A tool for evaluation of model outputs, primarily MT.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
🍐Pearmut





Platform for Evaluation and Reviewing of Multilingual Tasks: Evaluate model outputs for translation and NLP tasks with support for multimodal data (text, video, audio, images) and multiple annotation protocols (DA, ESA, ESAAI, MQM, cESA, and more!).

Table of Contents
- Quick Start
- Campaign Configuration
- Advanced Features
- Campaign Management
- CLI Commands
- Terminology
- Development
- Citation
- Changelog
Quick Start
Install and run locally without cloning:
pip install pearmut
# Download example campaigns
wget https://raw.githubusercontent.com/zouharvi/pearmut/refs/heads/main/examples/esa.json
wget https://raw.githubusercontent.com/zouharvi/pearmut/refs/heads/main/examples/da.json
# Load and start
pearmut add esa.json da.json
pearmut run
Campaign Configuration
Basic Structure
Campaigns are defined in JSON files (see examples/). The simplest configuration uses task-based assignment where each user has pre-defined tasks:
{
"info": {
"assignment": "task-based",
# DA: scores
# ESA: error spans and scores
# cESA: error spans and scores, comparison of multiple translations
# MQM: error spans, categories, and scores
"protocol": "ESA",
},
"campaign_id": "wmt25_#_en-cs_CZ",
"data": [
# data for first task/user
[
[
# each evaluation item is a document
{
"instructions": "Evaluate translation from en to cs_CZ", # message to show to users above the first item
"src": "This will be the year that Guinness loses its cool. Cheers to that!",
"tgt": {"modelA": "Nevím přesně, kdy jsem to poprvé zaznamenal. Možná to bylo ve chvíli, ..."},
"item_id": "first item in first document"
},
{
"src": "I'm not sure I can remember exactly when I sensed it. Maybe it was when some...",
"tgt": {"modelA": "Tohle bude rok, kdy Guinness přijde o svůj „cool“ faktor. Na zdraví!"},
"item_id": "second item in first document"
}
...
],
# more document
...
],
# data for second task/user
[
...
],
# arbitrary number of users (each corresponds to a single URL to be shared)
]
}
Each item has to have tgt (dictionary from model names to strings, even for a single model evaluation).
Optionally, you can also include src (source string) and/or ref (reference string).
If neither src nor ref is provided, only the model outputs will be displayed.
For full Pearmut functionality (e.g. automatic statistical analysis), add item_id as well.
Any other keys that you add will simply be stored in the logs.
Load campaigns and start the server:
pearmut add my_campaign.json # Use -o/--overwrite to replace existing
pearmut run
Assignment Types
task-based: Each user has predefined itemssingle-stream: All users draw from a shared pool (random assignment)dynamic: Items are dynamically assigned based on current model performance (see Dynamic Assignment)
Advanced Features
Shuffling Model Translations
By default, Pearmut randomly shuffles the order in which models are shown per each item in order to avoid positional bias.
The shuffle parameter in campaign info controls this behavior:
{
"info": {
"assignment": "task-based",
"protocol": "ESA",
"shuffle": true # Default: true. Set to false to disable shuffling.
},
"campaign_id": "my_campaign",
"data": [...]
}
Documents in data_welcome are not shuffled and so don't require to have the same models in all documents.
Showing Model Names
By default, model names are hidden to avoid biasing annotators. To display model names on top of each output block, set show_model_names to true:
{
"info": {
"assignment": "task-based",
"protocol": "ESA",
"show_model_names": true # Default: false.
},
"campaign_id": "my_campaign",
"data": [...]
}
Custom Score Sliders
For multi-dimensional evaluation tasks (e.g., assessing fluency on a Likert scale), you can define custom sliders with specific ranges and steps:
{
"info": {
"assignment": "task-based",
"protocol": "ESA",
"sliders": [
{"name": "Fluency", "min": 0, "max": 5, "step": 1},
{"name": "Adequacy", "min": 0, "max": 100, "step": 1}
]
},
"campaign_id": "my_campaign",
"data": [...]
}
When sliders is specified, only the custom sliders are shown. Each slider must have name, min, max, and step properties. All sliders must be answered before proceeding.
By default, cESA uses a single score slider which is colored relative to other translations of the same segment. This can be turned on or off using slider_colors parameter in info.
Textfield comment box
To enable a textfield for commenting, post-editing or translation tasks, use the textfield parameter in info. The textfield content is stored in annotations alongside scores and error spans.
{
"info": {
"protocol": "DA",
"textfield": "prefilled" # Options: null, "hidden", "visible", "prefilled"
}
}
Textfield modes:
nullor omitted: No textfield (default)"hidden": Textfield hidden by default, shown by clicking a button"visible": Textfield always visible"prefilled": Textfield visible and pre-filled with model output for post-editing
Custom MQM Taxonomy
For MQM protocol campaigns, you can define a custom error taxonomy instead of using the default MQM categories. Specify mqm_categories in the campaign info section as a dictionary mapping main categories to lists of subcategories:
{
"info": {
"assignment": "task-based",
"protocol": "MQM",
"mqm_categories": {
"General": ["Accuracy", "Fluency"],
"Audio-specific": ["Inaudible", "Background noise", "Speaker overlap", "Misinterpretation"],
"Style": ["Awkward", "Embarassing"],
"Unknown": [] # Category with no subcategories
}
},
"campaign_id": "custom_mqm_example",
"data": [...]
}
If mqm_categories is not provided, the default MQM taxonomy will be used. The empty string key "" provides an unselected state in the dropdown. Categories with empty subcategory lists (e.g., "Style": []) do not require a subcategory selection.
The severity levels can also be customized via mqm_severities (default: ["Minor", "Major"]):
"mqm_severities": ["Neutral", "Minor", "Major", "Critical"]
See examples/custom_mqm.json for a complete example.
Custom Instructions
Set campaign-level instructions using the instructions field in info (supports HTML).
Instructions default to protocol-specific ones (DA: scoring, ESA: error spans + scoring, MQM: error spans + categories + scoring).
{
"info": {
"protocol": "DA",
"instructions": "Rate translation quality on a 0-100 scale.<br>Pay special attention to document-level phenomena."
}
}
Pre-filled Error Spans (ESAAI)
Include error_spans to pre-fill annotations that users can review, modify, or delete:
{
"src": "The quick brown fox jumps over the lazy dog.",
"tgt": {"modelA": "Rychlá hnědá liška skáče přes líného psa."},
"error_spans": {
"modelA": [
{
"start_i": 0, # character index start (inclusive)
"end_i": 5, # character index end (inclusive)
"severity": "minor", # "minor", "major", "neutral", or null
"category": null # MQM category string or null
},
{
"start_i": 27,
"end_i": 32,
"severity": "major",
"category": null
}
]
}
}
The error_spans field is a 2D array (one per candidate). See examples/esaai_prefilled.json.
Tutorial and Attention Checks
Add validation rules for tutorials or attention checks. For tutorial items that users should be able to skip if they've seen them before, add skippable: true at the item level:
{
"src": "The quick brown fox jumps.",
"tgt": {"modelA": "Rychlá hnědá liška skáče."},
"skippable": true, # Show skip button for incomplete items
"validation": {
"modelA": {
"warning": "Please set score between 70-80.", # shown on failure (omit for silent logging)
"score": [70, 80], # required score range [min, max]
"error_spans": [{"start_i": [0, 2], "end_i": [4, 8], "severity": "minor"}] # expected spans
}
}
}
Types:
- Tutorial: Include
skippable: trueandwarningto let users skip after feedback - Loud attention checks: Include
warningwithoutskippableto force retry - Silent attention checks: Omit
warningto log failures without notification (quality control)
The validation field is an array (one per candidate). Dashboard shows ✅/❌ based on validation_threshold in info (integer for max failed count, float [0,1) for max proportion, default 0).
Score comparison: Use score_greaterthan to ensure one candidate scores higher than another:
{
"src": "AI transforms industries.",
"tgt": {"A": "UI transformuje průmysly.", "B": "Umělá inteligence mění obory."},
"validation": {
"A": [
{"warning": "A has error, score 20-40.", "score": [20, 40]}
],
"B": [
{"warning": "B is correct and must score higher than A.", "score": [70, 90], "score_greaterthan": "A"}
]
}
}
The score_greaterthan field specifies the index of the candidate that must have a lower score than the current candidate.
See examples/tutorial/esa_deen.json for a mock campaign with a fully prepared ESA tutorial.
To use it, simply extract the data attribute and prefix it to each task in your campaign.
Universal Tutorial Items with data_welcome
Use data_welcome to add tutorial items that users must complete before starting regular tasks. The structure is a list of documents (same as data). Welcome items have IDs welcome_0, welcome_1, etc. and are tracked separately via progress_welcome.
Form Items for User Metadata
Collect user information (demographics, expertise) before annotation tasks using form items in data_welcome.
Form items have text (label/question) and form (field type: null, "string", "number", "choices", and "script").
Documents must be homogeneous: all form items or all evaluation items.
{
"data_welcome": [
[
{"text": "What is your native language?", "form": "string"},
{"text": "Rate your expertise (1-10)", "form": "number"}
]
]
}

It is possible to automatically collect additional information from the host system using "script" field type.
Typically such a form document (or their sequence) would be stored in "data_welcome" such that it is both mandatory and show to all users.
See examples/user_info_form.json.
Single-stream Assignment
All annotators draw from a shared pool with random assignment:
{
"campaign_id": "my campaign 6",
"info": {
"assignment": "single-stream",
# DA: scores
# MQM: error spans and categories
# ESA: error spans and scores
"protocol": "ESA",
"users": 50, # number of annotators (can also be a list, see below)
"docs_per_user": 10, # optional: show goodbye after N documents per user
},
"data": [...], # list of all items (shared among all annotators)
}
Set docs_per_user to limit how many documents each user annotates before seeing the goodbye message (for single-stream, this is the number of documents).
Dynamic Assignment
The dynamic assignment type intelligently selects items based on current model performance to focus annotation effort on top-performing models using contrastive comparisons.
All items must contain outputs from all models for this assignment type to work properly.
{
"campaign_id": "my dynamic campaign",
"info": {
"assignment": "dynamic",
"protocol": "ESA",
"users": 10, # number of annotators
"dynamic_models": 2, # how many models to compare per item (optional, default: 1)
"dynamic_coldstart": 5, # annotations per model before dynamic kicks in (optional, default: 5)
"docs_per_user": 20, # optional: show goodbye after N documents per user
},
"data": [...], # list of all items (shared among all annotators)
}
Set docs_per_user to limit how many documents each user annotates before seeing the goodbye message (for dynamic, this is roughly the number of documents × models).
How it works:
- Initial phase: Each model gets
dynamic_coldstartannotations with fully random contrastive evaluation - Dynamic phase: After the initial phase, models sampled according to 1/rank (by average score) are identified
- Contrastive evaluation: From the top N models,
dynamic_modelsmodels are randomly selected for each item - Item prioritization: Items with the least annotations for the selected models are prioritized
This approach efficiently focuses annotation resources on distinguishing between the best-performing models while ensuring all models get adequate baseline coverage. The contrastive evaluation allows for direct comparison of multiple models simultaneously. For an example, see examples/dynamic.json.
Pre-defined User IDs and Tokens
The users field accepts:
- Number (e.g.,
50): Generate random user IDs - List of strings (e.g.,
["alice", "bob"]): Use specific user IDs - List of dictionaries: Specify custom tokens:
{
"info": {
...
"users": [
{"user_id": "alice", "token_pass": "alice_done", "token_fail": "alice_fail"},
{"user_id": "bob", "token_pass": "bob_done"} # missing tokens are auto-generated
],
},
...
}
Multimodal Annotations
Support for HTML-compatible elements (YouTube embeds, <video> tags, images). Ensure elements are pre-styled. See examples/multimodal.json.
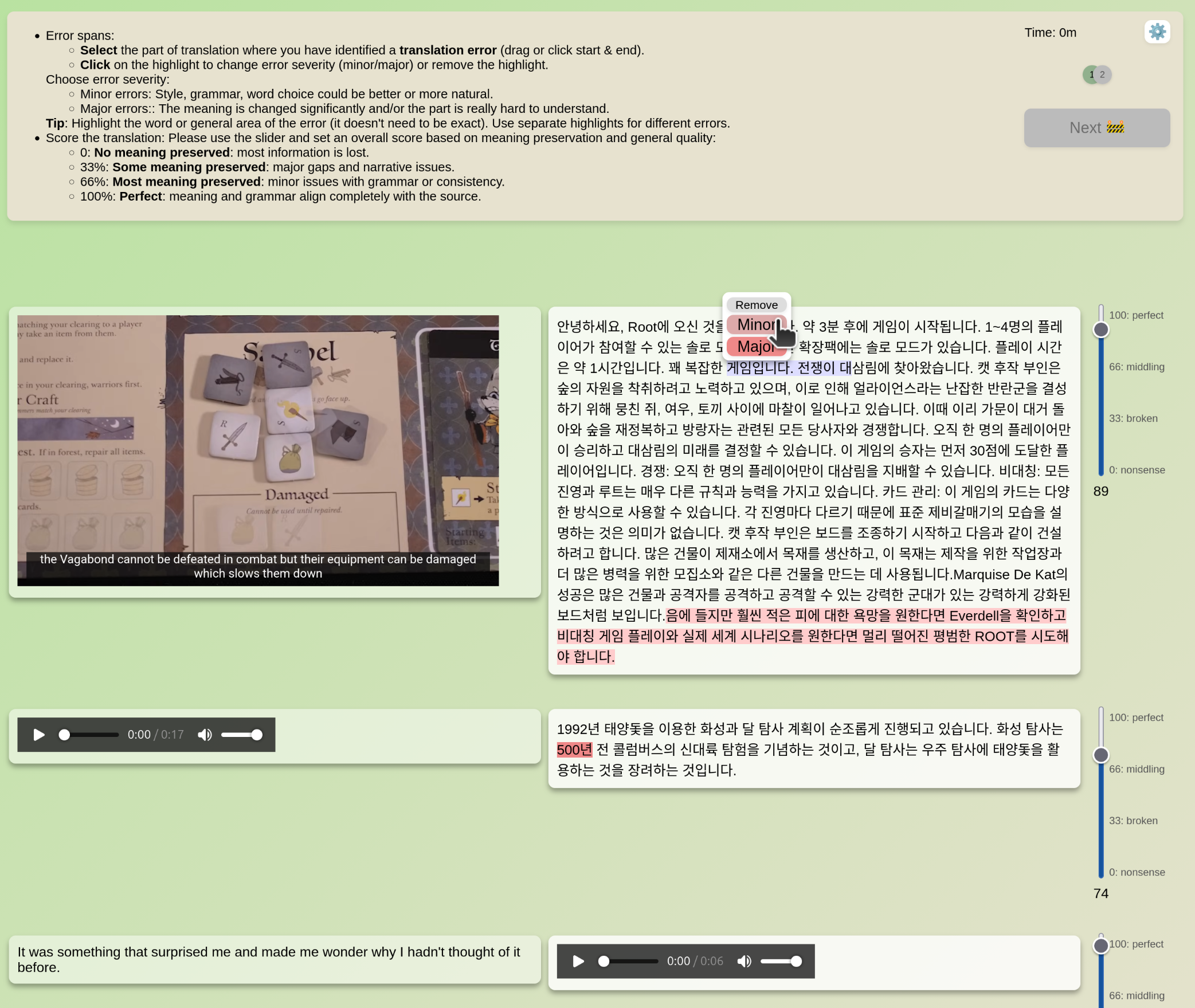
Hosting Assets
Host local assets (audio, images, videos) using the assets key:
{
"campaign_id": "my_campaign",
"info": {
"assets": {
"source": "videos", # Source directory
"destination": "assets/my_videos" # Mount path (must start with "assets/")
}
},
"data": [ ... ]
}
Files from videos/ become accessible at localhost:8001/assets/my_videos/. Creates a symlink, so source directory must exist throughout annotation. Destination paths must be unique across campaigns.
CLI Commands
pearmut add <file(s)>: Add campaign JSON files (supports wildcards)-o/--overwrite: Replace existing campaigns with same ID--url <url>: Server URL prefix (default:http://localhost:8001)
pearmut run: Start server--port <port>: Server port (default: 8001)--url <url>: Server URL prefix
pearmut purge [campaign]: Remove campaign data- Without args: Purge all campaigns
- With campaign name: Purge specific campaign only
PEARMUT_ROOT=<path> pearmut: User pearmut with custom root directoryPEARMUT_TOKEN_MAIN=<token> pearmut run: Main admin token
Campaign Management
Management link (shown when adding campaigns or running server) provides:
- Annotator progress overview
- Access to annotation links
- Task progress reset (data preserved)
- Download progress and annotations
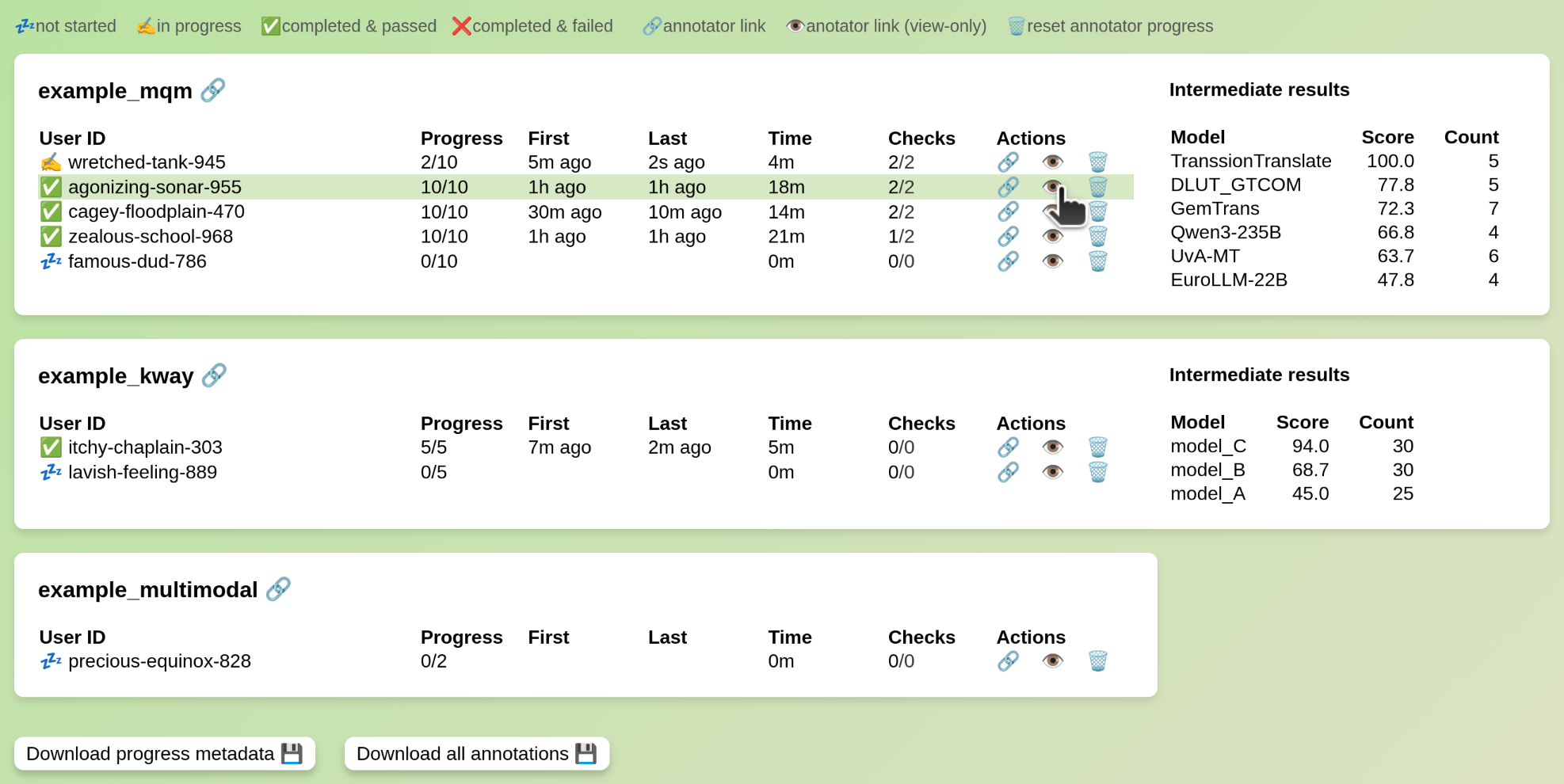
Completion tokens are shown at annotation end for verification (download correct tokens from dashboard). Incorrect tokens can be shown if quality control fails.

When tokens are supplied, the dashboard will try to show model rankings based on the names in the dictionaries.
Custom Completion Messages
Customize the goodbye message shown to users when they complete all annotations using the instructions_goodbye field in campaign info. Supports arbitrary HTML for styling and formatting with variable replacement: ${TOKEN} (completion token) and ${USER_ID} (user ID). Default: "If someone asks you for a token of completion, show them: ${TOKEN}".
Prolific Integration
Use task-based assignment with Prolific. For each task, Pearmut generates a unique URL which can be uploaded to Prolific's interface. Add redirect (on completion) to instructions_goodbye:
"instructions_goodbye": "<a href='https://app.prolific.com/submissions/complete?cc=${TOKEN}'>Click here to return to Prolific</a>"
The ${TOKEN} is automatically replaced based on passing attention checks (see Attention checks and Pre-defined tokens).
Terminology
- Campaign: An annotation project that contains configuration, data, and user assignments. Each campaign has a unique identifier and is defined in a JSON file.
- Campaign File: A JSON file that defines the campaign configuration, including the campaign ID, assignment type, protocol settings, and annotation data.
- Campaign ID: A unique identifier for a campaign (e.g.,
"wmt25_#_en-cs_CZ"). Used to reference and manage specific campaigns. Typically a campaign is created for a specific language and domain.
- Task: A unit of work assigned to a user. In task-based assignment, each task consists of a predefined set of items for a specific user.
- Item: A single annotation unit within a task. For translation evaluation, an item typically represents a document (source text and target translation). Items can contain text, images, audio, or video.
- Document: A collection of one or more segments (sentence pairs or text units) that are evaluated together as a single item.
- User / Annotator: A person who performs annotations in a campaign. Each user is identified by a unique user ID and accesses the campaign through a unique URL.
- Attention Check: A validation item with known correct answers used to ensure annotator quality. Can be:
- Loud: Shows warning message and forces retry on failure
- Silent: Logs failures without notifying the user (for quality control analysis)
- Token: A completion code shown to users when they finish their annotations. Tokens verify the completion and whether the user passed quality control checks:
- Pass Token (
token_pass): Shown when user meets validation thresholds - Fail Token (
token_fail): Shown when user fails to meet validation requirements
- Pass Token (
- Tutorial: An instructional validation item that teaches users how to annotate. Items with
skippable: truecan be skipped if users have already completed the tutorial. - Validation: Quality control rules attached to items that check if annotations match expected criteria (score ranges, error span locations, etc.). Used for tutorials and attention checks.
- Model: The system or model that generated the output being evaluated (e.g.,
"GPT-4","Claude"). Used for tracking and ranking model performance. - Dashboard: The management interface that shows campaign progress, annotator statistics, access links, and allows downloading annotations. Accessed via a special management URL with token authentication.
- Protocol: The annotation scheme defining what data is collected:
- Score: Numeric quality rating (0-100)
- Error Spans: Text highlights marking errors with severity (
minor,major) - Error Categories: MQM taxonomy labels for errors
- Template: The annotation interface type. The
annotatetemplate supports comparing multiple outputs simultaneously. - Assignment: The method for distributing items to users:
- Task-based: Each user has predefined items
- Single-stream: Users draw from a shared pool with random assignment
- Dynamic: Items are intelligently assigned based on model performance to focus on top models
Development
Server responds to data-only requests from frontend (no template coupling). Frontend served from pre-built static/ on install.
Local development:
cd pearmut
# Frontend (separate terminal, recompiles on change)
npm install web/ --prefix web/
npm run build --prefix web/
# optionally keep running indefinitely to auto-rebuild
npm run watch --prefix web/
# Install as editable
pip3 install -e .
# Load examples
pearmut add examples/wmt25_#_en-cs_CZ.json examples/wmt25_#_cs-de_DE.json
pearmut run
Creating new protocols:
- Add HTML and TS files to
web/src - Add build rule to
webpack.config.js - Reference as
info->templatein campaign JSON
See web/src/annotate.ts for example.
Deployment
Run on public server or tunnel local port to public IP/domain and run locally.
Citation
If you use this work in your paper, please cite as following.
@misc{zouhar2026pearmut,
title={Pearmut: Human Evaluation of Translation Made Trivial},
author={Vilém Zouhar and Tom Kocmi},
year={2026},
eprint={2601.02933},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.02933},
}
Contributions are welcome! Please reach out to Vilém Zouhar. See changes in CHANGELOG.md.

Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pearmut-1.1.4.tar.gz.
File metadata
- Download URL: pearmut-1.1.4.tar.gz
- Upload date:
- Size: 115.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8a012d772447a40572cf0e963cbf0c716dd0e4dfa129ce70cc044c3e04c3bd65
|
|
| MD5 |
431398719daae6657b95672cd17c9d69
|
|
| BLAKE2b-256 |
b40811187dfd3c80c4717c63f74eb880b6f7d3d1d10ffe938a00cf7af6db8710
|
Provenance
The following attestation bundles were made for pearmut-1.1.4.tar.gz:
Publisher:
publish.yml on zouharvi/pearmut
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pearmut-1.1.4.tar.gz -
Subject digest:
8a012d772447a40572cf0e963cbf0c716dd0e4dfa129ce70cc044c3e04c3bd65 - Sigstore transparency entry: 1418511530
- Sigstore integration time:
-
Permalink:
zouharvi/pearmut@33a089fa254c0425289202c84e5662d8571a89a0 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/zouharvi
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@33a089fa254c0425289202c84e5662d8571a89a0 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file pearmut-1.1.4-py3-none-any.whl.
File metadata
- Download URL: pearmut-1.1.4-py3-none-any.whl
- Upload date:
- Size: 119.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
12f5a9a6990e1ba7252e55e308069725c85124c51e71c9e1f3b1046c08308587
|
|
| MD5 |
9dae4017d0f0deaca36e0018fae7e858
|
|
| BLAKE2b-256 |
69edc4d2e54fa33e8fba92a51cc4d002c0599a5eabb521b905fc8c5cb7adb265
|
Provenance
The following attestation bundles were made for pearmut-1.1.4-py3-none-any.whl:
Publisher:
publish.yml on zouharvi/pearmut
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pearmut-1.1.4-py3-none-any.whl -
Subject digest:
12f5a9a6990e1ba7252e55e308069725c85124c51e71c9e1f3b1046c08308587 - Sigstore transparency entry: 1418511623
- Sigstore integration time:
-
Permalink:
zouharvi/pearmut@33a089fa254c0425289202c84e5662d8571a89a0 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/zouharvi
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@33a089fa254c0425289202c84e5662d8571a89a0 -
Trigger Event:
workflow_dispatch
-
Statement type:







