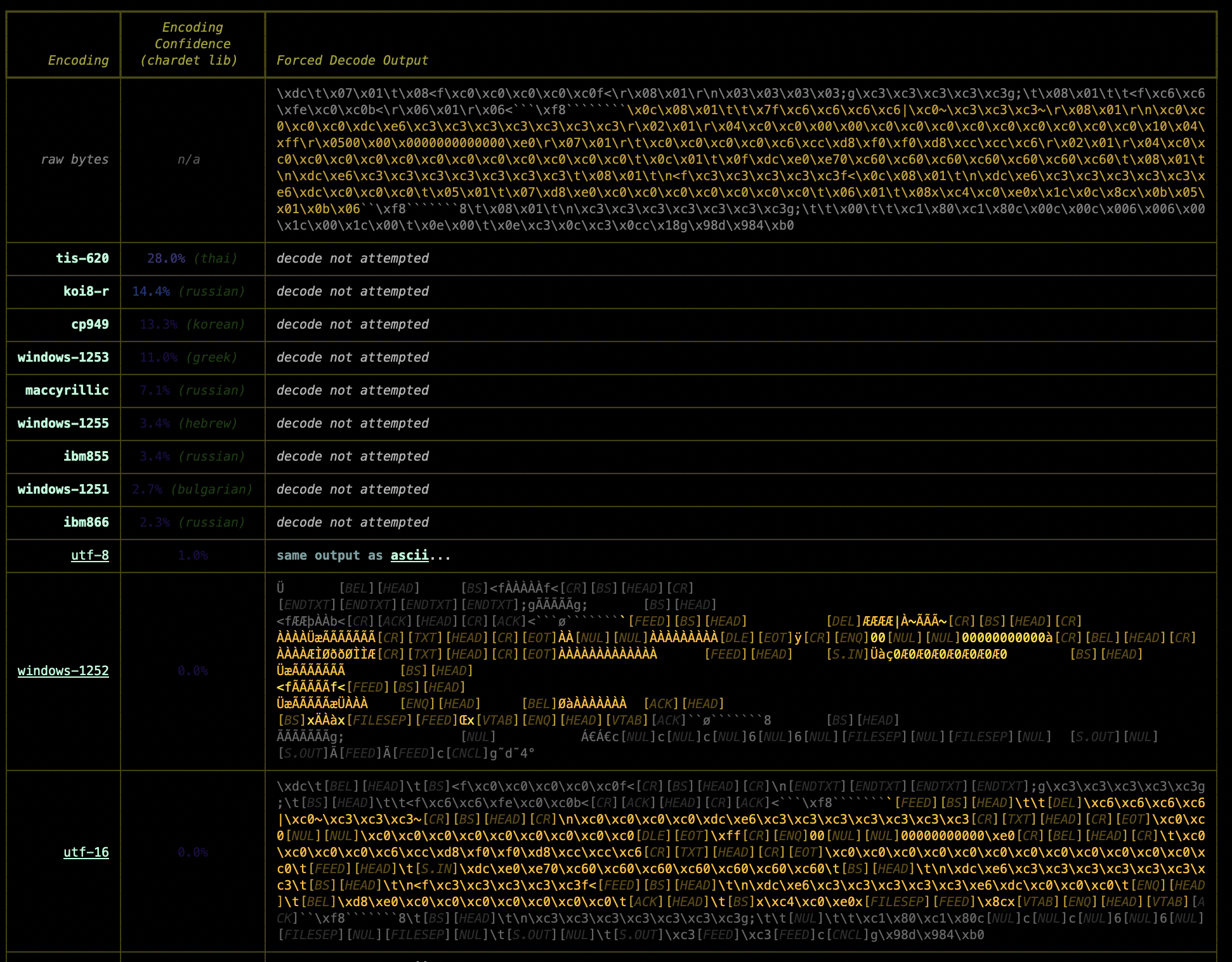
PDF Resources
3rd Party PDF Tools
Installing Didier Stevens's PDF Analysis Tools
Stevens's tools provide comprehensive info about the contents of a PDF, are guaranteed not to trigger the rendering of any malicious content (especially pdfid.py), and have been battle tested for well over a decade. It would probably be a good idea to analyze your PDF with his tools before you start working with this one.
If you're lazy and don't want to retrieve the tools yourself there's a script to download them that ships with Pdfalyzer. Just run this:
pdfalyzer_install_pdf_parser
If there is a discrepancy between the output of betweeen his tools and this one you should assume his tool is correct and Pdfalyzer is wrong until you conclusively prove otherwise.
Installing The t1utils Font Suite
t1utils is a suite of old but battle tested apps for manipulating old Adobe font formats. You don't need it unless you're dealing with an older Type 1 or Type 2 font binary but given that those have been very popular exploit vectors in the past few years it can be extremely helpful. One of the tools in the suite, t1disasm, is particularly useful because it decrypts and decompiles Adobe Type 1 font binaries into a more human readable string representation.
There's a script to help you install the suite if you need it:
scripts/install_t1utils.sh
External Documentation
Official Adobe Documentation
- Official Adobe PDF 1.7 Specification - Indispensable map when navigating a PDF forest.
- Adobe Type 1 Font Format Specification - Official spec for Adobe's original font description language and file format. Useful if you have suspicions about malicious fonts. Type1 seems to be the attack vector of choice recently which isn't so surprising when you consider that it's a 30 year old technology and the code that renders these fonts probably hasn't been extensively tested in decades because almost no one uses them anymore outside of people who want to use them as attack vectors.
- Adobe CMap and CIDFont Files Specification - Official spec for the character mappings used by Type1 fonts / basically part of the overall Type1 font specification.
- Adobe Type 2 Charstring Format - Describes the newer Type 2 font operators which are also used in some multiple-master Type 1 fonts.
Other Stuff
- Didier Stevens's PDF tools
- Didier Stevens's free book about malicious PDFs - The master of the malicious PDFs wrote a whole book about how to analyze them. It's an old book but the PDF spec was last changed in 2008 so it's still relevant.
- Analyzing Malicious PDFs Cheat Sheet - Like it says on the tin. If that link fails there's a copy here in the repo.
- T1Utils Github Repo - Suite of tools for manipulating Type1 fonts.
t1disasmManual - Probably the most useful part of the T1Utils suite because it can decompile encrypted ancient Adobe Type 1 fonts into something human readable.- PDF Flaws 101 from Black Hat 2020.
- A Curious Exploration of Malicious PDF Documents by Julian Lindenhofer, Rene Offenthaler and Martin Pirker, 2020. Overview of all the possible execution paths that can lead to a PDF executing JavaScript, opening loca/remote files, or making web requests.
- Malicious PDF Generator is a well maintained GitHub project that does what it says on the tin.
- PDF is Broken, and so is this file is a 2021 report on what happens when you challenge cybersecurity teams to turn PDFs into weapons. (Among other things they managed to create a PDF that launches a webserver when you open it.)
- linuxPDF is a project that managed to embed an entire linux operating system inside a PDF document. The related DoomPDF managed to embed the classic video game Doom in a PDF.
- horrifying-pdf-experiments is a repo of horrifying things you can do with PDFs.
Did The World Really Need Another PDF Tool?
This tool was built to fill a gap in the PDF assessment landscape following my own recent experience trying to find malicious content in a PDF file. Didier Stevens's pdfid.py and pdf-parser.py are still the best game in town when it comes to PDF analysis tools but they lack in the visualization department and also don't give you much to work with as far as giving you a data model you can write your own code around. Peepdf seemed promising but turned out to be in a buggy, out of date, and more or less unfixable state. And neither of them offered much in the way of tooling for embedded binary analysis.
Thus I felt the world might be slightly improved if I strung together a couple of more stable/well known/actively maintained open source projects (AnyTree, PyPDF, Rich, and YARA via The Yaralyzer) into this tool.
Contributing
One easy way of contributing is to run the script to test against all the PDFs in your ~/Documents folder and report any issues.
Beyond that see CONTRIBUTING.md.
Code Glossary
These are the naming conventions at play in Pdfalyzer code base:
| Term | Meaning |
|---|---|
PDF Object |
Instance of a PyPDF class that represents the information stored in the PDF binary between open and close guillemet quotes (« and ») |
reference_key |
String found in a PDF object that names a property (e.g. /BaseFont or /Subtype) |
reference |
Link from a PDF object to another node. Outward facing relationships, basically. |
address |
reference_key plus a hash key or numerical array index if that's how the reference works. e.g. if node A has a reference key /Resources pointing to a dict {'/Font2': [IndirectObject(55), IndirectObject(2)]} the address of IndirectObject(55) from node A would be /Resources[/Font2][0] |
tree_address |
Like the address but starting at the root of the tree. Describes the series of objects you would step through if you walked the tree from the root to this node. |
relationship |
Any link between nodes created by addresses/reference keys |
non_tree_relationship |
any link between nodes that is not considered a parent/child tree relationship |
indeterminate_node |
any node whose place in the tree cannot be decided until every node has been seen |
link_node |
nodes like /Dest that just contain a pointer to another node |
Reference
PyPDFdocumentation (latest is 4.x or something so these are the relevant docs forpdfalyze)
[^1]: The official Adobe PDF specification calls this tree the PDF's "logical structure", which is a good example of nomenclature that does not help those who see it understand anything about what is being described. I can forgive them given that they named this thing back in the 80s, though it's a good example of why picking good names for things at the beginning is so important.
[^2]: An exception will be raised if there's any issue placing a node while parsing or if there are any nodes not reachable from the root of the tree at the end of parsing. If there are no exceptions then all internal PDF objects are guaranteed to exist in the tree except in these situations when warnings will be printed:
/ObjStm (object stream) is a collection of objects in a single stream that will be unrolled into its component objects.
/XRef Cross-reference stream objects which hold the same references as the /Trailer are hacked in as symlinks of the /Trailer
[^3]: Given the nature of the PDFs this tool is meant to be scan anything resembling "rendering" the document is pointedly NOT offered.
[^4]: pipx is a tool that basically runs pip install for a python package but in such a way that the installed package's requirements are isolated from your system's python packages. If you don't feel like installing pipx then pip install should work fine as long as there are no conflicts between The Pdfalyzer's required packages and those on your system already. (If you aren't using other python based command line tools then your odds of a conflict are basically 0%.)
[^5]: Technically they are SymlinkNodes, a really nice feature of AnyTree.
[^6]: At least they weren't catching it as of September 2022.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pdfalyzer-1.19.6.tar.gz.
File metadata
- Download URL: pdfalyzer-1.19.6.tar.gz
- Upload date:
- Size: 146.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.6.1 CPython/3.11.11 Darwin/22.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
888df3252f73fe28132a017824bc60f7a686c6a05800f3b026f76f48ee655dd3
|
|
| MD5 |
a5293fb006e7a6c9c37e580aecfd4420
|
|
| BLAKE2b-256 |
69e439183a9674a5eb292143d9a3dd1c4fa9541fffcf567f5295efefd5be86db
|
File details
Details for the file pdfalyzer-1.19.6-py3-none-any.whl.
File metadata
- Download URL: pdfalyzer-1.19.6-py3-none-any.whl
- Upload date:
- Size: 168.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.6.1 CPython/3.11.11 Darwin/22.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
95f535d48b0446ae1b8ab411e48ef6b7011ba2c41e541044a30390d550cd2239
|
|
| MD5 |
f6f51ba9ccda619fb5b5cb4d24e3d99a
|
|
| BLAKE2b-256 |
1efe5370f7fcb8fa047760ec0c0645ae6fb4f588c19b4bd89794d0d3bd82e13e
|








{kind=link}
{kind=link}