Preprocessing Library for Natural Language Processing

Project description
PreNLP




Preprocessing Library for Natural Language Processing
Installation
Requirements
- Python >= 3.6
- Mecab morphological analyzer for Korean
sh scripts/install_mecab.sh # Only for Mac OS users, run the code below before run install_mecab.sh script. # export MACOSX_DEPLOYMENT_TARGET=10.10 # CFLAGS='-stdlib=libc++' pip install konlpy - C++ Build tools for fastText
- g++ >= 4.7.2 or clang >= 3.3
- For Windows, Visual Studio C++ is recommended.
With pip
prenlp can be installed using pip as follows:
pip install prenlp
Usage
Data
Dataset Loading
Popular datasets for NLP tasks are provided in prenlp. All datasets is stored in /.data directory.
- Sentiment Analysis: IMDb, NSMC
- Language Modeling: WikiText-2, WikiText-103, WikiText-ko, NamuWiki-ko
| Dataset | Language | Articles | Sentences | Tokens | Vocab | Size |
|---|---|---|---|---|---|---|
| WikiText-2 | English | 720 | - | 2,551,843 | 33,278 | 13.3MB |
| WikiText-103 | English | 28,595 | - | 103,690,236 | 267,735 | 517.4MB |
| WikiText-ko | Korean | 477,946 | 2,333,930 | 131,184,780 | 662,949 | 667MB |
| NamuWiki-ko | Korean | 661,032 | 16,288,639 | 715,535,778 | 1,130,008 | 3.3GB |
| WikiText-ko+NamuWiki-ko | Korean | 1,138,978 | 18,622,569 | 846,720,558 | 1,360,538 | 3.95GB |
General use cases are as follows:
WikiText-2 / WikiText-103
>>> wikitext2 = prenlp.data.WikiText2()
>>> len(wikitext2)
3
>>> train, valid, test = prenlp.data.WikiText2()
>>> train[0]
'= Valkyria Chronicles III ='
IMDB
>>> imdb_train, imdb_test = prenlp.data.IMDB()
>>> imdb_train[0]
["Minor Spoilers<br /><br />Alison Parker (Cristina Raines) is a successful top model, living with the lawyer Michael Lerman (Chris Sarandon) in his apartment. She tried to commit ...", 'pos']
Normalization
Frequently used normalization functions for text pre-processing are provided in prenlp.
url, HTML tag, emoticon, email, phone number, etc.
General use cases are as follows:
>>> from prenlp.data import Normalizer
>>> normalizer = Normalizer(url_repl='[URL]', tag_repl='[TAG]', emoji_repl='[EMOJI]', email_repl='[EMAIL]', tel_repl='[TEL]', image_repl='[IMG]')
>>> normalizer.normalize('Visit this link for more details: https://github.com/')
'Visit this link for more details: [URL]'
>>> normalizer.normalize('Use HTML with the desired attributes: <img src="cat.jpg" height="100" />')
'Use HTML with the desired attributes: [TAG]'
>>> normalizer.normalize('Hello 🤩, I love you 💓 !')
'Hello [EMOJI], I love you [EMOJI] !'
>>> normalizer.normalize('Contact me at lyeoni.g@gmail.com')
'Contact me at [EMAIL]'
>>> normalizer.normalize('Call +82 10-1234-5678')
'Call [TEL]'
>>> normalizer.normalize('Download our logo image, logo123.png, with transparent background.')
'Download our logo image, [IMG], with transparent background.'
Tokenizer
Frequently used (subword) tokenizers for text pre-processing are provided in prenlp.
SentencePiece, NLTKMosesTokenizer, Mecab
SentencePiece
>>> from prenlp.tokenizer import SentencePiece
>>> SentencePiece.train(input='corpus.txt', model_prefix='sentencepiece', vocab_size=10000)
>>> tokenizer = SentencePiece.load('sentencepiece.model')
>>> tokenizer('Time is the most valuable thing a man can spend.')
['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.']
>>> tokenizer.tokenize('Time is the most valuable thing a man can spend.')
['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.']
>>> tokenizer.detokenize(['▁Time', '▁is', '▁the', '▁most', '▁valuable', '▁thing', '▁a', '▁man', '▁can', '▁spend', '.'])
Time is the most valuable thing a man can spend.
Moses tokenizer
>>> from prenlp.tokenizer import NLTKMosesTokenizer
>>> tokenizer = NLTKMosesTokenizer()
>>> tokenizer('Time is the most valuable thing a man can spend.')
['Time', 'is', 'the', 'most', 'valuable', 'thing', 'a', 'man', 'can', 'spend', '.']
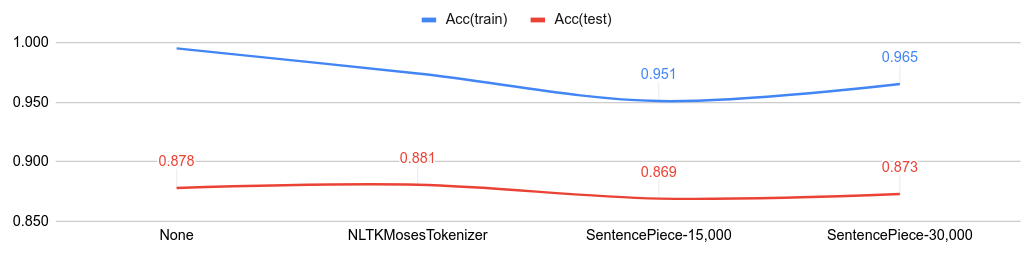
Comparisons with tokenizers on IMDb
Below figure shows the classification accuracy from various tokenizer.
- Code: NLTKMosesTokenizer, SentencePiece
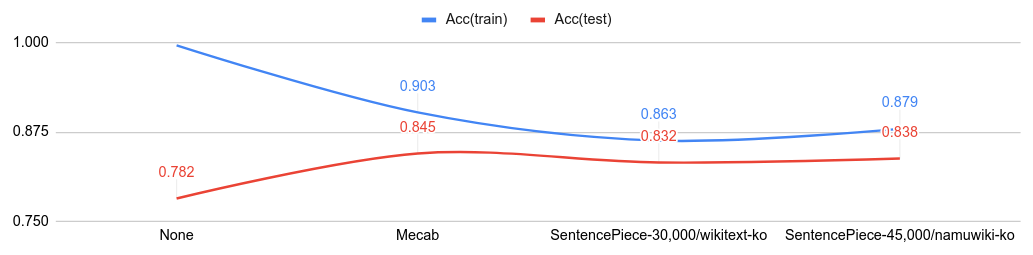
Comparisons with tokenizers on NSMC (Korean IMDb)
Below figure shows the classification accuracy from various tokenizer.
- Code: Mecab, SentencePiece
Author
- Hoyeon Lee @lyeoni
- email : lyeoni.g@gmail.com
- facebook : https://www.facebook.com/lyeoni.f
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file prenlp-0.0.13-py3-none-any.whl.
File metadata
- Download URL: prenlp-0.0.13-py3-none-any.whl
- Upload date:
- Size: 30.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.2.0.post20200210 requests-toolbelt/0.9.1 tqdm/4.42.1 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b0b91705bb3bdbe1163169e12f6b119dfc7607b50a5771e3f4626769e919335e
|
|
| MD5 |
5a880cb885dbd52adefbc99202ae713b
|
|
| BLAKE2b-256 |
7d5904563c069b1f23830c9e9323f79e132c0051df730af640fd3152503ff731
|







