Production-grade RLMs (Recursive Language Models) with tool use, built on DSPy
Project description
predict-rlm




Production-grade RLMs (Recursive Language Models) with tool use, built on DSPy. By Trampoline AI.
Based on the Recursive Language Models paper by Alex L. Zhang, Tim Kraska, and Omar Khattab from the Stanford NLP lab.
Installation
uv add predict-rlm
Or with pip:
pip install predict-rlm
predict-rlm also requires Deno for its sandboxed code interpreter:
curl -fsSL https://deno.land/install.sh | sh
Quick start
import dspy
from predict_rlm import File, PredictRLM
class AnalyzeImages(dspy.Signature):
"""Analyze images and answer the query. Load each image as a base64 data
URI and use predict() with dspy.Image to extract visual information."""
images: list[File] = dspy.InputField()
query: str = dspy.InputField()
answer: str = dspy.OutputField()
rlm = PredictRLM(AnalyzeImages, lm="openai/gpt-5.4", sub_lm="openai/gpt-5.1")
result = rlm(images=[File(path="page.png")], query="Extract all visible text, then count each letter A-Z (case-insensitive).")
print(result.answer)
Use it with your coding agent
Add the predict-rlm agent skill to Claude Code, Codex, Cursor, or any compatible coding agent:
npx skills add Trampoline-AI/predict-rlm
Your agent will then know how to build RLMs using predict-rlm — including the file structure, signatures, tools, and skills patterns.
Demos
| Example | Description | Input / Output | Preview |
|---|---|---|---|
| Document Analysis | Analyze documents and extract key dates, entities, and financial information into a structured report | Input: 1 PDF, 136 pages Output: Structured briefing report with key dates, entities, and financial info (sample) |
 |
| Document Redaction | Redact PII from PDFs based on a policy, then verify the redactions visually | Input: 1 PDF, 6 pages Output: 96 PII redactions across 6 categories, verified redacted PDF (sample) |
 |
| Invoice Processing | Extract vendor info, line items, and totals from PDF invoices into a consolidated Excel spreadsheet | Input: 2 PDFs, 2 pages Output: Line items, totals, and vendor info in Excel (sample) |
 |
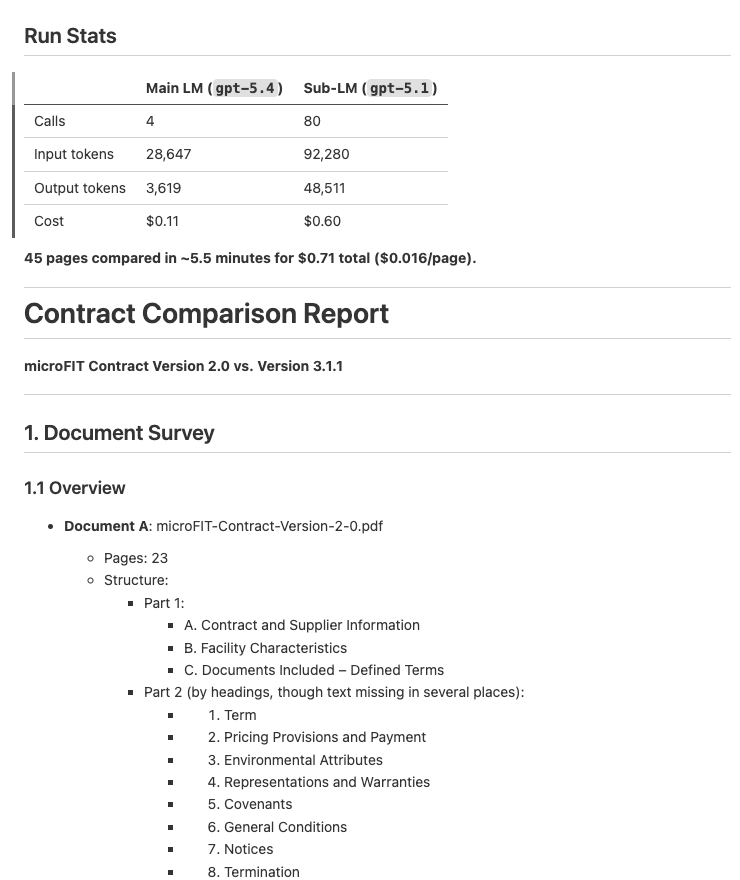
| Contract Comparison | Compare two contract versions and produce a structured diff report with per-section analysis | Input: 2 PDFs, 45 pages Output: Per-section diff report with key differences (sample) |
 |
Why RLMs?
Think of an RLM as a callable, pre-configured agent. Like Claude Code or Cursor, it can autonomously explore context, write and execute code, call tools, inspect results, and iterate until the task is done. Unlike a chat agent, an RLM is a function — you define its inputs, outputs, and tools, then call it from your code. It returns structured data, not chat messages.
This makes RLMs ideal for tasks that are:
- Specific and repeatable — tasks with a well-defined SOP and a known desired outcome. Think of an RLM as a Claude Code that's been purpose-built for one task — with the right tools, the right instructions, and a tuned workflow that reliably produces the result you want. You define the procedure once, and the RLM follows it every time.
- Context-heavy — too much data to fit in a single prompt. The RLM selectively loads what it needs via tools, working through documents page by page rather than stuffing everything into one call.
- Multi-step — require exploring, extracting, computing, and synthesizing. The RLM writes code to orchestrate these steps, parallelizing where possible (e.g. processing 50 pages concurrently with
asyncio.gather()). - Action-oriented — need to make changes, not just read. By giving the RLM tools that modify state (redact text, call APIs, write files), it becomes an autonomous executor — not just an analyzer.
- Iterative — the RLM can inspect its own results, catch errors, retry with different approaches, and verify its work before submitting. It self-corrects in ways a single LLM call cannot.
What is predict-rlm?
predict-rlm extends DSPy's RLM with a built-in predict() tool — a sub-LM the RLM can call from within its sandbox to perform language understanding, vision analysis, and structured extraction via DSPy signatures.
The architecture is two-level:
- The outer LLM (the RLM itself) writes and executes Python code in a sandboxed REPL. It plans, orchestrates, and iterates.
- The sub-LM (via
predict()) handles perception and extraction — analyzing images, understanding text, and returning typed results.
The sub-LM supports dspy.Image type hints, which means predict() calls can pass images (as URLs or base64) directly to a vision-capable model. This makes RLMs natively multimodal — the outer LLM renders a PDF page to an image, passes it to predict(), and gets back structured data. The RLM itself doesn't need to be a vision model; it delegates visual understanding to the sub-LM.
The outer LLM decides what to look at and when; the sub-LM decides what it sees. This separation is key to context management — the outer LLM's context stays small (code + tool results), while context-heavy work like reading a full page image or analyzing a long text block is offloaded to predict() calls. Each predict() call gets its own context window with the sub-LM, so the RLM can process far more total data than any single LLM call could hold.
Features
- Built-in
predict()tool — call a sub-LM from inside the sandbox with DSPy signatures and type hints - JSPI-enabled WASM sandbox — concurrent async tool execution via Pyodide with
asyncio.gather() - Structured outputs — Pydantic models, typed fields, and lists as output types
- Custom tools — give the RLM tools that read, write, or modify external state
- Skills — composable bundles of instructions, PyPI packages, and tools for domain-specific tasks
- Multimodal — sub-LM calls support
dspy.Image, so the RLM can analyze images, PDFs, screenshots, etc. without the outer LLM needing vision capabilities - Optimizable — built on DSPy, so optimizers can tune prompts and few-shot examples automatically. Inference-time scaling techniques like GEPA push accuracy further by generating and selecting among multiple candidate solutions
How it works
- You define inputs, outputs, and tools — what the RLM receives, what it should produce, and what actions it can take
- The outer LLM writes Python code in a sandboxed Pyodide/WASM REPL
- Inside the sandbox, it calls
await predict(signature, **kwargs)to invoke the sub-LM for understanding and extraction - It iterates — exploring data, calling tools, building up intermediate results, and handling errors
- When done, it calls
SUBMIT()with the final structured output
Each iteration is a REPL turn: the LLM sees the output of its previous code, decides what to do next, and writes more code. State persists between iterations, so it can accumulate findings across many steps.
Signatures and file I/O
The DSPy signature defines the inputs, outputs, and strategy (via the docstring). Use File for file-typed fields — input files are mounted into the sandbox, output files are synced back (see API for details).
from predict_rlm import File, PredictRLM, Skill
class AnalyzeDocuments(dspy.Signature):
"""Analyze documents and produce a structured report.
1. Survey the documents — file names, page counts, document types
2. Render pages as images and use predict() to extract content
3. Produce the report following the criteria's format
"""
documents: list[File] = dspy.InputField()
analysis: DocumentAnalysis = dspy.OutputField()
pdf_skill = Skill(
name="pdf",
instructions="Use pymupdf to open and render PDF pages...",
packages=["pymupdf"],
)
rlm = PredictRLM(
AnalyzeDocuments,
lm="openai/gpt-5.4",
sub_lm="openai/gpt-5.1",
skills=[pdf_skill],
)
documents = [File(path="report.pdf"), File(path="appendix.pdf")]
result = rlm(documents=documents)
Inside the sandbox, the RLM autonomously decides which pages to load and when:
# The RLM writes code like this — you don't write this, the LLM does:
import pymupdf, base64, asyncio
doc = pymupdf.open(documents[0])
images = [
f"data:image/png;base64,{base64.b64encode(doc[i].get_pixmap(dpi=200).tobytes('png')).decode()}"
for i in range(3)
]
results = await asyncio.gather(*[
predict("page: dspy.Image -> dates: list[str]", page=img)
for img in images
])
Skills
Skills are the primary way to extend what an RLM can do inside its sandbox. The sandbox starts with just Python's standard library and predict() — skills add PyPI packages, instructions, modules, and tools on top.
Skills are for general capabilities — teaching the RLM how to use a library or approach a domain. For single specialized functions (fetch a URL, query a database, call an API), use the tools= parameter directly instead.
This is powerful for the same reason CLI tools are powerful for Claude Code: if there's a Python package for it, the RLM can use it. Data manipulation with pandas, PDF parsing with pdfplumber, image processing with Pillow, web scraping with beautifulsoup4, geospatial analysis with shapely — skills make any of these available inside the sandbox, and the RLM can write code against them autonomously.
Package compatibility: The sandbox runs Pyodide (CPython compiled to WebAssembly), which supports pure-Python packages out of the box via micropip. Packages with C extensions only work if they ship a pre-built Pyodide wheel — many popular ones do (numpy, pandas, scipy, Pillow, pymupdf, etc.), but packages that rely on system libraries without a Pyodide build (e.g. psycopg2, torch) cannot be installed in the sandbox. For these, expose the functionality as a host-side tool instead — the tool runs in your normal Python environment and the RLM calls it from the sandbox via the tool bridge.
Unlike Claude Code skills, which need to be discovered and loaded on demand (because Claude Code is a general-purpose agent that can't load every capability at once), RLM skills are always loaded into context. This works because an RLM is already scoped to a specific task — you know exactly what capabilities it needs when you define it, so you can confidently pass all relevant skills upfront without worrying about context bloat or dynamic discovery.
from predict_rlm import PredictRLM, Skill
pdf_skill = Skill(
name="pdf-extraction",
instructions="Use pdfplumber for table extraction. Prefer page.extract_tables() for tabular content.",
packages=["pdfplumber"],
)
rlm = PredictRLM(
"documents -> tables: list[dict]",
lm="openai/gpt-5.4",
sub_lm="openai/gpt-5.1",
skills=[pdf_skill],
)
Skills are composable — pass multiple skills and their instructions, packages, and tools are merged automatically:
data_skill = Skill(
name="data-analysis",
instructions="Use pandas for tabular data. Print df.head() to inspect before processing.",
packages=["pandas", "openpyxl"],
)
viz_skill = Skill(
name="visualization",
instructions="Use matplotlib for charts. Save figures to bytes, don't call plt.show().",
packages=["matplotlib"],
)
rlm = PredictRLM(
"spreadsheet, query -> analysis: str, chart: bytes",
lm="openai/gpt-5.4",
skills=[data_skill, viz_skill],
)
Sandbox modules
Skills can mount Python modules directly into the sandbox via the modules field. This lets you ship custom Python code alongside a skill that the RLM can import in its sandbox code — without publishing it to PyPI.
from pathlib import Path
spreadsheet_skill = Skill(
name="spreadsheet",
instructions="Use openpyxl to build workbooks. Use formula_eval to verify formulas.",
packages=["openpyxl", "pandas", "formulas"],
modules={"formula_eval": str(Path(__file__).parent / "modules" / "formula_eval.py")},
)
The key maps the import name to the host filesystem path of the .py file. When the RLM runs, the module is mounted into the sandbox and becomes importable:
# Inside the sandbox, the RLM can write:
from formula_eval import evaluate
report = evaluate("output.xlsx")
Built-in skills
predict-rlm ships a library of pre-built skills you can use directly:
from predict_rlm.skills import pdf, spreadsheet
rlm = PredictRLM(MySignature, skills=[pdf, spreadsheet])
| Skill | Import | Packages | Modules | What it teaches the RLM |
|---|---|---|---|---|
from predict_rlm.skills import pdf |
pymupdf |
— | Read, render, modify, and redact PDFs | |
| spreadsheet | from predict_rlm.skills import spreadsheet |
openpyxl, pandas, formulas |
formula_eval |
Build and modify Excel workbooks with formulas and formatting |
Examples
Running the examples
git clone https://github.com/Trampoline-AI/predict-rlm.git
cd predict-rlm
uv sync --extra examples
Set your API key for the LLM provider used in the example (defaults to OpenAI):
export OPENAI_API_KEY=sk-...
Each example defaults to the PDFs in its sample/input/ directory. You can also pass file paths or a directory:
# Document analysis
uv run examples/document_analysis/run.py
# Document redaction
uv run examples/document_redaction/run.py
# Invoice processing
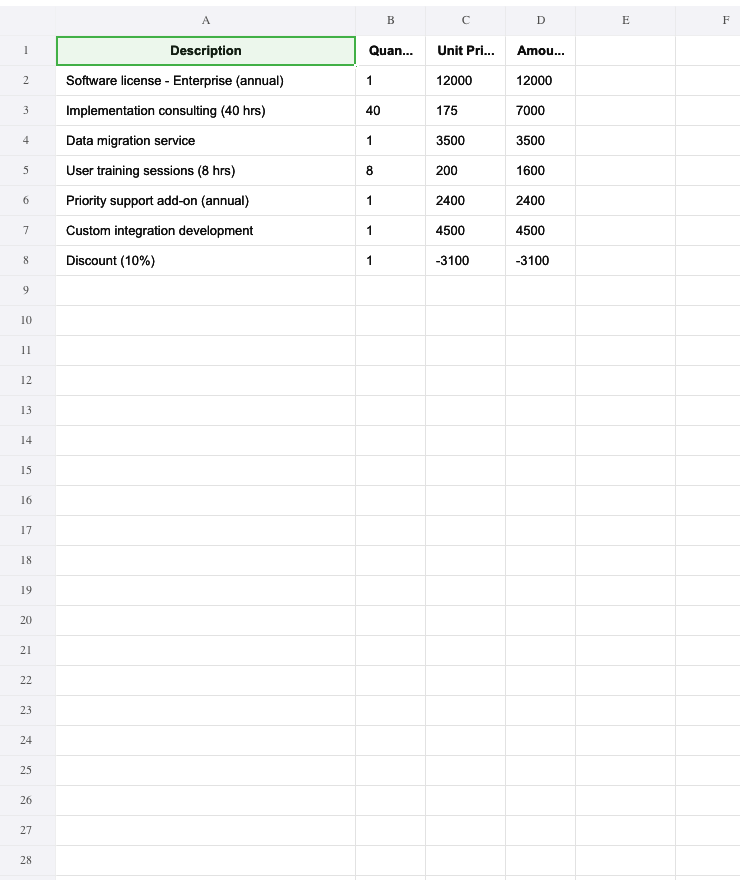
uv run examples/invoice_processing/run.py
# Contract comparison
uv run examples/contract_comparison/run.py
# Pass custom files or a directory
uv run examples/document_analysis/run.py /path/to/docs/
uv run examples/invoice_processing/run.py invoice1.pdf invoice2.pdf
# With debug output (prints REPL code and tool calls to stderr)
uv run examples/document_analysis/run.py --debug
Outputs are saved to output/{timestamp}/ inside each example directory.
Example #1: Document Analysis
What it does: Takes a set of PDFs and a natural language prompt (e.g. "extract key dates, entities, and financial information") and produces a structured report with typed fields.
The output is defined as Pydantic schemas:
class KeyDate(BaseModel):
name: str # e.g. "Submission Deadline"
date: str # ISO format (YYYY-MM-DD)
time: str | None = None # 24-hour format (HH:MM)
timezone: str | None = None # e.g. "EST", "UTC"
class KeyEntity(BaseModel):
name: str # e.g. "Acme Corporation"
role: str | None = None # e.g. "Contractor"
contact: str | None = None
class DocumentAnalysis(BaseModel):
report: str # Full markdown report
key_dates: list[KeyDate]
key_entities: list[KeyEntity]
The DSPy signature ties them together with task instructions:
class AnalyzeDocuments(dspy.Signature):
"""Analyze documents and produce a structured report.
1. Read the report criteria to understand what to extract
2. Survey the documents — file names, page counts, document types
3. Render pages and use predict() to extract content
4. Produce the report following the criteria's format
"""
documents: list[File] = dspy.InputField()
analysis: DocumentAnalysis = dspy.OutputField()
How it works:
The RLM receives File references as input. The files are mounted into the sandbox, and the RLM opens them directly with pymupdf. This is the key design pattern: the RLM manages its own context window. Given a 200-page document set, it doesn't try to process everything at once. Instead, it:
- Surveys the documents — checks file names and page counts to understand the structure
- Samples strategically — renders a few pages to understand the format and identify where key information lives
- Extracts in parallel — uses
asyncio.gather()to send multiple pages topredict()concurrently, extracting dates, entities, or other fields from each page simultaneously - Synthesizes — aggregates findings across pages, deduplicates, and produces the final structured output
The predict() calls use DSPy signatures with type hints, so the sub-LM returns typed data (not free-form text) that the RLM can immediately work with in code:
# Inside the sandbox, the RLM writes code like this:
result = await predict(
"page: dspy.Image -> dates: list[str], entities: list[str]",
instructions="Extract all dates and key entities from this page.",
page=page_image,
)
# result["dates"] is a list of strings, ready to use
What you provide: A DSPy Signature defining the task instructions, a Pydantic schema for the output, and a pdf skill. The service layer wires it all together in ~20 lines.
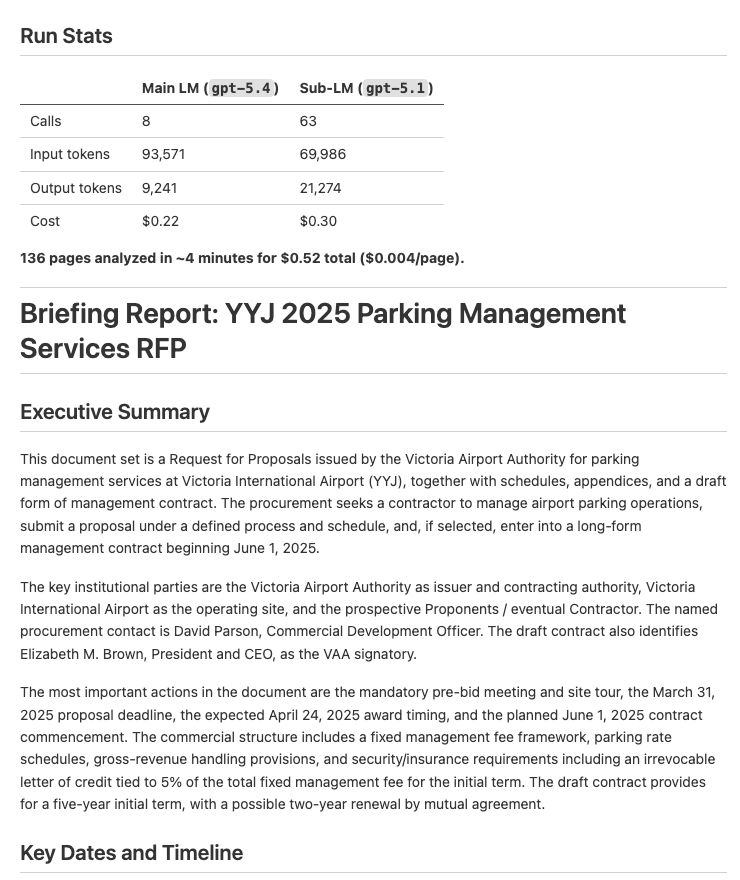
Sample run: The sample/ directory contains a 136-page airport parking management document and the full output produced by the RLM. Here are the run stats:
Main LM (gpt-5.4) |
Sub-LM (gpt-5.1) |
|
|---|---|---|
| Calls | 8 | 63 |
| Input tokens | 93,571 | 69,986 |
| Output tokens | 9,241 | 21,274 |
| Cost | $0.22 | $0.30 |
136 pages analyzed in ~4 minutes for $0.52 total ($0.004/page). The outer LLM made 8 calls to orchestrate the entire run, while 63 sub-LM calls did the heavy lifting in parallel.
Example #2: Document Redaction
What it does: Takes PDFs and a redaction policy (e.g. "redact all PII: names, phone numbers, addresses, signatures") and produces redacted PDF files with sensitive content blacked out — plus a structured report of every redaction applied.
This example demonstrates two key RLM capabilities:
First, the RLM is an autonomous executor that modifies files. It inspects pages, identifies sensitive content, applies redactions, and then re-inspects the pages to verify the redactions worked. If a text match fails (the exact string wasn't found on the page), it retries with a shorter substring.
Second, the RLM parallelizes sub-LM calls to process large documents efficiently. A 100-page PDF doesn't mean 100 sequential LLM calls — the RLM writes asyncio.gather() to fan out predict() calls across all pages concurrently. Each page gets its own sub-LM call with its own context window, all running in parallel.
How it works:
The RLM receives File references to PDFs, which are mounted into the sandbox. It uses pymupdf directly inside the sandbox (via skills) — no host-side tools needed. The workflow the RLM autonomously executes:
- Scans pages in parallel — renders batches of pages as images and fans out
predict()calls viaasyncio.gather()to identify all text matching the redaction criteria across every page concurrently - Applies redactions — uses pymupdf's
search_for()andadd_redact_annot()to black out identified strings. If any are missed, it adjusts and retries - Handles non-text content — for signatures, logos, or images, it estimates bounding box coordinates and redacts by area
- Verifies — re-renders redacted pages and confirms the sensitive content is gone
- Reports — produces a
RedactionResultwith per-page summaries and the complete list of redaction targets
Redacted PDFs are written to a list[File] output and synced back to the host automatically.
What you provide: A DSPy Signature with step-by-step redaction instructions, a Pydantic schema for the result, and skills for pymupdf and redaction patterns. The service layer wires it together in ~20 lines.
Sample run: The sample/ directory contains a 6-page mock employment agreement filled with PII (names, SINs, bank accounts, addresses, phone numbers, health cards) and the full output produced by the RLM — 96 redactions across all 6 pages. Here are the run stats:
Main LM (gpt-5.4) |
Sub-LM (gpt-5.1) |
|
|---|---|---|
| Calls | 6 | 20 |
| Input tokens | 55,432 | 19,572 |
| Output tokens | 5,866 | 6,905 |
| Cost | $0.14 | $0.09 |
6 pages fully redacted in about 2 minutes for $0.24 total. The RLM identified and redacted 96 instances of PII across 6 categories (names, addresses, phone numbers, emails, government IDs, financial info), then verified each page.
API
PredictRLM
The main class. Extends dspy.RLM with a built-in predict() tool.
PredictRLM(
signature, # DSPy signature (str or Signature class)
lm=None, # Main LM — LM instance or model string
sub_lm=None, # LM for predict() — LM instance or model string
max_iterations=30, # Max REPL iterations
max_llm_calls=50, # Max LM calls per execution
tools=None, # Additional tool functions
skills=None, # List of Skill instances
allowed_domains=None, # Domains the sandbox can access
debug=False, # Print REPL activity to stderr
)
File
Unified file type for inputs and outputs. Behavior is determined by the field position in the signature.
File(path="report.pdf") # Single file
File.from_dir("docs/") # All files in a directory -> list[File]
As an input field, the file is mounted into the sandbox. As an output field, it's synced back to the host after execution.
class MySignature(dspy.Signature):
source: File = dspy.InputField() # mounted into sandbox
docs: list[File] = dspy.InputField() # multiple files mounted
result: File = dspy.OutputField() # single file synced back
outputs: list[File] = dspy.OutputField() # multiple files synced back
Skill
Reusable bundle of instructions, packages, modules, and tools.
Skill(
name="my-skill", # Short identifier
instructions="How to approach...", # Injected into the RLM prompt
packages=["pandas", "pdfplumber"], # Installed in the sandbox
modules={"helper": "/path/to/mod.py"},# Mounted as importable modules in the sandbox
tools={"my_func": my_func}, # Exposed alongside predict()
)
Requirements
- Python 3.11+
- Deno (for the sandboxed code interpreter)
The RLM executes generated Python code inside a Pyodide WASM sandbox managed by Deno. Deno provides the V8 runtime with JSPI support, fine-grained permissions (network, filesystem), and runs the sandbox as a subprocess — your host Python process never executes untrusted code directly.
See the Deno installation docs for setup instructions. Deno is automatically invoked when PredictRLM runs — no additional configuration needed.
License
MIT — see LICENSE for details.
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file predict_rlm-0.1.0.tar.gz.
File metadata
- Download URL: predict_rlm-0.1.0.tar.gz
- Upload date:
- Size: 52.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
86606947364fc7dc9644aea36771f7eb5b733dc0cdf82a6c68ffb6ad6c6645ec
|
|
| MD5 |
b01062c6945a39ea8449899d35772cbd
|
|
| BLAKE2b-256 |
832fe32a1698461c13128645770e960f596dbceeb9c9ae69e89676e05ad62483
|
Provenance
The following attestation bundles were made for predict_rlm-0.1.0.tar.gz:
Publisher:
release.yml on Trampoline-AI/predict-rlm
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
predict_rlm-0.1.0.tar.gz -
Subject digest:
86606947364fc7dc9644aea36771f7eb5b733dc0cdf82a6c68ffb6ad6c6645ec - Sigstore transparency entry: 1217967449
- Sigstore integration time:
-
Permalink:
Trampoline-AI/predict-rlm@28b66b36d91a7c1f736286d9041d28bf6ba3369c -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/Trampoline-AI
-
Access:
private
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@28b66b36d91a7c1f736286d9041d28bf6ba3369c -
Trigger Event:
release
-
Statement type:
File details
Details for the file predict_rlm-0.1.0-py3-none-any.whl.
File metadata
- Download URL: predict_rlm-0.1.0-py3-none-any.whl
- Upload date:
- Size: 58.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
983a1f611f5bf33b1b95f760c1ae62400bc72855ec9978027b14a650f920055f
|
|
| MD5 |
eeafd070f4f7cbcf06f02218629baa90
|
|
| BLAKE2b-256 |
b053e35fee6323d40af3c3ba5aee93f58fe465f7b0fcc131f69f193451cf0b5e
|
Provenance
The following attestation bundles were made for predict_rlm-0.1.0-py3-none-any.whl:
Publisher:
release.yml on Trampoline-AI/predict-rlm
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
predict_rlm-0.1.0-py3-none-any.whl -
Subject digest:
983a1f611f5bf33b1b95f760c1ae62400bc72855ec9978027b14a650f920055f - Sigstore transparency entry: 1217967451
- Sigstore integration time:
-
Permalink:
Trampoline-AI/predict-rlm@28b66b36d91a7c1f736286d9041d28bf6ba3369c -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/Trampoline-AI
-
Access:
private
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@28b66b36d91a7c1f736286d9041d28bf6ba3369c -
Trigger Event:
release
-
Statement type:







