Prompt-level analytics for Claude Code — tokens, costs, and session insights from your local JSONL files
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Prompt-level analytics for Claude Code
Unofficial — not affiliated with Anthropic. This is a community tool that reads Claude Code's local log files. "Claude" and "Claude Code" are trademarks of Anthropic.





Other tools tell you what you spent per day or per session. This one goes down to the prompt: every prompt you have ever sent becomes one row, priced from the raw token counts in your local ~/.claude/projects/**/*.jsonl logs — no account, no API key, nothing leaves your machine.
- Tokens and cost per prompt and per project. A real dataset, not a daily total: which prompts and which projects actually cost you money, with a Pareto view of where it concentrates.
- Meta-analyses across long sessions. How the marginal cost of a prompt changes with its depth in the session, how the cache read/write mix shifts — the questions you can only ask once you have per-prompt rows.
- Automatic categorization of your prompts. A local, zero-dependency heuristic labels every prompt across eleven categories (plan / implementation / debug / refactor / review / test / docs / ops / question / followup / other) and scores its observed complexity 1–5. An optional LLM pass refines it (opt-in — see Categorization).
It validates its token totals against ccusage (see How the numbers stay accurate). Think of it as the per-prompt dataset layer that sits alongside the report-style tools.
See it without installing anything
Two surfaces on the same data — a terminal CLI and a Streamlit dashboard.
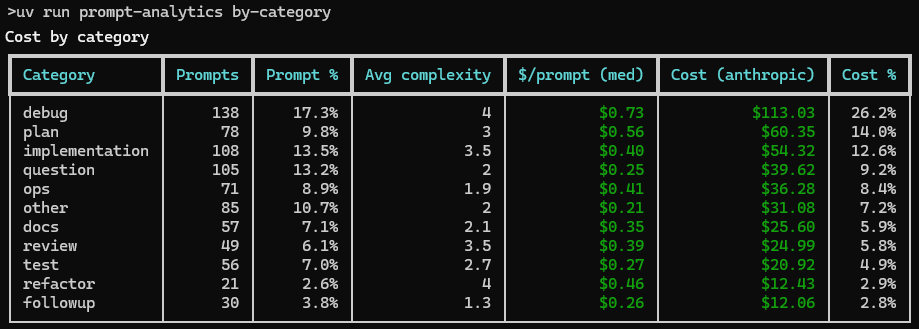
Every CLI command is a single line over your local logs. For example, by-category auto-labels each prompt and scores its observed complexity 1–5 — a local heuristic, no LLM required:
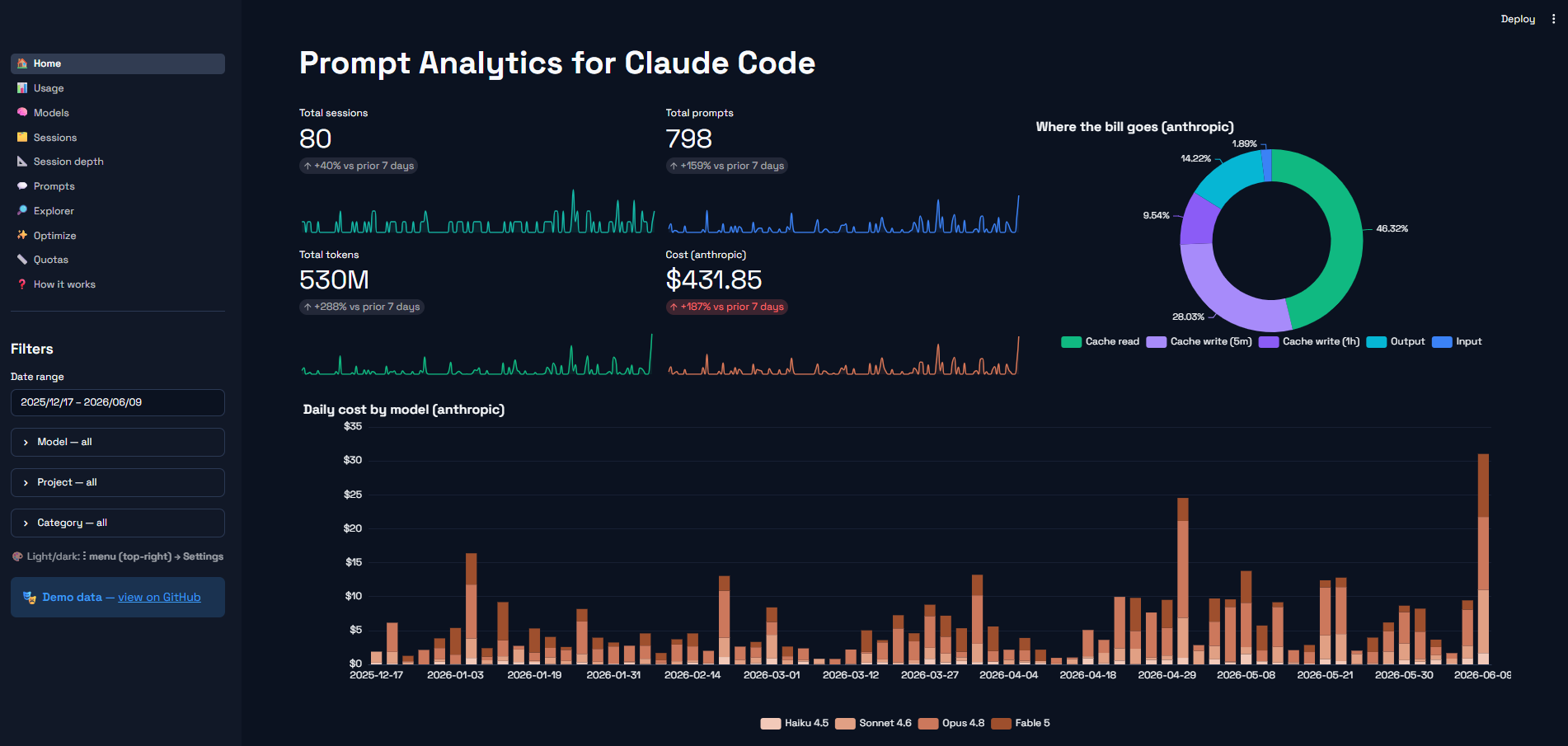
And a live Streamlit demo runs on a synthetic dataset (no real prompts), so you can explore the dashboard before installing — the image below links to the live demo:
▶ Live demo: prompt-analytics-demo.streamlit.app
Quick start
Zero install, straight from PyPI with uv — this reads your real ~/.claude/projects and prints a summary in the terminal:
uvx --from prompt-analytics-for-claude-code prompt-analytics summary
Use it often? Install the prompt-analytics command on your PATH:
uv tool install prompt-analytics-for-claude-code
prompt-analytics summary
Or with pip: pip install prompt-analytics-for-claude-code, then prompt-analytics summary.
The summary is a live parse of your logs — no extract step required (that one is just an export, see below). Running on the bundled demo dataset, the output looks like this; on your machine the source line reads live parse of ~/.claude/projects:
Usage summary
+------------------------------------------------------------------+
| Metric | Value |
|----------------------------+-------------------------------------|
| Sessions | 80 |
| Prompts | 798 |
| Projects | 5 |
| Period | 2025-12-17 .. 2026-06-09 (175 days) |
| Input tokens | 1,729,726 |
| Output tokens | 2,961,653 |
| Cache read tokens | 497,973,616 |
| Cache write (5m) tokens | 22,683,667 |
| Cache write (1h) tokens | 4,680,558 |
| Server tool use (requests) | 264 |
| Total tokens | 530,029,220 |
| Cost (anthropic) | $431.85 |
| Cost (copilot) | $413.84 |
| Subagents | $6.19 (1.4% of anthropic cost) |
+------------------------------------------------------------------+
Source: demo_data CSVs.
Prerequisites: Python 3.10+ and Claude Code with at least one recorded session under ~/.claude/projects/. No organization or Admin API key required (unlike the official Claude Code Analytics API, which needs both).
Dashboard
Prefer a UI? Install with the dashboard extra and point it at your own data:
uv tool install "prompt-analytics-for-claude-code[dashboard]"
prompt-analytics extract # write the CSVs the dashboard reads (./output)
prompt-analytics dashboard # launches Streamlit on http://localhost:8501
No data yet, or just curious? The live demo runs the same dashboard on synthetic data. More in docs/dashboard.md.
What it can tell you
Per-prompt rows turn into answers a daily total can't give. Every block below is real output from the bundled demo dataset (--from-csv demo_data); on your machine the source line reads live parse of ~/.claude/projects.
What one prompt actually costs, by session depth
This is the view the report-style tools don't give. Priced per prompt and bucketed by its position in the session: on this dataset the median prompt at depth 21–50 carries ×2.71 the depth-1 context (≈344k tokens) — and pays that cache rent on every turn until /compact or a new session resets it. sessions --depth prints the full distribution (median, box, p5–p95 tail, n per band); the dashboard's Session depth page draws it as a box plot.
Where the bill goes: context rent
Almost none of your spend is the text you type or the model writes — on this dataset 83% of the bill is "context rent": the cache reads and writes that re-send the conversation every turn (by-token-type breaks it down — cache reads alone are 94% of tokens but 46% of cost). Those aggregate token-type totals overlap with the report-style tools; the difference here is that the same numbers are also available per prompt.
TTL expiry and compaction: the hidden cache costs
Cache entries expire (5-minute or 1-hour TTL); pause longer and the next turn pays to re-write the whole context. ttl attributes those re-writes to the pause that caused them — here ≈$36 of re-writes across pauses of 5m–1h, plus a little more after longer ones.
compactions does the mirror analysis for /compact: context before/after and the cache-rebuild cost of the first post-compaction turn (on this dataset, 3 events, a median 266,598 → 85,905 tokens, −67.8%, rebuilt for $0.43 total). overhead isolates the fixed per-session cost (system prompt + CLAUDE.md + MCP tools ≈ 118,949 tokens here, $0.69 median per session).
Subagents, billed back to the prompt that spawned them
Sub-agent (isSidechain) work is parsed and its cost rolled into the parent prompt, so nothing is under-counted. summary calls it out (Subagents: $6.19 (1.4% of anthropic cost)) and by-model adds a per-model Subagents column.
Is a Pro/Max plan worth it vs the API?
break-even prices your whole history on the per-token grid (the API-equivalent), projects it to a month, and compares it to each flat-rate plan:
Plan break-even: API-equivalent vs subscription (anthropic)
+--------------------------------------------------------------------+
| Plan | Plan $/mo | Your API $/mo | vs plan | Saving $/mo |
|----------------+-----------+---------------+---------+-------------|
| Claude Pro | $20.00 | $74.03 | x3.70 | $54.03 |
| Claude Max 5x | $100.00 | $74.03 | x0.74 | $-25.97 |
| Claude Max 20x | $200.00 | $74.03 | x0.37 | $-125.97 |
+--------------------------------------------------------------------+
Over the 175-day window your usage is worth $431.85 of anthropic API
($74.03/month projected at this rate).
At this rate the Claude Pro plan ($20.00/mo) pays for itself: your
API-equivalent is $74.03/month (x3.70 the price), an estimated $54.03/month
cheaper than paying per token.
Commands
Every analysis command works on the fly — it parses your JSONL in memory (~0.5 s) when there is no fresh extract to read, so you never have to run extract first. All of them accept --output-dir DIR, --format table|csv|json, --pricing PATH, --no-cache, and --from-csv DIR (analyze the CSVs in DIR as-is, with no live parse and no freshness check — the CLI counterpart of what the dashboard does, e.g. summary --from-csv demo_data).
Totals and breakdowns
| Command | Key flags | What it shows |
|---|---|---|
summary |
Sessions, prompts, tokens by type, cost per provider, period, subagent share. | |
by-project |
--pareto --provider |
Cost / tokens / prompts per project, sorted; --pareto adds share + cumulative %. |
by-model |
--compact --provider |
Token and cost split per model (cache writes split by TTL, subagent column); --compact fits 80 columns. |
by-token-type |
--provider |
Cost split per token type — the context-rent share of the bill (cache vs generation vs input). |
by-category |
--provider |
Cost and observed complexity per category (needs categorize). |
prompts |
--top N --provider |
The N most expensive prompts, with a preview. |
sessions |
--depth | --top N, --project NAME |
Sessions ranked by cost, or --depth for the marginal-cost-by-depth meta-analysis; --project restricts to one. |
More commands — power-user analyses, pricing, export & pipeline
Power-user analyses (request grain — see What it can tell you)
| Command | Key flags | What it shows |
|---|---|---|
context |
--provider |
Accumulated context per turn by session depth — the "time to /compact" signal. |
ttl |
--provider |
Cache-TTL expiry losses: what inter-prompt pauses cost in cache re-writes. |
compactions |
--provider |
Each /compact event: context before/after and the cache-rebuild cost. |
overhead |
--provider |
Fixed per-session overhead (system prompt + CLAUDE.md + MCP tools). |
model-category |
--whatif MODEL --provider |
Cost by model × category; --whatif re-prices every cell on another model. |
recommend |
--min-prompts N --compact-at K |
Prescriptive: what compacting long sessions earlier would have saved. |
burn-rate |
--weeks N --provider |
Spend trend: $/day and week over week. |
break-even |
--provider |
Plan break-even: your API-equivalent value vs a Pro/Max subscription. |
Pricing, export and pipeline
| Command | Key flags | What it shows |
|---|---|---|
compare |
--providers A,B |
The same usage priced on several grids side by side. |
export |
--flat --out PATH |
Denormalized export for Excel/BI (see below). |
extract |
--no-text --since --until --timezone --strict |
Write the normalized CSVs to --output-dir. |
snapshot |
Append current quota utilization to quota_log.csv. |
|
categorize |
--llm --provider --batch --model --limit |
Label prompts — heuristic by default, LLM opt-in. |
run |
--categorize (+ --llm --provider --batch --model) --no-text --since … |
Pipeline: extract (+ optional categorize, with full LLM passthrough) + snapshot. |
dashboard |
--output-dir |
Launch the Streamlit dashboard — reads an extract, so run extract first (needs the dashboard extra). |
config init |
Write a default config.yml into the output directory. |
Run prompt-analytics <command> --help for the full flag list. extract and run always regenerate the whole output atomically — there is no incremental mode to misuse, and changing the pricing never requires a re-extract (costs are computed at read time from raw counts).
Exporting data
extract writes the canonical, inspectable, zero-dependency format: relational CSVs keyed by prompt_id / session_id (sessions, prompts, prompts_text, tokens, token_types, plus quota_log from snapshot) into ./output (gitignored). tokens.csv holds raw counts only — prices are computed at read time, so a pricing change never needs a re-extract. The exact column layout is the single source of truth in prompt_analytics/schema.py; the full data flow is documented in docs/architecture.md.
For spreadsheets and BI tools that want one flat table, export --flat writes a single denormalized CSV — one row per prompt, token columns pivoted (input_tokens, output_tokens, cache_read_tokens, …), a cost_<provider>_usd column per provider, and the session fields duplicated in:
prompt-analytics export --flat --out my_usage.csv
Every command also takes --format json (a {title, rows, notes} object with raw numeric values) and --format csv (raw rows on stdout, notes on stderr) for piping into jq, pandas, or a notebook.
Pricing providers
Costs are computed at read time from a generic multi-provider grid (prompt_analytics/data/pricing.yml). Two ship by default — anthropic (published API rates) and copilot (the GitHub Copilot equivalent) — so compare answers "what would this usage cost billed through Copilot instead of the API?". Add any rate card under providers: (an internal plan, a Bedrock tier, a negotiated rate) or pass --pricing ./my.yml; the bundled grid is kept honest by a weekly CI drift job (LiteLLM + the live Copilot page). See CONTRIBUTING.md for the schema and lookup rules.
Example: compare across providers
Provider cost comparison
+---------------------------------------------------------------------+
| Model | Tokens | Cost (anthropic) | Cost (copilot) |
|-------------------+-------------+------------------+----------------|
| claude-opus-4-8 | 205,870,608 | $211.45 | $202.49 |
| claude-fable-5 | 53,609,993 | $113.85 | $109.50 |
| claude-sonnet-4-6 | 144,545,831 | $82.41 | $79.14 |
| claude-haiku-4-5 | 126,002,788 | $24.13 | $22.71 |
| TOTAL | 530,029,220 | $431.85 | $413.84 |
+---------------------------------------------------------------------+
Total on copilot: x0.96 the anthropic total.
Categorization
By default, categorization is 100% local and runs for everyone — no API key, no network:
prompt-analytics categorize # heuristic, writes categories.csv
prompt-analytics by-category
A weighted FR+EN regex classifier labels each prompt across eleven categories (plan / implementation / debug / refactor / review / test / docs / ops / question / followup / other), and an observed complexity 1–5 is derived from the effort it actually triggered (turns, tool calls, length, cost) — a measurement, not a guess.
Cost by category
+---------------------------------------------------------------------------------------------------+
| Category | Prompts | Prompt % | Avg complexity | $/prompt (med) | Cost (anthropic) | Cost % |
|----------------+---------+----------+----------------+----------------+------------------+--------|
| debug | 138 | 17.3% | 4 | $0.73 | $113.03 | 26.2% |
| plan | 78 | 9.8% | 3 | $0.56 | $60.35 | 14.0% |
| implementation | 108 | 13.5% | 3.5 | $0.40 | $54.32 | 12.6% |
| question | 105 | 13.2% | 2 | $0.25 | $39.62 | 9.2% |
| ops | 71 | 8.9% | 1.9 | $0.41 | $36.28 | 8.4% |
| other | 85 | 10.7% | 2 | $0.21 | $31.08 | 7.2% |
| docs | 57 | 7.1% | 2.1 | $0.35 | $25.60 | 5.9% |
| review | 49 | 6.1% | 3.5 | $0.39 | $24.99 | 5.8% |
| test | 56 | 7.0% | 2.7 | $0.27 | $20.92 | 4.9% |
| refactor | 21 | 2.6% | 4 | $0.46 | $12.43 | 2.9% |
| followup | 30 | 3.8% | 1.3 | $0.26 | $12.06 | 2.8% |
+---------------------------------------------------------------------------------------------------+
Source: demo_data CSVs.
The $/prompt (med) column is the one to read alongside the total: a category can top the bill just by volume, but a high median per prompt is what flags work that is intrinsically expensive — here debug is costly both ways ($0.73/prompt) while followup stays cheap ($0.26). Token % and Cost % sit next to their own columns throughout, so volume and spend are never conflated.
Optional LLM refinement
categorize --llm re-labels prompts with an LLM; it only overwrites heuristic rows, never the reverse. Providers:
--provider anthropic(default whenANTHROPIC_API_KEYis set;--batchuses the Message Batches API, −50% cost).--provider openrouter— a third party. Up to ~2000 characters of each prompt are sent to OpenRouter; the command warns you at runtime before sending.--provider ollama— a local model via the OpenAI-compatible API atlocalhost:11434/v1. Free, no key, nothing leaves your machine.
Set keys in a .env file (see .env.example). Most Claude Code Pro/Max subscribers have no Console API key — that is exactly why the heuristic is the default.
How the numbers stay accurate
Claude Code writes a single assistant message as several JSONL lines carrying progressive snapshots of the same response — output_tokens grows line by line, and the model can even change mid-message. Naively summing every line double-counts and inflates token totals by roughly 2.5×.
The parser counts each response exactly once: for a given message.id + requestId it keeps the largest usage snapshot (ties broken by the first line, so a message straddling midnight belongs to its start day). Deduplication is global across all files, not per session — that is what corrects resumed / --resume sessions, where the same records are replayed into a new file.
On top of dedup, the extractor also:
- Filters fake prompts —
isMetaentries,<command-name>/<local-command-stdout>blocks,[Request interrupted by user], and the synthetic post-compaction "continuation" message are kept out ofprompts.csvand out of categorization, while their token usage is still counted against the session. - Has an explicit sidechain / sub-agent policy — inline
isSidechainevents and separatesubagents/*.jsonlfiles are parsed and their cost is rolled into the parent prompt (so nothing is silently under-counted), but they are excluded from the parent'sassistant_turns/tool_calls. - Splits cache writes by TTL —
cache_write_5m(1.25×) vscache_write_1h(2×), and countsserver_tool_userequests separately (billed per request, not per token).
These totals reconcile bucket-for-bucket with bunx ccusage --json (day × model) on real history — the reconciliation is scripted in scripts/reconcile_ccusage.py. Each command also prints its data source, and extract ends with a loud report (files read / skipped, unknown event types, unpriced models, Claude Code versions seen) so a silent format break surfaces immediately.
Privacy
This tool reads your entire Claude Code prompt history, so it is explicit about what it touches.
Reads (locally): ~/.claude/projects/**/*.jsonl (read-only); ~/.claude/.credentials.json (only snapshot, to reuse your existing token); the pricing grid bundled in the package. A relocated Claude directory is honored via CLAUDE_CONFIG_DIR, like Claude Code itself. On Windows, ~ means C:\Users\<you> (%USERPROFILE%).
Writes (locally, never inside the installed package): the CSVs in your output directory (default ./output, gitignored). prompts_text.csv contains the full text of every prompt in clear, and prompts.csv keeps a short prompt_preview — treat an export as sensitive before sharing or committing it. A parse cache lives under %LOCALAPPDATA%\prompt-analytics\ on Windows, $XDG_CACHE_HOME/prompt-analytics/ (default ~/.cache/prompt-analytics/) elsewhere — safe to delete; entries for deleted logs are garbage-collected on each run.
--no-textis honest: it skipsprompts_text.csvand blanks theprompt_previewcolumn.- Free-text cells starting with
=,+,-, or@are prefixed with'so a crafted prompt can't execute as a spreadsheet formula.
Network: nothing by default. extract and every analysis command are fully local. snapshot reuses the token Claude Code stored in ~/.claude/.credentials.json to call an undocumented Anthropic OAuth usage endpoint (sent to Anthropic only; it fails gracefully if the endpoint changes). categorize --llm sends prompt excerpts to the provider you choose — and OpenRouter is a third party.
Related tools
- ccusage — fast terminal usage reports (daily/session/blocks) and JSON output, 14+ CLIs supported. Complementary: it does aggregated reports, this does the per-prompt dataset. Token totals here are validated against it.
- usage-monitor-for-claude — real-time quota tray app for Windows; it discovered the undocumented quota endpoint this tool's
snapshotreuses. - Claude-Code-Usage-Monitor — real-time 5-hour-block burn-rate monitor with P90 predictions.
- Claude Code Analytics API — official, org-level analytics; requires an organization and an Admin API key.
Contributing
See CONTRIBUTING.md for dev setup, how to add a pricing provider, and how to capture a versioned test fixture. In short: uv sync --all-extras, then ruff check ., ruff format --check ., mypy prompt_analytics tests, and pytest.
License
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file prompt_analytics_for_claude_code-0.3.1.tar.gz.
File metadata
- Download URL: prompt_analytics_for_claude_code-0.3.1.tar.gz
- Upload date:
- Size: 541.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cc4b19dd259b8c6a47f1a91e37138009d1cba89b05d25e660eacd02e36cb8c13
|
|
| MD5 |
0f02b4e253159a1cb12aff9ebc5e69bb
|
|
| BLAKE2b-256 |
777244d93bc95f80997b99df90d04fcd64ce8e57091e318ffaa1e91d2143e6ff
|
Provenance
The following attestation bundles were made for prompt_analytics_for_claude_code-0.3.1.tar.gz:
Publisher:
release.yml on romainfjgaspard/prompt-analytics-for-claude-code
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
prompt_analytics_for_claude_code-0.3.1.tar.gz -
Subject digest:
cc4b19dd259b8c6a47f1a91e37138009d1cba89b05d25e660eacd02e36cb8c13 - Sigstore transparency entry: 1828368002
- Sigstore integration time:
-
Permalink:
romainfjgaspard/prompt-analytics-for-claude-code@50745030720eb4070423cc4532b2c41d5636e4aa -
Branch / Tag:
refs/tags/v0.3.1 - Owner: https://github.com/romainfjgaspard
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@50745030720eb4070423cc4532b2c41d5636e4aa -
Trigger Event:
push
-
Statement type:
File details
Details for the file prompt_analytics_for_claude_code-0.3.1-py3-none-any.whl.
File metadata
- Download URL: prompt_analytics_for_claude_code-0.3.1-py3-none-any.whl
- Upload date:
- Size: 162.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
62d477ffc536aa2ff189b4176553dfc769227a766ab21c95b448eae4cd9f3585
|
|
| MD5 |
dfd0daeb41a27dd94d49ef319aea7e94
|
|
| BLAKE2b-256 |
3169111546faacdf05301830c45f64cc350960ea139bb5c7ecd31b45601561e8
|
Provenance
The following attestation bundles were made for prompt_analytics_for_claude_code-0.3.1-py3-none-any.whl:
Publisher:
release.yml on romainfjgaspard/prompt-analytics-for-claude-code
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
prompt_analytics_for_claude_code-0.3.1-py3-none-any.whl -
Subject digest:
62d477ffc536aa2ff189b4176553dfc769227a766ab21c95b448eae4cd9f3585 - Sigstore transparency entry: 1828368424
- Sigstore integration time:
-
Permalink:
romainfjgaspard/prompt-analytics-for-claude-code@50745030720eb4070423cc4532b2c41d5636e4aa -
Branch / Tag:
refs/tags/v0.3.1 - Owner: https://github.com/romainfjgaspard
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@50745030720eb4070423cc4532b2c41d5636e4aa -
Trigger Event:
push
-
Statement type:







