An efficient GRPO training util.

Project description





English | 简体中文
Efficient GRPO training through shared-prefix forward
PrefixGrouper is a plug-and-play efficient GRPO training tool that requires minimal modifications to existing codebases to achieve reduced computation, lower device memory consumption, and accelerated training. Additionally, this tool can be applied to other scenarios requiring shared-prefix training/inference beyond GRPO.
In current mainstream GRPO training pipelines, policy model training primarily involves copying prefixes (typically questions, multimodal inputs, etc.) G times. Consequently, when training data prefixes are sufficiently long (e.g., long-context reasoning, image/long-video inference), redundant computation during training becomes non-negligible, leading to increased device memory usage, higher computation costs, and slower training speeds. To address this, we propose PrefixGrouper, a plug-and-play GRPO training tool that enables efficient training through shared-prefix forward passes. Reduced device memory consumption conversely allows more GPUs to support larger group sizes—critical for GRPO algorithms.
News
[2025/6/9] Our technical report is available here!
[2025/6/7] We've updated PrefixGrouper to version 0.0.1rc2 with better encapsulation and fewer code changes required. Welcome to use it!
[2025/6/3] We release PrefixGrouper. Tech report is coming, please stay tuned.
Method Overview
The core of PrefixGrouper lies in its attention operation design:
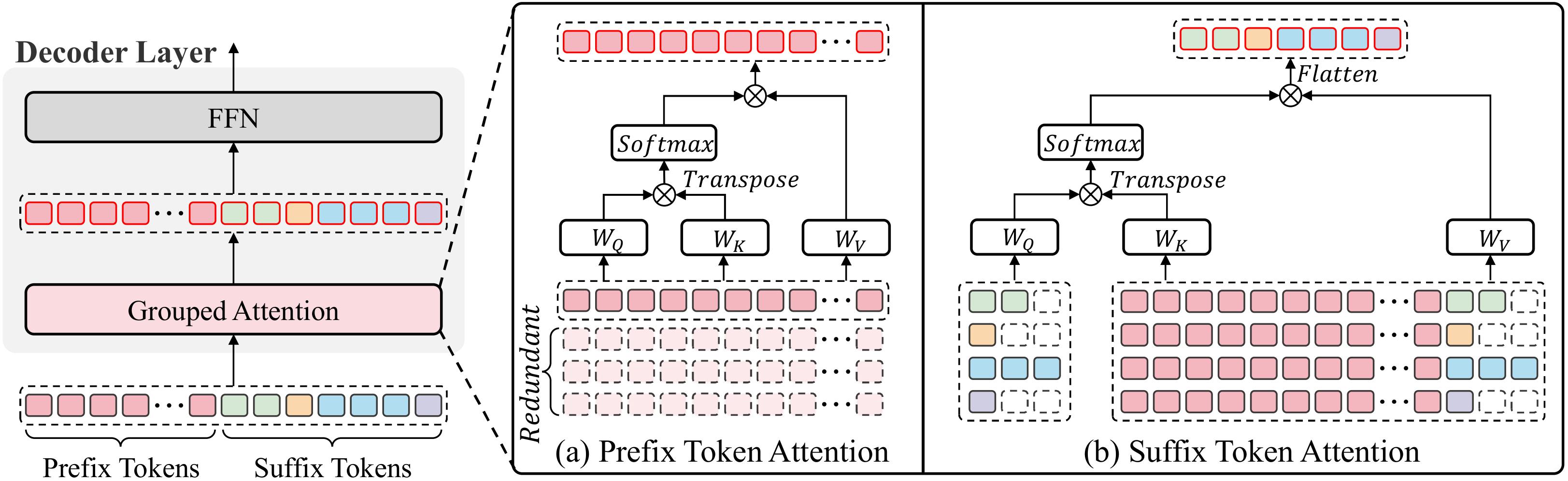
By decomposing the original redundant self-attention operation into prefix self-attention + suffix concat-attention, PrefixGrouper enables efficient GRPO training and is theoretically compatible with various attention implementations (EagerAttention, FlashAttention, SDPA, etc.) as well as hardware devices (GPU, NPU, etc.).
Comparison of FLOPs and memory usage between PrefixGrouper and baseline is as follows, which display results at fixed prefix lengths (4096, 8192, and 16384) across different ratios (prefix length / suffix length):
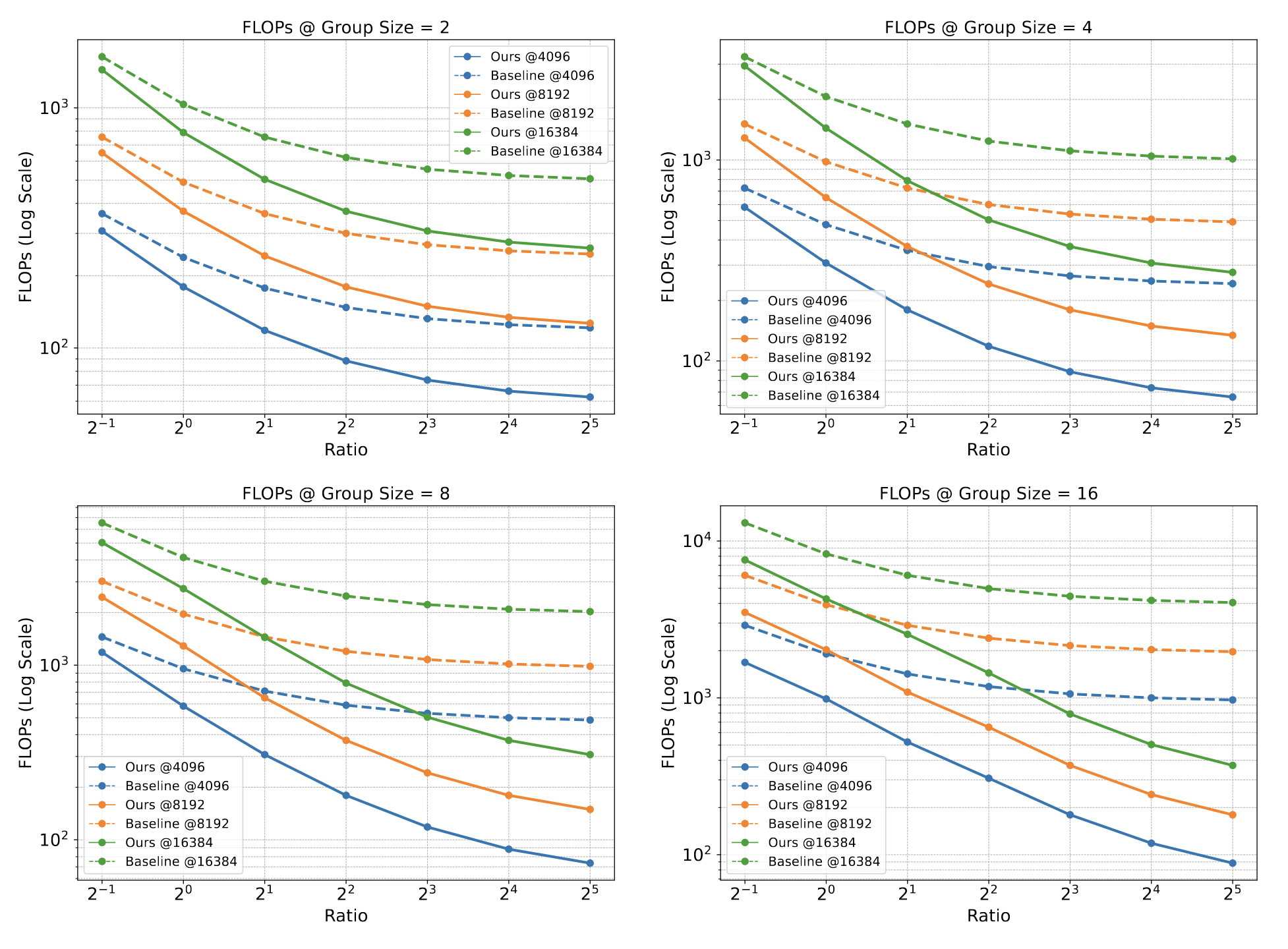
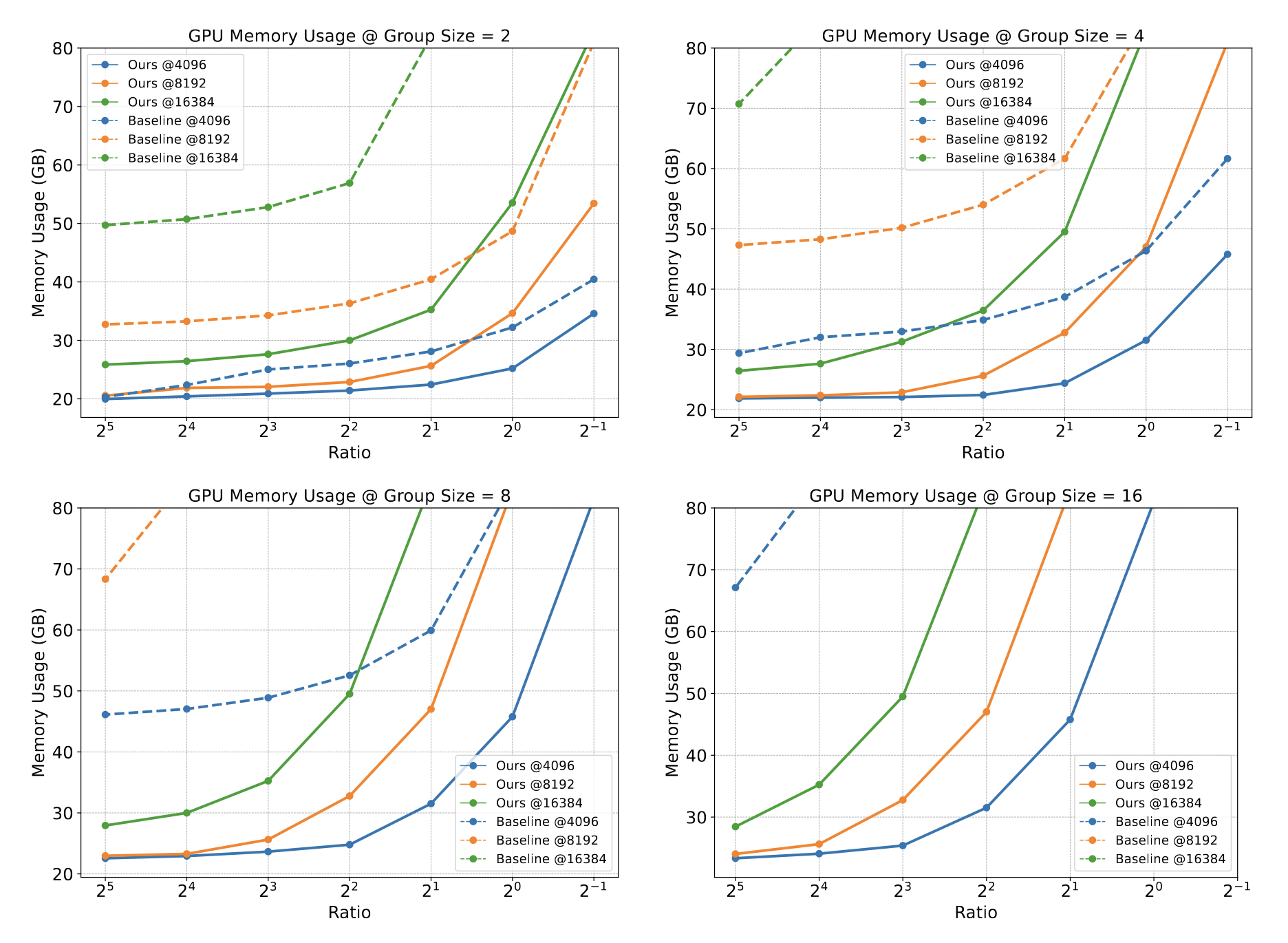
PrefixGrouper demonstrates significant advantages in long-context scenarios, further highlighting its efficiency.
Installation
pip install prefix_grouper
Quick Start
To make PrefixGrouper simpler and easier to use, we provide modification examples for some models.
- Model file modification examples can be found in
examples. For clarity, we wrap key modifications with "PrefixGrouper Start" and "PrefixGrouper End" comments. - For examples simulating the full training workflow, see
tests/equivalence. We provide an almost complete flow for one training step.
If you happen to use one of these models, you can directly integrate the example code into your codebase. However, we recommend briefly reviewing the tutorial below to better understand the tool's workflow.
Running examples:
cd PrefixGrouper
python src/tests/equivalence/test_xxx.py --model_path /path/to/your/model
Tutorial
[!TIP] For better understanding, it's recommended to read alongside the code in both
examplesandtests/equivalence.
Briefly, PrefixGrouper requires modifications in three areas: data input/output, attention mechanisms, and position encoding. Throughout this document, we refer to data corresponding to a query (prefix) as a sample, and each model-generated output based on the prefix as a response.
Data Input/Output
To minimize redundant prefix forward passes and maximize parallel acceleration, PrefixGrouper first concatenates each sample in the batch with its corresponding responses (pseudocode example):
- Best Practices (requires version
0.0.1rc2or above)
# Prefix: [b1, seq_len1], where b1 should be the number of samples
prompt_ids = ...
# Prefix mask: [b1, seq_len1]
prompt_mask = ...
# Suffix: [b2, seq_len2], where b2 should be the total number of responses across all samples
completion_ids = ...
# Suffix mask: [b2, seq_len2]
completion_mask = ...
# int or List[int]. int indicates each sample has the same number of responses, List[int] specifies different response counts per sample.
group_sizes = ...
# Initialize a PrefixGrouper instance.
prefix_grouper = PrefixGrouper.from_ungrouped_masks(
prefix_mask=prompt_mask,
suffix_mask=completion_mask,
group_sizes=group_sizes,
padding_mode="right",
device=device,
)
# Here we use PrefixGrouper to concatenate inputs into final input_ids with shape [b1, seq_len].
# NOTE: Can also input features, i.e. prompt_embeds ([b1, seq_len1, dim]), suffix_embeds ([b2, seq_len2, dim])
input_ids = prefix_grouper.concat_input(prompt_ids, prompt_mask, completion_ids, completion_mask)
attention_mask = prefix_grouper.padding_mask
# Perform model forward - just add one extra argument
res = model(*args, **kwargs, prefix_grouper=prefix_grouper)
# ====== Forward process complete ======
# Explanation of ``include_prefix_last`` parameter: Note that the first token output of the response is actually generated by the last token input of the prefix. Thus the output of the prefix's last token requires loss calculation. Passing ``include_prefix_last=1`` to ``split_output`` means ``PrefixGrouper`` will repeat and concatenate the prefix's last token to the beginning of the suffix. The mask undergoes identical processing.
prefix_output, prefix_mask, suffix_output, suffix_mask = (
prefix_grouper.split_output(res.logits, include_prefix_last=1)
)
# Must convert completion_ids to right padding to align with suffix_output positions
completion_ids = prefix_grouper.convert_padding(completion_ids, completion_mask, padding_mode="right")
# ====== Entire input/output process complete ======
# After obtaining normal outputs, proceed to calculate loss and backpropagate per standard GRPO procedure - fully identical.
# NOTE: Some parts are omitted here, such as advantage, KL loss, importance sampling, etc. Please write your own GRPO loss according to your actual needs.
suffix_output = suffix_output[:, :-1]
suffix_mask = suffix_mask[:, 1:]
# NOTE: Since suffix_output uses ``include_prefix_last=1``, ``completion_ids`` is actually 1 token shorter than ``suffix_output``
# Thus it doesn't require [:, 1:] slicing because the first token is already a valid target.
loss = (suffix_output.gather(-1, completion_ids.unsqueeze(-1)).squeeze(-1) - suffix_output.logsumexp(-1)).exp()
loss = loss * suffix_mask
loss = (loss.sum(-1) / suffix_mask.sum(-1)).mean()
(-loss).backward()
Explanation of concat_input and split_output:
concat_inputconcatenates prompts and completions based onprompt_maskandcompletion_mask. The resultinginput_idsare organized according to thepadding_modeparameter passed toPrefixGrouper. For example,PrefixGrouper.from_ungrouped_masks(..., padding_mode="right")means the concatenatedinput_idswill use compact right padding: prompts and completions form continuous sequences without intermediate padding, left-aligned with padding added on the right.split_outputsplits the output logits into prefix and suffix portions, returning corresponding masks. Note that theinclude_prefix_last=1parameter means the last token of the original prefix will be assigned to the beginning of the suffix. Specifically: inputprompt_ids([b1, seq_len1]) andcompletion_ids([b2, seq_len2]) produce output logits of size[b1, seq_len, dim]. Aftersplit_output(..., include_prefix_last=1),prefix_outputandsuffix_outputbecome sizes[b1, seq_len1 - 1, dim](missing last token) and[b2, seq_len2 + 1, dim](with extra first token). To better implementinclude_prefix_last=1,PrefixGrouperuses left padding for prefixes and right padding for suffixes during splitting, ensuring continuous boundaries. This requires convertingcompletion_idsto the same padding pattern viaprefix_grouper.convert_padding. Finally, note that after conversion,completion_idsremains shape[b2, seq_len2], whilesuffix_outputandsuffix_maskhave sequence lengthseq_len2 + 1(due to the extra token). Thus for alignment, usesuffix_output = suffix_output[:, :-1]andsuffix_mask = suffix_mask[:, 1:], whilecompletion_idsrequires no modification.
[!NOTE] NOTE that the output should use
suffix_maskreturned bysplit_outputto calculate loss rather thancompletion_mask, because both thesuffix_outputandcompletion_idswill be converted to right-padding, in which case thecompletion_maskmay not apply.
- Older Version Examples: Please see
tests/test_equivalence.
Key points for data processing: input concatenation, group_info statistics, and output splitting. Customize based on your project needs while maintaining interface consistency (see docs).
Attention Mechanism
Minor model modifications suffice for attention adaptation. For transformers supporting AttentionInterface, simple registration is possible (experimental). Below describes the generic approach:
if prefix_grouper is None:
# Original attention (baseline)
attn_output = _flash_attention_forward(...)
else:
# ===== PrefixGrouper Start =====
def attn_func(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, attn_mask: torch.Tensor, *args, **kwargs):
# Adapter function for dimension/parameter alignment
return _flash_attention_forward(...)
attn_output = prefix_grouper.forward(...)
# ====== PrefixGrouper End ======
Propagate prefix_grouper parameter through model forward passes.
Position Encoding
Position IDs for concatenated responses should share the same starting ID pattern: [0, 1, ..., prefix_len, prefix_len+1, ..., suffix1_end, prefix_len+1, ..., suffix2_end, ...]. Some useful information: prefix_grouper.group_info[i].prefix_len and prefix_grouper.group_info[i].suffix_lens can obtain the prefix/suffix length information (number of valid tokens excluding padding) for the i-th sample; prefix_grouper.padding_mask can retrieve the attention mask for the input tensor after concatenating the prefix and suffix. The above information can be used to assist in position ids calculation.
Position encoding is pre-adapted for models in the Quick Start section (see examples).
Start Training
Complete GRPO training simulations are provided in tests for reference.
Documentation
Core API documentation:
PrefixGrouper
PrefixGrouper(Optional[List[List[int]]] = None, device=None, padding_mode: Union[str, torch.Tensor] = "right")
group_info: Outer list: sample count (b). Inner lists: [prefix_len, suffix1_len, suffix2_len,...]. This parameter can be None, in which case you need to manually call init (same signature as PrefixGrouper.__init__) to implement delay initialization.
device: Device for initializing PrefixGrouper (actual ops use input tensor's device).
padding_mode: "left"/"right" (dense padding) or torch.Tensor (custom padding mask, shape [b, seq_len]).
Usage examples:
- With
concat_input(recommended):
prefix_grouper = PrefixGrouper(group_info, padding_mode="right")
- Custom input handling:
prefix_grouper = PrefixGrouper(group_info, padding_mode=custom_padding_mask)
PrefixGrouper.concat_input(self, prefix: torch.Tensor, prefix_mask: torch.Tensor, suffix: torch.Tensor, suffix_mask: torch.Tensor)
Concatenates prefix ([b, seq_len] or [b, seq_len, dim]) and suffix ([b * group_size, seq_len] or [b * group_size, seq_len, dim]) using group_info. Requires prefix_mask/suffix_mask (shape [b, seq_len]).
PrefixGrouper.forward(self, __attn_func: AttnFuncType, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, *args, **kwargs)
Performs attention using __attn_func. Function signature: attn_func(q, k, v, attn_mask, *args, **kwargs). Input q/k/v shape: [b, num_heads, seq_len, head_dim]. Output shape: [b, seq_len, num_heads, head_dim]. Do not manually pass attention masks.
PrefixGrouper.split_output(self, output: torch.Tensor, include_prefix_last: int = 0)
output: Shape [b, seq_len, dim]
include_prefix_last: Controls prefix boundary handling (0: no conversion; 1: attach last prefix token to suffixes).
Future Plans
- Hugging Face Transformers
AttentionInterfaceIntegration (This feature is currently in testing) - Additional Training Device Support (
NPUunder testing - no compatibility issues found so far) - Test Cases for More Models (We plan to release plain-text test cases for
Qwen2.5andQwen3models) - Support for other attention implementations (
EagerAttention,SDPA)
Data Usage Statement
Test data in this project is strictly for academic research purposes with the following limitations:
- Commercial use is prohibited
- Data redistribution is prohibited
- De-anonymization attempts are prohibited
Citation
If you find this work helpful, you can cite the following papers:
@misc{liu2025prefixgrouperefficientgrpo,
title={Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward},
author={Zikang Liu and Tongtian Yue and Yepeng Tang and Longteng Guo and Junxian Cai and Qingbin Liu and Xi Chen and Jing Liu},
year={2025},
eprint={2506.05433},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.05433},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file prefix_grouper-0.0.1.post1-py3-none-any.whl.
File metadata
- Download URL: prefix_grouper-0.0.1.post1-py3-none-any.whl
- Upload date:
- Size: 17.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a55127a02ed0e50e2817842e273c7280e9a5c171cb6a415075cac7416256a0cd
|
|
| MD5 |
b3ee6057da1d7c5f2a44cb6c3134dfe4
|
|
| BLAKE2b-256 |
cf3b6c08bd5cb8c0c46ec248b9acfda85c14cfd333d838629b5b17359535c059
|







