A high-performance and user-friendly Python package for OPLS-DA, aligned with 'ropls'. Features parallel permutation tests with dynamic progress tracking, and publication-ready visualizations.

Project description
π-OPLS-DA (pi-oplsda)



pi-oplsda bridges the gap between the rigorous algorithmic foundation of the gold-standard R package ropls and the modern Python data science ecosystem. It delivers blazing-fast parallel computing, native Pandas integration, and publication-ready visualizations—all in one lightweight package.
✨ Core Capabilities
- Standardized Rigor: Perfectly replicates
roplsstep-wise variance increments ($R^2X$, $R^2Y$, $Q^2$) and NIPALS-based orthogonal signal correction (OSC). - Pandas Native: Seamlessly feed
pandas.DataFrameinto the model. Sample IDs and feature names are automatically tracked, eliminating the need for tedious matrix index management. - Multi-Core Acceleration: Powered by
joblib, permutation tests are fully parallelized. - Publication-Ready Graphics: Built on
matplotlibandseabornto generate clean, high-resolution diagnostic plots with smart legend placement. - Structured Export: Extract model parameters, sample scores, and biomarker statistics (VIP, Covariance, Correlation) as instantly usable DataFrames for downstream pipelines.
Note: Due to the nature of eigen-decomposition, the signs of scores and loadings may be flipped between platforms. This is mathematically equivalent and does not affect biological interpretation.
📦 Installation
You can install pi-oplsda using either of the following methods, depending on whether you simply want to use the package or if you plan to modify the source code.
Option 1: Install directly from pypi or GitHub (Recommended for most users)
# Install module from The Python Package Index (PyPI)
pip install pi-oplsda
# Or you can choose install module from GitHub
pip install git+https://github.com/KaikunXu/pi-oplsda.git
Option 2: Install from source (For developers)
If you want to contribute to the project, modify the algorithm, or explore the source code, you can clone the repository and install it in "editable" mode. This means any changes you make to the local code will immediately take effect without needing to reinstall the package.
# 1. Clone the repository
git clone https://github.com/KaikunXu/pi-oplsda.git
# 2. Navigate into the project directory
cd pi-oplsda
# 3. Install in editable mode
pip install -e .
🚀 Quickstart & Tutorials
We provide interactive Jupyter Notebooks that walk you through the entire OPLS-DA workflow and our rigorous validation process:
- Quickstart Tutorial: A comprehensive guide from data loading to visualization and prediction.
- R-ropls Equivalence Benchmark: The complete script used to prove numerical consistency between Python and R implementations.
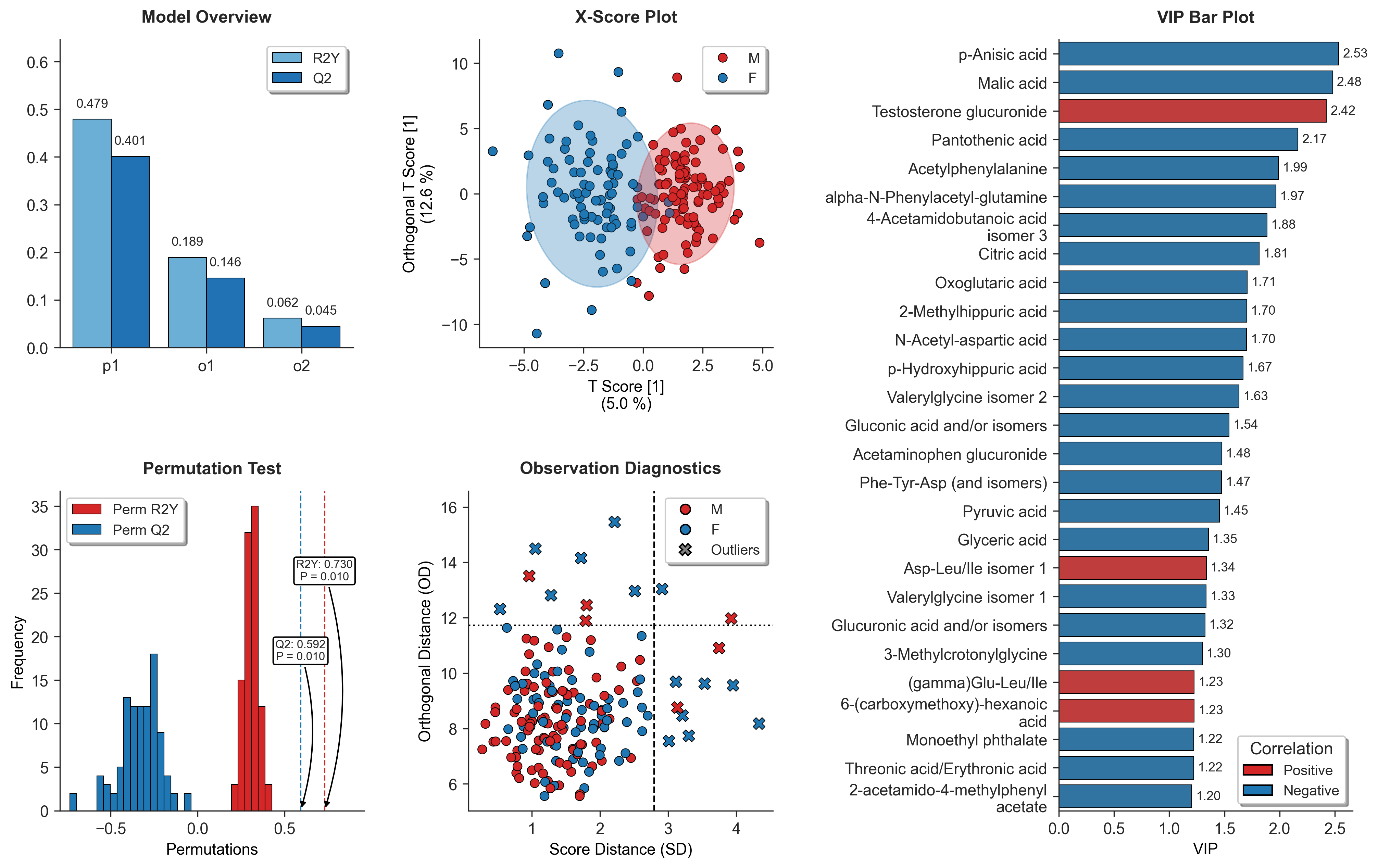
📈 Visualization
Running the OPLSDA_Visualizer will automatically generate a suite of tightly integrated diagnostic subplots to evaluate your model from multiple dimensions:
- Model Overview: Displays the step-wise increments of $R^2Y$ and $Q^2$ for both predictive and orthogonal components, illustrating the model's global explanatory and predictive capacity.
- X-Score Plot: Visualizes sample clustering and separation in the predictive latent space, complete with 95% Hotelling's $T^2$ confidence ellipses.
- Observation Diagnostics: Evaluates the relationship between sample influence (Score Distance) and model fit (Orthogonal Distance / DModX) to robustly identify multivariate outliers.
- Permutation Test: Validates model robustness against overfitting by comparing the original $R^2Y$ and $Q^2$ against permuted null distributions, providing empirical p-values.
- VIP Bar Plot: Ranks the top features contributing to group separation. It features automatic text wrapping for excessively long metabolite names on the Y-axis to ensure clean, publication-ready layouts.
- S-Plot (Optional): Highlights potential biomarkers based on the interplay between covariance (magnitude) and correlation (reliability). (Note: This plot is available exclusively for binary classification models, as demonstrated in the Quickstart Tutorial).
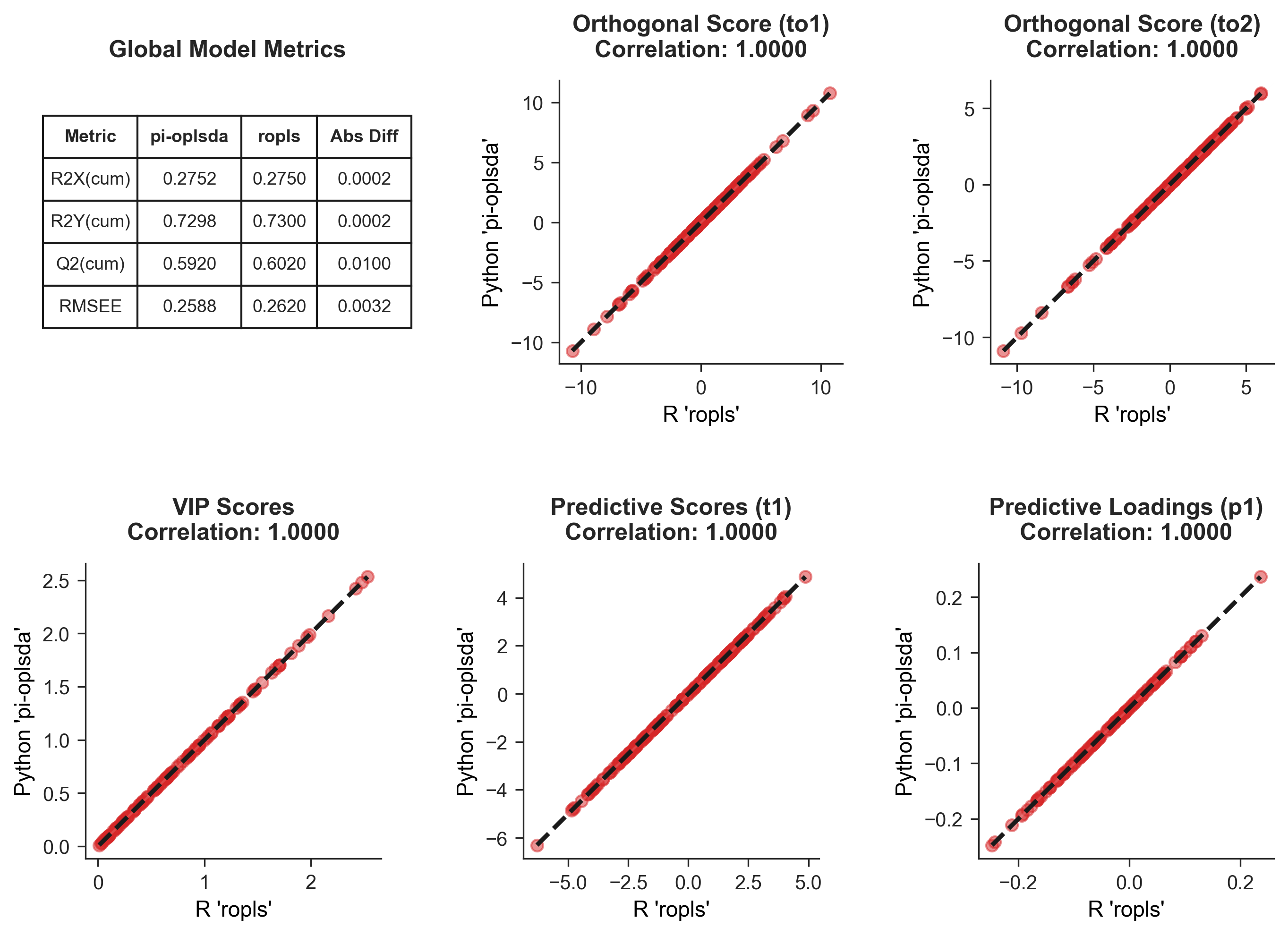
🎯 Mathematical Equivalence & Benchmarking
pi-oplsda is strictly validated against the gold-standard R package ropls (Bioconductor) to ensure scientific integrity. Our cross-platform benchmarking demonstrates that pi-oplsda produces numerically identical results across all key OPLS-DA metrics.
Using the Sacurine human urine dataset (183 samples, 109 metabolites), we compared the Python and R implementations:
| Metric | Description | Comparison |
|---|---|---|
| Global Quality | Cumulative $R^2X$, $R^2Y$, and $Q^2$ | Approximately equal |
| Error Assessment | Root Mean Square Error of Estimation (RMSEE) | Approximately equal |
| Latent Space | Predictive Scores ($t_1$, $to_{n}$) and Loadings ($p_1$) | Pearson's r > 0.999 |
| Variable Importance | Variable Importance in Projection (VIP) scores | Pearson's r > 0.999 |
Cross-platform benchmarking demonstrates that pi-oplsda produces numerically identical results across all key OPLS-DA metrics. To ensure a rigorous, one-to-one comparison of the underlying computational results, the testing process directly invokes the R engine via the rpy2 interface. Model parameters were strictly aligned between platforms, fixing the predictive component to 1, optimizing orthogonal components (n=3), and employing 7-fold cross-validation.
In the visualizations below, the solid red scatter points map the values generated by both platforms as coordinate pairs ($x_{\text{ropls}}, y_{\text{pi-oplsda}}$), while the dashed black lines denote the ideal axis of perfect equivalence ($y=x$). The exceptionally high correlation coefficients ($r \approx 1.0000$) provide mathematical proof of algorithmic identity:
- Global Model Metrics (Top-Left): Compares the overall cumulative explained variance ($R^2X$, $R^2Y$), cross-validated predictability ($Q^2$), and Root Mean Square Error of Estimation (RMSEE). The negligible absolute differences (Abs Diff $< 10^{-2}$) confirm macroscopic equivalence.
- Orthogonal Latent Space (Top-Right): Displays the correlation of the orthogonal score vectors (e.g., $t_{o1}, t_{o2}$). This confirms that both models possess identical geometric capabilities in extracting and filtering intra-class structured noise.
- Feature Importance & Predictive Space (Bottom Row): Illustrates the three critical vectors driving the discriminatory power of OPLS-DA: VIP Scores (determining biomarker ranking), Predictive Scores $t_1$ (driving sample clustering), and Predictive Loadings $p_1$ (determining feature weights). The diagonal alignment confirms absolute accuracy in microscopic sample profiling and feature extraction.
🤝 Acknowledgements
The algorithmic foundation of pi-oplsda is deeply inspired by the excellent R package ropls.
Note: Portions of this codebase, including code refactoring and documentation, were refined with the assistance of Gemini 3.1 Pro. All AI-assisted contributions have been strictly reviewed by the human author to ensure scientific accuracy and code quality.
🛠 Contributing
Contributions, issues, and feature requests are welcome! Feel free to check the issues page.
📄 License
This project is licensed under the MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pi_oplsda-1.0.2.tar.gz.
File metadata
- Download URL: pi_oplsda-1.0.2.tar.gz
- Upload date:
- Size: 133.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
28357e3bd3e24d09a2c03ed853f9a262d5e05f5df5677f6f894b98c42fb7b79d
|
|
| MD5 |
d85f3f8f6ec81ccce2d23f27dbfa5cb9
|
|
| BLAKE2b-256 |
4b1f543251bfaa834152ff727e767b8d54f6c2f77578b4f537a46493881133d3
|
File details
Details for the file pi_oplsda-1.0.2-py3-none-any.whl.
File metadata
- Download URL: pi_oplsda-1.0.2-py3-none-any.whl
- Upload date:
- Size: 131.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2237c68429c6146194c828831ac2a3bda7c60130c98b10614649168fc51ad4bb
|
|
| MD5 |
e8a4c1e6b0d98aa73270c038d1e154b0
|
|
| BLAKE2b-256 |
11067db35caf0775693d60789eb32604c630412aa1766312858f97dd0a65dee2
|







