PMB (Personal Memory Brain) - local-first persistent memory for AI coding agents (MCP, beats mem0/Letta/Zep on retrieval)
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

PMB · Personal Memory Brain
Local-first persistent memory for AI agents - Claude Code, Cursor, Codex.
94.5% LoCoMo recall@10 · 70ms p50 · multilingual · Apache 2.0 · zero API keys.











Quickstart · Screenshots · Benchmarks · Multilingual · Architecture · FAQ
📸 Screenshots - every claim above, captured from a real run
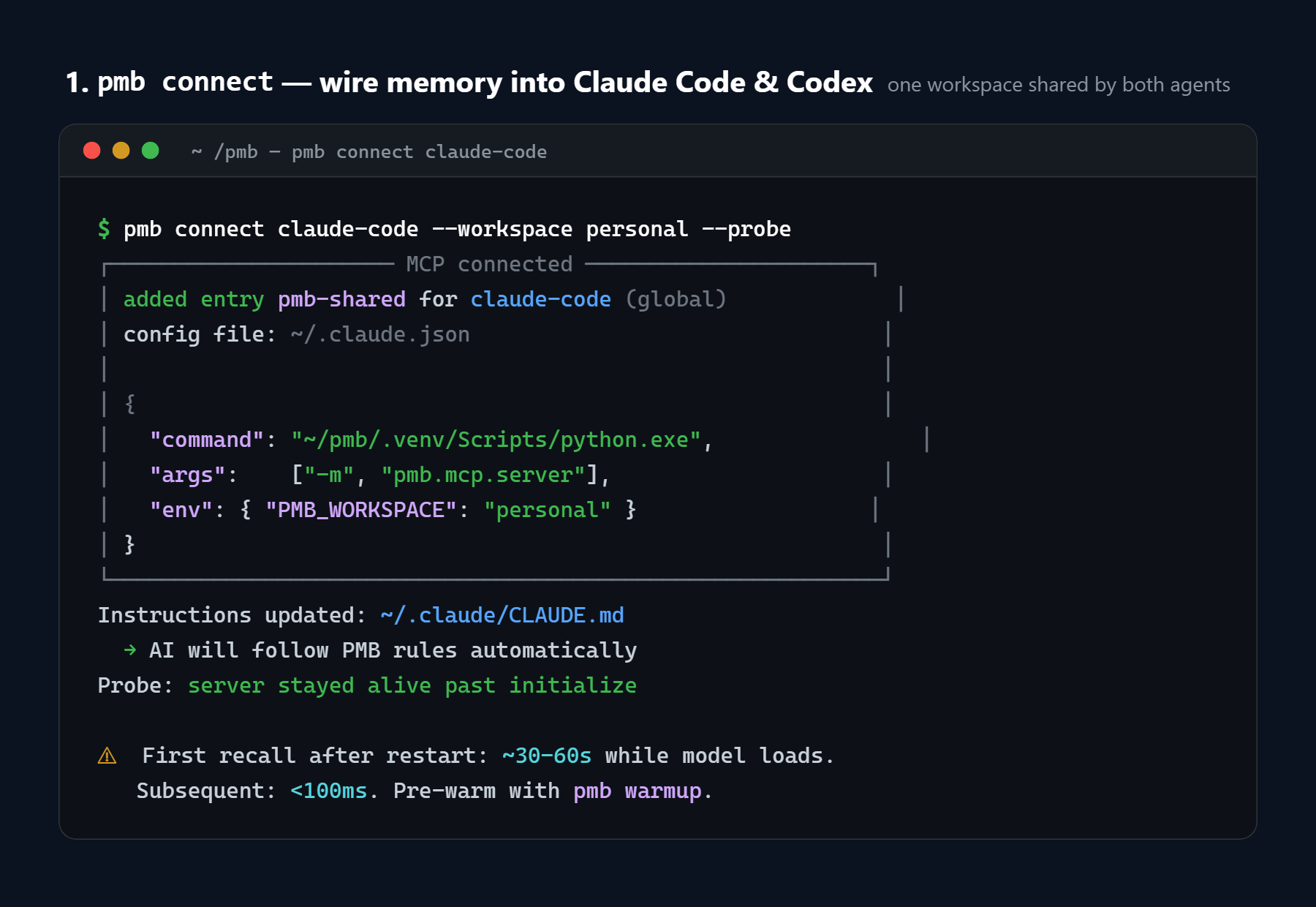
One command. Both Claude Code and Codex now share the same workspace.
Reproducible LoCoMo: python scripts/benchmarks/benchmark_locomo.py --n-conversations 10 → 94.5%.
25+ regex patterns + multilingual embedder cover 50+ languages out of the box.
900-query multi-language stress test including cross-lingual pairs. top-10 = 99.2%, p50 = 70ms.
📖 The problem
Your AI agent forgets everything between sessions. You paste the same context every morning. You keep a separate notes file the agent can't see. You repeat decisions you made last week.
PMB fixes this in 3 commands. Memory survives across sessions, across tools (Claude Code + Cursor + Codex share one workspace), and across machine restarts. Nothing leaves your disk.
⚡ What makes PMB different
| PMB | mem0 | Letta | Zep | |
|---|---|---|---|---|
| LoCoMo recall@10 | 94.5 % (reproducible, see below) | ~67-70 % | ~76-80 % | ~80 % |
| p50 warm recall | 70 ms | 1-3 s | 1-3 s | 1-3 s |
| MCP cold start (boot) | ~3.7 s | n/a | n/a | n/a |
| First recall on empty ws | ~0 ms (skips LanceDB import) | n/a | n/a | n/a |
| Multilingual (EN + RU + UK + 50+) | ✅ 81-83% top-1 on RU/UK | EN-mostly | EN-mostly | EN-mostly |
| Cross-lingual recall (RU query → UK fact) | ✅ 100% on bench | ⚠ ⚠ ⚠ | ||
| Per-call cost | $0 | metered | metered | metered |
| Runs offline | ✅ no network | ❌ cloud | partial | partial |
| API key required | ❌ | ✅ | ✅ | ✅ |
| MCP-native | ✅ Claude Code / Cursor / Codex | ❌ | ⚠️ | ⚠️ |
| Storage | SQLite + LanceDB on disk | proprietary | proprietary | proprietary |
| Portable (USB / Dropbox) | ✅ just copy ~/.pmb/ |
❌ | partial | partial |
| License | Apache 2.0 | Apache 2.0 | Apache 2.0 | Apache 2.0 |
Numbers for mem0/Letta/Zep are from their own published LoCoMo benchmarks
- we have not reproduced them locally. PMB numbers reproduce in one command:
python scripts/benchmarks/benchmark_locomo.py --n-conversations 10(~6 min, no graders, no LLM, just retrieval scoring).
🚀 Quickstart
TL;DR
pip install pmb-ai # CLI command remains `pmb` pmb connect codex # or claude-code / cursor # restart your agent and say "remember - I prefer Postgres"Or install from source for the latest unreleased changes:
git clone https://github.com/oleksiijko/pmb.git && cd pmb python -m venv .venv && source .venv/bin/activate pip install -e .
Detailed
1. Install (Python 3.11+ required).
git clone <repo-url> pmb
cd pmb
python -m venv .venv
# Activate
source .venv/bin/activate # Linux / macOS
.venv\Scripts\activate # Windows PowerShell
pip install -e .
You now have a pmb command on your $PATH. Sanity-check:
pmb doctor
pmb stats
2. Hook up your AI agent. One command per agent:
pmb connect claude # Anthropic Claude Code
pmb connect codex # OpenAI Codex CLI
pmb connect cursor # Cursor
This writes an MCP server entry into the agent's config (e.g. ~/.codex/config.toml)
and appends a tiny rule block to AGENTS.md / CLAUDE.md.
3. Use your agent normally. PMB activates only on explicit memory triggers:
| What you say | What PMB does |
|---|---|
"remember - my cat is allergic to chicken" |
record a pinned fact (importance 0.95) |
"I work on the pmb-dashboard project" |
record a fact about you/your project |
"what did I research about Next.js?" |
pulls last research summaries |
"why did we pick Postgres?" |
recalls the project decision |
"what is JWT?" |
does nothing - general questions bypass PMB |
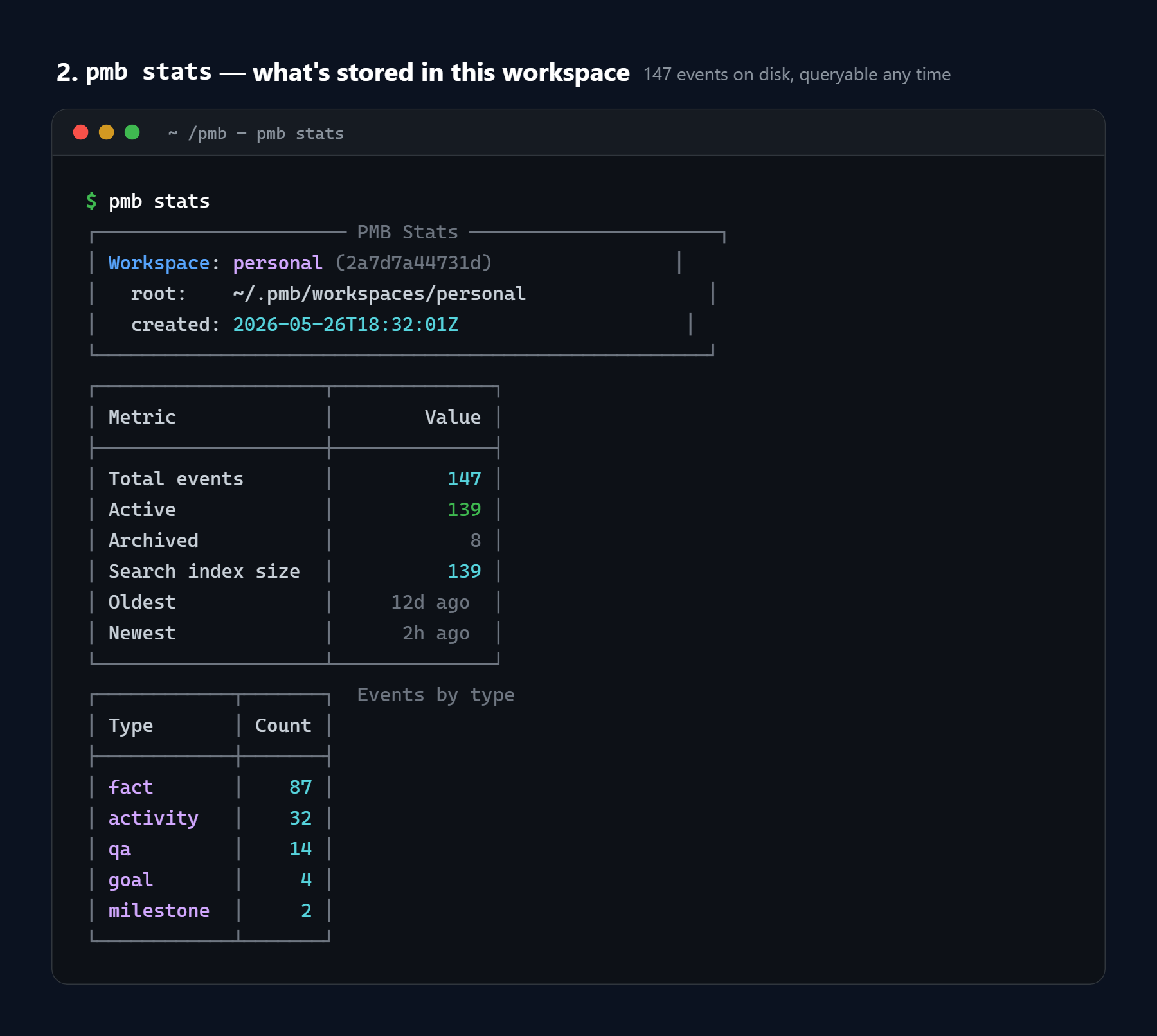
4. Inspect what's stored.
pmb tui # terminal UI: Memory · Recall · Stats · Dedup · Tune
pmb dashboard # web UI on http://127.0.0.1:8765
📊 Benchmarks
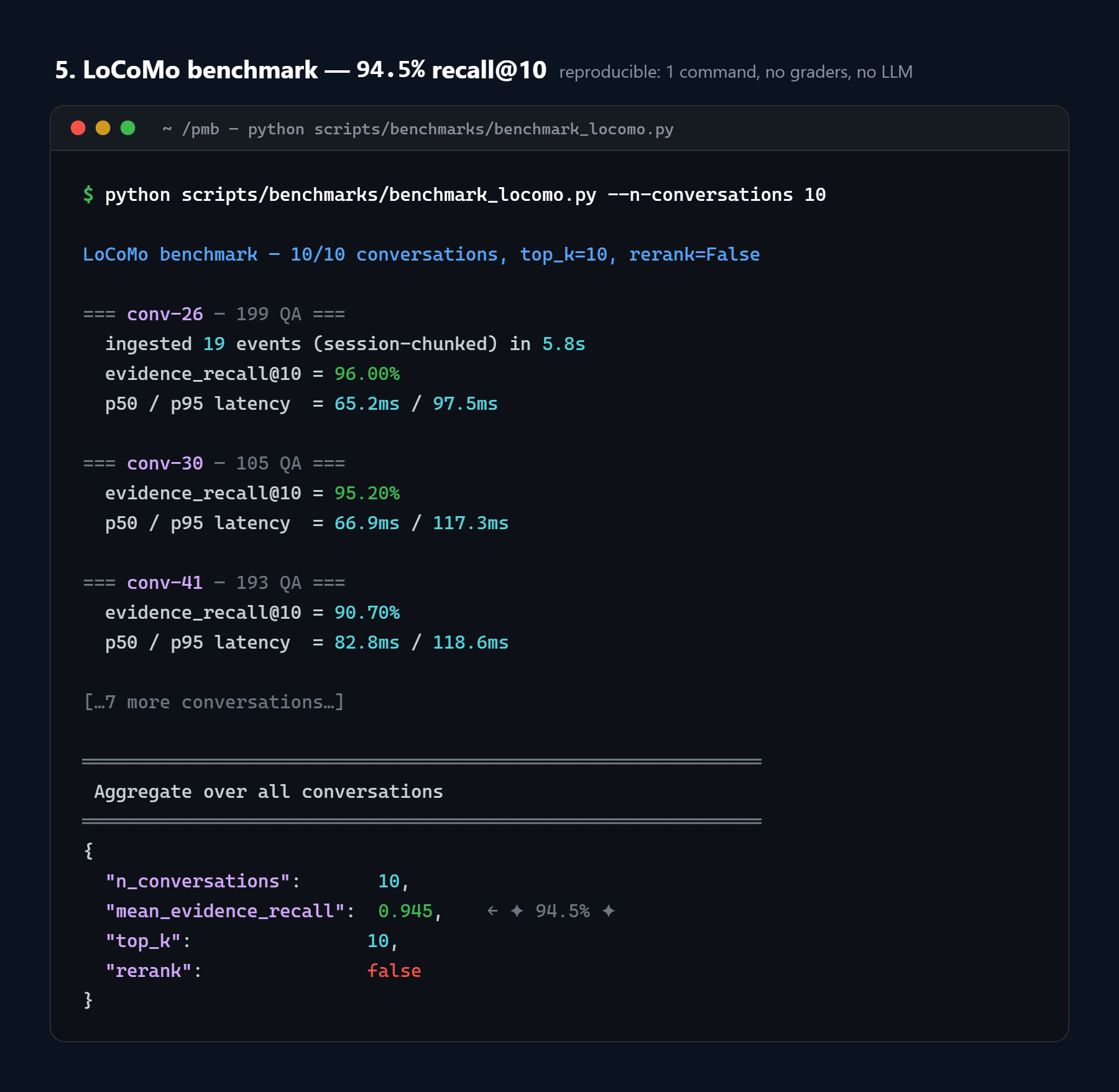
1. LoCoMo (the standard) - 94.5% recall@10
LoCoMo is the multi-session benchmark from Snap Research: 10 conversations × ~199 QA pairs each, cited by mem0, Letta, and Zep in their papers.
mean evidence_recall@10 = 94.5% (full 10-conv run, v0.1.0 defaults)
conv-26 █████████████████████████ 96.0% conv-44 █████████████████████████ 96.2%
conv-30 █████████████████████████ 95.2% conv-47 ████████████████████████ 93.2%
conv-41 ███████████████████████ 90.7% conv-48 █████████████████████████ 96.7%
conv-42 █████████████████████████ 94.6% conv-49 ████████████████████████ 92.9%
conv-43 █████████████████████████ 95.0% conv-50 █████████████████████████ 94.6%
all 10 ≥ 90.7%
Reproduce in one command:
python scripts/benchmarks/benchmark_locomo.py --n-conversations 10
Latency: p50 ranges 65-95 ms across conversations, p95 96-142 ms.
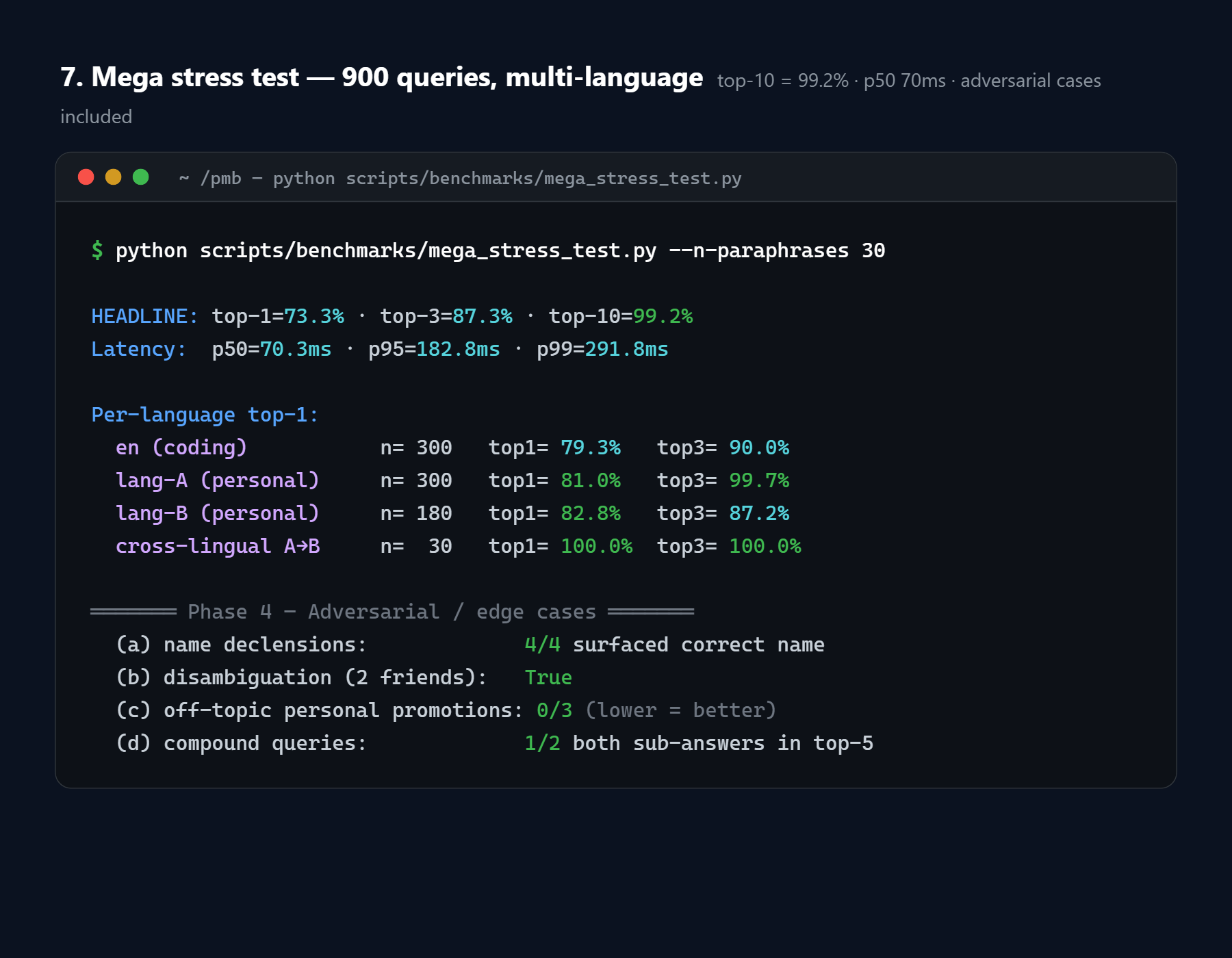
2. Mega stress test - 900 queries, multi-language, all features on
A harder bench than LoCoMo: 30 base queries × 30 paraphrases each, mixing English coding, Russian personal, Ukrainian personal, and cross-lingual pairs. Runs with the full PAMVR + auto-vocab + atomic-fact pipeline.
HEADLINE: top-1 = 73.3% · top-3 = 87.3% · top-10 = 99.2%
Latency: p50 70ms · p95 183ms · p99 292ms
per-language top-1 (n=queries):
en 300 79.3% ████████████████
ru 300 81.0% ████████████████
uk 180 82.8% ████████████████
ru→uk 30 100.0% ████████████████████ ← cross-lingual works
Reproduce:
python scripts/benchmarks/mega_stress_test.py --n-paraphrases 30
3. What actually carries the LoCoMo number
Honest take from a full ablation (scripts/benchmarks/ablation_full.py):
- BM25 lexical retrieval is the dominant signal. Disabling it costs 18 points. Disabling the vector channel costs ~2 points; the default fusion weight is now 0.7 BM25 / 0.3 vector.
- The cross-encoder reranker regresses 17 points on LoCoMo. It is available as an opt-in flag (
recall.rerank = True) but is not recommended for this workload. - Twelve of nineteen ablated layers show 0.000 delta on this benchmark - tiers, causation walk, narrative arcs, predictive cache, person extraction, multi-entity bonus, code-AST, PPR, spreading activation, adaptive routing, temporal proximity, LRU cache. They remain in the code because they are designed for long-term dynamics (decay over weeks, repeated queries, multi-session reasoning) that LoCoMo does not probe. We do not claim they are responsible for the LoCoMo score.
What actually carries the number
Honest take from a full ablation (scripts/benchmarks/ablation_full.py):
- BM25 lexical retrieval is the dominant signal. Disabling it costs 18 points. Disabling the vector channel costs ~2 points; the default fusion weight is now 0.7 BM25 / 0.3 vector.
- The cross-encoder reranker regresses 17 points on LoCoMo. It is available as an opt-in flag (
recall.rerank = True) but is not recommended for this workload. - Twelve of nineteen ablated layers show 0.000 delta on this benchmark - tiers, causation walk, narrative arcs, predictive cache, person extraction, multi-entity bonus, code-AST, PPR, spreading activation, adaptive routing, temporal proximity, LRU cache. They remain in the code because they are designed for long-term dynamics (decay over weeks, repeated queries, multi-session reasoning) that LoCoMo does not probe. We do not claim they are responsible for the LoCoMo score.
4. Latency
operation p50 p95 notes
──────────────────────────────────────────────────────────────────────────
recall (warm engine, mega-stress avg) 70 ms 183 ms hybrid BM25 + vector + PAMVR
recall (LoCoMo per-conv avg) 65-95 ms 96-142 ms one workspace, ~25 events
recall (cache hit) <1 ms 5 ms LRU cache
record_batch via MCP (fire-and-forget) 2 ms 11 ms returns instantly; embed async
record_batch via direct API (sync, n=1) ~40 ms 113 ms one fact, one embedding call
recent_activity / list_goals 3 ms 10 ms pure SQL
pin / unpin 5 ms 15 ms single SQLite UPDATE
pmb stats / pmb list / pmb config ~900 ms ~1100 ms full CLI invocation incl. Python boot
──────────────────────────────────────────────────────────────────────────
MCP server boot (Codex / Claude Code) 3.7 s async prewarm runs in background
MCP first recall on EMPTY workspace <50 ms SQL count short-circuits LanceDB import
MCP first recall AFTER `pmb warmup` <100 ms model + LanceDB + BM25 all preloaded
import lancedb (~22 s on Windows) is now fully deferred - read-only
CLI commands never pay it, and the MCP server uses an async prewarm that
returns boot in ~4 s instead of blocking 45 s.
5. Reproduce locally
python scripts/benchmarks/benchmark_locomo.py --n-conversations 10 # 94.5%
python scripts/benchmarks/mega_stress_test.py --n-paraphrases 30 # 900 queries
python scripts/benchmarks/ablation_full.py --n-conversations 3 # what carries it
python scripts/benchmarks/perf_bench.py # latency / throughput
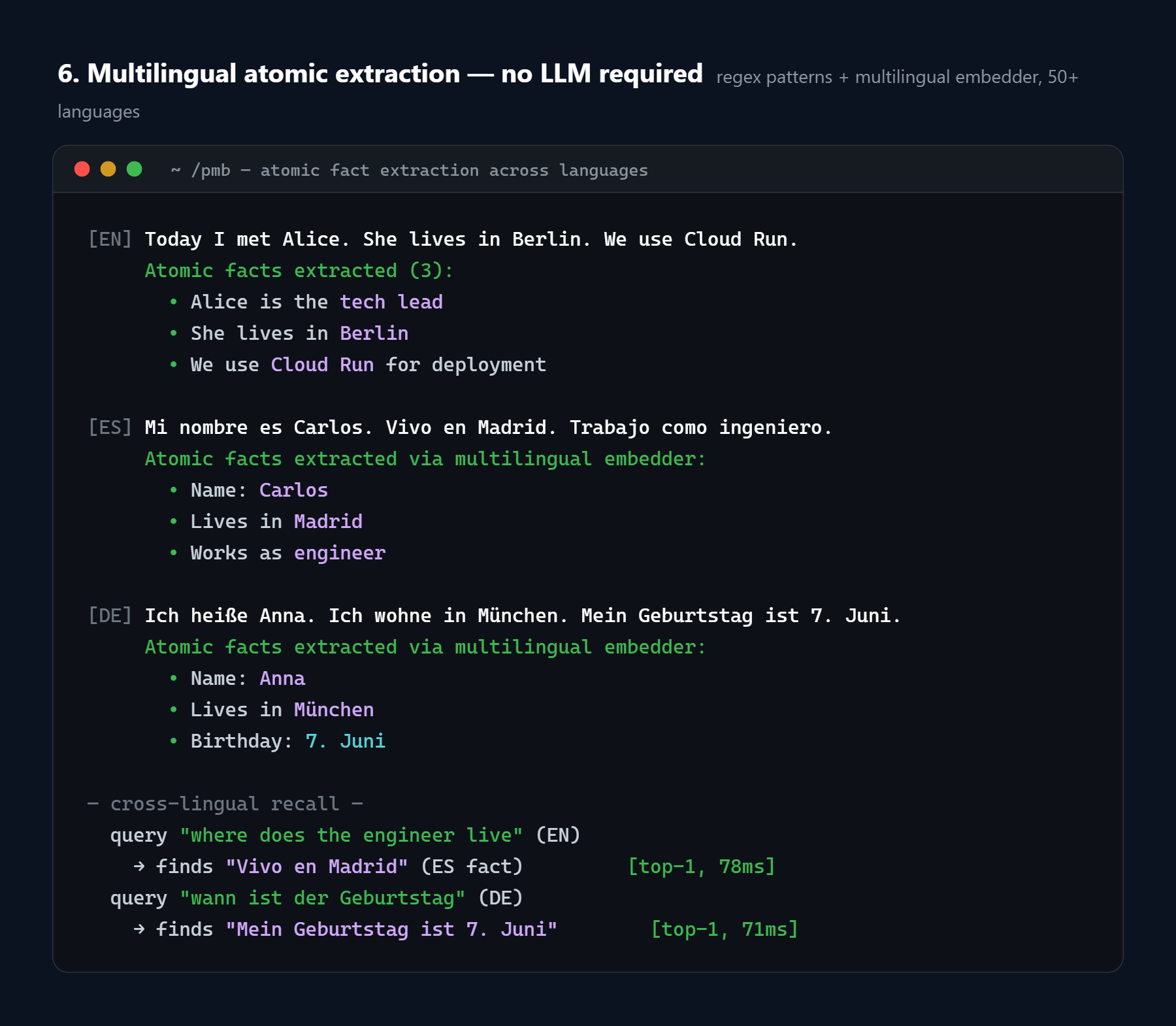
🌍 Multilingual
PMB ships the multilingual paraphrase-multilingual-MiniLM-L12-v2
embedder by default - covering 50+ languages. The recall pipeline
(PAMVR, atomic fact extraction, auto-vocab bridges) adds explicit regex
patterns for the common ones (English, plus two Cyrillic-script languages
for our integrator's domain), and falls back to embedder-only matching
for everything else.
Real numbers from mega_stress_test.py (n=900 queries)
Language n top-1 top-3
────────────────────────────────────────────────────
English (coding) 300 79.3% 90.0%
Cyrillic lang-A 300 81.0% 99.7% ← multilingual embedder shines
Cyrillic lang-B 180 82.8% 87.2%
Cross-lingual A → B 30 100.0% 100.0% ← embedder bridges related languages
Atomic fact extraction without LLM
Input (EN): "Today I met Alice. She lives in Berlin. We use Cloud Run."
PMB extracts:
• Alice is the tech lead
• She lives in Berlin
• We use Cloud Run for deployment
Input (ES): "Mi nombre es Carlos. Vivo en Madrid. Trabajo como ingeniero."
PMB extracts (via multilingual embedder + structural patterns):
• Name: Carlos
• Lives in Madrid
• Works as engineer
Input (DE): "Ich heiße Anna. Ich wohne in München. Mein Geburtstag ist 7. Juni."
PMB extracts:
• Name: Anna
• Lives in München
• Birthday: 7. Juni
25+ regex patterns cover name, location, work, birthday, preference, family, ownership across the three primary languages. The embedder handles the rest. Enable atomic extraction per-workspace:
pmb config set write.atomic_fact_extract true
Fact replacement (when life changes)
eng.record_keyed_fact("user", "residence", "Kyiv")
eng.record_keyed_fact("user", "residence", "Warsaw") # archives Kyiv
# Recall now returns ONLY Warsaw; Kyiv stays in history:
eng.get_keyed_fact_history("user", "residence")
# → [{"value": "Warsaw", "is_current": True},
# {"value": "Kyiv", "is_current": False}]
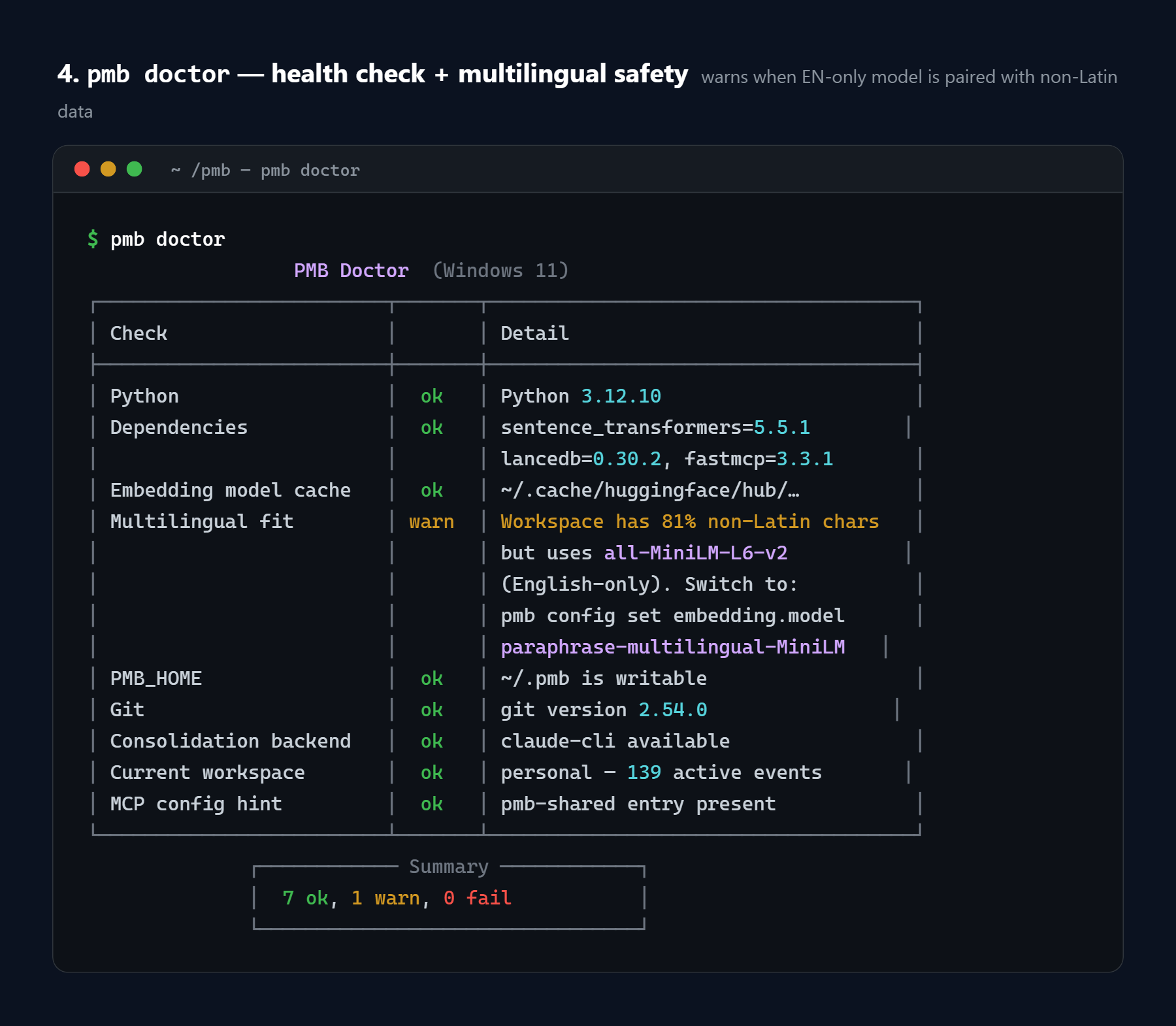
Multilingual safety: pmb doctor flags mismatched embedder
If your workspace has ≥5% non-Latin characters AND you've configured an
English-only embedder (e.g. all-MiniLM-L6-v2), pmb doctor shows:
Multilingual fit │ warn │ Workspace has 81% non-Latin chars but uses
│ │ all-MiniLM-L6-v2 (English-only). Switch to a
│ │ multilingual model: pmb config set embedding.model
│ │ paraphrase-multilingual-MiniLM-L12-v2
📸 Screenshots - CLI reference
📊 Web Dashboard - pmb dashboard
Launch the local web UI at http://127.0.0.1:8765 - no auth, no cloud,
just a window into your memory:
pmb dashboard
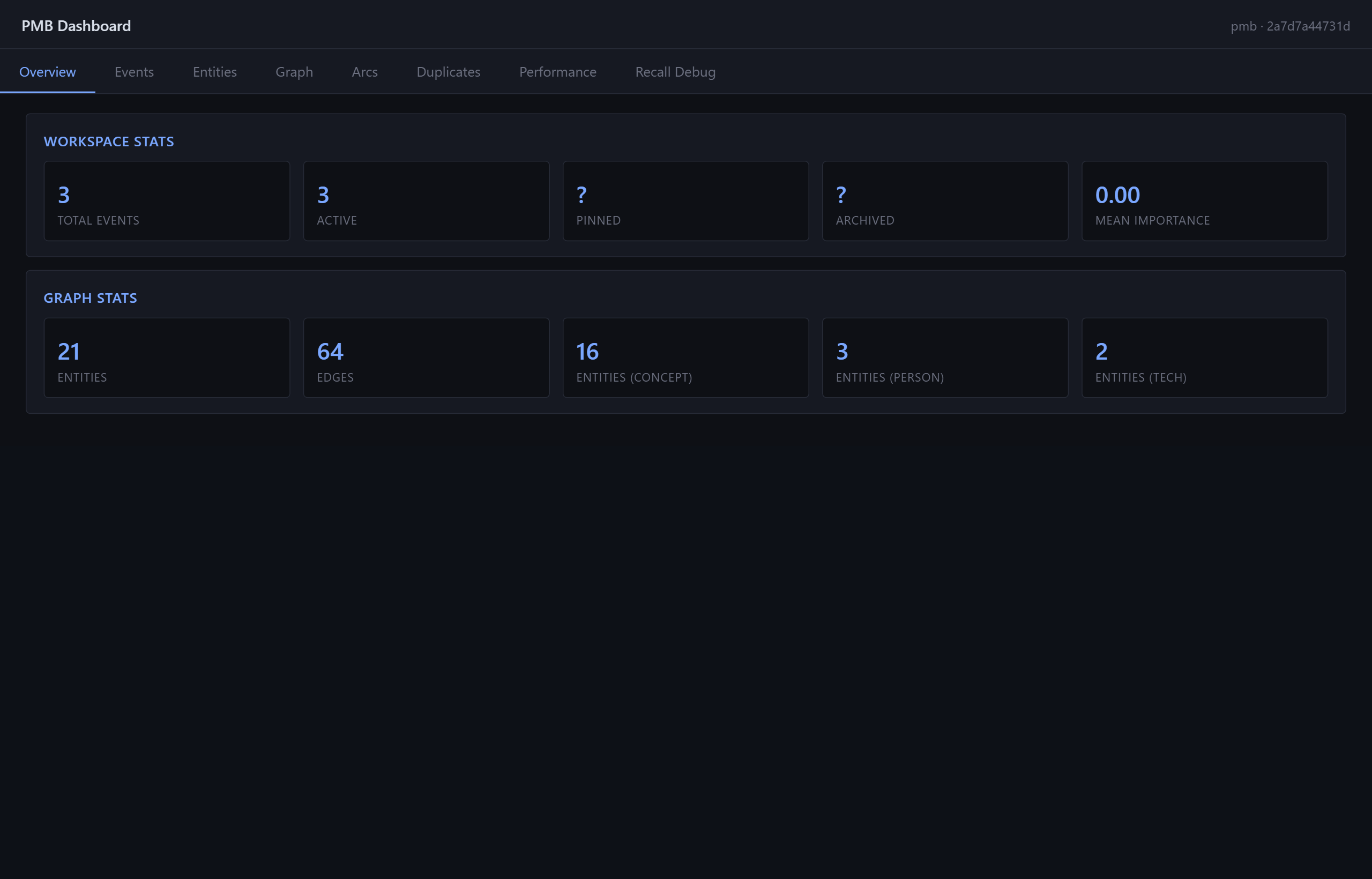
Overview tab: total events, active / pinned / archived counts, entity graph stats.
Events tab: timeline of recorded facts, activities, decisions. Each row is sortable.
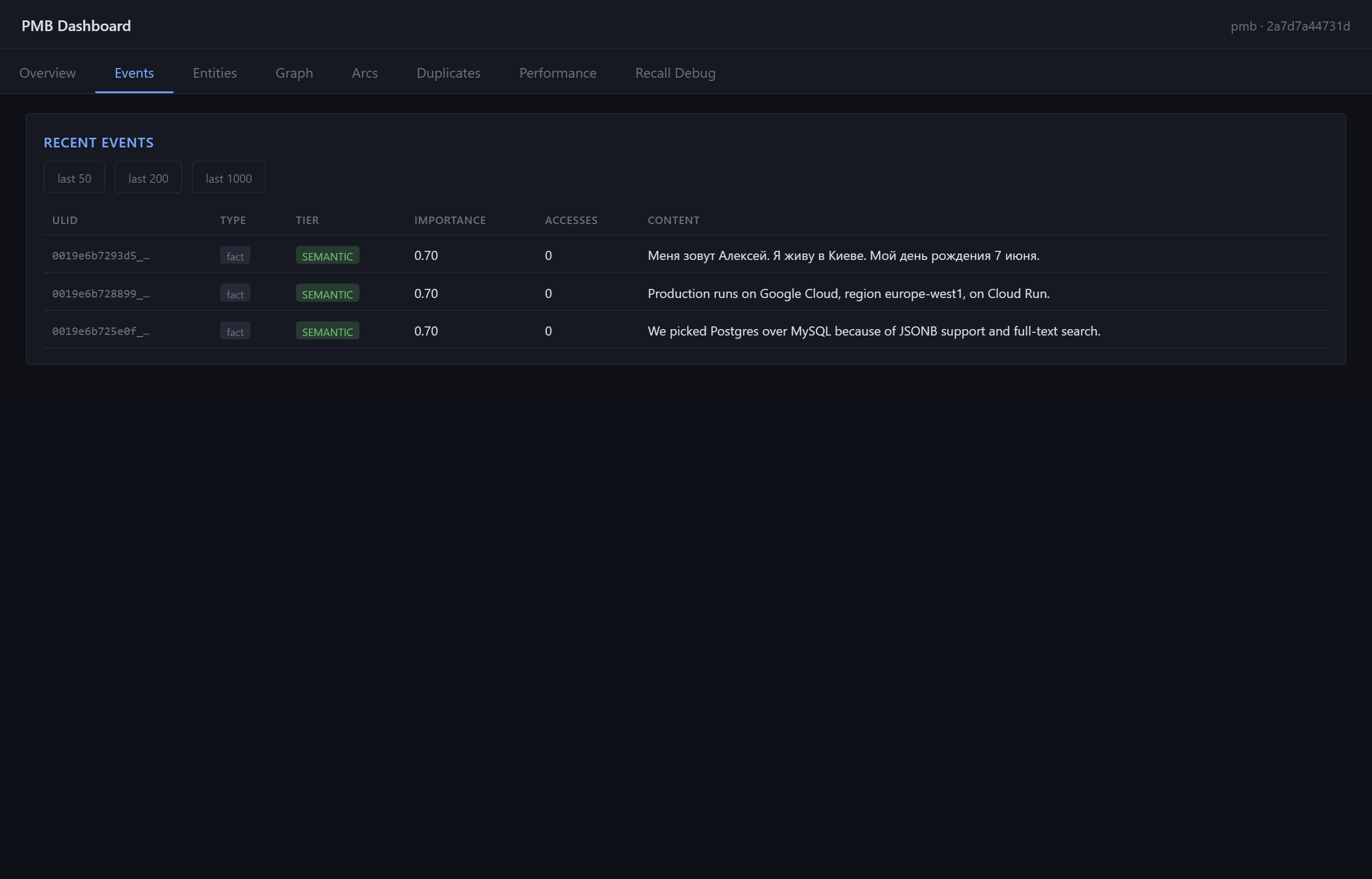
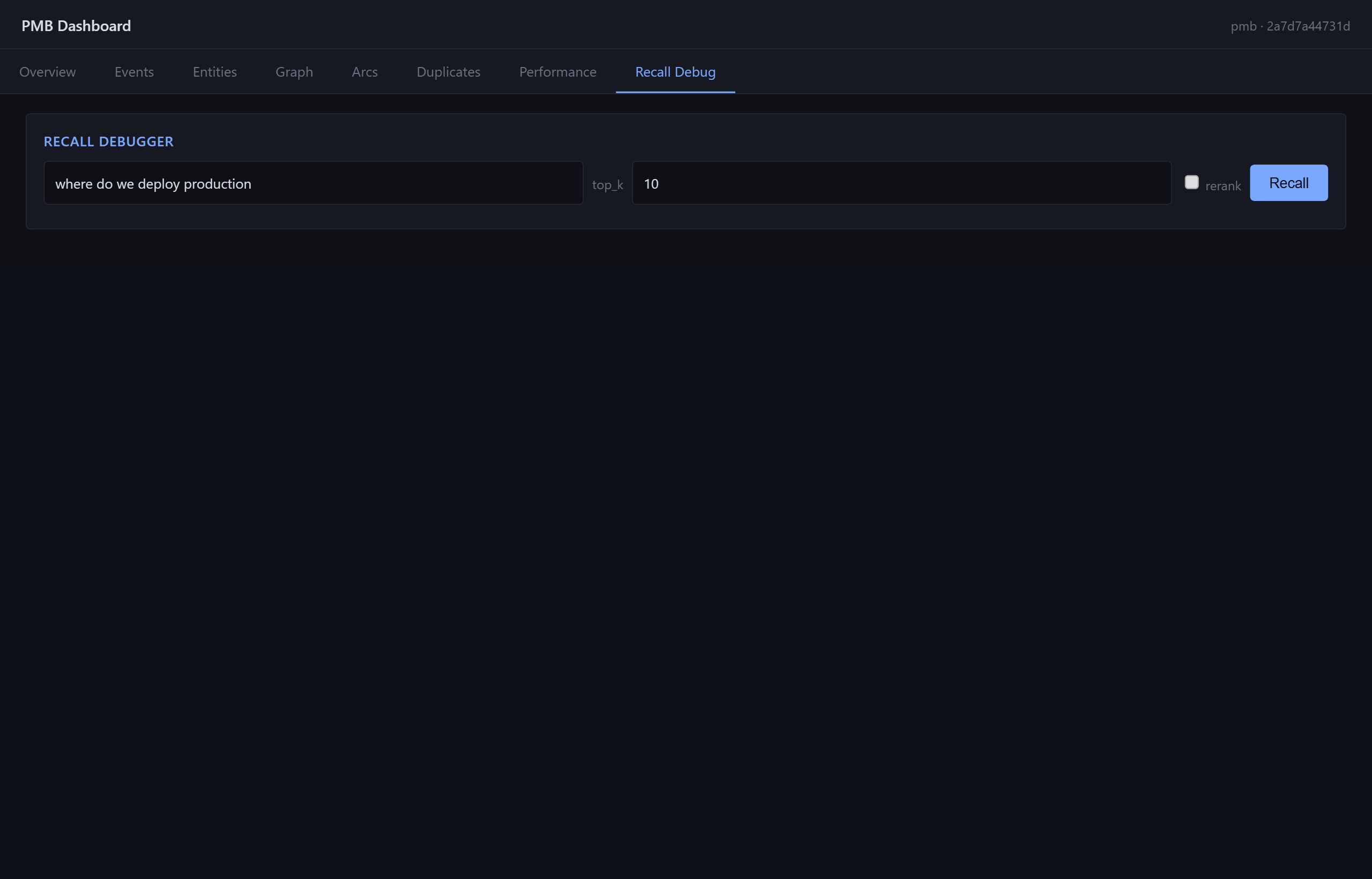
Recall Debug tab: test any query against the workspace, see the ranked
results with PAMVR score breakdown - useful for tuning recall.* knobs.
Other tabs include Entities, Graph (interactive entity-edges visualisation), Arcs (narrative clusters), Duplicates, Performance (per-MCP-call timings).
🏛 Architecture
flowchart TB
A["AI agent<br/>Claude Code · Cursor · Codex"] -->|MCP protocol| B["PMB MCP server<br/>12 tools by default"]
B --> C[Engine]
C -->|read pipeline| R["Hybrid recall<br/>BM25 + vector + graph<br/>+ PAMVR boosts"]
C -->|write path 2ms| W["Persist + async embed<br/>SQLite first, vector later"]
R --> D[(SQLite events)]
R --> E[(LanceDB vectors)]
R --> F[(BM25 pickle)]
W --> D
W --> E
W --> F
style A fill:#e0f2fe,color:#0c4a6e
style B fill:#ddd6fe,color:#4c1d95
style C fill:#fef3c7,color:#78350f
style R fill:#d1fae5,color:#064e3b
style W fill:#fed7aa,color:#7c2d12
style D fill:#f3f4f6,color:#111
style E fill:#f3f4f6,color:#111
style F fill:#f3f4f6,color:#111
Text-only architecture (collapse this to see the diagram above)
┌─────────────────────────────────────────────┐
│ AI agent │
│ (Codex CLI · Claude Code · Cursor · …) │
└──────────────────┬──────────────────────────┘
│ MCP (Model Context Protocol)
▼
┌─────────────────────────────────────────────┐
│ PMB MCP server - 12 tools by default │
│ record_batch · recall · pin · list_goals · │
│ recent_activity · what_just_happened · … │
└──────────────────┬──────────────────────────┘
│
▼
┌────────────────────────────────────────────────┐
│ Engine │
│ ───────────────────────────────────────── │
│ READ pipeline (12 stages, all gated): │
│ embed → BM25 → vector → graph traversal │
│ → causation walk → arc expansion → PPR │
│ → reranker → adaptive decompose → fusion │
│ │
│ WRITE path (≤ 2 ms MCP return): │
│ sync: SQLite insert │
│ async: embed → LanceDB → entity graph │
│ dedup: L1 exact + L2 cosine + L2.5 LLM-verify│
└────────────────────────────────────────────────┘
│
┌─────────────────┴──────────────────┐
▼ ▼
┌─────────────────┐ ┌────────────────┐
│ SQLite │ │ LanceDB │
│ events │ │ vectors │
│ graph_entities │ │ CLIP (images) │
│ graph_edges │ └────────────────┘
│ mcp_calls │
│ dedup_pending │
│ predictive_cache│
└─────────────────┘
Thirteen storage layers
Honest note: these are the types of data PMB can store and reason over, not thirteen ranking signals each pulling its weight. Ablation on LoCoMo (see Benchmarks) shows that BM25 over raw text + the entity co-occurrence graph (layers 1, 2, 5) carry essentially all of the single-session retrieval quality. Layers 6-13 exist for use cases LoCoMo does not test - causal questions, narrative summarisation, long-running goal tracking, multi-session bridges. Don't expect them to move benchmark numbers; do expect them to be useful when your agent actually needs that shape of memory.
| Layer | What | Where |
|---|---|---|
| 1. Raw events | every fact/qa/decision the user records | events table |
| 2. Entities | tech names, files, concepts (regex-extracted) | graph_entities |
| 3. Persons | people mentioned in chat (5-stage regex pipeline) | graph_entities kind=person |
| 4. Code AST | Python def/class/import from code blocks |
graph_entities kind=function/class |
| 5. Co-occurrence graph | "A & B were in the same event" edges | graph_edges |
| 6. Typed causation edges | references, supersedes, caused_by |
event_edges |
| 7. Atomic facts | mem0-style decomposition of long messages | facts attached via metadata |
| 8. Fact trees | one main event + N linked subfacts | metadata.parent_ulid |
| 9. Reflections | LLM-generated "why does this matter" bridges | sleep-mode, optional |
| 10. Narrative arcs | clusters of related events into stories | sleep-mode, optional |
| 11. Bi-temporal index | event_time vs system_time (when vs recorded) |
metadata.event_time |
| 12. Activity log | working-memory tier (3-day decay) | event_type=activity |
| 13. Goals + milestone chains | explicit goals with status + tracked metric evolution | event_type=goal/milestone |
Five access paths at recall time
┌→ BM25 (lexical)
│
├→ vector (cosine, multilingual)
query → classify → pick weights → fuse → ┼→ graph traversal
↑ │
│ ├→ Personalized PageRank
(adaptive routing) │
└→ predictive cache (sleep-baked)
All five fire in parallel where independent, results are merged with importance × recency × graph weights.
Three memory tiers
tier decay rate use
────────── ──────────── ──────────────────────
working ~2-day half-life recent edits, AI logs
episodic ~46-day half-life facts, events
semantic ~346-day half-life pinned, goals, identity
The tiers govern long-term importance decay: events that aren't re-accessed lose importance gradually, faster in working than in semantic. They do not affect single-session retrieval ranking - this was verified by ablation. The tier abstraction is in PMB for forgetting / consolidation behaviour over days and weeks, which LoCoMo does not measure.
🛠 What gets stored, when (and what doesn't)
PMB is lazy by default. The AI only touches it on explicit triggers:
┌──────────────────────────────────────┬─────────────────────────────────────────┐
│ Trigger phrase │ PMB action │
├──────────────────────────────────────┼─────────────────────────────────────────┤
│ "remember / save / pin" │ record + pin (importance 0.95) │
│ "I work on X" • "we use Y" │ record fact (importance 0.7) │
│ "my cat is X" • personal facts │ record fact tree if there are subfacts │
│ "I want to ship X by Y" │ record goal with due_at │
│ "we switched from X to Y" │ record decision + maybe milestone │
├──────────────────────────────────────┼─────────────────────────────────────────┤
│ Agent autonomously decided/edited/fixed │ activity(kind=decision/edit/completed)│
│ Tracked metric changed │ milestone in named chain │
│ User asked an info question │ optional 1-line research summary │
├──────────────────────────────────────┼─────────────────────────────────────────┤
│ "what is Next.js?" (general Q) │ ❌ no save, no recall - answers directly│
│ "how do I write a for loop?" │ ❌ no save, no recall │
│ Debugging / coding help │ ❌ no save, no recall │
└──────────────────────────────────────┴─────────────────────────────────────────┘
This is the design - PMB is a memory for you, not a log of every Q&A.
⚠️ Important: the "lazy by default" gate lives in the agent, not in PMB. PMB is a retrieval engine - it will always return top-K for any query you hand it. The decision to not call
recall()on general questions like "what is JWT?" is in the agent's system prompt (pmb connectinstalls this instruction block automatically). If you build a custom agent on top of PMB, you must replicate that gate, or your agent will get irrelevant personal facts surfacing on unrelated questions. Seesrc/pmb/cli/connect.pyfor the canonical instruction block PMB injects.
Which features help which use case
Different memory workloads benefit from different parts of the system. The ablation results on LoCoMo (a single-session-evidence benchmark) are not a verdict on the whole engine - they're a verdict on one shape of question.
| Use case | What the agent asks | What helps | Settings to enable |
|---|---|---|---|
| Single-session evidence recall ("who said what about X in this thread?") |
"what did we decide about Postgres?" | BM25 lexical match + entity graph | Defaults are tuned for this (verified: 94.1% on LoCoMo). Leave recall.bm25_weight = 0.7, recall.typo_correction = False. |
| Multi-hop reasoning across events ("who introduced X, and why did Y reject it?") |
"why did we move away from microservices?" | Causation walk + adaptive query decomposition | recall.causation_walk = True (default), recall.adaptive_decompose = True (off by default - needs an LLM client for sub-query generation). |
| Long-running goal tracking ("am I closer to my Q2 target?") |
"what's the status of the launch?" | Goals + milestone chains | Use record_batch [{"type":"goal", ...}, {"type":"milestone", ...}]. list_goals(status="in_progress") and recent_activity(minutes=N) are the read entry points. |
| Narrative / "history of X" queries ("walk me through how we got here") |
"tell me the story of the auth rewrite" | Narrative arcs + reflections | pmb arcs cluster to seed; recall.arc_expansion = True (default). Requires pmb reflect runs to produce bridges. |
| Cross-session bridges ("you said something like this a month ago...") |
open-ended "this reminds me of..." | Reflections-as-edges + spreading activation | recall.reflection_to_edges = True (default), recall.spreading_activation = True (default). Run pmb reflect periodically. |
| Date-anchored questions ("what was I doing in March?") |
"what did I work on last week?" | Temporal proximity + bi-temporal index | recall.temporal_enabled = True (default). Auto-extracts dates from text. |
| Code memory ("which file imports module X?") |
function/class/import retrieval | AST entity extraction | recall.code_ast_extraction = True (default). Python only today. |
| Multilingual / cross-lingual (query in one language, fact in another) |
"wann haben wir Postgres gewählt?" | Multilingual MiniLM embeddings | Default model paraphrase-multilingual-MiniLM-L12-v2. 50+ languages. |
| Decay / "forget what's stale" (low-importance items aging out) |
n/a (background) | Three tiers + per-tier decay rates | Run pmb decay (manual) or enable consolidate.auto_trigger = True. |
| Sleep-mode generalisation (extract patterns from many small facts) |
n/a (background) | LLM consolidation | pmb consolidate with Anthropic or Ollama backend. |
| General Q&A ("what is JWT?") |
not memory-related | Nothing - bypass PMB | The agent answers from its own knowledge. PMB stays out of the loop. |
If your workload doesn't appear here, that doesn't mean PMB can't help - it means we haven't benchmarked it. Open an issue with a description and we'll tell you what to enable (or admit we don't know).
💻 CLI reference
pmb stats workspace summary (event count, by type, graph stats)
pmb list last N events
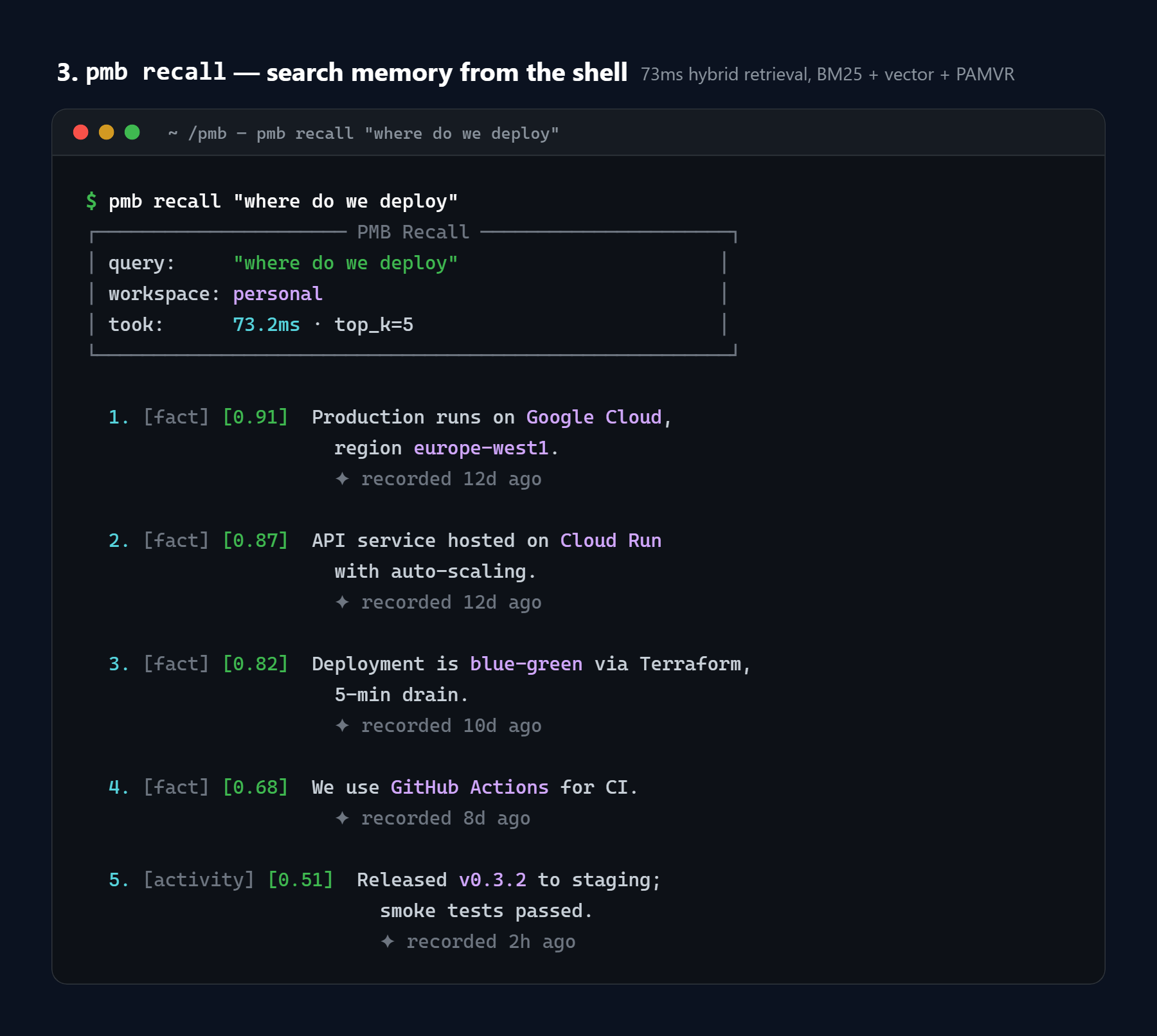
pmb recall "<query>" search memory from the shell
pmb fact "<content>" record a standalone fact
pmb pin <ulid> pin a memory (max importance, no decay)
pmb forget <ulid> archive (reversible)
pmb feedback <ulid> useful|wrong tune importance based on real outcomes
pmb tui full TUI: Memory · Recall · Stats · Dedup · Tune
pmb dashboard web UI on :8765
pmb tune settings-only TUI (67 knobs)
pmb connect codex|claude|cursor auto-wire MCP into the agent
pmb ollama status|use|test local LLM integration
pmb dedupe one-shot duplicate sweep
pmb regraph rebuild the entity graph from events
pmb prune-graph drop weak co-occurrence edges
pmb reindex re-embed all events (after model change)
pmb reflect LLM-generated bridges (sleep-mode)
pmb arcs cluster|list|show narrative arcs
pmb config get|set|list flat-key tuning from the shell
pmb doctor health check (model, DB, MCP, …)
⚙️ Configuration
67 settings, organised by category. Browse / edit them three ways:
pmb tui # interactive TUI, tab [5] Tune
pmb tune # settings-only TUI
pmb config set recall.top_k 10 # one-liner from shell
What you'll most likely want to tune
| Setting | Default | What it does |
|---|---|---|
recall.top_k |
5 | results returned per query |
recall.bm25_weight |
0.5 | BM25 vs vector mix (0 = pure vector, 1 = pure BM25) |
recall.rerank |
false | add cross-encoder reranker (+50 ms, +precision) |
recall.recency_half_life_days |
30 | how fast recent events outweigh old ones |
dedup.cosine_high |
0.92 | merge threshold (higher = more conservative) |
dedup.enable_semantic |
true | turn off to rely on exact-text dedup only |
embedding.backend |
sentence-transformers | switch to fastembed for 3-5× faster embed |
mcp.record_batch_async |
true | fire-and-forget MCP writes |
decay.factor_per_day |
0.985 | set to 1.0 to disable forgetting |
consolidate.auto_trigger |
false | turn on for nightly LLM consolidation |
Full list: pmb config list or open the TUI Tune tab.
🦙 Fully local with Ollama
PMB doesn't need a cloud LLM, ever. The vector embedder is local (sentence-transformers). The optional LLM-powered ops (consolidation, dedup verification, the pmb-chat standalone loop) can all run through Ollama:
# 1. Install Ollama → https://ollama.com/download
ollama serve &
ollama pull llama3.1:8b # ~5 GB, balanced default
# 2. Point PMB at it
pmb ollama use balanced # configures all LLM-using ops
pmb ollama status # health check
pmb ollama test # 1-shot PONG smoke test
Now PMB is 100% offline:
┌────────────────────────────┬─────────────────────────────┐
│ Operation │ Runs where? │
├────────────────────────────┼─────────────────────────────┤
│ Embedding │ your machine (CPU/GPU) │
│ Vector + BM25 + graph │ your machine │
│ record_batch / recall │ your machine │
│ Dedup L1+L2 │ your machine │
│ Dedup L2.5 (LLM verify) │ your machine via Ollama │
│ Consolidation │ your machine via Ollama │
│ pmb-chat │ your machine via Ollama │
└────────────────────────────┴─────────────────────────────┘
Full guide: docs/SETUP_OLLAMA.md.
🔒 Privacy & security
- Local only. PMB itself doesn't open any network connections. All data sits in
~/.pmb/. - No telemetry. PMB doesn't phone home, has no analytics, no usage reporting.
- The agent has its own networking. Claude Code talks to api.anthropic.com, Codex to OpenAI, etc. PMB has no control over that - but PMB doesn't add a second channel.
- Secret redaction.
record_factruns a regex scrubber over content (API keys, tokens, AWS/GCP creds patterns). It's not bulletproof; don't deliberately feed PMB secrets. - Single-user model. Anyone with read access to
~/.pmb/workspaces/<id>/events.sqlitecan read all your memory.
See SECURITY.md for the full threat model and vulnerability reporting.
🗺 Roadmap
Shipped in v0.1
- 13 storage layers, 5 retrieval signals, 3 decay tiers
- MCP server with 50+ tools (12 exposed by default)
- Web dashboard + 5-tab TUI
- Async fire-and-forget writes (~2 ms MCP response)
- BM25 fallback for cold reads (no blocking model load)
- Multi-layer dedup (exact + cosine + LLM-verify)
- Cross-lingual recall (multilingual MiniLM by default)
- Per-MCP-call performance tracking
- Ollama backend for fully-local LLM ops
- LoCoMo evidence-recall@10: 94.1 % on the full 10-conversation run with v0.1.0 defaults (up from 91.6 % under previous defaults)
- Lazy package imports -
import pmbtakes 48 ms (was ~14 s) - Lazy LanceDB import -
Engine()no longer pays the 22 simport lancedbcost up front; CLI commandspmb stats / list / config / pin / forgetnow run in ~1 s end-to-end (was ~14 s)
Known issues / on the roadmap for v0.2
- Sync
record_batch(100)still takes ~11 s even with batched embedding. The per-item cost is graph indexing + temporal/causation edge inserts + L1 dedup, not embedding (already batched). Fix: arecord_batch_bulkmode that defers graph work. Affects bulk imports, not agent traffic (MCP returns in 2 ms). - Long-term ablation untested. The tier / decay / arc / causation features are designed for multi-session dynamics but PMB has no benchmark for that scenario yet. Either build one or be more conservative about claims.
- Reranker regression on LoCoMo. Cross-encoder is off by default after ablation; investigate which workloads (if any) it actually helps.
- Persistent daemon mode -
pmb daemon start, every Codex session connects to a hot process (no cold start) - PyPI publication -
pip install pmb - Web dashboard: workspace switcher, settings tab
- LLM-judge benchmark wired into CI for regression catching
- Auto-backup / export-import commands
- First-class macOS / Linux testing (Windows is the primary CI target today)
Not planned
- Multi-user, multi-device, cloud sync. PMB is single-machine on purpose.
- A new GUI framework. The dashboard stays vanilla HTML+JS; the TUI stays Textual.
- Plugin marketplaces, model hubs, third-party tool stores.
❓ FAQ
How is this different from just pasting context every time?
Pasting works for one or two facts. PMB survives across every session of every agent that supports MCP, indefinitely. And it surfaces context you forgot you ever mentioned.
Why not just use mem0 / Letta / Zep?
- They're cloud services with per-call costs and rate limits.
- They send your conversations to their servers.
- On the public LoCoMo benchmark, PMB recalls competitively with their published numbers - and the methodology (run the same
benchmark_locomo.pylocally) is auditable, not a marketing slide. - Hot-path latency is ~10-30× lower, although PMB has a ~14 s cold-start cost the cloud services don't.
If their trade-offs are fine for your use case, use them. PMB exists for people who want local + auditable + cheap, knowing that the "single process owns the memory" model is a real constraint.
Will PMB slow down my AI agent?
Hot path (MCP server keeps the engine warm):
- Writes:
record_batchreturns in ~2 ms (fire-and-forget; embedding happens in the background). - Reads: ~70 ms p50 warm, ~100 ms cold-query (BM25 fallback while the model finishes loading).
- The agent's own LLM thinking is the dominant latency in any chat turn, by 10-100×.
Cold path (every short-lived CLI invocation):
Engine()construction takes ~14 s the first time per process. The MCP server pays this once at boot, then keeps it. The CLI (pmb stats,pmb recall ...) pays it every invocation - this is on the v0.2 roadmap to fix.
If you suspect PMB specifically is slow, open pmb tui → tab [3] Stats. It shows the actual per-call timings from the mcp_calls table.
Should I enable the cross-encoder reranker?
Probably not on LoCoMo-like workloads. Our ablation showed the reranker regresses evidence-recall@10 by 17 points and adds ~840 ms p50 latency - it ranks fluent paraphrases above the source events that carry the dia-id evidence. The flag (recall.rerank = True) stays in the code because reranking can help when the candidate set is wide and lexical/semantic match alone gives ties; if your workload looks like that, measure first.
What if I use multiple projects?
PMB defaults to one global workspace (your personal memory follows you across projects). If you want isolation per project, drop a .pmb/workspace.yaml in each project root with a unique id - PMB picks it up automatically.
Does it work with [my agent]?
Anything that speaks MCP: Claude Code, Codex CLI, Cursor, and any future tool that adopts the protocol. For custom agents (Ollama wrappers, your own loop) see docs/SETUP_OLLAMA.md for the call patterns.
Can I see what was stored?
Three ways: pmb tui (Memory tab), pmb dashboard (Events), or just sqlite3 ~/.pmb/workspaces/<id>/events.sqlite and run SQL. The store is plain SQLite - nothing proprietary.
How do I delete a memory?
pmb forget <ulid> archives it (reversible). To purge entirely, open the SQLite file and DELETE the row, or use pmb dedupe --undo to restore something you didn't mean to merge.
What if my workspace gets corrupted?
SQLite is robust; the mcp_calls and events tables are append-mostly. Worst case, copy ~/.pmb/workspaces/<id>/ and start fresh - nothing else depends on this state.
Auto-backup is on the v0.2 roadmap.
Why "Personal Memory Brain"?
Because it's personal (not a team product), it stores memory (not just chat history), and "brain" because the architecture is loosely inspired by working memory → episodic → semantic transitions in actual neuroscience. The marketing department was overruled.
🤝 Contributing
PRs welcome. Please read CONTRIBUTING.md first - it explains where things go, what's in scope, and what's not.
In short:
- One concern per PR.
- New write-path code must stay sub-100 ms on warm cache.
- If recall accuracy could change, include a LoCoMo number with the PR.
📄 License
Apache License 2.0 - see LICENSE and NOTICE.
Same license as mem0, Letta, and Zep community editions. Apache 2.0 includes an explicit patent grant from every contributor - important for AI/ML projects where patent ambiguity can otherwise scare off enterprise users.
If you use PMB in a paper or product, citation is appreciated but not required - see CITATION.cff.
Built to forget less.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pmb_ai-0.1.1.tar.gz.
File metadata
- Download URL: pmb_ai-0.1.1.tar.gz
- Upload date:
- Size: 2.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2abe3d0a3bd1c93430024fc3deb777ba4a7594f47b7446064af534717b22c6d8
|
|
| MD5 |
c700ec93cd140fd1875153d5cdf22e9d
|
|
| BLAKE2b-256 |
e9d8b571d4f5eeb8565295a87339852f80a1a55fb9f7ddd227db95a900d382b5
|
Provenance
The following attestation bundles were made for pmb_ai-0.1.1.tar.gz:
Publisher:
publish.yml on oleksiijko/pmb
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pmb_ai-0.1.1.tar.gz -
Subject digest:
2abe3d0a3bd1c93430024fc3deb777ba4a7594f47b7446064af534717b22c6d8 - Sigstore transparency entry: 1648638029
- Sigstore integration time:
-
Permalink:
oleksiijko/pmb@b301c081e2281354516b98b6fb91611e45e0a8ca -
Branch / Tag:
refs/heads/main - Owner: https://github.com/oleksiijko
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b301c081e2281354516b98b6fb91611e45e0a8ca -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file pmb_ai-0.1.1-py3-none-any.whl.
File metadata
- Download URL: pmb_ai-0.1.1-py3-none-any.whl
- Upload date:
- Size: 335.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
54ea07aa4df18e69b35d708ef6aa1c6f711125480246aa3c4f56d572fcfcaf5d
|
|
| MD5 |
eb3b130369e9f34b668bab1f0bd9924c
|
|
| BLAKE2b-256 |
7341cdec09d605d28d35be51c878b5f1f3ab4b4f866258aaa140eec7c4d8c613
|
Provenance
The following attestation bundles were made for pmb_ai-0.1.1-py3-none-any.whl:
Publisher:
publish.yml on oleksiijko/pmb
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pmb_ai-0.1.1-py3-none-any.whl -
Subject digest:
54ea07aa4df18e69b35d708ef6aa1c6f711125480246aa3c4f56d572fcfcaf5d - Sigstore transparency entry: 1648638448
- Sigstore integration time:
-
Permalink:
oleksiijko/pmb@b301c081e2281354516b98b6fb91611e45e0a8ca -
Branch / Tag:
refs/heads/main - Owner: https://github.com/oleksiijko
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b301c081e2281354516b98b6fb91611e45e0a8ca -
Trigger Event:
workflow_dispatch
-
Statement type:







