Data workflows, cli and dataflow automation.

Project description
🍋 pipelime



If life gives you lemons, use pipelime.
Welcome to pipelime, a swiss army knife for data processing!
pipelime is a full-fledge framework for data science: read your datasets,
manipulate them, write back to disk or upload to a remote data lake.
Then build up your dataflow with Piper and manage the configuration with Choixe.
Finally, embed your custom commands into the pipelime workspace, to act both as dataflow nodes and advanced command line interface.
Maybe too much for you? No worries, pipelime is modular and you can just take out what you need:
- data processing scripts: use the powerful
SamplesSequenceand create your own data processing pipelines, with a simple and intuitive API. Parallelization works out-of-the-box and, moreover, you can easily serialize your pipelines to yaml/json. Integrations with popular frameworks, e.g., pytorch, are also provided. - easy dataflow:
Pipercan manage and execute directed acyclic graphs (DAGs), giving back feedback on the progress through sockets or custom callbacks. - configuration management:
Choixeis a simple and intuitive mini scripting language designed to ease the creation of configuration files with the help of variables, symbol importing, for loops, switch statements, parameter sweeps and more. - command line interface:
pipelimecan remove all the boilerplate code needed to create a beautiful CLI for you scripts and packages. You focus on what matters and we provide input parsing, advanced interfaces for complex arguments, automatic help generation, configuration management. Also, anyPipelimeCommandcan be used as a node in a dataflow for free! - pydantic tools: most of the classes in
pipelimederive frompydantic.BaseModel, so we have built some useful tools to, e.g., inspect their structure, auto-generate human-friendly documentation and more (including a wizard to help you writing input data to deserialize any pydantic model).
Installation
Install pipelime using pip:
pip install pipelime-python
To be able to draw the dataflow graphs, you need the draw variant:
pip install pipelime-python[draw]
Warning
The
drawvariant needsGraphvizhttps://www.graphviz.org/ installed on your system On Linux Ubuntu/Debian, you can install it with:sudo apt-get install graphviz graphviz-devAlternatively you can use
condaconda install --channel conda-forge pygraphvizPlease see the full options at https://github.com/pygraphviz/pygraphviz/blob/main/INSTALL.txt
Basic Usage
Underfolder Format
The Underfolder format is the preferred pipelime dataset formats, i.e., a flexible way to
model and store a generic dataset through filesystem.
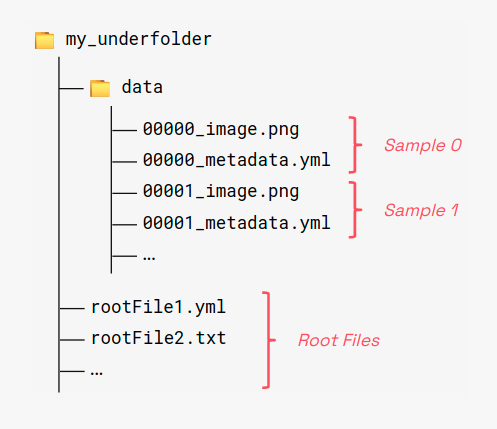
An Underfolder dataset is a collection of samples. A sample is a collection of items.
An item is a unitary block of data, i.e., a multi-channel image, a python object,
a dictionary and more.
Any valid underfolder dataset must contain a subfolder named data with samples
and items. Also, global shared items can be stored in the root folder.
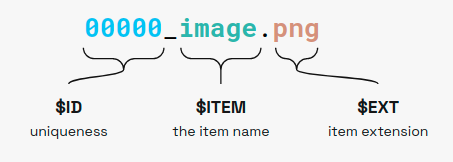
Items are named using the following naming convention:
Where:
$IDis the sample index, must be a unique integer for each sample.ITEMis the item name.EXTis the item extension.
We currently support many common file formats and others can be added by users:
.png,.jpeg/.jpg/.jfif/.jpe,.bmpfor images.tiff/.tiffor multi-page images and multi-dimensional numpy arrays.yaml/.yml,.jsonand.toml/.tmlfor metadata.txtfor numpy 2D matrix notation.npyfor general numpy arrays.pkl/.picklefor picklable python objects.binfor generic binary data
Root files follow the same convention but they lack the sample identifier part, i.e., $ITEM.$EXT
Reading an Underfolder Dataset
pipelime provides an intuitive interface to read, manipulate and write Underfolder Datasets.
No complex signatures, weird object iterators, or boilerplate code, you just need a SamplesSequence:
from pipelime.sequences import SamplesSequence
# Read an underfolder dataset with a single line of code
dataset = SamplesSequence.from_underfolder('tests/sample_data/datasets/underfolder_minimnist')
# A dataset behaves like a Sequence
print(len(dataset)) # the number of samples
sample = dataset[4] # get the fifth sample
# A sample is a mapping
print(len(sample)) # the number of items
print(set(sample.keys())) # the items' keys
# An item is an object wrapping the actual data
image_item = sample["image"] # get the "image" item from the sample
print(type(image_item)) # <class 'pipelime.items.image_item.PngImageItem'>
image = image_item() # actually loads the data from disk (may have been on the cloud as well)
print(type(image)) # <class 'numpy.ndarray'>
Writing an Underfolder Dataset
You can write a dataset by calling the associated operation:
# Attach a "write" operation to the dataset
dataset = dataset.to_underfolder('/tmp/my_output_dataset')
# Now run over all the samples
dataset.run()
# You can easily spawn multiple processes if needed
dataset.run(num_workers=4)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pipelime_python-1.4.0.tar.gz.
File metadata
- Download URL: pipelime_python-1.4.0.tar.gz
- Upload date:
- Size: 126.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5ff32a4964039868492ae94b03d6de63e153116182d6268d3eebc23a1c99c244
|
|
| MD5 |
fa22a47ede942660c499628dd14ad723
|
|
| BLAKE2b-256 |
34703ea8205a1455e976b09018dd9f3a87a36032a672fd2a0fd21fc5294ea4f5
|
File details
Details for the file pipelime_python-1.4.0-py3-none-any.whl.
File metadata
- Download URL: pipelime_python-1.4.0-py3-none-any.whl
- Upload date:
- Size: 172.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9d69fe76ed8832d19cb761fb2fde4deed1c45dd57329c221fc1881d45203722b
|
|
| MD5 |
c6f6d10e96a0d06bdbd50b32ec073ba8
|
|
| BLAKE2b-256 |
f6b9ed947a09aa13d19de00facb6d7fcf43b6cb5a02d5cd4a0fb525529e03a0d
|







