Edit/read/observe memory with pymem and pandas

Project description
Edit/read/observe memory with pymem and pandas DataFrames
pip install pdmemedit
Tested against Windows 10 / Python 3.10 / Anaconda
Why not use the best libraries for organizing Big Data to organize Big Data?
# Here is an example
# start a separate Python process and get the pid
from time import sleep
import os
tu = (
6666,
77777554,
"b1abvababubux",
b"b1abvababubux",
"b1abvababubux".encode("utf-16-le"),
)
print(os.getpid())
while True:
print(f"{tu=}\t{id(tu)=}")
for v in tu:
print(f"{v=}\t{id(v)=}")
sleep(5)
# output:
# tu=(6666, 77777554, 'b1abvababubux', b'b1abvababubux', b'b\x001\x00a\x00b\x00v\x00a\x00b\x00a\x00b\x00u\x00b\x00u\x00x\x00') id(tu)=1784089644304
# v=6666 id(v)=1784088602128
# v=77777554 id(v)=1784088604816
# v='b1abvababubux' id(v)=1784089580144
# v=b'b1abvababubux' id(v)=1784089556480
# v=b'b\x001\x00a\x00b\x00v\x00a\x00b\x00a\x00b\x00u\x00b\x00u\x00x\x00' id(v)=1784089244720
import pymem
import numpy as np
from pdmemedit import Pdmemory
# pass either pid or filename, but not both
pdme = Pdmemory(
pid=21956, filename=None # pid of the Python process we have just created
)
# memory to DataFrame
pdme.update_region_df(
limitfunction=lambda x: True,
dtypes=(
"S1",
np.int8,
np.uint8,
np.int16,
np.uint16,
np.int32,
np.uint32,
np.int64,
np.uint64,
np.float32,
np.float64,
),
allowed_protections=(
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_EXECUTE_READ,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_EXECUTE_READWRITE,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_EXECUTE_WRITECOPY,
# pymem.ressources.structure.MEMORY_PROTECTION.PAGE_NOACCESS,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_READONLY,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_READWRITE,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_WRITECOPY,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_GUARD,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_NOCACHE,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_WRITECOMBINE,
),
)
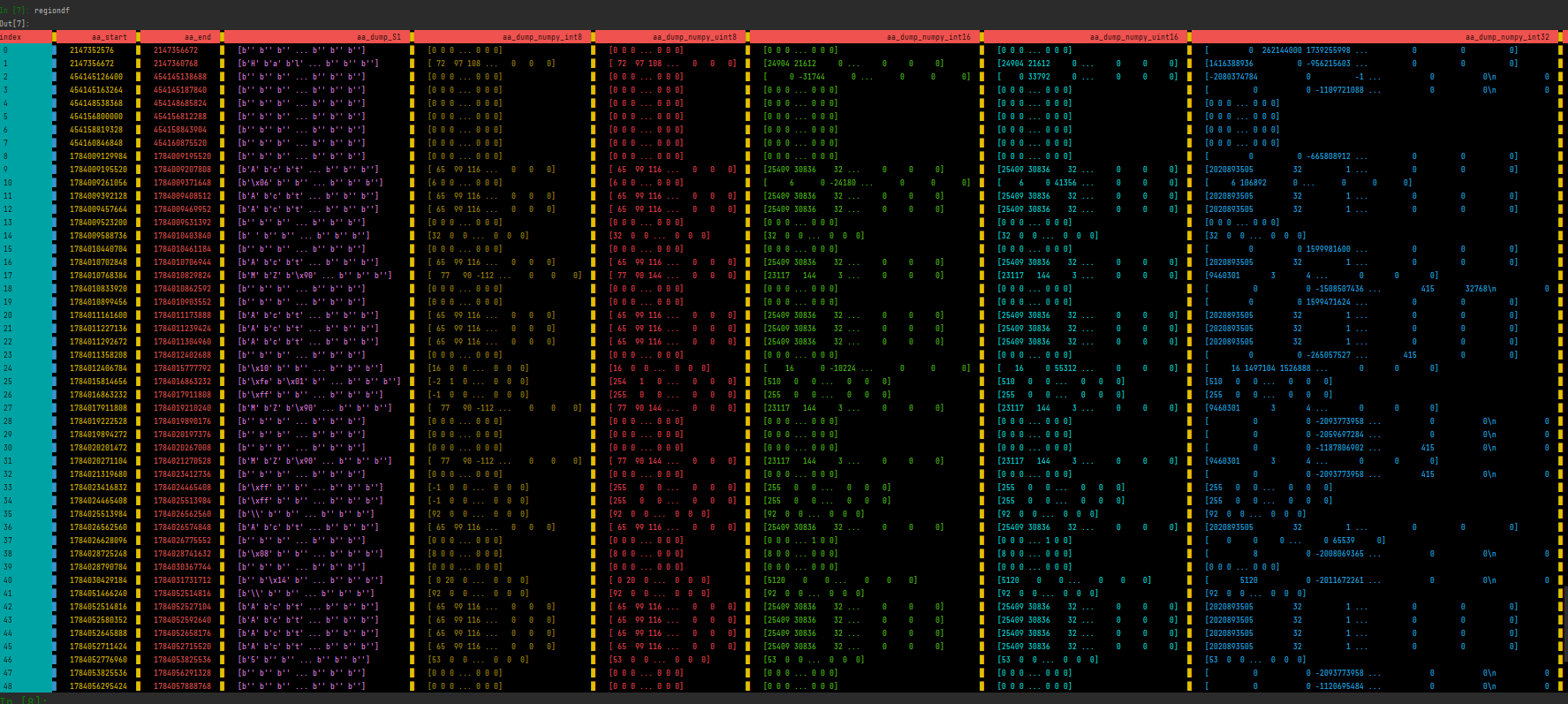
regiondf = pdme.get_regiondf()
print(regiondf)
###################################################################
# Search for a string
# Don't forget to get a memory dump by calling pdme.update_region_df before you search for a string
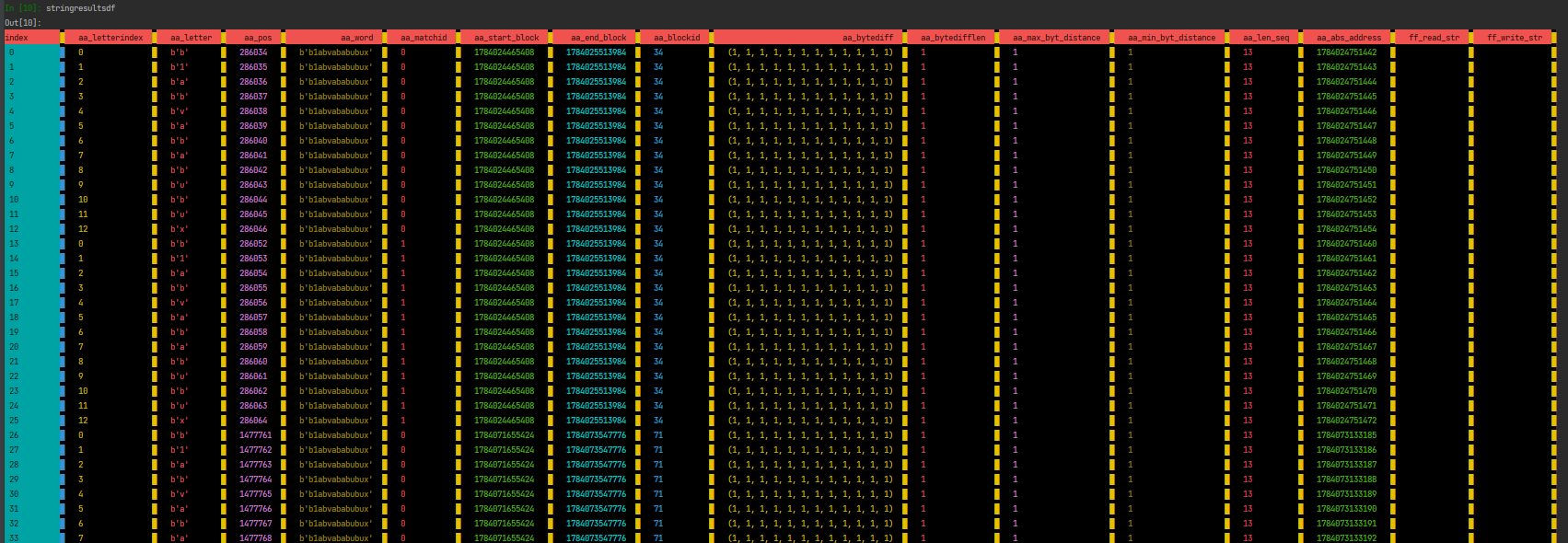
pdme.search_string("b1abvababubux")
stringresultsdf = pdme.get_searchstringdf()
print(stringresultsdf)
###################################################################
# Search for a number
# Don't forget to get a memory dump by calling pdme.update_region_df before you search for a number
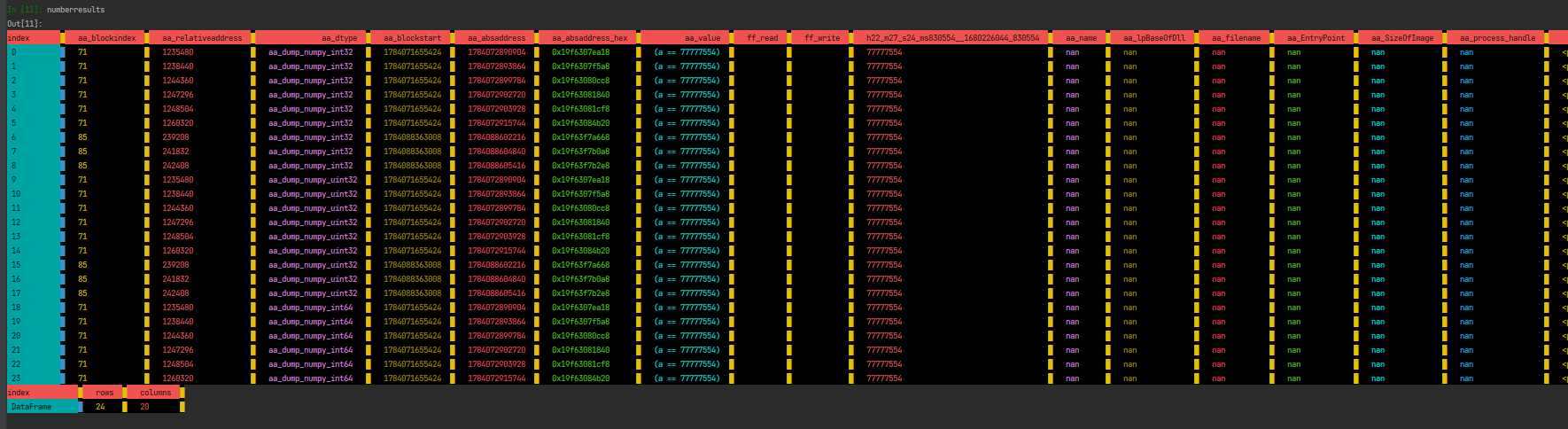
pdme.search_number(
numexprquery=f"(a == 77777554)", # numexpr.evaluate string, name of 'a' can't be changed
dtypes=(
np.int8,
np.uint8,
np.int16,
np.uint16,
np.int32,
np.uint32,
np.int64,
np.uint64,
# np.float32,
# np.float64,
),
)
numberresults = pdme.get_searchnumberdf()
print(numberresults)
###################################################################
# Call pdme.search_number first, edit the DataFrame (self.numbersearchdf) until it serves your needs
# and call pdme.observe_numbers to see how the value changes
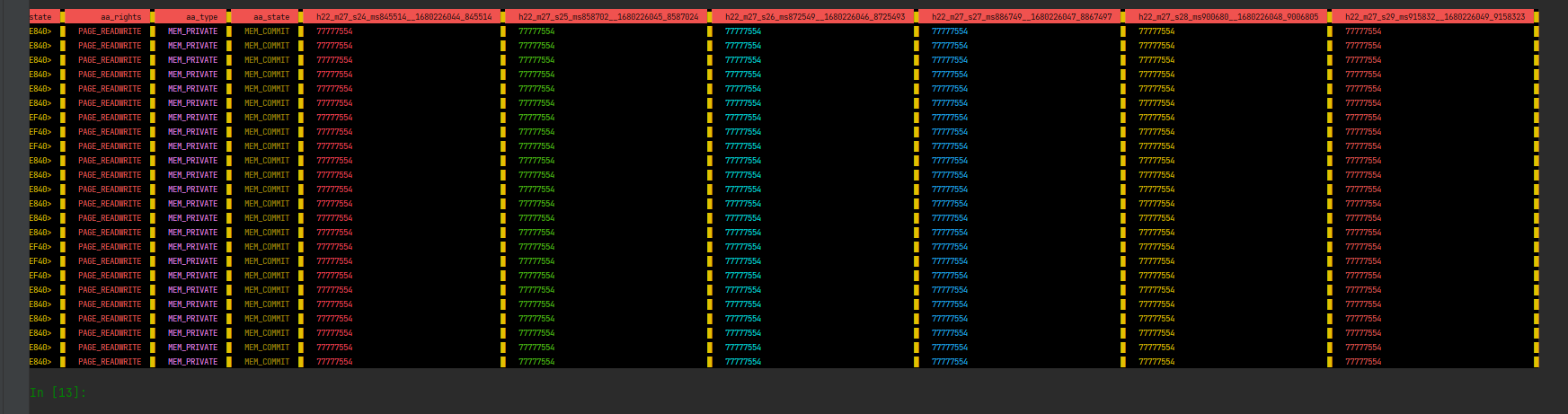
pdme.observe_numbers( # ctrl+c to break
keepcondition="(new >= old)", # numexpr.evaluate string, names of 'new/old' can't be changed
sleep_between_scans=1,
savefolder=None,
printoutputlimit=100,
)
observedvalues = pdme.get_observerdf()
print(observedvalues)
###################################################################
# How to edit the memory
numberresults.ff_write.apply(lambda x: x(99999999)) # Overwrites results with 99999999
stringresultsdf.ff_write_str.apply(
lambda x: x("B")
) # binary/utf-8/utf-16-le... conversation should work automatically - overwrites each single letter
# Output after calling numberresults.ff_write/stringresultsdf.ff_write_str
# tu=(6666, 99999999, 'BBBBBBBBBBBBB', b'BBBBBBBBBBBBB', b'B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00') id(tu)=1784089644304
# v=6666 id(v)=1784088602128
# v=99999999 id(v)=1784088604816
# v='BBBBBBBBBBBBB' id(v)=1784089580144
# v=b'BBBBBBBBBBBBB' id(v)=1784089556480
# v=b'B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00B\x00' id(v)=1784089244720
###################################################################
# Use this with care, and limit the area of interest as much as possible, this method might use a lot of memory and get really slow, since
# it dumps the memory of the whole process and compares every single byte with the last memory dump.
# You can stop recording by pressing Ctrl+C
pdme.record_all_changing_values( # might get very slow and use a lot of memory
limitfunc=lambda x: True,
dtype=np.uint32,
allowed_protections=(
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_EXECUTE_READ,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_EXECUTE_READWRITE,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_READWRITE,
pymem.ressources.structure.MEMORY_PROTECTION.PAGE_READONLY,
),
)
pdme.get_differencesdf()
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
pdmemedit-0.10.tar.gz
(38.3 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
pdmemedit-0.10-py3-none-any.whl
(38.7 kB
view details)
File details
Details for the file pdmemedit-0.10.tar.gz.
File metadata
- Download URL: pdmemedit-0.10.tar.gz
- Upload date:
- Size: 38.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e6b7a03056eede644f52eb51e3bc19757d3444c90c8d7c1aa504027008a8367c
|
|
| MD5 |
d6565860e7a08828e47beb620702697d
|
|
| BLAKE2b-256 |
289e5528a75ecc44893472ba46e577b2134c652cbdc289e24aae07b779d046f5
|
File details
Details for the file pdmemedit-0.10-py3-none-any.whl.
File metadata
- Download URL: pdmemedit-0.10-py3-none-any.whl
- Upload date:
- Size: 38.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f55a3d805a623bed96f1ba78c968d0e5a8ffe9c6ee5ccb16eed9c05dea543477
|
|
| MD5 |
586e19a8804c72cd8193c29a8bafd71e
|
|
| BLAKE2b-256 |
297553844cf30ce5c519e6aa104563e8e54af83cf9655de3cf5381f9b65f5d8d
|







