pix2tex: Using a ViT to convert images of equations into LaTeX code.

Project description
pix2tex - LaTeX OCR








The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
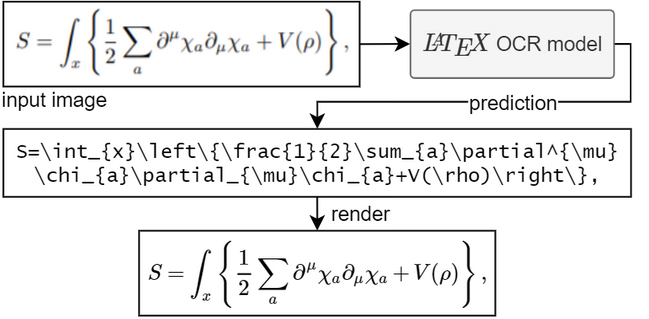
Using the model
To run the model you need Python 3.7+
If you don't have PyTorch installed. Follow their instructions here.
Install the package pix2tex:
pip install "pix2tex[gui]"
Model checkpoints will be downloaded automatically.
There are three ways to get a prediction from an image.
-
You can use the command line tool by calling
pix2tex. Here you can parse already existing images from the disk and images in your clipboard. -
Thanks to @katie-lim, you can use a nice user interface as a quick way to get the model prediction. Just call the GUI with
latexocr. From here you can take a screenshot and the predicted latex code is rendered using MathJax and copied to your clipboard.Under linux, it is possible to use the GUI with
gnome-screenshot(which comes with multiple monitor support). For other Wayland compositers,grimandslurpwill be used for wlroots-based Wayland compositers andspectaclefor KDE Plasma. Note thatgnome-screenshotis not compatible with wlroots or Qt based compositers. Sincegnome-screenshotwill be preferred when available, you may have to set the environment variableSCREENSHOT_TOOLtogrimorspectaclein these cases (other available values aregnome-screenshotandpil).If the model is unsure about the what's in the image it might output a different prediction every time you click "Retry". With the
temperatureparameter you can control this behavior (low temperature will produce the same result). -
You can use an API. This has additional dependencies. Install via
pip install -U "pix2tex[api]"and runpython -m pix2tex.api.run
to start a Streamlit demo that connects to the API at port 8502. There is also a docker image available for the API: https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:apiTo also run the streamlit demo run
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.pyand navigate to http://localhost:8501/
-
Use from within Python
from PIL import Image from pix2tex.cli import LatexOCR img = Image.open('path/to/image.png') model = LatexOCR() print(model(img))
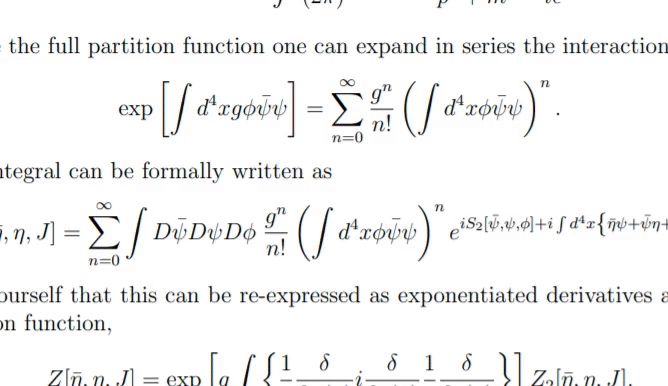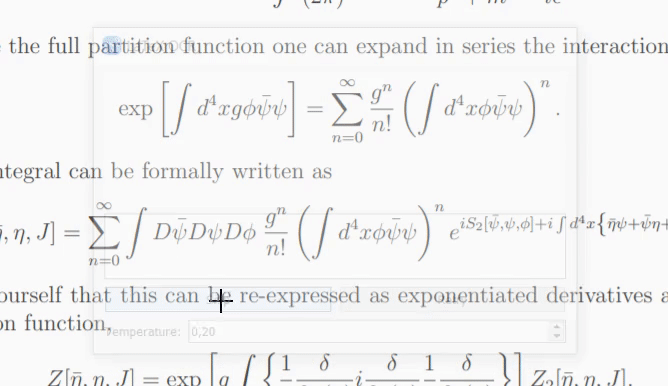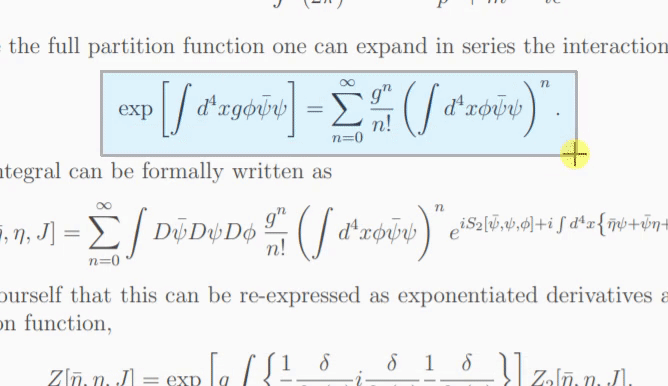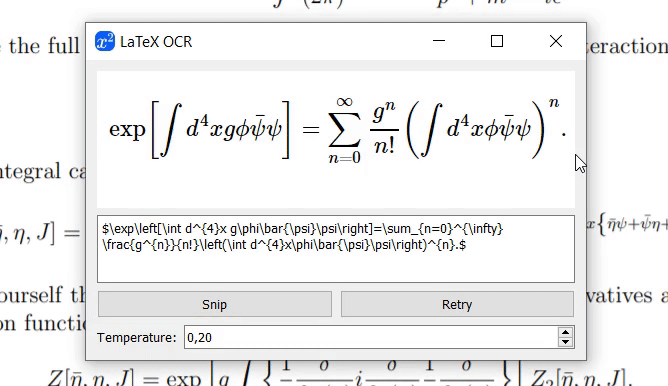

The model works best with images of smaller resolution. That's why I added a preprocessing step where another neural network predicts the optimal resolution of the input image. This model will automatically resize the custom image to best resemble the training data and thus increase performance of images found in the wild. Still it's not perfect and might not be able to handle huge images optimally, so don't zoom in all the way before taking a picture.
Always double check the result carefully. You can try to redo the prediction with an other resolution if the answer was wrong.
Want to use the package?
I'm trying to compile a documentation right now.
Visit here: https://pix2tex.readthedocs.io/
Training the model
Install a couple of dependencies pip install "pix2tex[train]".
- First we need to combine the images with their ground truth labels. I wrote a dataset class (which needs further improving) that saves the relative paths to the images with the LaTeX code they were rendered with. To generate the dataset pickle file run
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
To use your own tokenizer pass it via --tokenizer (See below).
You can find my generated training data on the Google Drive as well (formulae.zip - images, math.txt - labels). Repeat the step for the validation and test data. All use the same label text file.
- Edit the
data(andvaldata) entry in the config file to the newly generated.pklfile. Change other hyperparameters if you want to. Seepix2tex/model/settings/config.yamlfor a template. - Now for the actual training run
python -m pix2tex.train --config path_to_config_file
If you want to use your own data you might be interested in creating your own tokenizer with
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
Don't forget to update the path to the tokenizer in the config file and set num_tokens to your vocabulary size.
Model
The model consist of a ViT [1] encoder with a ResNet backbone and a Transformer [2] decoder.
Performance
| BLEU score | normed edit distance | token accuracy |
|---|---|---|
| 0.88 | 0.10 | 0.60 |
Data
We need paired data for the network to learn. Luckily there is a lot of LaTeX code on the internet, e.g. wikipedia, arXiv. We also use the formulae from the im2latex-100k [3] dataset. All of it can be found here
Dataset Requirements
In order to render the math in many different fonts we use XeLaTeX, generate a PDF and finally convert it to a PNG. For the last step we need to use some third party tools:
- XeLaTeX
- ImageMagick with Ghostscript. (for converting pdf to png)
- Node.js to run KaTeX (for normalizing Latex code)
- Python 3.7+ & dependencies (specified in
setup.py)
Fonts
Latin Modern Math, GFSNeohellenicMath.otf, Asana Math, XITS Math, Cambria Math
TODO
- add more evaluation metrics
- create a GUI
- add beam search
- support handwritten formulae (kinda done, see training colab notebook)
- reduce model size (distillation)
- find optimal hyperparameters
- tweak model structure
- fix data scraping and scrape more data
- trace the model (#2)
Contribution
Contributions of any kind are welcome.
Acknowledgment
Code taken and modified from lucidrains, rwightman, im2markup, arxiv_leaks, pkra: Mathjax, harupy: snipping tool
References
[1] An Image is Worth 16x16 Words
[3] Image-to-Markup Generation with Coarse-to-Fine Attention
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pix2tex-0.1.4-py3-none-any.whl.
File metadata
- Download URL: pix2tex-0.1.4-py3-none-any.whl
- Upload date:
- Size: 427.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.7.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a024309508fc3e8a4ce5241e095276626d098df53e609410013f2ec35a4b7612
|
|
| MD5 |
580de02f6788eff06e51bd9ac92abe14
|
|
| BLAKE2b-256 |
12b8673667ace0a131169502420810aa9dfca69aad960d5af88da68ddd46c7f0
|







