Deep generative modeling library



Project description
Pixyz: A library for developing deep generative models








What is Pixyz?
Pixyz is a high-level deep generative modeling library, based on PyTorch. It is developed with a focus on enabling easy implementation of various deep generative models.
Recently, many papers about deep generative models have been published. However, its reproduction becomes a hard task, for both specialists and practitioners, because such recent models become more complex and there are no unified tools that bridge mathematical formulation of them and implementation. The vision of our library is to enable both specialists and practitioners to implement such complex deep generative models by just as if writing the formulas provided in these papers.
Our library supports the following deep generative models.
- Explicit models (likelihood-based)
- Variational autoencoders (variational inference)
- Flow-based models
- Autoregressive generative models (note: not implemented yet)
- Implicit models
- Generative adversarial networks
Moreover, Pixyz enables you to implement these different models in the same framework and in combination with each other.
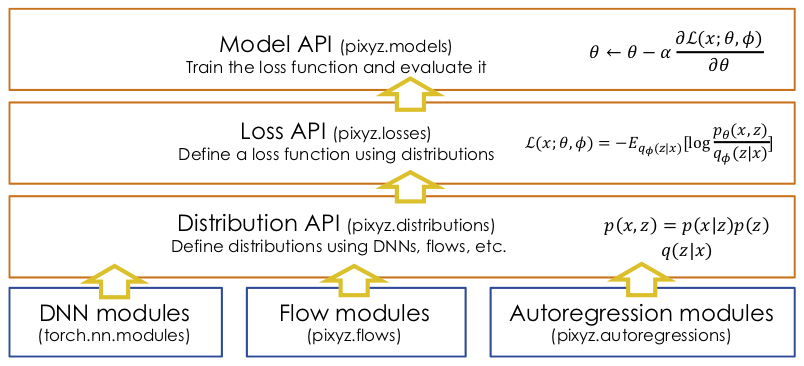
The overview of Pixyz is as follows. Each API will be discussed below.
Note: Since this library is under development, there are possibilities to have some bugs.
Installation
Pixyz can be installed by using pip.
$ pip install pixyz
If installing from source code, execute the following commands.
$ git clone https://github.com/masa-su/pixyz.git
$ pip install -e pixyz
You can also install pixyz and PyTorch environment through Docker Hub
# pull docker image from https://hub.docker.com/r/kenoharada/pixyz
$ docker pull kenoharada/pixyz:v0.3.0_python_3.7.7_pytorch_1.6.0_cuda_10.1
# Run pixyz environment
$ docker run --runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=0 --rm -it kenoharada/pixyz:v0.3.0_python_3.7.7_pytorch_1.6.0_cuda_10.1
Quick Start
Here, we consider to implement a variational auto-encoder (VAE) which is one of the most well-known deep generative models. VAE is composed of a inference model
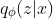
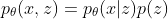
![\mathcal{L}(x;\phi,\theta)=-E_{q_{\phi}(z|x)}\left[\log{p_{\theta}(x|z)}\right]+D_{KL}\left[q_{\phi}(z|x)||p_{prior}(z)\right]](https://pypi-camo.freetls.fastly.net/b18b593bce0b2342da6d54d485fe66eee88e278b/68747470733a2f2f6c617465782e636f6465636f67732e636f6d2f6769662e6c617465783f5c6d61746863616c7b4c7d28783b5c7068692c5c7468657461293d2d455f7b715f7b5c7068697d287a7c78297d5c6c6566745b5c6c6f677b705f7b5c74686574617d28787c7a297d5c72696768745d2b445f7b4b4c7d5c6c6566745b715f7b5c7068697d287a7c78297c7c705f7b7072696f727d287a295c72696768745d)
In Pixyz, deep generative models are implemented in the following three steps:
- Define distributions(Distribution API)
- Set the loss function of a model(Loss API)
- Train the model(Model API)
1. Define distributions(Distribution API)
First, we need to define two distributions (
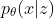
pixyz.distributions.* class (Distribution API), instead of torch.nn.Module .
For example,
>>> from pixyz.distributions import Bernoulli, Normal
>>> # inference model (encoder) q(z|x)
>>> class Inference(Normal):
... def __init__(self):
... super(Inference, self).__init__(var=["z"],cond_var=["x"],name="q") # var: variables of this distribution, cond_var: coditional variables.
... self.fc1 = nn.Linear(784, 512)
... self.fc21 = nn.Linear(512, 64)
... self.fc22 = nn.Linear(512, 64)
...
... def forward(self, x): # the name of this argument should be same as cond_var.
... h = F.relu(self.fc1(x))
... return {"loc": self.fc21(h),
... "scale": F.softplus(self.fc22(h))} # return parameters of the normal distribution
...
>>> # generative model (decoder) p(x|z)
>>> class Generator(Bernoulli):
... def __init__(self):
... super(Generator, self).__init__(var=["x"], cond_var=["z"], name="p")
... self.fc1 = nn.Linear(64, 512)
... self.fc2 = nn.Linear(512, 128)
...
... def forward(self, z): # the name of this argument should be same as cond_var.
... h = F.relu(self.fc1(z))
... return {"probs": F.sigmoid(self.fc2(h))} # return a parameter of the Bernoulli distribution
Once defined, you can create instances of these classes.
>>> p = Generator()
>>> q = Inference()
In VAE,
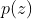
pixyz.distributions.* as
>>> prior = Normal(loc=torch.tensor(0.), scale=torch.tensor(1.),
... var=["z"], features_shape=[64], name="p_prior")
If you want to find out what kind of distribution each instance defines and what modules (the network architecture) define it, just print them.
>>> print(p)
Distribution:
p(x|z)
Network architecture:
Generator(
name=p, distribution_name=Bernoulli,
var=['x'], cond_var=['z'], input_var=['z'], features_shape=torch.Size([])
(fc1): Linear(in_features=64, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=512, bias=True)
(fc3): Linear(in_features=512, out_features=784, bias=True)
)
If you are working on the iPython environment, you can use print_latex to display them in the LaTeX compiled format.

Conveniently, each distribution instance can perform sampling over given samples, regardless of the form of the internal DNN modules.
>>> samples_z = prior.sample(batch_n=1)
>>> print(samples_z)
{'z': tensor([[ 0.6084, 1.4716, 0.6413, 1.3184, -0.8930, 0.0603, 1.2254, 0.5910, ..., 0.8389]])}
>>> samples = p.sample(samples_z)
>>> print(samples)
{'z': tensor([[ 1.5377, 0.4713, 0.0354, 0.5013, 1.2584, 0.8908, 0.6323, 1.0844, ..., -0.7603]]),
'x': tensor([[0., 1., 0., 1., 0., 0., 1., 1., 0., 0., 1., 1., 1., 1., ..., 0.]])}
As in this example, samples are represented in dictionary forms in which the keys correspond to random variable names and the values are their realized values.
Moreover, the instance of joint distribution
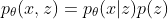
>>> p_joint = p * prior
This instance can be checked as
>>> print(p_joint)
Distribution:
p(x,z) = p(x|z)p_{prior}(z)
Network architecture:
Normal(
name=p_{prior}, distribution_name=Normal,
var=['z'], cond_var=[], input_var=[], features_shape=torch.Size([64])
(loc): torch.Size([1, 64])
(scale): torch.Size([1, 64])
)
Generator(
name=p, distribution_name=Bernoulli,
var=['x'], cond_var=['z'], input_var=['z'], features_shape=torch.Size([])
(fc1): Linear(in_features=64, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=512, bias=True)
(fc3): Linear(in_features=512, out_features=784, bias=True)
)

Also, it can perform sampling in the same way.
>>> p_joint.sample(batch_n=1)
{'z': tensor([[ 1.5377, 0.4713, 0.0354, 0.5013, 1.2584, 0.8908, 0.6323, 1.0844, ..., -0.7603]]),
'x': tensor([[0., 1., 0., 1., 0., 0., 1., 1., 0., 0., 1., 1., 1., 1., ..., 0.]])}
By constructing the joint distribution in this way, you can easily implement more complicated generative models.
2. Set the loss function of a model(Loss API)
Next, we set the objective (loss) function of the model with defined distributions.
Loss API (pixyz.losses.*) enables you to define such loss function as if just writing mathematic formulas. The loss function of VAE (Eq.(1)) can easily be converted to the code style as follows.
>>> from pixyz.losses import KullbackLeibler, LogProb, Expectation as E
>>> reconst = -E(q, LogProb(p)) # the reconstruction loss (it can also be written as `-p.log_prob().expectation()`)
>>> kl = KullbackLeibler(q,prior) # Kullback-Leibler divergence
>>> loss_cls = (kl + reconst).mean()
Like Distribution API, you can check the formula of the loss function by printing.
>>> print(loss_cls)
mean \left(D_{KL} \left[q(z|x)||p_{prior}(z) \right] - \mathbb{E}_{q(z|x)} \left[\log p(x|z) \right] \right)

When evaluating this loss function given data, use the eval method.
>>> loss_tensor = loss_cls.eval({"x": x_tensor}) # x_tensor: input data
>>> print(loss_tensor)
tensor(1.00000e+05 * 1.2587)
3. Train the model(Model API)
Finally, Model API (pixyz.models.Model) can train the loss function given the optimizer, distributions to train, and training data.
>>> from pixyz.models import Model
>>> from torch import optim
>>> model = Model(loss_cls, distributions=[p, q],
... optimizer=optim.Adam, optimizer_params={"lr":1e-3}) # initialize a model
>>> train_loss = model.train({"x": x_tensor}) # train the model given training data (x_tensor)
After training the model, you can perform generation and inference on the model by sampling from
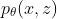
More information
These frameworks of Pixyz allow the implementation of more complex deep generative models. See sample codes and the pixyzoo repository as examples.
For more detailed usage, please check the Pixyz documentation.
If you encounter some problems in using Pixyz, please let us know.
Citation
@misc{suzuki2021pixyz,
title={Pixyz: a library for developing deep generative models},
author={Masahiro Suzuki and Takaaki Kaneko and Yutaka Matsuo},
year={2021},
eprint={2107.13109},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Acknowledgements
This library is based on results obtained from a project commissioned by the New Energy and Industrial Technology Development Organization (NEDO).
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pixyz-0.3.3.tar.gz.
File metadata
- Download URL: pixyz-0.3.3.tar.gz
- Upload date:
- Size: 55.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.2 pkginfo/1.8.2 requests/2.21.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
aefc9184423a4d661cf727a45f03cd46245ca959680fb20812dc007554408fe9
|
|
| MD5 |
d74e89bc2c5b165553e520448038a0b5
|
|
| BLAKE2b-256 |
2c65b8113d4939b1654b05946e6510cb4eb6cc726a6624ccc729a69671728494
|
File details
Details for the file pixyz-0.3.3-py3-none-any.whl.
File metadata
- Download URL: pixyz-0.3.3-py3-none-any.whl
- Upload date:
- Size: 73.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.2 pkginfo/1.8.2 requests/2.21.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
73897c866968f713fc542a3f082c2cbfbece3c8dbd43d9c7201a34bc49c80243
|
|
| MD5 |
7617070d36be98ea4ebd83fbcc03e859
|
|
| BLAKE2b-256 |
8fc335083628485cd09c2be0216f8c434b40a877561d44dde2f2b1fe934412d3
|







